如何做与别人的网站一样的网络广告营销策略
协议
在网络通信中,协议是非常重要的概念。协议是在网络通信过程中的约定。发送方和接收方需要提前商量好数据的格式,才能确保正确进行沟通。
应用层协议
应用层,对应着应用程序,是跟我们程序员打交道最多的一层。调用操作系统提供的网络API写出的代码,都是在应用层上的。
应用层这里有很多现成的协议,但更多的,还是需要我们程序员根据实际的业务场景自定义协议(网络传输的数据要怎么使用,也要考虑数据是什么样的格式,包含哪些内容)。
应用层的协议在开发时一般是客户端和服务器共同约定的。
自定义协议,一般要约定好两方面内容:
1、客户端和服务器要交互哪些信息
2、数据的具体格式
客户端按照上述约定发送请求,服务器按照上述约定解析请求,服务器按照上述约定构造响应,客户端按照上述约定解析响应。
举个例子:
点个外卖~
打开外卖相关的APP,显示出主页,主页里面就会显示出一些快餐店、饭店的列表。
而这些饭店都是在我们附近的(打开软件时,客户端和服务器交互了位置信息),显示的饭店列表中,也会包含一些信息——饭店的名称、图片、评分、简介……上述的这些信息,需要通过一定的格式来组织的,往往是设计客户端和设计服务器这两伙程序员坐在一起,一起把这个事情敲定下来的~~~
一个简单粗暴但五脏俱全的例子:
1、请求,约定使用行文本的格式来进行表示:
userId,postion\n(请求以\n结尾,使用,对信息进行分割)
例如:(1001,[经纬度]\n)
2、 响应,也是使用行文本来表示,一个响应中可能会包含多个饭店,每个饭店占一行,每个饭店都要返回 id,名称,图片,评分,简介
例如:( 2001,A 饭店,[logo图片地址],4.9,高端饭店\n
2002,B饭店,[logo图片地址],4.5,干净卫生的饭店\n
\n)
若干行的最后,使用空行来作为所有数据的结束标志,上面这一系列内容就是同一个响应中的数据了。
补充:
客户端和服务器之间往往交互的是“结构化数据”(结构化数据:一个结构体/类,其中包含了很多个属性),而网络传输的数据其实是“字符串”、“二进制比特流”。
约定协议的过程,其实就是把结构化数据转成字符串/二进制比特流的过程。
把结构化数据转成字符串/二进制bit流的操作,称为“序列化”。
把字符串/二进制比特流还原成结构化数据的操作,称为“反序列化”。
序列化/反序列化具体要组织成什么样的格式,要包含哪些信息,约定这两件事情的过程,就是自定义协议的过程。
为了让程序员更方便地去约定这里的协议格式,业界给出了几个比较好用地方案:
xml协议
大致模型如下:
<属性名>称为标签(tag),一般是成对出现的,分别为开始标签和结束标签。开始标签和结束标签中间夹着的是标签的值,标签是可以嵌套的。(标签名/标签值/标签的嵌套关系,这些都是程序员自定义的)
优点 :使得数据内容的可读性和拓展性都提升了很多,标签的名字能够对数据起到说明作用,后续再增加一个属性,新添加一个标签即可,对已有代码影响不大
缺点:冗余信息比较多,标签的描述性信息,占据的空间反而比数据本身还要多了。
json协议
大致模型如下:
采用的是键值对结构:
键与值之间用:进行分割,键与键之间用,进行分割,若干个键值对之间使用{ }分隔开,一个{ }就形成了一个json对象,还可以把多个json对象放到一起,使用,分隔开,将整体使用[ ]括起来,此时就形成了一个json数组。
优点:可读性、扩展性都更好,而且对比xml来说,占用的空间更少了。
缺点:虽然json的确比xml占用的空间更少了,节省了宽带,但很明显,这里的宽带仍然还是有浪费的部分,尤其是这种数组格式的json,这种情况下往往会传输很多相同的数据字段,很多key关键字都是重复传输的(id、name……)。
protobuffer
这种约定是更加节省宽带的方式,也是效率最高的方式。
protobuffer只是在发阶段(写代码阶段)定义出这里有的哪些资源,描述每个字段的定义。程序真正运行时,实际传输的数据是不包含这些信息的。这样的数据都是按照二进制的方式来进行组织的。
这种方式虽然程序运行的效率会很高,但不利于程序员进行阅读。
所以虽然protobuffer运行效率更高,但是使用并没有比json广泛,只有一些对于性能要求非常高的场景protobuffer。
传输层协议
传输层的协议,虽然是系统内核已经实现好的,但我们仍需要重点进行关注,我们在之前的网络编程中使用的socket API 就是传输层提供的。
端口号
端口号,是一个两个字节的整数。标识了一个主机上的正在进行网络通信应用程序。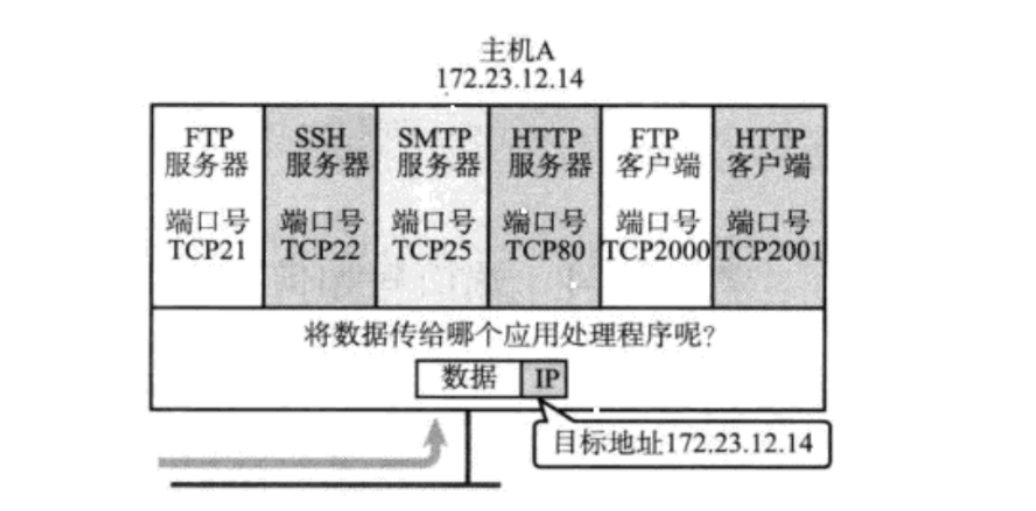
在TCP/IP协议中,用源IP、源端口号、目的IP、目的端口号、协议号,这样一个五元组来标识一个通信。 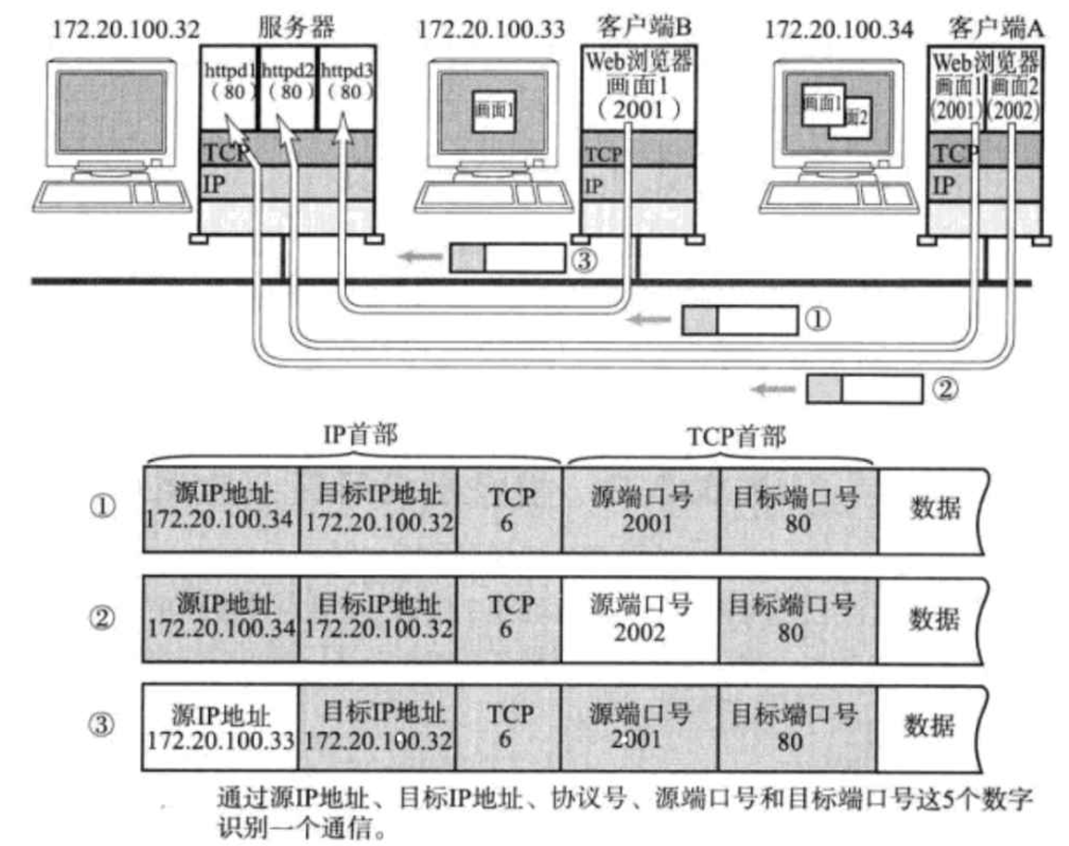
端口号的范围划分:
0~1023:是一些知名端口号,HTTP,FTP,SSH等这些广为使用的服务器,他们的端口号是固定的。
1024~65535:操作系统动态分配的端口号。我们前面在网络编程中,客户端程序的端口号,就是由操作系统在这个范围内分配的。
知名端口号:
SSH服务器:22;
FTP服务器:21;
telnet服务器:23;
HTTP服务器:80;
HTTPS服务器:443;
我们在写程序使用端口号时,需要避开这些知名端口号。
UDP协议
前面我们已经提到过,UDP协议的四个特点:无连接,不可靠传输,面向数据报,全双工。
研究一个协议,我们主要研究报文格式,基于报文格式,来了解这个协议的特性。
UDP数据报 = 报头(重点)+载荷(应用层数据包)
UDP协议格式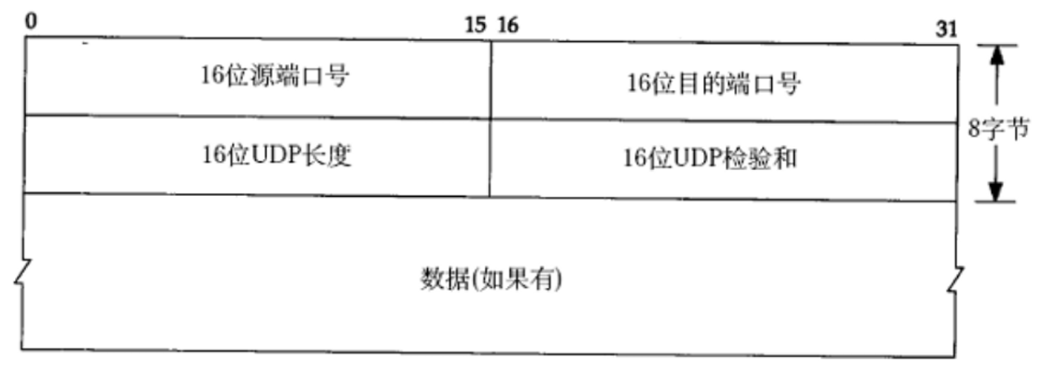
实际上的UDP数据报是这样的: UDP的报头中,一个有4个字段,每个字段2个字节(一共8个字节)。
UDP的报头中,一个有4个字段,每个字段2个字节(一共8个字节)。
由于UDP中使用2个字节(16位)来识别端口号,端口号的取值范围就是0~65535,同理数据报的最大长度也是65535(64KB),一旦数据超出64KB,数据就有可能会出现截断(64KB后面的数据就没有了)。
总的数据报最大长度是64KB,载荷部分实际的最大长度应该是64KB-8KB(报头长度)
为了解决数据被截断问题,有两个方案:
方案1:在应用层,把数据报进行拆分,之前一个数据报,表示N个页面,拆分成每一个页面占用一个UDP数据报,甚至可以进一步拆分成,一个页面对应多个UDP数据报(开发和测试成本很大)。
方案2:使用TCP代替UDP,TCP没有长度限制。
那为什么不对UDP的长度进行扩展呢?技术上是很容易实现,但要改就要所有就得所有的系统一起改,如果一方改了,另一方不改,相互之间就无法进行通信了。
校验和:验证数据在传输的过程中是否正确。
数据在网络传输的过程中是可能出错的。网络数据传输的过程中是使用光信号/电信号/电磁波进行传输的,上述信号都是很容易收到干扰的。
比如,使用高低电平来表示0 1 ,此时外界如果加上一个磁场,就可能把高电平变为低电平,低电平变为高电平,此时,0->1,1->0,就出现了比特翻转。现代的传输体系,会有一系列的保护机制,来减少外界的干扰。
校验和的作用就是用来识别出当前数据是否在传输过程中出现错误。
注意:网络中的校验和,并非是简单的按照数据的长度或者数量来进行校验的,一定是数据的内容会参与到其中。
严格来说,校验和只能用来“证伪”,即只能证明数据是出错了。没办法确保这个数据100%是正确的。但是出现这种情况的概率很小,实践中可以近似地认为校验和一致,数据就一致了。
UDP中的校验和是使用比较简单的算法——CRC算法(循环冗余校验)实现的。
比如,要产生一个两个字节的校验和:
加的过程可能会有一些数据比较大,超出了short的范围,其实也没有关系,这里不用管。
UDP数据发送方,在发送数据之前,先计算一遍CRC,把计算好的CRC的值放到UDP数据报中(设这个CRC值为value1)
接下来,这个数据报会通过网络传输到达接收端,接收端收到数据之后,也会使用同样的算法,再算一遍CRC的值,得到的结果是value2。比较自己计算的value2和收到的value1的值是否一致。如果是一致的,那么数据大概率是没有问题的。如果不一致,则传输过程中一定出现了错误。
为什么value1 == value2时,要说数据大概率是没有问题呢?如果只有一个bit为位发生翻转,那么CRC是100%能够发现错误的。但是如果恰好有两个/多个bit位发生翻转,就有可能校验和恰好和之前的一样,这种情况出现的概率比较低,可以忽略不计,但如果需要有跟你广告的检查精度,就需要使用其他更为严格的校验和算法了。
这里我们重点介绍md5/sha1算法 ,这两个算法背后的数学公式大同小异,且研究起来比较困难,这里我们认识下他们的特点即可:
1、定长:无论原始数据有多长,算出来的md5的最终值始终都是一个固定长度(16位、32位、64位)。
2、分散:计算md5的过程中,原始数据,只要变化一点点,算出来的md5的值就会发生很大的变化。(这样的特性,也使得md5可以作为一个字符的hash算法)
3、不可逆:给一个源字符串,计算md5值,过程非常简单(比CRC难一点,但是整体比较简单),但是如果给一个算好的md5值,还原为原始字符串,理论上是无法完成的。
原始字符串变为md5码的过程会有很多信息量损失,无法进行还原,就像火腿肠无法还原成猪肉那样。