渭南网站建设费用明细重庆seo网站建设
🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
概述
GraphRAG 是一款革命性的智能问答系统,巧妙地将知识图谱与检索增强生成技术相结合。就像给AI装上了"概念导航仪",它能够将输入文档转化为立体化的知识网络,在回答用户问题时实现精准的"信息寻宝"。系统融合了自然语言处理、机器学习和图论算法,让答案生成过程既智能又有迹可循。
设计动机
传统检索增强系统就像在图书馆里摸黑找书,常常陷入以下困境:
- 上下文容易在长文档中"迷路"
- 概念之间的关联就像断了线的珍珠
- 决策过程像个黑箱,难以追溯
GraphRAG 的创新之处在于:
- 用知识图谱搭建"概念立交桥",保持信息间的立体关联
- 引入智能导航算法,让信息检索变成"自动驾驶"
- 可视化系统就像给思考过程装上行车记录仪
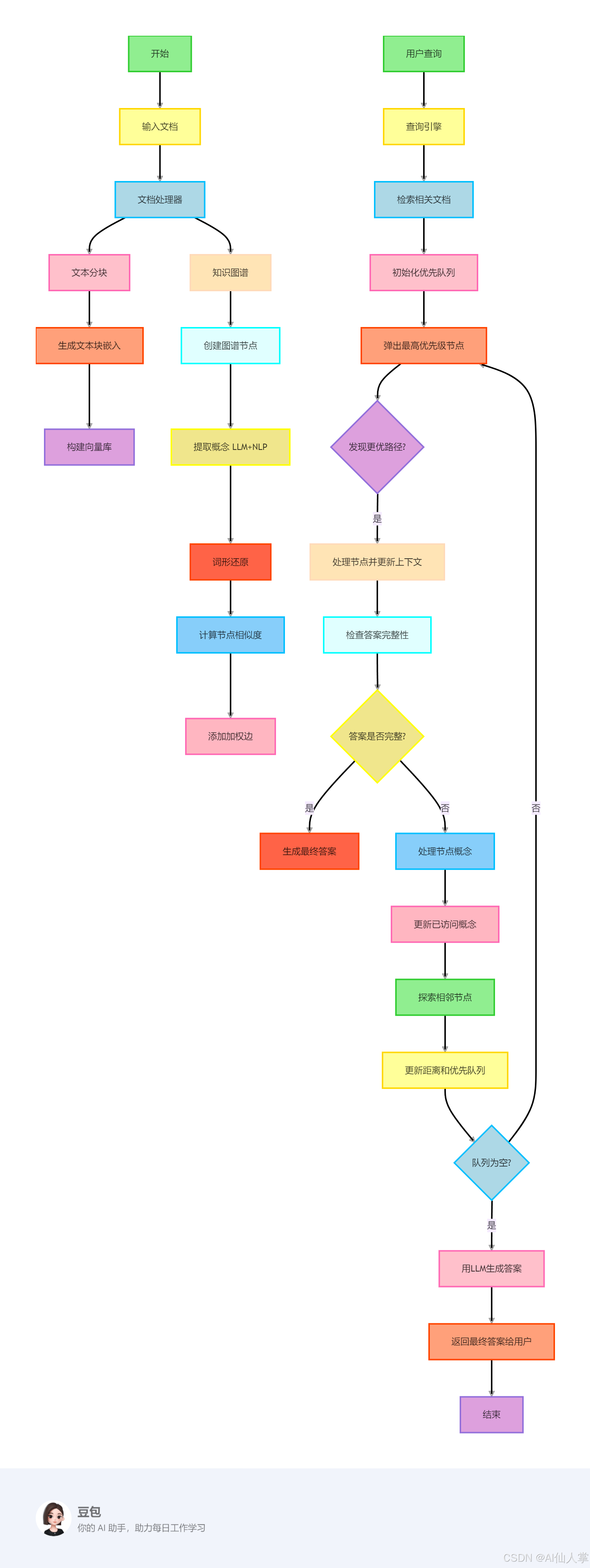
核心组件
- 文档处理器(DocumentProcessor):文档拆解专家,擅长将文档切成营养丰富的"知识块"
- 知识图谱(KnowledgeGraph):架构师,用节点和边搭建概念之间的高速公路网
- 查询引擎(QueryEngine):导航系统,在知识图谱中规划最优解答路径
- 可视化器(Visualizer):灵魂画手,将抽象的知识网络转化为直观的思维导图
实现细节
文档处理流程
- 将文档切成易于消化的知识块(就像把披萨切成小块)
- 为每个知识块生成语义指纹(嵌入向量)
- 建立向量数据库,打造高速语义搜索引擎
知识图谱构建
- 节点:每个知识块化身知识图谱的"城市"
- 边:构建城市之间的"高速公路",基于:
- 语义相似度(城市间的直线距离)
- 共享概念(城市间的贸易往来)
- 边权重:就像道路限速值,决定信息检索的优先路线
智能查询流程
- 用户问题变身"寻宝地图"(生成查询嵌入)
- 初始化优先队列:锁定最相关的"起点城市"
- 类Dijkstra算法导航:
- 按连接强度优先探索(老司机带路)
- 实时评估上下文完整性(检查油箱余量)
- 动态扩展搜索范围(发现新大陆就更新地图)
- 终极答案生成:当知识图谱"燃料"耗尽时,启动大语言模型引擎
可视化呈现
- 节点:知识城市
- 边:彩色高速公路(颜色越深限速越高)
- 遍历路径:红色虚线组成的"最佳路线"
- 起终点标记:绿色起点站 vs 红色终点站
技术优势
- 立体化上下文感知:告别平面化搜索,实现三维知识导航
- 智能路径规划:不是简单关键词匹配,而是概念级语义寻路
- 决策过程透明化:每个答案都附带"行车记录仪"回放
- 弹性知识架构:新知识接入就像给城市扩建新区
- 高效信息检索:优先选择信息高速公路,拒绝乡间小道
结语
GraphRAG 如同给传统检索系统装上了GPS和全景天窗,在保持专业深度的同时,带来了更智能的导航体验和更透明的决策过程。随着知识图谱与语言模型的持续进化,这种"图脑结合"的架构正在开启智能问答的新纪元——让机器不仅知道答案,更懂得答案之间的千丝万缕。
导入依赖库
import networkx as nx
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.prompts import PromptTemplate
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain.callbacks import get_openai_callbackfrom sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import os
import sys
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from typing import List, Tuple, Dict
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
import nltk
import spacy
import heapqfrom concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
import numpy as npfrom spacy.cli import download
from spacy.lang.en import Englishsys.path.append(os.path.abspath(os.path.join(os.getcwd(), '..'))) # 将父目录加入系统路径
from helper_functions import *
from evaluation.evalute_rag import *# 加载环境变量
load_dotenv()# 设置OpenAI API密钥
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"nltk.download('punkt', quiet=True)
nltk.download('wordnet', quiet=True)
定义文档处理器类
# 文档处理专家
class DocumentProcessor:def __init__(self):"""初始化文档处理器,配备文本分割器和OpenAI嵌入引擎属性:- text_splitter:递归字符文本分割器,配置了块大小和重叠量- embeddings:OpenAI嵌入模型实例"""self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)self.embeddings = OpenAIEmbeddings()def process_documents(self, documents):"""文档加工流水线:切分->嵌入->存储参数:- documents:待处理文档列表返回:- (文本块列表, 向量数据库) 元组"""splits = self.text_splitter.split_documents(documents)vector_store = FAISS.from_documents(splits, self.embeddings)return splits, vector_storedef create_embeddings_batch(self, texts, batch_size=32):"""批量生成文本嵌入(内存友好模式)参数:- texts:待嵌入文本列表- batch_size:批处理大小返回:- 嵌入向量矩阵"""embeddings = []for i in range(0, len(texts), batch_size):batch = texts[i:i+batch_size]batch_embeddings = self.embeddings.embed_documents(batch)embeddings.extend(batch_embeddings)return np.array(embeddings)def compute_similarity_matrix(self, embeddings):"""计算余弦相似度矩阵(语义关系网)参数:- embeddings:嵌入向量集合返回:- 相似度矩阵"""return cosine_similarity(embeddings)
定义知识图谱类
# 概念提取模型
class Concepts(BaseModel):concepts_list: List[str] = Field(description="概念列表")# 知识图谱构建专家
class KnowledgeGraph:def __init__(self):"""初始化知识图谱构建器属性:- graph:网络图实例- lemmatizer:词形还原器- concept_cache:概念缓存字典- nlp:spaCy NLP模型- edges_threshold:边添加阈值"""self.graph = nx.Graph()self.lemmatizer = WordNetLemmatizer()self.concept_cache = {}self.nlp = self._load_spacy_model()self.edges_threshold = 0.8def build_graph(self, splits, llm, embedding_model):"""图谱构建四部曲:节点创建->嵌入生成->概念提取->边连接参数:- splits:文档块列表- llm:大语言模型实例- embedding_model:嵌入模型实例"""self._add_nodes(splits)embeddings = self._create_embeddings(splits, embedding_model)self._extract_concepts(splits, llm)self._add_edges(embeddings)def _add_nodes(self, splits):""" 将文档块转化为图谱节点 """for i, split in enumerate(splits):self.graph.add_node(i, content=split.page_content)def _create_embeddings(self, splits, embedding_model):""" 为文档块生成语义指纹 """texts = [split.page_content for split in splits]return embedding_model.embed_documents(texts)def _compute_similarities(self, embeddings):""" 计算语义相似度矩阵 """return cosine_similarity(embeddings)def _load_spacy_model(self):""" 加载spaCy模型(自动下载模式) """try:return spacy.load("en_core_web_sm")except OSError:print("正在下载spaCy模型...")download("en_core_web_sm")return spacy.load("en_core_web_sm")def _extract_concepts_and_entities(self, content, llm):