邢台网站百度关键词搜索怎么弄
基于SoftMax回归实现图片分类
- 1,softmax回归
- 2,softmax回归从0实现
- 2.1,导入相关库
- 2.2,获取训练集和测试集的迭代器
- 2.3,初始化模型参数
- 2.4,按轴求和运算
- 2.5,SoftMax运算
- 2.6,定义SoftMax回归模型
- 2.7,使用交叉熵损失函数
- 2.8,计算预测准确率
- 2.9,训练模型
- 3,softmax回归简洁实现
- 3.1,导入相关库
- 3.2,获取训练集和测试集的迭代器
- 3.3,初始化模型参数
- 3.4,使用交叉熵损失函数
- 3.5,使用梯度下降优化算法
- 3.6,训练模型
1,softmax回归
与之前介绍的线性回归一样,softmax回归也是一个单层神经网络,softmax回归的输出层也是全连接层。因此softmax回归和线性回归都被归类为线性神经网络。 其特性如下:
-
使用
softmax操作可以将原始的多个输出值转为概率分布,得到每个类的预测置信度; -
softmax回归虽然名字中有回归,但实际它是一个多类 分类模型 \textcolor{red}{分类模型} 分类模型。它常用于多分类问题的输出层,可以将原始的输出值转为概率分布; -
softmax 回使用交叉熵损失函数来衡量预测和真实标签的区别; -
交叉熵损失中的独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。 比如:标签y将是一个三维向量, 其中(1,0,0)对应于“猫”、(0,1,0)对应于“鸡”、(0,0,1)对应于“狗。
2,softmax回归从0实现
自己编写函数从0开始实现:使用softmax回归进行Fashion-MNIST数据集的图片分类。
2.1,导入相关库
导入相关库
import torch
from IPython import display
from d2l import torch as d2l
2.2,获取训练集和测试集的迭代器
# 批量大小256,每次随机读256张图片
batch_size = 256 # 使用上一节定义的函数获取训练集和测试集的迭代器
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
2.3,初始化模型参数
# 每个图片都是(长*宽*通道数)28*28*1的形式。
# 但softmax的输入需要是一个向量,因此需要拉长成一个向量 注:28*28=784
num_inputs = 784# 数据集有10个类别,因此模型输出维度为10
num_outputs = 10# 初始化权重(XW+b)
# X拉平后形状一般是(batch_size,num_inputs)。此处为(256,784)
# W形状为形状为 (num_inputs, num_outputs)。此处是(784,10);requires_grad=True表示需要计算梯度"""
进行矩阵乘法 X*W 时,结果形状为 (batch_size, num_outputs)。
"""W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)# b被初始化为元素全为0的一维张量。对每一个输出都需要有一个偏移,因此偏移是长为10的向量。同样需要计算梯度
b = torch.zeros(num_outputs, requires_grad=True)
- 注:最后会执行广播相加:PyTorch会自动将 b 变为 (batch_size, num_outputs),以便与 W*X 的形状匹配。
2.4,按轴求和运算
给定一个矩阵X,我们可以对所有元素求和
# 矩阵按轴求和
# 此处构建一个2×3的矩阵
X = torch.tensor([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])"""
* 第一个参数0或1:表示沿着维度为0或1求和;
* 0表示按列相加得到的是行形式;1表示按行相加得到的是列形式
* 第二个参数keepdim=True:保持输出的维度与输入相同,即使结果是标量
* 偏移最终是通过广播机制相加的
"""
X.sum(0, keepdim=True), X.sum(1, keepdim=True)
运行结果如下:

2.5,SoftMax运算
实现softmax 由三个步骤组成:
- 对每个项求幂(使用
exp); - 对每一行求和(小批量中每个样本是一行),得到每个样本的规范化常数;
- 将每一行除以其规范化常数,确保结果的和为1;
在查看代码之前,我们回顾一下这个表达式:
定义
softmax操作。实现:对于任何随机输入,将每个元素变成一个非负数。 此外,依据概率原理,每行总和为1。
代码实现如下:
# 注意此处X是一个矩阵,而非向量。对矩阵按行做softmax
def softmax(X):# ①先对X每个项求幂(使之非负)X_exp = torch.exp(X)# ②对每一行求和,得到规范化常数partition = X_exp.sum(1, keepdim=True)# ③每一行除以规范化常数,确保结果的和为1return X_exp / partition # 这里应用了广播机制(第i行除以partition中第i个元素)
使用例子,打印输出做检查
# 随机创建一个均值为0标准差为1的2行5列的矩阵X
X = torch.normal(0, 1, (2, 5))# 进行softmax运算
X_prob = softmax(X)# X_prob形状不变,但所有值均为正
X_prob, X_prob.sum(1,keepdim=True)
# X_prob.sum(1)求和操作指定参数keepdim=True表示保留原始张量的维度
运行结果如下:

2.6,定义SoftMax回归模型
接下来实现
softmax回归模型
定义模型
- 通过代码体会输入如何通过网络映射到输出
- 需要注意,将数据传递到模型之前,需要使用
reshape函数将每张原始图像展平为向量
def net(X):""" * 通过y=XW+b计算得到的预测值还需要进行softmax运算* 我们需要的x是批量大小乘以输入维数的矩阵,因此X最终被reshape成一个256×784的矩阵(256*28*28)* reshape的第一个参数-1表示自动计算行大小,此处算成256* W形状是(784,10)即(num_inputs, num_outputs)。w.shape[0]=784。* 最终返回一个元素值均大于0且行和为1的输出"""return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
2.7,使用交叉熵损失函数
用python的高级索引操作从
y_hat中提取对应于真实类别标签的预测值
- 假设有3个类别,对2个样本进行预测。创建一个数据样本
y_hat,其中包含2个样本在3个类别的预测概率, 它们对应的真实数据标签是y。
# 创建一个向量y表示真实的类别标签
# y告诉我们在第一个样本中正确的预测是第一类;第二个样本中正确的预测是第三类
y = torch.tensor([0, 2])# y_hat是经过softmax运算之后的预测值(假设有3个类别,对2个样本进行预测)
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])"""
以下是python的一个高级索引操作:* 对于第一个样本(y[0] = 0),从y_hat的第一行(因为[0, 1]中的0指的是第一行)中选择索引为0的元素,即y_hat[0, 0]=0.1* 对于第二个样本(y[1] = 2),你会从y_hat的第二行(因为[0, 1]中的1指的是第二行)中选择索引为2的元素,即y_hat[1, 2]=0.5* [0, 1]也可以通过range(len(y_hat))得到,下面代码替换成y_hat[range(len(y_hat)), y]输出不变"""
y_hat[[0, 1], y]
运算结果如下:

最大似然估计
假设一个袋子里面有很多(不考虑放回问题)红色球和蓝色球,五次取出的球分别为红、红、蓝、红、蓝。则设取出红色球的概率是θ,取出蓝色球的概率是(1-θ)。
-
则此样本的概率是: θ 3 ( 1 − θ ) 2 \textcolor{red}{θ^3(1-θ)^2} θ3(1−θ)2
-
似然函数即为: L ( θ ) = θ 3 ( 1 − θ ) 2 \textcolor{red}{L(θ) = θ^3(1-θ)^2} L(θ)=θ3(1−θ)2
-
似然估计认为存在即合理 ,我们抽到了这组样本,就认为这组样本被抽到的概率最大,即L(θ)最大 -
通过一系列运算:取对数、关于θ求导、令导数为0。求出θ值为 3 5 \frac{3}{5} 53时似然函数取最大值
-
因此估计取出红球的概率是 3 5 \frac{3}{5} 53,取出蓝球的概率为 2 5 \frac{2}{5} 52
交叉熵损失函数
交叉熵损失函数在分类问题中常被使用。采用真实标签对应的的预测概率的负对数似然。
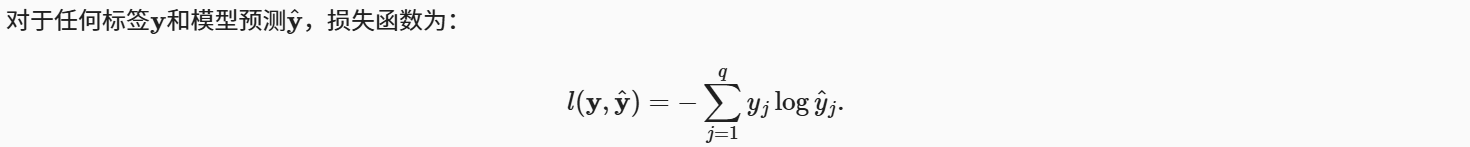
接下来,只需一行代码就可以实现交叉熵损失函数
-
y_hat 中的一行表示该样本属于每个类别的预测概率;
-
-torch.log(...)计算这些预测概率的负对数。因为在很多损失函数中,我们希望最大化正确类别的概率(即最小化负对数概率),这样,如果模型对真实类别的预测概率越高,损失就越小;反之,如果预测概率越低,损失就越大。
# 给定预测y_hat和真实标号y,计算交叉熵损失
def cross_entropy(y_hat, y):"""以下代码使用了高级索引操作:* 从y_hat 中选取每个样本在其真实类别上的预测概率(取第一个样本的第1个元素和第二个样本的第三个元素)。* len(y__hat)是样本数* range(len(y_hat)) 生成一个索引列表,而 y 是真实标签的索引列表"""return - torch.log(y_hat[range(len(y_hat)), y])# 打印查看,y_hat是2*3;y是长为2的向量(使用都的是之前定义的值)
print(y_hat)
print(y)cross_entropy(y_hat, y) # 输出两个样本的交叉熵损失
运行结果如下:

2.8,计算预测准确率
将预测类别与真实y元素进行比较,当预测与真实标签分类y一致时,即是正确的。
输出预测正确的样本数
def accuracy(y_hat, y): # len(y_hat.shape) > 1可判断是否为多维张量,多分类任务中,我们期望 y_hat 是多维的# y_hat.shape[1]>1 判断列数是否大于1if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:"""argmax()函数的作用是找出给定轴上最大值的索引;参数axis=1 指的是沿着每一行进行操作(列通常是0);找出每一行中最大值元素的索引,存入y_hat,作为预测的分类类别。"""y_hat = y_hat.argmax(axis=1)# dtype()表示求数组或张量中元素的数据类型。此处保证y_hat和y的数据类型一致,以便比较# cmp最终是一个布尔型张量,存储了y_hat和 y之间元素的比较结果 cmp = y_hat.type(y.dtype) == y# cmp.type(y.dtype)将cmp的数据类型转换为和y相同,以便可以进行sum操作# True 转换时可视为 1,False 可视为 0# 输出的是预测正确的样本数return float(cmp.type(y.dtype).sum())
计算预测准确率
准确率即正确预测的数量除以总样本数。
# 预测正确的样本数除以y长度(样本数)就是预测正确的概率
accuracy(y_hat, y) / len(y)
运算结果如下:

- 第一个样本的
预测类别是2(该行的最大元素为0.6,索引为2),这与实际标签0不一致; - 第二个样本的
预测类别是2(该行的最大元素为0.5,索引为2),这与实际标签2一致; - 因此,这两个样本的分类精度率为0.5。
对于任意数据迭代器data_iter可访问的数据集, 评估在任意模型net的精度。
# 给一个模型和数据迭代器,计算模型在数据迭代器上的精度
def evaluate_accuracy(net, data_iter): if isinstance(net, torch.nn.Module):net.eval() # 如果 net是 torch.nn.Module 的一个实例。则将模型设置为评估模式(无需计算梯度...)# 初始化累加器Accumulator,构造一个长为2的列表分别存储正确预测数和预测总数metric = Accumulator(2) with torch.no_grad(): # 不计算梯度for X, y in data_iter:"""numel()返回张量中元素的总数,即预测总数accuracy(net(X), y)返回预测正确的样本数量"""metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]# 定义累加器
class Accumulator: # 构造函数:创建Accumulator实例时,初始化一个长为n的列表,其中每一个元素都是0.0,用于存储累加的值def __init__(self, n): self.data = [0.0] * n"""zip(self.data, args):将 self.data 列表和 args 元组中的元素一一配对,形成一个迭代器,其中每个元素都是一个包含两个值的元组[a + float(b) for a, b in zip(self.data, args)]:遍历 zip 函数生成的迭代器,对于每一对值 (a, b),它将 a(self.data 中的当前值)与 float(b)(args 中对应的值转换为浮点数)相加,并将结果收集到一个新的列表中。"""# 累加方法:add 方法接受任意数量的参数(通过 *args 实现),这些参数对应于要累加到 data 列表中的每个变量的值。def add(self, *args): self.data = [a + float(b) for a, b in zip(self.data, args)]# 重置方法:将累加器中的所有变量值清空,准备进行新的累加操作。def reset(self):self.data = [0.0] * len(self.data)# 通过重载 __getitem__ 方法,使得 Accumulator 实例可以像列表一样通过索引访问 data 列表中的元素。def __getitem__(self, idx):return self.data[idx]
由于我们一开始使用随机权重初始化net模型, 因此该模型的精度应接近于随机猜测。 例如在有10个类别情况下的精度为0.1。
evaluate_accuracy(net, test_iter)

2.9,训练模型
updater是更新模型参数用的函数。它可以是d2l.sgd函数,也可以是框架的内置优化函数。
训练函数
def train_epoch_ch3(net, train_iter, loss, updater):# 如果使用的是torch.nn.Module实现,则将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 创建一个长度为3的迭代器 。分别记录训练损失总和、训练中正确的样本数、样本数metric = Accumulator(3)for X, y in train_iter:y_hat = net(X)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer): # 当updater使用PyTorch内置的优化器时:# 执行:①梯度清零、②计算梯度、③参数自更新updater.zero_grad()"""反向传播计算平均梯度"""l.mean().backward() # 计算平均损失的梯度"""step()函数是优化器(torch.optim.Optimizer的子类)的一个方法,用于更新模型的参数。调用step()时,优化器会根据之前通过反向传播计算得到的梯度来更新模型中的可训练参数"""updater.step()metric.add(float(l.sum()), accuracy(y_hat,y), y.numel())else: # 使用定制的优化器和损失函数l.sum().backward()# 调用自定义更新函数updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度return metric[0] / metric[2], metric[1] / metric[2]
- 累加器累加的三个指标分别是:总损失、准确率、样本数;
- train_epoch_ch3 函数返回的是平均损失和平均准确率;
训练
- num_epochs:训练的总轮数
- updater:优化函数(优化器对象)
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): # Animator用来实现动画效果animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):# train_epoch_ch3 返回的两个值分别是训练损失和训练准确率。train_metrics是个包含两个元素的元组(tuple)train_metrics = train_epoch_ch3(net, train_iter, loss, updater)# 评估模型在测试集上的精度test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,)) # 绘制动画# 取出训练损失和训练准确率train_loss, train_acc = train_metrics# 打印训练损失、训练精度print(f"train_loss: {train_loss};train_acc: {train_acc}")# 打印测试集上的精度print(f"test_acc: {test_acc}")"""Python的assert语句中,如果条件为False,则后面的值会被转换成字符串形式,用作异常消息第一个assert语句中的train_loss < 0.5不满足时会抛出一个AssertionError异常,并显示train_loss值作为错误消息"""assert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc
使用线性回归中定义过的小批量随机梯度下降来作优化器优化模型参数,设置学习率为0.1。
lr = 0.1def updater(batch_size):return d2l.sgd([W, b], lr, batch_size)
训练十个迭代周期
num_epochs = 10# 调用训练函数
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
运行结果如下:

在训练集上训练完成后,我们在测试集上对图像进行分类预测。给定一系列图像,比较它们的实际标签和模型预测。
- net是一个已经训练好的神经网络模型
- n默认值为6,指定要显示多少个预测结果
# 定义预测函数
def predict_ch3(net, test_iter, n=6): for X, y in test_iter: # 从测试数据集迭代器中取出一批次数据(每个批次包含多个图像和对应的标签)break# 将真实的数字标签转为文本标签trues = d2l.get_fashion_mnist_labels(y) # argmax函数可以找到指定轴上的最大值的索引# 将预测的数字标签转为文本标签preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1)) # 展示六个图像的数据titles = [true +'\n' + pred for true, pred in zip(trues, preds)]d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])# 调用预测函数进行分类预测
predict_ch3(net, test_iter)
运行结果如下,六个图像全部预测正确:

3,softmax回归简洁实现
使用深度学习框架来简洁地实现线性回归模型。
3.1,导入相关库
import torch
from torch import nn
from d2l import torch as d2l
3.2,获取训练集和测试集的迭代器
此处加载的是上一节介绍的FashionMnist 图像分类数据集。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
3.3,初始化模型参数
softmax回归的输出层是一个全连接层(线性层)。
"""
我们在线性层前定义了展平层(flatten),来调整网络输入的形状
nn.Linear(784, 10) 是一个全连接层,将784个输入特征映射到10个输出类别
"""
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))# 初始化权重。参数m是一个层(layer)
def init_weights(m): if type(m) == nn.Linear: # 如果传入的m是全连接层"""在PyTorch中,nn.init.normal_(tensor, mean=0, std=1)函数用于将张量(tensor)初始化为正态分布的值。mean参数代表正态分布的均值,默认值为0;std参数代表正态分布的标准差,默认值为1"""nn.init.normal_(m.weight, std=0.01) # 以均值为0、标准差为0.01的正态分布初始化全连接层的权重weight。"""
下面这行代码将 init_weights 函数应用到模型 net 的每一层上,该层如果是 nn.Linear 类型,就会使用 init_weights 函数来初始化其权重。
"""
net.apply(init_weights);
3.4,使用交叉熵损失函数
注意:在nn.CrossEntropyLoss函数内部,进行了softmax运算。
"""
reduction参数有以下几个选项:'none':返回每个样本的损失。'mean':返回平均损失。'sum':求和,返回总损失。
"""
loss = nn.CrossEntropyLoss(reduction='none')
3.5,使用梯度下降优化算法
使用学习率为0.1的小批量随机梯度下降作为优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
3.6,训练模型
注意:softmax 运算实际上在损失函数nn.CrossEntropyLoss内部隐式地完成的
"""训练模型一个迭代周期"""
def train_epoch_ch3(net, train_iter, loss, updater):# 如果使用的是torch.nn.Module实现,则将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 创建一个长度为3的累加器 metric = Accumulator(3)for X, y in train_iter:y_hat = net(X) l = loss(y_hat, y) # 简洁实现中:softmax 运算实际上在损失函数内部隐式地完成if isinstance(updater, torch.optim.Optimizer): # 当updater使用PyTorch内置的优化器时:①梯度清零、②计算梯度、③参数自更新updater.zero_grad()"""使用批量梯度下降来训练模型时,我们通常希望计算整个批量的平均损失,并基于这个平均损失来更新模型的参数。这是因为平均损失提供了一个更稳定的梯度估计,有助于模型在训练过程中更平滑地收敛。"""l.mean().backward() # 计算平均损失的梯度"""step()函数是优化器(torch.optim.Optimizer的子类)的一个方法,用于更新模型的参数。调用step()时,优化器会根据之前通过反向传播计算得到的梯度来更新模型中的可训练参"""updater.step()# 累加器分别记录训练损失总和、训练中正确的样本数、样本总数metric.add(float(l.sum()), accuracy(y_hat,y), y.numel())else: # 使用定制的优化器和损失函数l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度return metric[0] / metric[2], metric[1] / metric[2]
训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): # Animator是用来实现动画效果的,可以不用关注animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):# train_epoch_ch3 返回的两个值分别是训练损失和训练准确率。train_metrics是个包含两个元素的元组(tuple)train_metrics = train_epoch_ch3(net, train_iter, loss, updater)# 评估模型在测试集上的精度test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,)) # 绘制动画不用管# 取出训练损失和训练准确率train_loss, train_acc = train_metrics# 调用train_ch3函数时会打印训练损失、训练精度print(f"train_loss: {train_loss};train_acc: {train_acc}")# 调用train_ch3函数时会打印测试集上的精度print(f"test_acc: {test_acc}")"""Python的assert语句中,如果条件为False,则后面的值会被转换成字符串形式,用作异常消息第一个assert语句中的train_loss < 0.5不满足时会抛出一个AssertionError异常,并显示train_loss值作为错误消息"""assert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc
训练十轮
num_epochs = 10
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
运行结果如下:
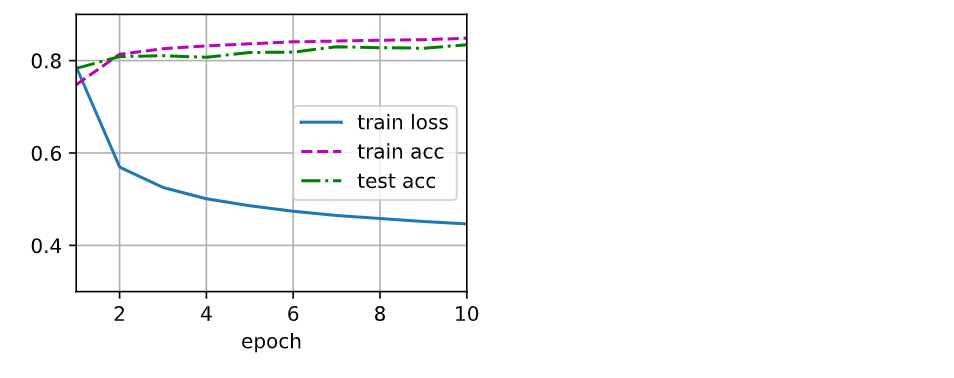
和以前一样,这个算法使结果收敛到一个相当高的精度,而且这次的代码比之前更精简了。