买过域名之前就可以做网站了吗推广引流渠道有哪些
Sparse Transformer 论文
解决了 Transformer 在长序列建模时的计算开销和内存过大的问题。
可视化了一个 128 层自注意力在 CIFAR-10 的数据集上学习到的注意力模式,发现:1)稀疏性普遍存在:大多数层在多数数据点上表现出稀疏注意力;2)例外:部分层想要捕捉全局依赖关系。Transformer 的注意力机制呈现了和卷积模型类似的归纳偏置,即浅层的网络倾向于提取纹理信息,深层的网络倾向于提取语义信息。
分解自注意力(Factorized self-attention)
Local 自注意力只关注自身相邻的,其余设为 0,类似于卷积;Atrous 自注意力是跳着计算,类似膨胀卷积;一种简单思路是交替使用 Local 自注意力和 Atrous 自注意力。但 OpenAI 并没有这么做,而是将二者合为一。

由于 Transformer 的最复杂的计算是 Q K T QK^T QKT,稀疏注意力是让设置好的像素点参与注意力的计算。由此,引入了连接模式的变量 S = { S 1 , … … , S n } S=\{S_1,……,S_n\} S={S1,……,Sn}。其中 S i S_i Si 是在预测第 i 个时间片的索引,是一个由 0 和 1 组成的二维矩阵。
Attend ( X , S ) = ( a ( x i , S i ) ) i ∈ { 1 , … , n } ( 2 ) a ( x i , S i ) = softmax ( ( W q x i ) K S i T d ) V S i ( 3 ) K S i = ( W k x j ) j ∈ S i V S i = ( W v x j ) j ∈ S i ( 4 ) \begin{aligned} \operatorname{Attend}(X, S) = \left(a(\mathbf{x}_i, S_i)\right)_{i \in \{1, \ldots, n\}} \quad (2) \\a(\mathbf{x}_i, S_i) = \operatorname{softmax}\left(\frac{(W_q \mathbf{x}_i) K_{S_i}^T}{\sqrt{d}}\right) V_{S_i} \quad (3) \\K_{S_i} = \left(W_k \mathbf{x}_j\right)_{j \in S_i} \quad V_{S_i} = \left(W_v \mathbf{x}_j\right)_{j \in S_i} \quad (4) \end{aligned} Attend(X,S)=(a(xi,Si))i∈{1,…,n}(2)a(xi,Si)=softmax(d(Wqxi)KSiT)VSi(3)KSi=(Wkxj)j∈SiVSi=(Wvxj)j∈Si(4)
其中 W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv 是计算 Query,Key,Value 三个向量的权值矩阵。稀疏 Transformer 通过让链接模式作用到 K T K^T KT 上,从而降低 Q K T QK^T QKT 的复杂度
跨步注意力(Stride Attention) 由两种形式的连接模式组成。假设步长 l l l,行注意力是当前时间片的前 l l l 个时间片的值为 1,其余为 0;列注意力是每隔 l l l 个时间片段值为 1, 其余为 0。行注意力和列注意力的表达式如下,复杂度均为 O ( n ) O(\sqrt{n}) O(n):
A i ( 1 ) = { t , t + 1 , t + 2 , … … , i } , w h e r e t = m a x ( 0 , i − l ) A i ( 2 ) = { j : ( i − j ) m o d l = 0 } \begin{aligned} A_i^{(1)}=\{t,t+1,t+2,……,i\},where\quad t = max(0,i-l) \\A_i^{(2)}=\{j:(i-j)\mod l =0\} \end{aligned} Ai(1)={t,t+1,t+2,……,i},wheret=max(0,i−l)Ai(2)={j:(i−j)modl=0}
固定注意力(Fixed Attention) 也有行注意力和列注意力组成:
A i ( 1 ) = { j : ( [ j / l ] = [ i / l ] ) } A i ( 2 ) = { j : j m o d l ∈ { t , t + 1 , … … , l } } \begin{aligned} A_i^{(1)}=\{j:([j/l]=[i/l])\} \\A_i^{(2)}=\{j:j\mod l \in\{t,t+1,……,l\}\} \end{aligned} Ai(1)={j:([j/l]=[i/l])}Ai(2)={j:jmodl∈{t,t+1,……,l}}
将以上注意力核融入网络中:
- 每个残差块使用不同的注意力类型: a t t e n t i o n ( X ) = W p ⋅ a t t e n d ( X , A ( r m o d p ) ) attention(X)=W_p·attend(X,A^{(r \mod p)}) attention(X)=Wp⋅attend(X,A(rmodp)) 其中 r 是当前残差块的缩影,p 是注意力核的类别数;
- 每个注意力头计算所有类型注意力核,合并他们的结果: a t t e n t i o n ( X ) = W p ⋅ a t t e n d ( X , ∪ m = 1 p A ( m ) attention(X)=W_p·attend(X,\cup_{m=1}^p A^{(m)} attention(X)=Wp⋅attend(X,∪m=1pA(m)
- 对于多头注意力,每个头选择一个注意力核,合并结果: a t t e n t i o n ( X ) = W p ( a t t e n d ( X , A ) ( i ) ) i ∈ { 1 , … … , n h } attention(X)=W_p(attend(X,A)^{(i)})_{i\in\{1,……,n_h\}} attention(X)=Wp(attend(X,A)(i))i∈{1,……,nh} 其中 n h n_h nh 组不同注意力核并行计算,然后在特征维度拼接。
多层 Transformer 训练

作者使用了在 ResNet v2 中提出的激活前置的残差模块,一个 N N N 层的网络可以表示为:
H 0 = e m b e d ( X , W e ) H k = H k − 1 + r e s b l o c k ( H k − 1 ) y = s o f t m a x ( n o r m ( H N ) W o u t ) \begin{aligned} H_0=embed(X,W_e) \\H_k=H_{k-1}+resblock(H_{k-1}) \\y=softmax(norm(H_N)W_{out}) \end{aligned} H0=embed(X,We)Hk=Hk−1+resblock(Hk−1)y=softmax(norm(HN)Wout)
其中 embed 是可学习的嵌入层: e m b e d ( X , W e ) = ( x i W e + ∑ j = 1 n e m b o i ( j ) W j ) embed(X,W_e)=\left(\boldsymbol{x}_iW_e+\sum_{j=1}^{n_{emb}}\boldsymbol{o}_i^{(j)}W_j\right) embed(X,We)=(xiWe+∑j=1nemboi(j)Wj) 其中 n e m b n_{emb} nemb 的值为 d d a t a d_{data} ddata 或 d a t t n d_{attn} dattn, x i \boldsymbol{x}_i xi 是序列中第 i 个元素的 one-hot 编码, o i ( j ) \boldsymbol{o}_i^{(j)} oi(j) 是 x i \boldsymbol{x}_i xi 在第 j j j 维特征上的 one-hot 编码。
resblock(h) 由一个注意力模块和一个前馈神经网络组成:
a ( H ) = dropout( attention ( n o r m ( H ) ) ) b ( H ) = d r o p o u t ( f f ( n o r m ( H + a ( H ) ) ) ) resblock ( H ) = a ( H ) + b ( H ) \begin{gathered} a(H)=\text{dropout( attention }(\mathrm{norm}(H))) \\ b(H)=\mathrm{dropout}(\mathrm{ff}(\mathrm{norm}(H+a(H)))) \\ \operatorname{resblock}(H)=a(H)+b(H) \end{gathered} a(H)=dropout( attention (norm(H)))b(H)=dropout(ff(norm(H+a(H))))resblock(H)=a(H)+b(H)
梯度检查点
一个以时间换空间的一个策略,在反向传播的过程中,不是保存所有节点的参数值,而是只保留部分关键节点的值,然后通过这些关键节点反向推出其他节点的值。这样虽然引入了额外的节点参数的计算工作,但是大大节约了显存,从而使得训练更长的序列成为可能。
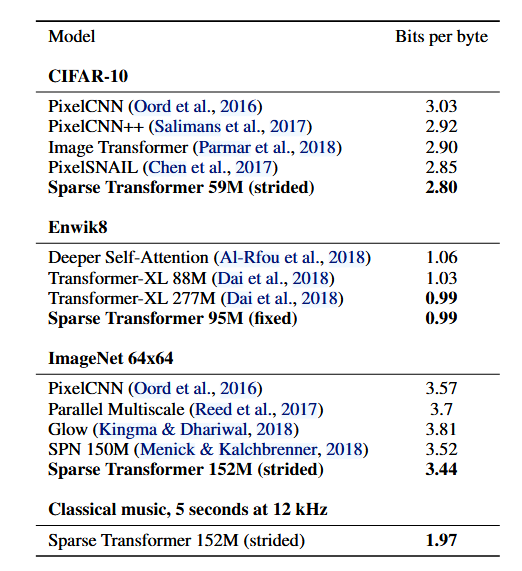
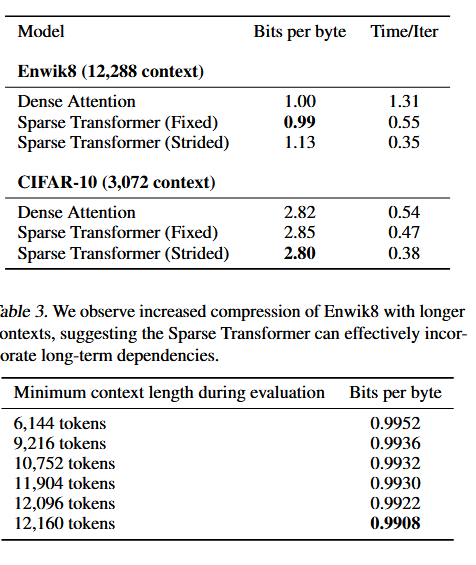
实验结果