日本做头像的网站有哪些关键词搜索引擎优化推广

需求说明
督导检查,各条线都要收集资料。
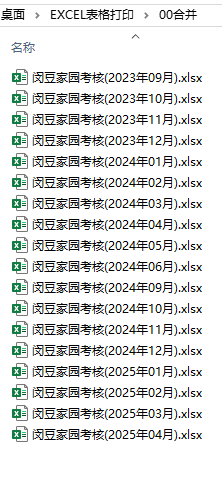
今天去加班,遇到家教主任,她让我用保教主任的彩色打印机打印这套活跃度表格。(2023学年上学期下学期-2024学年上学期,就是202309-202504)
每个excle都是内容在A4一页竖版上
打印预览(在A4一页上)
存在问题:
但是一共有18个表格,如果我要手动一个个打开打印,容易少打(需要检查才能知道少打那一页)、错页(需要手动排序)。还要花时间关闭。
在现在这个争分夺秒补资料的时期,一个个表格打印实在是太烦了。
解决思路
前期我用星火讯飞问过excle是否可以保存PDF,代码没有运行成功。所以这次我用豆包问问excle是否可以保存PDF
问题1:excle转PDF
问题1的解决代码
'''
20250504闵豆EXCLE转pdf
豆包、阿夏
20250504
'''
import os
import win32com.client as win32def convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path):try:# 创建 Excel 应用程序对象excel = win32.gencache.EnsureDispatch('Excel.Application')# 使 Excel 应用程序可见(可选,有助于调试)excel.Visible = True# 打开 Excel 文件workbook = excel.Workbooks.Open(xlsx_file_path)# 保存所有工作表为一个 PDFworkbook.ExportAsFixedFormat(0, pdf_file_path)# 关闭工作簿和 Excel 应用程序workbook.Close(SaveChanges=False)excel.Quit()print(f"成功将 {xlsx_file_path} 转换为 {pdf_file_path}")except Exception as e:print(f"转换 {xlsx_file_path} 时出错: {e}")def main():path = r'C:\Users\jg2yXRZ\OneDrive\桌面\EXCEL表格打印'# 定义源文件夹路径source_folder = path + r'\00合并'# 定义目标文件夹路径target_folder = path + r'\01pdf'# 检查源文件夹是否存在if not os.path.exists(source_folder):print(f"源文件夹 {source_folder} 不存在。")return# 如果目标文件夹不存在,则创建它if not os.path.exists(target_folder):os.makedirs(target_folder)# 遍历源文件夹中的所有文件for root, dirs, files in os.walk(source_folder):for file in files:if file.endswith(('.xlsx', '.xls')):xlsx_file_path = os.path.join(root, file)pdf_file_name = os.path.splitext(file)[0] + '.pdf'pdf_file_path = os.path.join(target_folder, pdf_file_name)convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path)if __name__ == "__main__":main()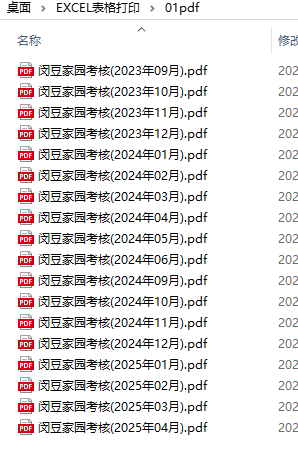
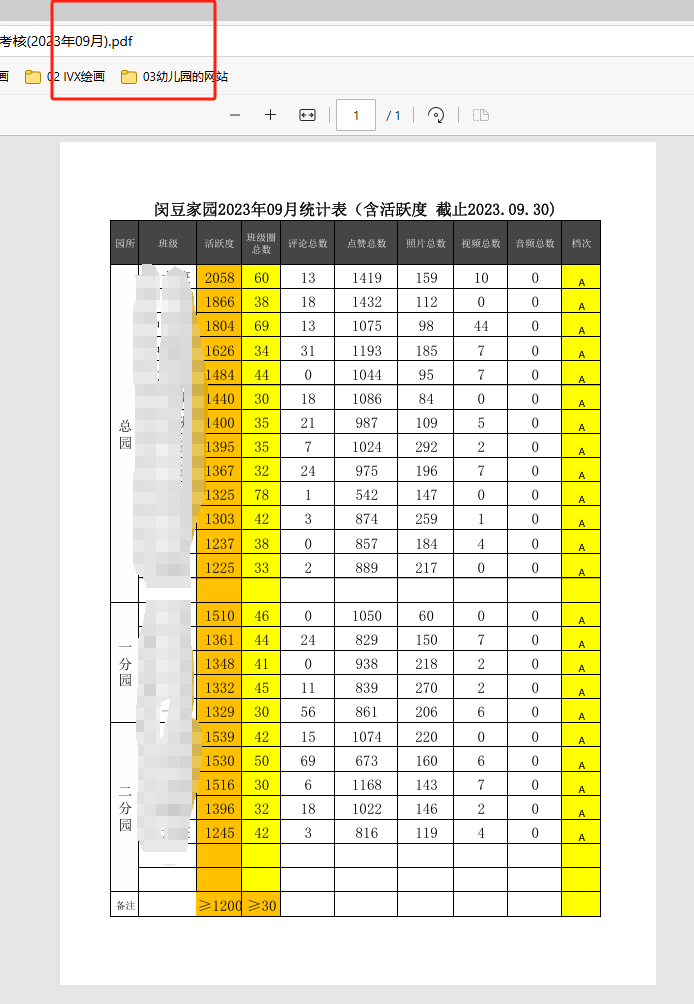
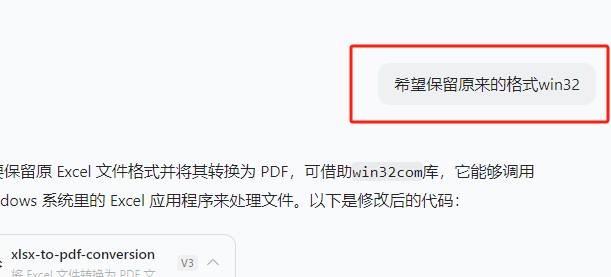
五分钟就出现了excel转pdf的效果(要用win32才保留原来的格式)
问题2:缺少页眉
很快就发现这套excel没有页眉,如果要做资料,这套excle也要有“学校”的页眉
第1次尝试,豆包
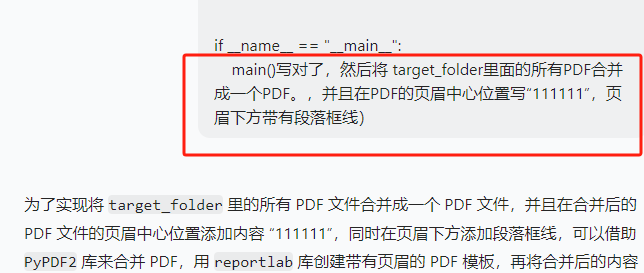
'''
20250504闵豆EXCLE转pdf,加页眉
豆包、阿夏
20250504
'''import os
import win32com.client as win32
from PyPDF2 import PdfReader, PdfWriter
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
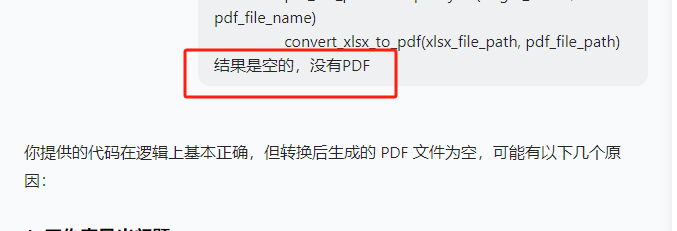
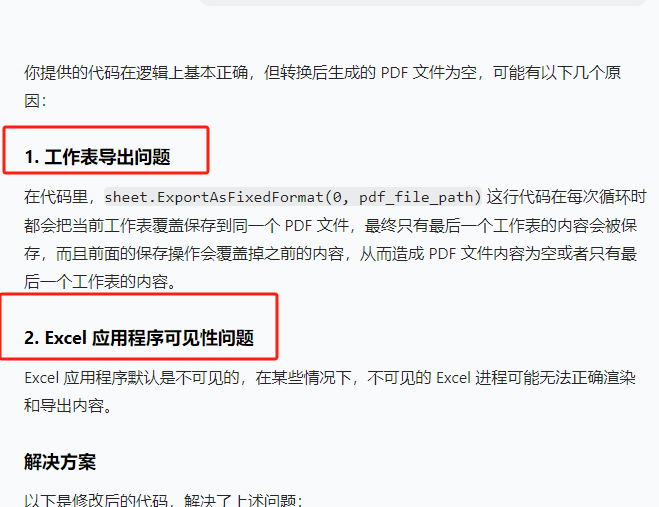
from reportlab.lib.units import inchdef convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path):try:# 创建 Excel 应用程序对象excel = win32.gencache.EnsureDispatch('Excel.Application')# 使 Excel 应用程序可见(可选,有助于调试)excel.Visible = True# 打开 Excel 文件workbook = excel.Workbooks.Open(xlsx_file_path)# 保存所有工作表为一个 PDFworkbook.ExportAsFixedFormat(0, pdf_file_path)# 关闭工作簿和 Excel 应用程序workbook.Close(SaveChanges=False)excel.Quit()print(f"成功将 {xlsx_file_path} 转换为 {pdf_file_path}")except Exception as e:print(f"转换 {xlsx_file_path} 时出错: {e}")def create_cover_page_with_header(pdf_path):c = canvas.Canvas(pdf_path, pagesize=letter)# 设置字体和字号c.setFont('Helvetica', 12)# 页眉文本header_text = "111111"# 计算文本宽度text_width = c.stringWidth(header_text, 'Helvetica', 12)# 页眉位置(居中)x = (letter[0] - text_width) / 2y = letter[1] - 0.5 * inch# 绘制页眉文本c.drawString(x, y, header_text)# 绘制页眉下方的段落框线c.line(0.5 * inch, y - 2, letter[0] - 0.5 * inch, y - 2)c.save()def merge_pdfs(source_folder, output_pdf):pdf_writer = PdfWriter()# 遍历源文件夹中的所有 PDF 文件for root, dirs, files in os.walk(source_folder):for file in sorted(files):if file.endswith('.pdf'):pdf_path = os.path.join(root, file)pdf_reader = PdfReader(pdf_path)for page in pdf_reader.pages:pdf_writer.add_page(page)# 创建带有页眉的封面页cover_pdf_path = 'cover_with_header.pdf'create_cover_page_with_header(cover_pdf_path)cover_pdf_reader = PdfReader(cover_pdf_path)# 将封面页添加到合并后的 PDF 开头pdf_writer.insert_page(cover_pdf_reader.pages[0], 0)# 保存合并后的 PDFwith open(output_pdf, 'wb') as out:pdf_writer.write(out)print(f"成功将 {source_folder} 中的所有 PDF 合并为 {output_pdf}")# 删除临时封面页 PDFos.remove(cover_pdf_path)def main():path = r'C:\Users\jg2yXRZ\OneDrive\桌面\EXCEL表格打印'# 定义源文件夹路径source_folder = path + r'\00合并'# 定义目标文件夹路径target_folder = path + r'\01pdf'# 定义合并后的 PDF 输出路径merged_pdf_path = path + r'\merged_pdfs.pdf'# 检查源文件夹是否存在if not os.path.exists(source_folder):print(f"源文件夹 {source_folder} 不存在。")return# 如果目标文件夹不存在,则创建它if not os.path.exists(target_folder):os.makedirs(target_folder)# 遍历源文件夹中的所有文件for root, dirs, files in os.walk(source_folder):for file in files:if file.endswith(('.xlsx', '.xls')):xlsx_file_path = os.path.join(root, file)pdf_file_name = os.path.splitext(file)[0] + '.pdf'pdf_file_path = os.path.join(target_folder, pdf_file_name)convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path)# 合并目标文件夹中的所有 PDF 文件merge_pdfs(target_folder, merged_pdf_path)if __name__ == "__main__":main()结果:新建一页空白,添加了页眉,后面的每页统计表pdf都没有加到页眉

换了一个思路问豆包,结果还是一样的,只有第一页加了页眉
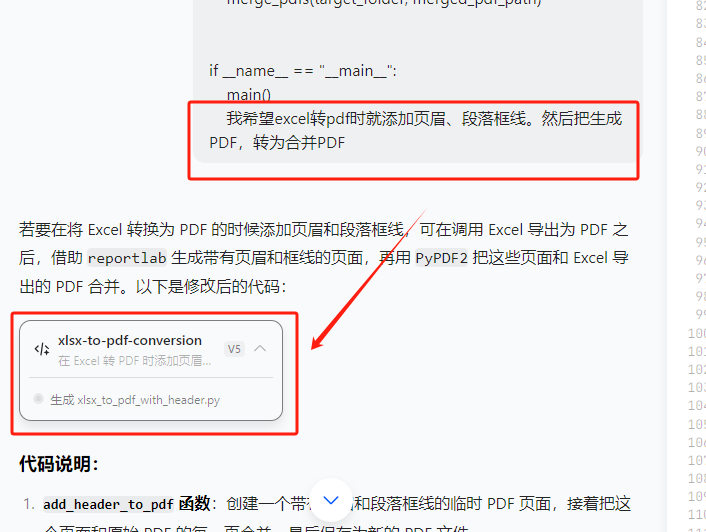
第2次尝试,deepseek
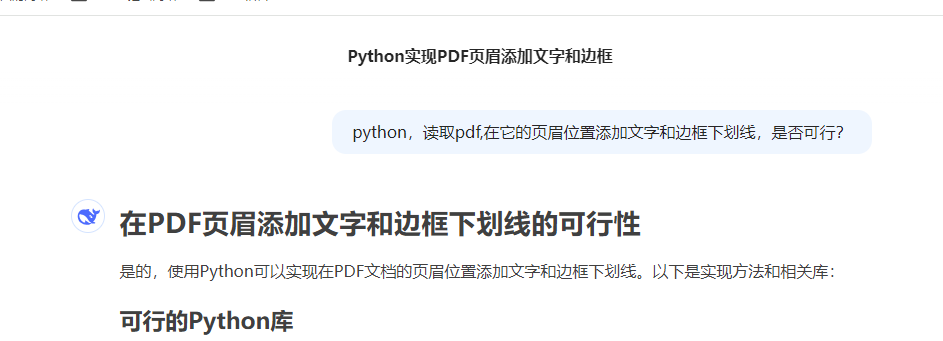
import fitz # PyMuPDFdef add_header_with_border(input_pdf, output_pdf, header_text):doc = fitz.open(input_pdf)for page in doc:# 获取页面尺寸page_rect = page.rectwidth = page_rect.width# 创建页眉矩形区域 (顶部2cm高)header_rect = fitz.Rect(0, 0, width, 50)# 添加下划线边框 (1pt粗)page.draw_rect(header_rect, color=(0, 0, 0), width=1)# 在边框下方添加一条细线作为下划线page.draw_line(fitz.Point(0, 48), fitz.Point(width, 48), color=(0, 0, 0), width=0.5)# 添加页眉文本 (居中)text = header_textfont_size = 12text_rect = fitz.Rect(0, 10, width, 30)page.insert_textbox(text_rect,text,fontsize=font_size,fontname="helv",color=(0, 0, 0),align=1 # 1=居中)doc.save(output_pdf)doc.close()# 使用示例
add_header_with_border("input.pdf", "output.pdf", "这是页眉文字")把这个代码和之前的excle转PDF 合并一起
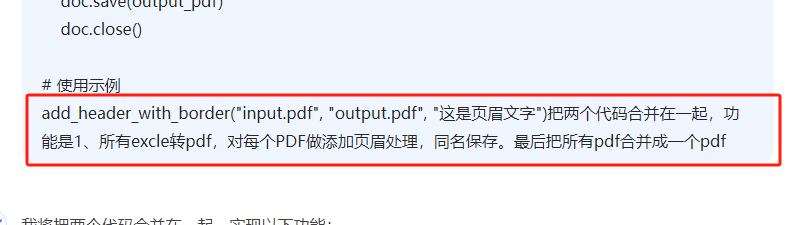
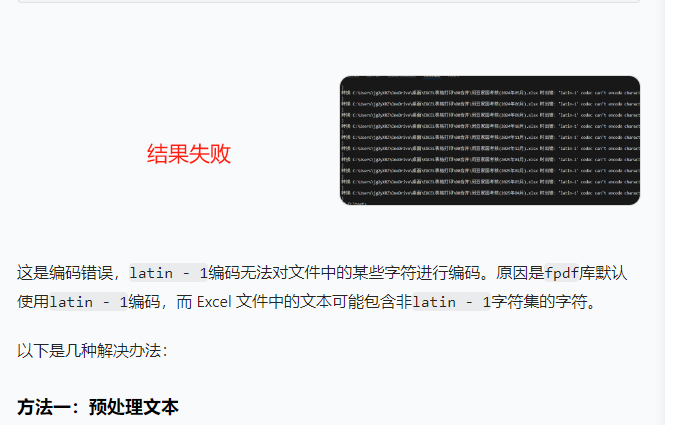
很幸运这个写出来代码运行成功了,但是页眉是?号(非汉字),而且画了一整个黑框。

继续调整问题
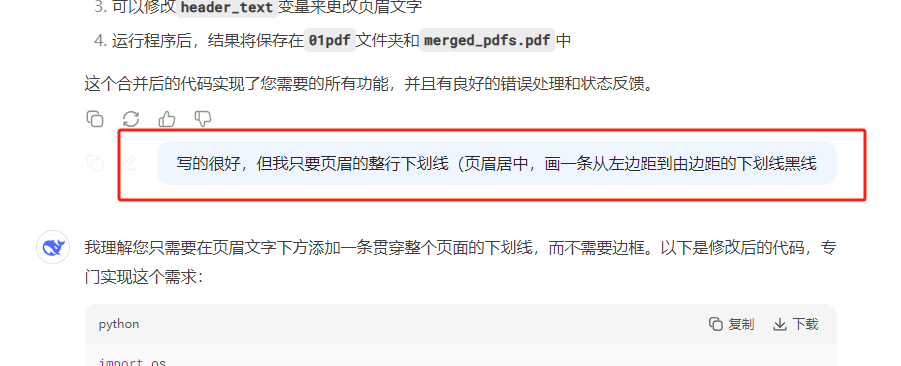 、
、
这次每页PDF都有页码了,不过下划线在页眉的上面

最后问一次


正确代码
'''
20250504闵豆EXCLE转pdf,加页眉+下划线
豆包、阿夏
20250504
'''
import os
import win32com.client as win32
from PyPDF2 import PdfReader, PdfWriter
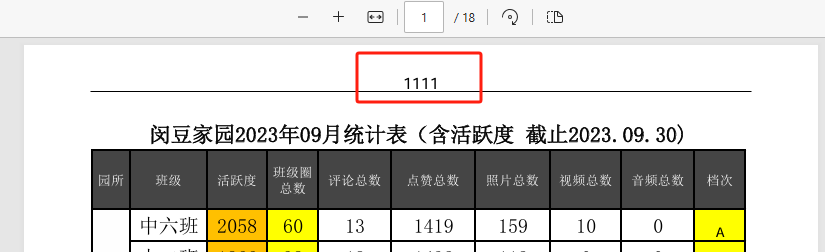
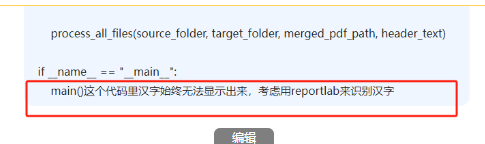
import fitz # PyMuPDFdef convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path):"""将Excel文件转换为PDF"""try:excel = win32.gencache.EnsureDispatch('Excel.Application')excel.Visible = Falseworkbook = excel.Workbooks.Open(xlsx_file_path)workbook.ExportAsFixedFormat(0, pdf_file_path)workbook.Close(SaveChanges=False)excel.Quit()print(f"成功将 {xlsx_file_path} 转换为 {pdf_file_path}")return Trueexcept Exception as e:print(f"转换 {xlsx_file_path} 时出错: {e}")return Falsedef add_header_to_pdf(input_pdf, output_pdf, header_text):"""为PDF添加页眉(文字+下方下划线)"""try:doc = fitz.open(input_pdf)for page in doc:# 获取页面尺寸page_rect = page.rectwidth = page_rect.widthleft_margin = 50 # 左边距right_margin = width - 50 # 右边距# 先添加页眉文本 (居中)text = header_textfont_size = 12text_rect = fitz.Rect(0, 20, width, 40) # 文本区域# 插入文本并获取文本高度text_height = page.insert_textbox(text_rect,text,fontsize=font_size,fontname="helv",color=(0, 0, 0),align=1 # 1=居中)# 在文本下方添加下划线# 计算下划线位置(文本底部+2pt)underline_y = 20 + (40 - 20 - text_height) + 2page.draw_line(fitz.Point(left_margin, underline_y),fitz.Point(right_margin, underline_y),color=(0, 0, 0),width=0.8 # 线宽)doc.save(output_pdf)doc.close()print(f"成功为 {input_pdf} 添加页眉")return Trueexcept Exception as e:print(f"为 {input_pdf} 添加页眉时出错: {e}")return Falsedef merge_pdfs(source_folder, output_pdf):"""合并所有PDF文件"""try:pdf_writer = PdfWriter()# 按文件名排序添加所有PDF文件pdf_files = sorted([f for f in os.listdir(source_folder) if f.endswith('.pdf')])for pdf_file in pdf_files:pdf_path = os.path.join(source_folder, pdf_file)pdf_reader = PdfReader(pdf_path)for page in pdf_reader.pages:pdf_writer.add_page(page)# 保存合并后的PDFwith open(output_pdf, 'wb') as out:pdf_writer.write(out)print(f"成功合并所有PDF为 {output_pdf}")return Trueexcept Exception as e:print(f"合并PDF时出错: {e}")return Falsedef process_all_files(source_folder, target_folder, merged_pdf_path, header_text):"""处理所有文件:转换、添加页眉、合并"""if not os.path.exists(source_folder):print(f"源文件夹 {source_folder} 不存在。")return Falseos.makedirs(target_folder, exist_ok=True)for root, dirs, files in os.walk(source_folder):for file in files:if file.endswith(('.xlsx', '.xls')):xlsx_path = os.path.join(root, file)pdf_name = os.path.splitext(file)[0] + '.pdf'pdf_path = os.path.join(target_folder, pdf_name)if convert_xlsx_to_pdf(xlsx_path, pdf_path):temp_pdf = os.path.join(target_folder, f"temp_{pdf_name}")if add_header_to_pdf(pdf_path, temp_pdf, header_text):os.remove(pdf_path)os.rename(temp_pdf, pdf_path)return merge_pdfs(target_folder, merged_pdf_path)def main():base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\EXCEL表格打印'source_folder = os.path.join(base_path, '00合并')target_folder = os.path.join(base_path, '01pdf')merged_pdf_path = os.path.join(base_path, 'merged_pdfs.pdf')header_text = "上海市XX区XX幼儿园" # 页眉文本process_all_files(source_folder, target_folder, merged_pdf_path, header_text)if __name__ == "__main__":main()汉字不显示
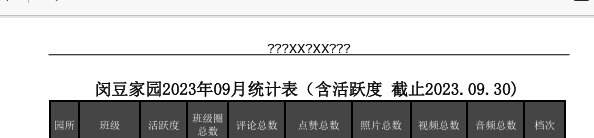

如果是数字、字母,可以显示

继续修改
中间又用豆包、智谱清言写了十几次都不成功。其中提到
-
替代方案:
- 如果fitz库无法解决问题,可以考虑使用其他库,如
ReportLab或WeasyPrint,这些库对中文支持较好。
- 如果fitz库无法解决问题,可以考虑使用其他库,如
感觉fitz识别汉字很差。考虑试试reportlab和WeasyPrint识别汉字能力好。
最后把可以显示数字页眉的代码贴入deepseek,加了ReportLab的提示,就像xlsx转pdf时要求必须用win32转
终于成功了
'''
20250504 闵豆EXCEL转PDF,加页眉(汉字中文、英文、字母+下划线)
豆包、智谱清言、deepseek、阿夏
20250504
'''import os
import win32com.client as win32
from PyPDF2 import PdfReader, PdfWriter
import fitz # PyMuPDF
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
import iodef convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path):"""将Excel文件转换为PDF"""try:excel = win32.gencache.EnsureDispatch('Excel.Application')excel.Visible = Falseworkbook = excel.Workbooks.Open(xlsx_file_path)workbook.ExportAsFixedFormat(0, pdf_file_path)workbook.Close(SaveChanges=False)excel.Quit()print(f"成功将 {xlsx_file_path} 转换为 {pdf_file_path}")return Trueexcept Exception as e:print(f"转换 {xlsx_file_path} 时出错: {e}")return Falsedef add_header_to_pdf(input_pdf, output_pdf, header_text):"""为PDF添加页眉(使用reportlab生成带汉字的页眉)"""try:# 注册中文字体(确保字体文件存在)font_path = r'C:\Windows\Fonts\simsun.ttc' # 宋体if not os.path.exists(font_path):font_path = r'C:\Windows\Fonts\STSONG.TTF' # 备用路径if not os.path.exists(font_path):print("❌ 错误:未找到宋体字体文件!")return Falsepdfmetrics.registerFont(TTFont('SimSun', font_path))# 读取原始PDForiginal_pdf = PdfReader(input_pdf)pdf_writer = PdfWriter()for page in original_pdf.pages:# 获取页面尺寸media_box = page.mediaboxwidth = float(media_box[2])height = float(media_box[3])# 创建一个临时PDF用于页眉packet = io.BytesIO()can = canvas.Canvas(packet, pagesize=(width, height))# 设置字体和大小can.setFont('SimSun', 12)# 计算文本宽度以居中text_width = can.stringWidth(header_text, 'SimSun', 12)# 绘制页眉文本(居中)can.drawString((width - text_width) / 2, height - 20, header_text)# 绘制下划线can.line(50, height - 25, width - 50, height - 25)can.save()# 将页眉合并到原始页面packet.seek(0)header_pdf = PdfReader(packet)page.merge_page(header_pdf.pages[0])pdf_writer.add_page(page)# 保存结果with open(output_pdf, 'wb') as output_file:pdf_writer.write(output_file)print(f"✅ 成功为 {input_pdf} 添加页眉")return Trueexcept Exception as e:print(f"❌ 添加页眉时出错: {e}")return Falsedef merge_pdfs(source_folder, output_pdf):"""合并所有PDF文件"""try:pdf_writer = PdfWriter()# 按文件名排序添加所有PDF文件pdf_files = sorted([f for f in os.listdir(source_folder) if f.endswith('.pdf')])for pdf_file in pdf_files:pdf_path = os.path.join(source_folder, pdf_file)pdf_reader = PdfReader(pdf_path)for page in pdf_reader.pages:pdf_writer.add_page(page)# 保存合并后的PDFwith open(output_pdf, 'wb') as out:pdf_writer.write(out)print(f"成功合并所有PDF为 {output_pdf}")return Trueexcept Exception as e:print(f"合并PDF时出错: {e}")return Falsedef process_all_files(source_folder, target_folder, merged_pdf_path, header_text):"""处理所有文件:转换、添加页眉、合并"""if not os.path.exists(source_folder):print(f"源文件夹 {source_folder} 不存在。")return Falseos.makedirs(target_folder, exist_ok=True)for root, dirs, files in os.walk(source_folder):for file in files:if file.endswith(('.xlsx', '.xls')):xlsx_path = os.path.join(root, file)pdf_name = os.path.splitext(file)[0] + '.pdf'pdf_path = os.path.join(target_folder, pdf_name)if convert_xlsx_to_pdf(xlsx_path, pdf_path):temp_pdf = os.path.join(target_folder, f"temp_{pdf_name}")if add_header_to_pdf(pdf_path, temp_pdf, header_text):os.remove(pdf_path)os.rename(temp_pdf, pdf_path)return merge_pdfs(target_folder, merged_pdf_path)def main():base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\EXCEL表格打印'source_folder = os.path.join(base_path, '00合并')target_folder = os.path.join(base_path, '01pdf')merged_pdf_path = os.path.join(base_path, 'merged_pdfs.pdf')header_text = "上海市CY区abc123幼儿园" # 页眉文本(支持中文)process_all_files(source_folder, target_folder, merged_pdf_path, header_text)if __name__ == "__main__":main()最后效果:
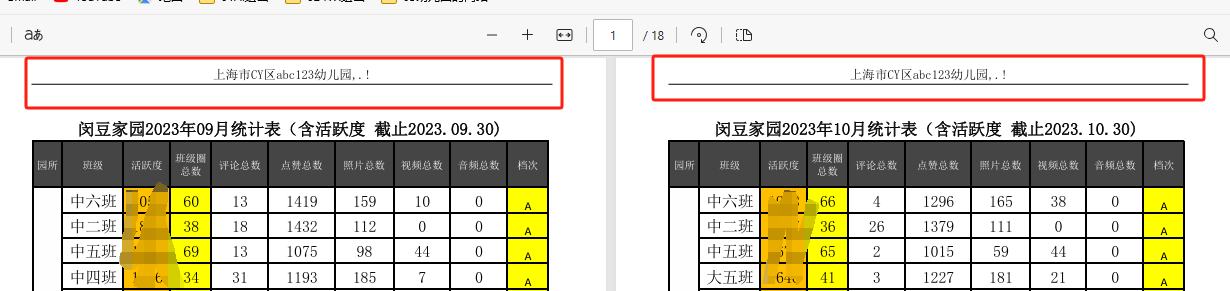
汉字中文、英文大写、英文小写、数字、符号都可以显示成页眉。整段下框线(下划线)也有
单页PDF的页眉

所有PDF都有页眉了
合并打印
感悟:
为了添加pdf的汉字页眉,四个AI工具,花了4个小时,太累了。还是乖乖的把EXCEL模版里面添加好页眉吧!

但是EXCEL页眉左中右,如果我设置居中显示,最多只能中间部分有下划线,不能画出左边距到右边距地一根横线

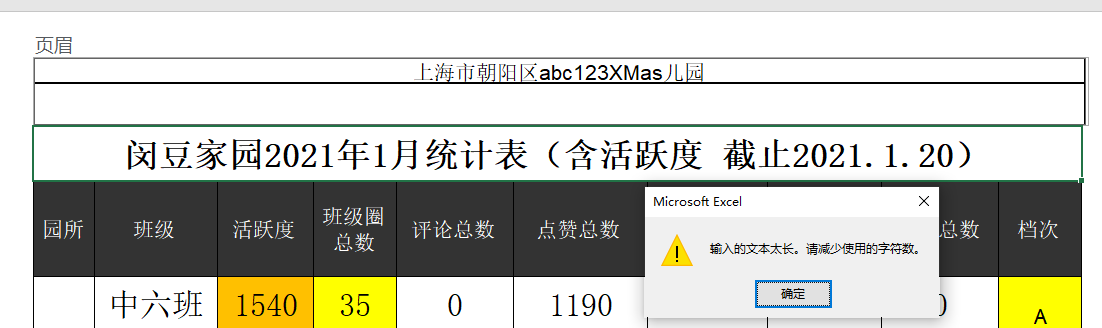
我从左边的页眉区输入学校,然后按了很多空格,的确页眉边长,有下划线了,
但是保存时提示太长,不给保存
调到正好长度(下划线不超过两端)

预览时显示制作右侧中策有下划线
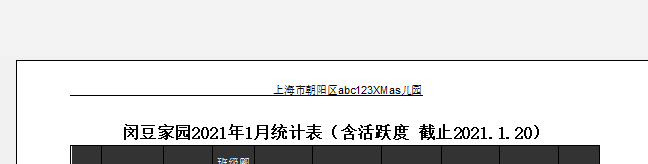
在最后加一个逗号,改成白色逗号
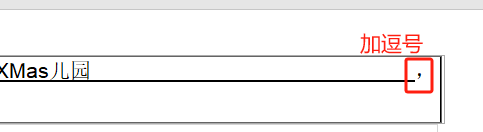

打印时,勉强可以算左右整段下划线
