海沧建设网站多少网站优化排名公司
提纲:
转换目标 dialect
转换的模式
部分地降低
部分下降的注意事项
完成 Toy 示例
利用 Affine dialect 的优化
到了当前这个阶段,我们热切期待生成实际的代码,看到我们的 Toy 编程语言变得生动,我们将使用 LLVM 生成代码,但是,如果这里仅仅展示 LLVM builder interface并不会非常令人兴奋。取而代之的是,我们将会通过在同一个函数中共存混合的 dialect,以便展示怎么去逐步地让程序下降。
为了让事情变得更有趣,本章里,我们将会复用在优化仿射变换的dialect - Affine - 中现存的优化实现。这个 dialect 是为了计算密集的程序片段而定制的,而且它是有限制的:例如,Affine 并不能支持对我们的内建的 toy.print 的表示,而且它也不应该支持。取而代之的是,我们可以让 Toy 程序中计算密集的程序片段以 Affine 为目标,而且在下一章中直接以 LLVM IR 为目标来下降 toy.print。因为是部分下降,我们将从参与 Toy 运算的 TensorType 下降到 MemRefType,它是通过仿射循环嵌套来索引的。张量表示数据的一个抽象的数值型性的序列,也就是说它们可以不躺在任何的内存中。另一方面,MemRefs 表示更低层级的缓冲区访问,因为它们具体地引用到了一片内存区域。
Dialect 转换
MLIR 有很多不同的 dialects,所以,在它们之间构建一个统一的转换框架是非常重要的。
这就是 DialectConversion framework 所扮演的角色。这个 framework 允许将一组 illegal 的 operations 变换成为一组 legal 的operations。
为了使用这个 framework,我们需要题哦给你过两个件事情,以及可选的第三件事情:
. 一个转换目标
。这是一个正式的规范,说明这个转换中合法的operations 或 dialects。
不合法的 operations 将需要重写模式以便进行合法化。
. 一组重写模式
。这是一组用于将非法 operations 变换为由0个或多个合法 operations 的模式。
. 可选地,一个类型转换器
。如果提供一个类型变换器,这将用于参数块的类型。在我们的变换中不需要这个变换器。
转换目标 dialect
按照我们的意图,我们想把计算密集的 Toy operations 变换成
由 Affine,Arith,Func 和 MemRef 等dialects 中的 operations 构成的混合体,然后才能做更深入的优化。
为了能够开始做代码下降,我们先定义我们的转换目标:
void ToyToAffineLoweringPass::runOnOperation() {// The first thing to define is the conversion target. This will define the// final target for this lowering.mlir::ConversionTarget target(getContext());// We define the specific operations, or dialects, that are legal targets for// this lowering. In our case, we are lowering to a combination of the// `Affine`, `Arith`, `Func`, and `MemRef` dialects.target.addLegalDialect<affine::AffineDialect, arith::ArithDialect,func::FuncDialect, memref::MemRefDialect>();// We also define the Toy dialect as Illegal so that the conversion will fail// if any of these operations are *not* converted. Given that we actually want// a partial lowering, we explicitly mark the Toy operations that don't want// to lower, `toy.print`, as *legal*. `toy.print` will still need its operands// to be updated though (as we convert from TensorType to MemRefType), so we// only treat it as `legal` if its operands are legal.target.addIllegalDialect<ToyDialect>();target.addDynamicallyLegalOp<toy::PrintOp>([](toy::PrintOp op) {return llvm::none_of(op->getOperandTypes(),[](Type type) { return type.isa<TensorType>(); });});...
}上文中,我们先将 toy dialect 设置为illegal,并且设置 toy.print 为legal。我们也可以用其他的顺序做这件事。单独的 operations 总是优先于更宽泛的 dialect 的定义,所有,顺序并不重要。从 ConversionTarget::getOpInfo 可以看到详情。
变换的模式
定义了变换的目标之后,我们可以定义把illegal operations 变换成 legal operations。跟第三章介绍的 canonicalization framework 很像,DialectConversion framework 也使用 RewritePatterns 来实施变换逻辑。这些模式可能是之前看到的 RewritePatterns 或者是指定给 ConversionPattern framework 的这种新类型的模式。ConversionPatterns 有别于传统的 RewriePatterns,在 ConversionPatterns 中,它们接受一个额外的 operands 参数,其中包含着已经被重映射或替换的 operands。在处理类型转换时会用到这些,因为这个模式将会在新类型的数值上做运算,但是数值与老的参数相同【值不变,类型变】。对于我们的代码下降,这种不变性将会非常有用,因为它是从作用在当前的 TensorType 转移到 MemRefType上。让我们一起看看对 toy.transpose operation 的代码片段:
/// Lower the `toy.transpose` operation to an affine loop nest.
struct TransposeOpLowering : public mlir::ConversionPattern {TransposeOpLowering(mlir::MLIRContext *ctx): mlir::ConversionPattern(TransposeOp::getOperationName(), 1, ctx) {}/// Match and rewrite the given `toy.transpose` operation, with the given/// operands that have been remapped from `tensor<...>` to `memref<...>`.llvm::LogicalResultmatchAndRewrite(mlir::Operation *op, ArrayRef<mlir::Value> operands,mlir::ConversionPatternRewriter &rewriter) const final {auto loc = op->getLoc();// Call to a helper function that will lower the current operation to a set// of affine loops. We provide a functor that operates on the remapped// operands, as well as the loop induction variables for the inner most// loop body.lowerOpToLoops(op, operands, rewriter,[loc](mlir::PatternRewriter &rewriter,ArrayRef<mlir::Value> memRefOperands,ArrayRef<mlir::Value> loopIvs) {// Generate an adaptor for the remapped operands of the TransposeOp.// This allows for using the nice named accessors that are generated// by the ODS. This adaptor is automatically provided by the ODS// framework.TransposeOpAdaptor transposeAdaptor(memRefOperands);mlir::Value input = transposeAdaptor.input();// Transpose the elements by generating a load from the reverse// indices.SmallVector<mlir::Value, 2> reverseIvs(llvm::reverse(loopIvs));return rewriter.create<mlir::AffineLoadOp>(loc, input, reverseIvs);});return success();}
};现在我们可以准备在下降过程中使用的模式列表:
void ToyToAffineLoweringPass::runOnOperation() {...// Now that the conversion target has been defined, we just need to provide// the set of patterns that will lower the Toy operations.mlir::RewritePatternSet patterns(&getContext());patterns.add<..., TransposeOpLowering>(&getContext());...部分地下降
一旦定义了模式,我们就可以做实际的下降了。DialectConversion framework 提供了几个不同的下降样式, 但是,
对于我们的意图而言,我们将会执行一个部分下降,因为这时我们不会对 toy.print 做变换。
void ToyToAffineLoweringPass::runOnOperation() {...// With the target and rewrite patterns defined, we can now attempt the// conversion. The conversion will signal failure if any of our *illegal*// operations were not converted successfully.if (mlir::failed(mlir::applyPartialConversion(getOperation(), target, patterns)))signalPassFailure();
}部分下降的设计考量要素
在查看我们做下降的结果之前,是展开讨论部分下降中潜在的设计考量要素。在我们的下降中,我们把值的类型,TensorType,变换成为buffer类的被分配的类型,MemRefType。然而,考虑到我们不对 toy.print operation 做下降,我们需要临时地连接这两个世界。有好几个方法可以做到这一点,每一种方法都有其对应的折中:
. 产生从buffer 进行 load 的 operation
选项之一是产生从 buffer 类型加载数据的 load operation,从而实现一个数值类型的实例。这允许 toy.print 这个 operation 的定义保持不变。 这个方法的缺点是,在 affine dialect 伤的优化将被限制,因为,这个 load 实际上将会导致一个深 copy,而且这只有在我们的优化做完了之后才能可见。
. 产生一个新版本的 toy.print,使其可以作用在下降了的数据类型上
另一个可选项是定义另一个更低层级的 toy.print 的变体,使其作用在更低层级的类型上。这个选项的好处是没有向优化器做隐藏的不必要的数据拷贝。 其缺点是需要做额外的 operation 的定义,这个第一个 print operation 的定义在很多方面会重复。 定义一个 ODS 的基class 可以起到简化效果,但是你仍然需要单独地处理这些 operations。
. 升级 toy.print 以便使其可以作用在下降了的数据类型上
第三个选项是升级现有的 toy.print 的定义,使其可以作用在更低层级的类型。这个方法的好处是简单,不需要引发额外的隐藏的拷贝, 并且不需要做另一个 operation 的定义。缺点是它需要在 Toy dialect 中混合一些抽象层级。
为了简单,我们将会在下降中使用第三个选项。这涉及在 PrintOp 的 operation 定义文件中升级operation 的类型约束:
def PrintOp : Toy_Op<"print"> {...// The print operation takes an input tensor to print.// We also allow a F64MemRef to enable interop during partial lowering.let arguments = (ins AnyTypeOf<[F64Tensor, F64MemRef]>:$input);
}完成 Toy 示例
让我们一起看一个具体例子:
toy.func @main() {%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>%2 = toy.transpose(%0 : tensor<2x3xf64>) to tensor<3x2xf64>%3 = toy.mul %2, %2 : tensor<3x2xf64>toy.print %3 : tensor<3x2xf64>toy.return
}随着 affine 下降添加进我们的流水线,我们现在可以生成如下代码:
func.func @main() {%cst = arith.constant 1.000000e+00 : f64%cst_0 = arith.constant 2.000000e+00 : f64%cst_1 = arith.constant 3.000000e+00 : f64%cst_2 = arith.constant 4.000000e+00 : f64%cst_3 = arith.constant 5.000000e+00 : f64%cst_4 = arith.constant 6.000000e+00 : f64// Allocating buffers for the inputs and outputs.%0 = memref.alloc() : memref<3x2xf64>%1 = memref.alloc() : memref<3x2xf64>%2 = memref.alloc() : memref<2x3xf64>// Initialize the input buffer with the constant values.affine.store %cst, %2[0, 0] : memref<2x3xf64>affine.store %cst_0, %2[0, 1] : memref<2x3xf64>affine.store %cst_1, %2[0, 2] : memref<2x3xf64>affine.store %cst_2, %2[1, 0] : memref<2x3xf64>affine.store %cst_3, %2[1, 1] : memref<2x3xf64>affine.store %cst_4, %2[1, 2] : memref<2x3xf64>// Load the transpose value from the input buffer and store it into the// next input buffer.affine.for %arg0 = 0 to 3 {affine.for %arg1 = 0 to 2 {%3 = affine.load %2[%arg1, %arg0] : memref<2x3xf64>affine.store %3, %1[%arg0, %arg1] : memref<3x2xf64>}}// Multiply and store into the output buffer.affine.for %arg0 = 0 to 3 {affine.for %arg1 = 0 to 2 {%3 = affine.load %1[%arg0, %arg1] : memref<3x2xf64>%4 = affine.load %1[%arg0, %arg1] : memref<3x2xf64>%5 = arith.mulf %3, %4 : f64affine.store %5, %0[%arg0, %arg1] : memref<3x2xf64>}}// Print the value held by the buffer.toy.print %0 : memref<3x2xf64>memref.dealloc %2 : memref<2x3xf64>memref.dealloc %1 : memref<3x2xf64>memref.dealloc %0 : memref<3x2xf64>return
}利用 affine 的优化功能
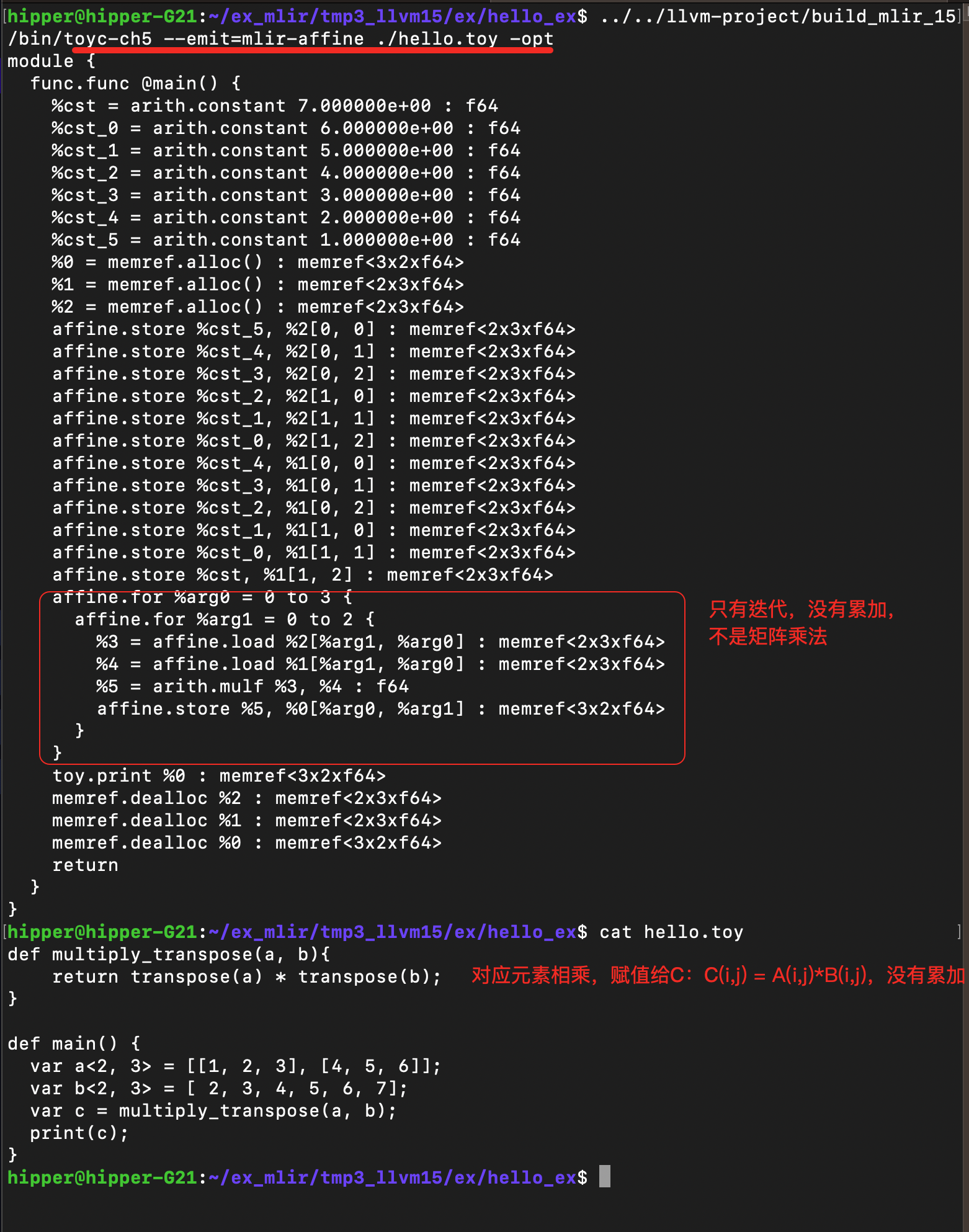
我们朴素的下降是正确的,但是,从效率考量的角度,还留下了更上一层楼的追求。例如,toy.mul的下降生成了一些冗余的loads。让我们尝试添加一些现存的的优化策略到流水线中,帮助清楚这些冗余。添加 LoopFusion 和 AffineScalarReplacement passes 到流水线中,会生成如下的结果:
func.func @main() {%cst = arith.constant 1.000000e+00 : f64%cst_0 = arith.constant 2.000000e+00 : f64%cst_1 = arith.constant 3.000000e+00 : f64%cst_2 = arith.constant 4.000000e+00 : f64%cst_3 = arith.constant 5.000000e+00 : f64%cst_4 = arith.constant 6.000000e+00 : f64// Allocating buffers for the inputs and outputs.%0 = memref.alloc() : memref<3x2xf64>%1 = memref.alloc() : memref<2x3xf64>// Initialize the input buffer with the constant values.affine.store %cst, %1[0, 0] : memref<2x3xf64>affine.store %cst_0, %1[0, 1] : memref<2x3xf64>affine.store %cst_1, %1[0, 2] : memref<2x3xf64>affine.store %cst_2, %1[1, 0] : memref<2x3xf64>affine.store %cst_3, %1[1, 1] : memref<2x3xf64>affine.store %cst_4, %1[1, 2] : memref<2x3xf64>affine.for %arg0 = 0 to 3 {affine.for %arg1 = 0 to 2 {// Load the transpose value from the input buffer.%2 = affine.load %1[%arg1, %arg0] : memref<2x3xf64>// Multiply and store into the output buffer.%3 = arith.mulf %2, %2 : f64affine.store %3, %0[%arg0, %arg1] : memref<3x2xf64>}}// Print the value held by the buffer.toy.print %0 : memref<3x2xf64>memref.dealloc %1 : memref<2x3xf64>memref.dealloc %0 : memref<3x2xf64>return
}这里,我们可以看到冗余的 allocation 被移除了,两个循环嵌套被融合了,并且一些不必要的 loads 被移除了。你可以构建 toyc-ch5 并且自己有一下试验:
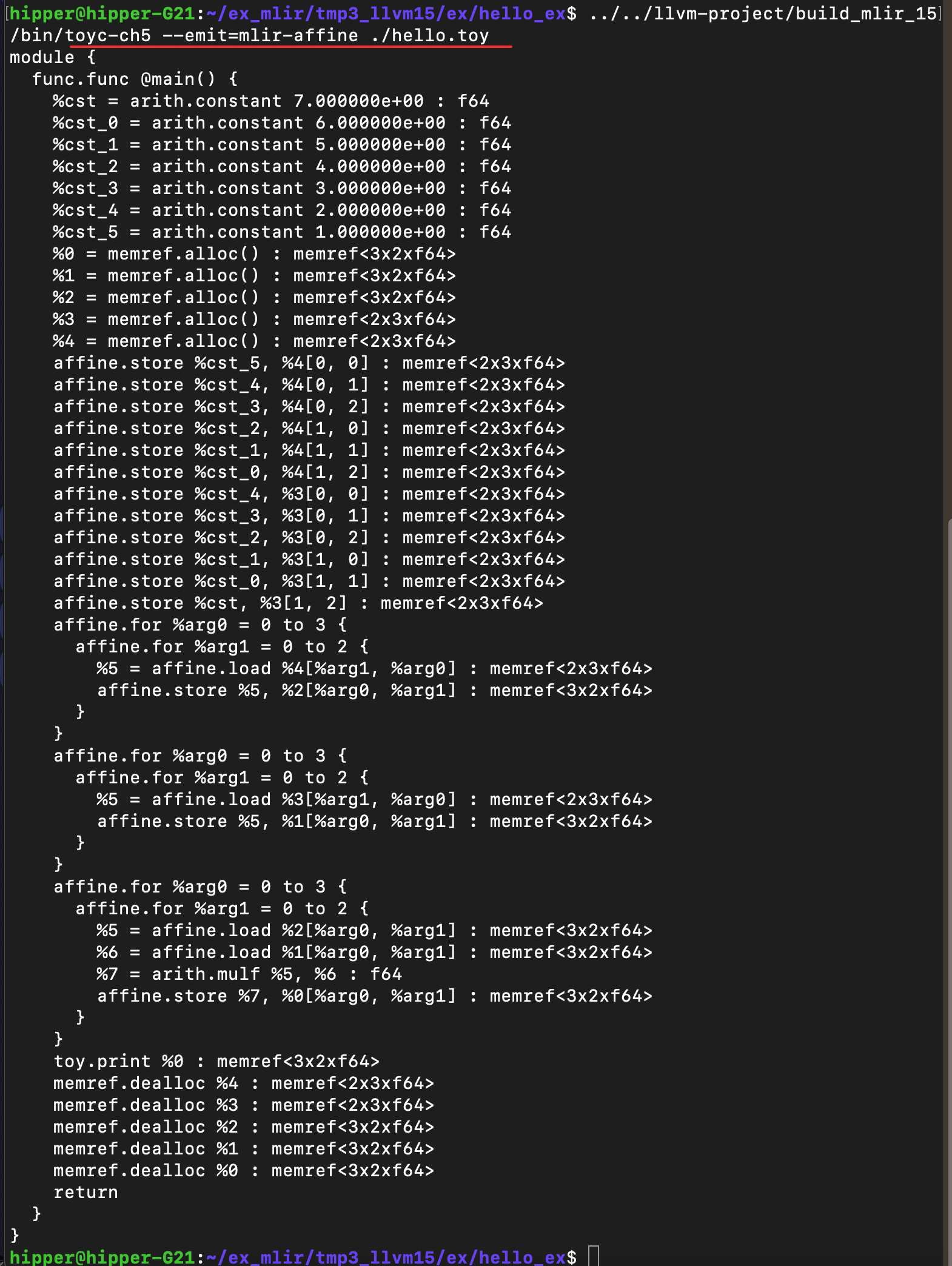
toyc-ch5 test/Examples/Toy/Ch5/affine-lowering.mlir -emit=mlir-affine我们也可以加入 -opt 查看我们的优化效果。
本章中,怀着优化的意图,我们探索了部分下降的一些方面。下一张中,我们将会继续讨论 dialect 变换,是以 LLVM 为目标生成代码。
效果图:
没有 -opt 优化: