建设施工合同范本网站seo优化网站
1 前言
nuScenes 数据集在大模型训练中应用广泛,在很多CVPR或者其它论文中经常能看到使用nuScenes 数据集达到SOTA水平。
在之前的博客《自动驾驶---学术论文的常客:nuScenes 数据集》中,笔者主要介绍了nuScenes数据集的来源和下载方式,本篇博客主要介绍如何使用nuScenes数据集。

2 nuScenes devkit 教程
主要内容来源于官方教程。假定nuscenes数据集的文件目录为:data/sets/nuscenes,并加载完整数据集的一个mini版(完整的数据集太大了)。
2.1 整体架构
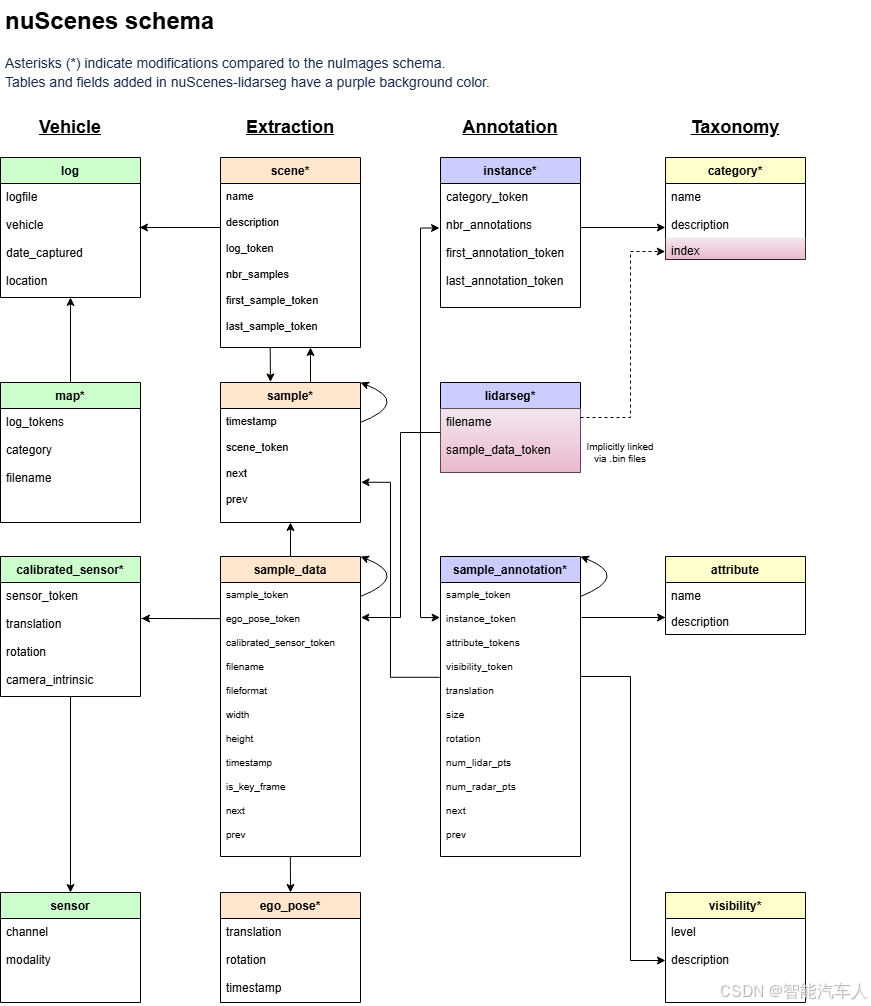
数据集按数据库组织,由下面13个基础表(每个表也是一个json文件)构成:
| 表名 | 说明 |
|---|---|
| log | 日志信息,用于提取数据。 |
| scene | 车辆行驶 20 秒的片段。 |
| sample | 特定时间戳下场景的标注快照,按 2Hz 采样的关键帧,一个场景有 40 个样本。 |
| sample_data | 特定传感器收集的数据,包含图像、点云、雷达数据,有关键帧的 sample 和非关键帧的 sweep。 |
| ego_pose | 特定时间戳下车辆的姿态。 |
| sensor | 特定的传感器类型。 |
| calibrated sensor | 特定车辆上特定传感器的标定定义,含传感器(激光雷达、雷达、相机)外参和相机内参。 |
| instance | 观察到的所有对象实例的枚举。 |
| category | 对象类别的分类体系(如车辆、人类)。 |
| attribute | 实例在类别不变时可改变的属性。 |
| visibility | 从 6 个不同相机收集的所有图像中像素的可见比例。 |
| sample_annotation | 感兴趣对象的标注实例。 |
| map | 以俯视图二进制语义掩码形式存储的地图数据。 |
整个nuScenes数据集的文件架构及相互关系如下图所示:
2.2 使用说明
按步骤说明如何通过python使用nuScenes数据集,一般会使用mini版本,完整的数据集版本是非常大的。
(1)创建文件夹,运行下面代码将设置好数据集和工具集。
mkdir -p data/sets/nuscenes # Make the directory to store the nuScenes dataset in.#wget https://www.nuscenes.org/data/v1.0-mini.tgz # Download the nuScenes mini split.tar -xf data/data57268/v1.0-mini.tgz -C data/sets/nuscenes # Uncompress the nuScenes mini split.pip install nuscenes-devkit &> /dev/null # Install nuScenes.(2)初始化
%matplotlib inline
from nuscenes.nuscenes import NuScenesnusc = NuScenes(version='v1.0-mini', dataroot='data/sets/nuscenes', verbose=True)(3)nuScenes是一个大规模数据集,有1000 个场景,每个约20秒。我们加载的mini版数据集有10 个场景。让我们看看加载在数据集中的场景。
nusc.list_scenes()my_scene = nusc.scene[0](4)sample 样本
在场景中,我们每0.5秒标注一个数据 (2 Hz)。我们定义样本为一个场景在给定时间戳标注的关键帧。让我们看下这个场景中第一个标注样本。
first_sample_token = my_scene['first_sample_token']# The rendering command below is commented out because it tends to crash in notebooks
nusc.render_sample(first_sample_token)(5)让我们看下它的元数据,通过 token 使用get 方法
my_sample = nusc.get('sample', first_sample_token)(6)sample_data 样本数据
nuScenes数据集包含完整传感器套件收集的数据。因此,对每一个场景快照,我们提供对这些传感器数据的引用。
让我们看看取自 CAM_FRONT 的 sample_data 元数据。
sensor = 'CAM_FRONT'
cam_front_data = nusc.get('sample_data', my_sample['data'][sensor])
cam_front_data我们也可以画出特定传感器的 sample_data。
nusc.render_sample_data(cam_front_data['token'])
2.3 应用举例
下面这段代码主要作用:取每一个场景下前视相机的数据以及自车姿态的数据。当然还有其它模块的使用,这里就不一一举例了。
# Load the datasetnusc = NuScenes(version=args.version, dataroot=args.dataroot)# Iterate the scenesscenes = nusc.scenefor scene in scenes:token = scene['token']first_sample_token = scene['first_sample_token']last_sample_token = scene['last_sample_token']name = scene['name']description = scene['description']# Get all image and pose in this scenefront_camera_images = []ego_poses = []camera_params = []curr_sample_token = first_sample_tokenwhile True:sample = nusc.get('sample', curr_sample_token)# Get the front camera image of the sample.cam_front_data = nusc.get('sample_data', sample['data']['CAM_FRONT'])# nusc.render_sample_data(cam_front_data['token'])# Get the ego pose of the sample.pose = nusc.get('ego_pose', cam_front_data['ego_pose_token'])ego_poses.append(pose)# Get the camera parameters of the sample.camera_params.append(nusc.get('calibrated_sensor', cam_front_data['calibrated_sensor_token']))# Advance the pointer.if curr_sample_token == last_sample_token:breakcurr_sample_token = sample['next']scene_length = len(front_camera_images)print(f"Scene {name} has {scene_length} frames")其中scene.json中的内容如下,可通过里面的token信息,可以找到当前场景下其它标注信息,如位置,传感器等信息。
{
"token": "cc8c0bf57f984915a77078b10eb33198",
"log_token": "7e25a2c8ea1f41c5b0da1e69ecfa71a2",
"nbr_samples": 39,
"first_sample_token": "ca9a282c9e77460f8360f564131a8af5",
"last_sample_token": "ed5fc18c31904f96a8f0dbb99ff069c0",
"name": "scene-0061",
"description": "Parked truck, construction, intersection, turn left, following a van"
},上述json文件中的字段解析如下:
| 字段名 | 类型 | 说明 |
|---|---|---|
| token | string | 场景的唯一标识符(UUID4 格式)。 |
| log_token | string | 关联的日志文件的 token,用于追溯数据来源。 |
| nbr_samples | integer | 该场景包含的样本数量(每个场景按 2Hz 采样,20 秒共 40 个样本,但此处为 39,可能因数据截断或异常导致)。 |
| first_sample_token | string | 场景中第一个样本的 token。 |
| last_sample_token | string | 场景中最后一个样本的 token。 |
| name | string | 场景的名称(通常为 scene-<编号>格式)。 |
| description | string | 场景的简短描述,包含关键交通元素和驾驶行为。 |
再比如,我们可以画lidar的数据。在原始的 nuScenes 开发工具包中,可以将一个样本数据令牌传递给 render_sample_data 函数,以渲染点云的鸟瞰图。不过,这些点会根据与自车的距离来着色。而现在使用扩展后的 nuScenes 开发工具包,只需将 show_lidar_seg 参数设置为 True,就可以可视化点云的类别标签。
my_sample = nusc.sample[87]
sample_data_token = my_sample['data']['LIDAR_TOP']
nusc.render_sample_data(sample_data_token, with_anns=False, show_lidarseg=True)