网站制作软件都是什么软件在线生成个人网站app
目录
- 引言
- 一、语音识别
- 1.声学模型
- 2.语言模型
- 3.词典
- 二、声音识别(声纹识别)
- 三、语音识别、声音识别、语义识别的区别
- 四、总结
引言
咋一看这个标题是不是很多小伙伴都迷糊了,哇哈,这两个不是一样的吗?

结论是,这两者是不一样的!!

前段时间小马分析了《如何实现语音智能客服》,也介绍了其中语音转文字部分的自动语音识别ASR。但后来小马又在薅一本微证书《智能声音识别》,课程之前也一直以为“语音”、“声音”不就都是一码事吗,然后学习过程中发现声音识别和语音识别的区别还是需要理一理的。
一、语音识别
我们引用之前整理的《如何实现语音智能客服》内容,语音转文字部分的自动语音识别ASR构成约等于AM声学模型(语音识别成文字,深度神经网络算法对各种声学现象的训练) + LM语言模型(文本生成) + 词典(两模型建立联系)。
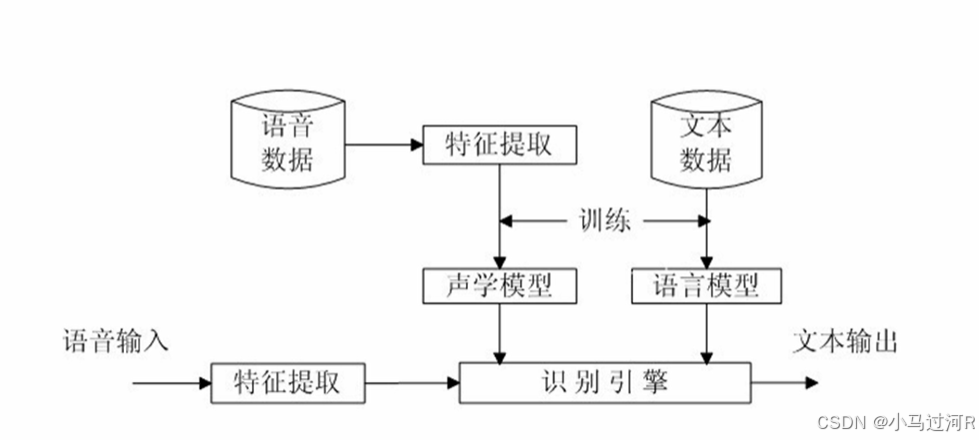
1.声学模型
底层是深度神经网络算法,通过对各种声学现象的学习训练,声学模型选择声学现象对应最大概率的声学单元输出。通过学习不同的声学现象提炼出共性的部分,训练一个通用的声学模型。
所以说人工智能的本质就是概率学和统计学。
声学现象:
主要包括声音的三大要素:响度、音调、音色。举例来说,同一个人在不同情绪下(如高兴和生气)说同一句话,其声学现象会有所不同;感冒时与未感冒时的声学现象也会有所差异。此外,不同人、不同年龄、不同性别、不同环境、不同心情、不同收音设备等因素都会导致声学现象的不同。
声学单元:
是声学模型底层的建模单元,不同模型可能采用不同的建模单元,但这些差异对最终的识别结果并无影响。以音节(不含音调)为建模单元为例,建模单元可以是“wo”、“xue”、“ni”、“hao”、“tong”、“shi”等。也可以通俗理解为NLP的单词单元。
2.语言模型
语言模型是纯文本层面的模型,与声音的三要素无关,它对应的是文本的词序列条件概率。其原理是基于文本统计,即相关文本数据量越多,覆盖面越广,模型就越接近真实使用场景。
3.词典
声学模型和语言模型的联系:
声学模型和语言模型通过词典联系起来。
语音识别的目的:识别语音的内容。并以电脑自动将人类的语音内容转换为相应的文字。
以上就是整个语音识别的过程和原理。
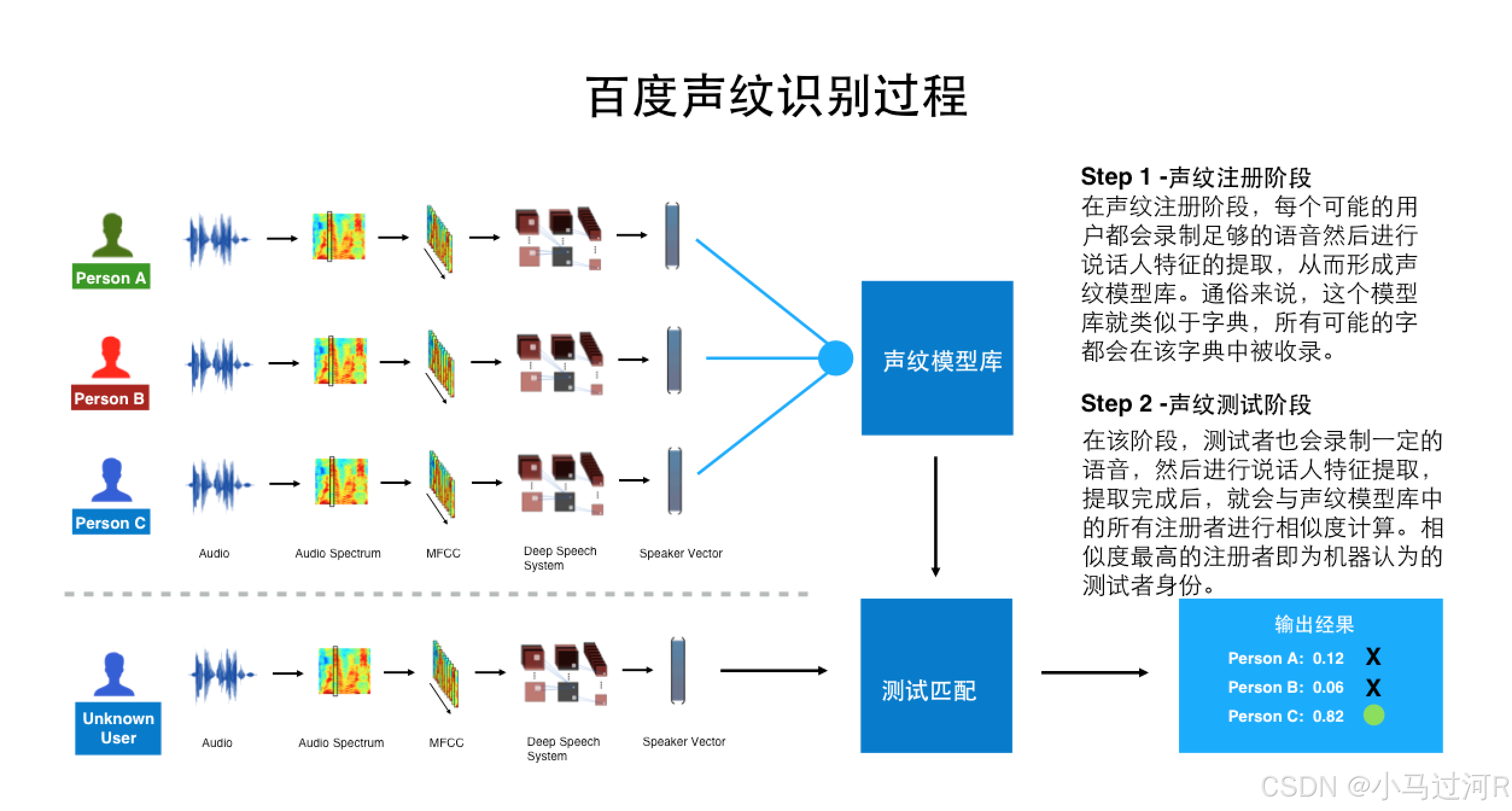
二、声音识别(声纹识别)
声音识别又叫声纹识别,声纹识别是一种通过比对和分析个体声音的独特特征(如音调、音色等)来验证或识别说话者身份的生物识别技术。
基本原理:该技术提取并存储个体的声纹特征,形成独特的“声音指纹”。在验证过程中,系统会将输入的语音信号与已存储的声纹进行比对,以确认说话者的身份。
不同的任务和应用会使用不同的声音识别技术,如缩小刑侦范围时可能需要辨认技术,而银行交易时则需要确认技术。例如:通过语音波形中反映说话人的语音参数,进而连接到声纹库,鉴别人的身份。所承载的功能特点和人脸识别是一样的,都是为了证明人的身份。
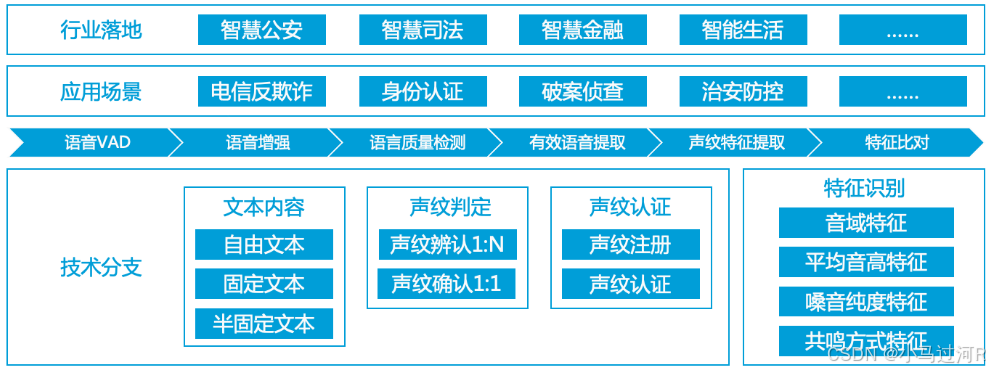
核心原理:
1.信号采集
通过麦克风等设备捕捉声波,并将其转换为电信号,再数字化为计算机可处理的音频数据。 采样率、量化位数等参数影响声音的清晰度和质量。 2.预处理
滤波:去除背景噪声,增强有效信号。
端点检测:确定语音信号的起止点,分割有效片段。
分帧与加窗:将连续声音分割为短时帧(如20-30ms/帧),减少频谱失真。
3. 特征提取
梅尔频率倒谱系数(MFCC):模拟人耳对频率的感知,提取音色、音调等特征。
线性预测编码(LPC):描述声音的频谱包络。
频谱分析:通过短时傅里叶变换(STFT)获取频域信息。
4. 模式匹配
声学模型:使用隐马尔可夫模型(HMM)或深度学习(如CNN、RNN)匹配声音特征与预训练模型。
语言模型(语音识别场景):结合上下文优化文本输出。
模板匹配(如声纹识别):对比声纹库中的特征,确认说话人身份。
5.后处理
通过语法检查、语义理解等优化结果。 例如音乐识别中,匹配音频指纹与数据库以确定歌曲。
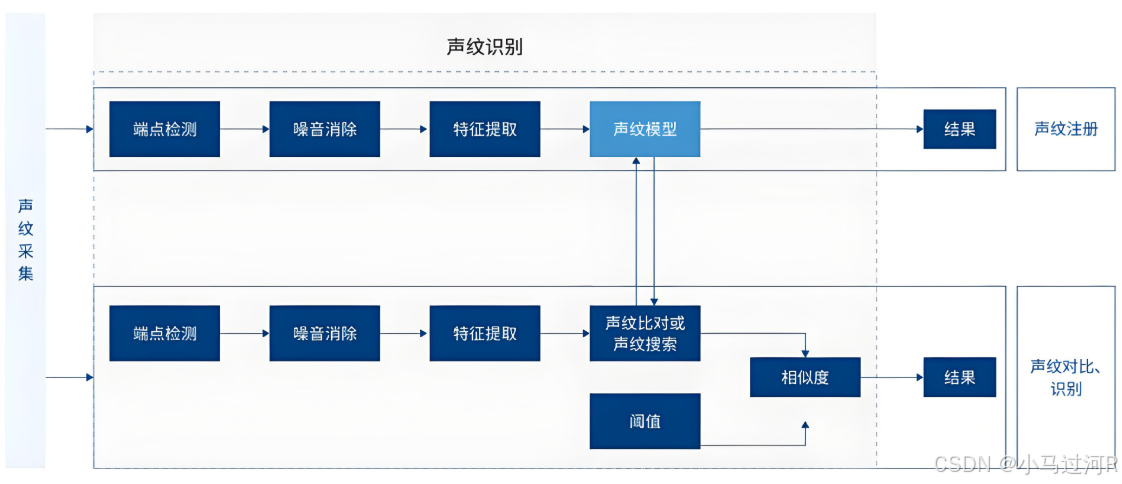
从核心原理中第3和4的内容我们甚至可以清晰地看到,声音识别和语音识别在原理上一样,都是通过对采集到的语音信号进行分析和处理,提取相应的特征或建立相应的模型,然后据此做出判断。但二者的根本目的、提取的特征、建立的模型是不一样的。
三、语音识别、声音识别、语义识别的区别
声音识别、语音识别、语义识别的区别:
语音识别:该技术的目的是识别语音的内容,电脑会自动将人类的语音内容转换为相应的文字。
声音识别:该技术旨在识别说话人的身份,也被称为说话人识别,是生物识别技术的一种。
语义识别:该技术是对语音识别出来的内容进行语义理解和纠正,例如在同声翻译机中的应用。
四、总结
综上,声音识别不注重语音信号的语义,而是从语音信号中提取个人声纹特征,挖掘出包含在语音信号中的个性因素。
语音识别注重识别语音内容,声音识别(声纹识别)注重提取并识别个人声纹特征。
声音识别的准确性依赖于信号质量、特征提取算法及模型训练数据量。例如,听歌识曲通过短时音频指纹匹配实现快速识别,而声纹识别则利用音色、频率等生物特征进行身份验证。
- 留彩蛋是一种传统^^