网站手机端制作软件国外搜索引擎
文章目录
- Oracle 23ai Vector Search 系列之5 向量索引
- Oracle 23ai支持的向量索引类型
- 内存中的邻居图向量索引 (In-Memory Neighbor Graph Vector Index)
- 磁盘上的邻居分区矢量索引 (Neighbor Partition Vector Index)
- 创建向量索引
- HNSW索引
- IVF索引
- 向量索引示例
- 参考
Windows 环境图形化安装 Oracle 23ai
Oracle 23ai Vector Search 系列之1 架构基础
Oracle 23ai Vector Search 系列之2 ONNX(Open Neural Network Exchange)
Oracle 23ai Vector Search 系列之3 集成嵌入生成模型(Embedding Model)到数据库示例,以及常见错误
Oracle 23ai Vector Search 系列之4 VECTOR数据类型和基本操作
Oracle 23ai Vector Search的典型工作流程:
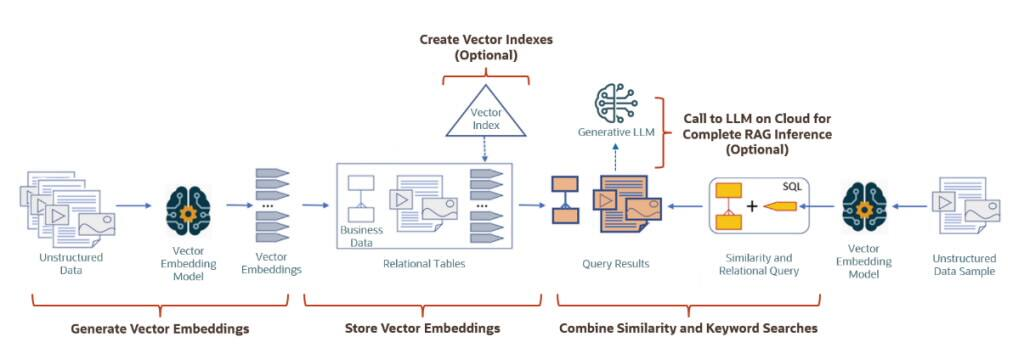
来源:https://blogs.oracle.com/coretec/post/getting-started-with-vectors-in-23ai
Oracle 23ai Vector Search 系列之5 向量索引
Oracle Database 23ai推出了AI Vector Search功能,和数据库的普通索引一样,对于向量检索也可以通过向量索引(Vector Indexes)加速高维向量的相似性搜索(similarity search)。
Oracle 23ai支持的向量索引类型
Oracle提供了两种主要索引类型:
- 内存中的邻居图向量索引 (In-Memory Neighbor Graph Vector Index)
- 磁盘上的邻居分区矢量索引(Neighbor Partition Vector Index)
内存中的邻居图向量索引 (In-Memory Neighbor Graph Vector Index)
HNSW(Hierarchical Navigable Small World :分层可导航小世界)索引 是 Oracle AI Vector Search 中唯一支持的内存邻居图向量索引类型。基于HNSW图算法,通过多层图结构加速搜索。
HNSW索引在23ai版本引入的新的内存结构:向量内存池(Vector Memory Pool)中创建;向量内存池(Vector Memory Pool)位于SGA中,Oracle通过 vector_memory_size参数控制这块内存的大小。
参考:
Understand Hierarchical Navigable Small World Indexes
磁盘上的邻居分区矢量索引 (Neighbor Partition Vector Index)
IVF(Inverted File Flat :倒排文件扁平) 索引是一种基于分区的向量索引技术,是 Oracle AI Vector Search 中唯一支持的邻居分区向量索引类型。
IVF索引在磁盘上创建,并且和其他数据块一样可以缓存在buffer cache。
参考:
Understand Inverted File Flat Vector Indexes
创建向量索引
创建不同类型向量索引的语法稍有不同。
参考:
CREATE VECTOR INDEX
https://docs.oracle.com/en/database/oracle/oracle-database/23/sqlrf/create-vector-index.html
HNSW索引
HNSW索引创建语法如下:
CREATE VECTOR INDEX vector_index_name ON table_name ( vector_column )[ GLOBAL ] ORGANIZATION INMEMORY [ NEIGHBOR ] GRAPH [ WITH ] [ DISTANCE metric name ][ WITH TARGET ACCURACY percentage_value ][ PARAMETERS ( TYPE HNSW , { [ NEIGHBORS ] | M } max_closest_vectors_connected , [ EFCONSTRUCTION ] max_candidates_to_consider )] [ PARALLEL degree_of_parallelism ]参数说明:
- ORGANIZATION INMEMORY [NEIGHBOR] GRAPH
声明索引类型为 HNSW(基于内存的图结构索引)
必须包含 INMEMORY 和 GRAPH 关键字。- DISTANCE(可选)
定义向量相似度的计算方式。
可选值:EUCLIDEAN(欧氏距离)L2_SQUARED(欧氏距离平方,即CLIDEAN_SQUARED`)COSINE(余弦相似度)DOT(点积相似度)MANHATTAN(曼哈顿距离)HAMMING(汉明距离)
默认:若省略,使用系统默认距离函数(通常是 EUCLIDEAN- WITH TARGET ACCURACY(可选)
作用:指定索引的目标搜索精度(百分比)。
取值范围:>0 且 <=100。
示例:WITH TARGET ACCURACY 95 表示目标精度为 95%。
注意:精度越高,查询速度可能越慢。- PARAMETERS(可选)TYPE HNSW 定义 HNSW 索引NEIGHBORS 或 M 作用:定义每个层中向量最多可连接的邻居数量(最后一层允许最多 2M 个邻居)。 取值范围:>0 且 <=2048。 示例:NEIGHBORS 64 或 M 64。影响:值越大,索引构建时间越长,但查询精度可能更高。EFCONSTRUCTION 作用:控制索引构建时每一步插入操作搜索的候选向量数量。取值范围:>0 且 <=65535。示例:EFCONSTRUCTION 500。影响:值越大,索引构建时间越长,但索引质量(精度)更高。- PARALLEL(可选)
作用:指定索引构建时的并行度(如多线程或分布式加速)。
示例:PARALLEL 8 表示使用 8 个并行线程。
IVF索引
IVF索引创建语法如下:
CREATE VECTOR INDEX vector_index_name ON table_name ( vector_column )[ INCLUDE ( covering_column[,covering_column]+ ) ][ GLOBAL ] ORGANIZATION [ NEIGHBOR ] PARTITIONS [ WITH ] [ DISTANCE metric name ][ WITH TARGET ACCURACY percentage_value ][ PARAMETERS ( TYPE IVF , { NEIGHBOR PARTITIONS number_of_partitions | [ SAMPLES_PER_PARTITION number_of_samples ]| [ MIN_VECTORS_PER_PARTITION min_number_of_vectors_per_partition] })] [ PARALLEL degree_of_parallelism ]参数说明:
- INCLUDE(可选)
作用:指定索引包含的非向量列,用于非向量列的查询优化。
示例:INCLUDE (colomn1)。- GLOBAL(可选)
作用:声明索引为全局索引(适用于分布式或分区表场景)。
默认:省略时为局部索引。- ORGANIZATION [NEIGHBOR] PARTITIONS
作用:声明索引类型为 IVF(基于分区的索引)。
必须包含 PARTITIONS 关键字,NEIGHBOR 为可选修饰符。- DISTANCE(可选)
定义向量相似度的计算方式。
可选值:EUCLIDEAN(欧氏距离)L2_SQUARED(欧氏距离平方,即CLIDEAN_SQUARED`)COSINE(余弦相似度)DOT(点积相似度)MANHATTAN(曼哈顿距离)HAMMING(汉明距离)
默认:若省略,使用系统默认距离函数(通常是 EUCLIDEAN- WITH TARGET ACCURACY(可选)
作用:指定索引的目标搜索精度(百分比)。
取值范围:>0 且 <=100。
示例:WITH TARGET ACCURACY 95 表示目标精度为 95%。
注意:精度越高,查询速度可能越慢。- PARAMETERS(可选)
作用:定义 IVF 索引的详细参数,必须包含 TYPE IVF。NEIGHBOR PARTITIONS作用:指定分区的数量(即聚类中心的数量)。取值范围:>0 且 <=10,000,000。示例:NEIGHBOR PARTITIONS 1000。分区越多,每个分区的向量越少,搜索速度越快,但精度可能降低。SAMPLES_PER_PARTITION作用:指定每个分区用于聚类算法的采样数。取值范围:1 ≤ 值 ≤ 总向量数/分区数。示例:SAMPLES_PER_PARTITION 1000。采样数越多,聚类中心越准确,但构建时间越长。默认值通常为总向量数的 1%~10%。MIN_VECTORS_PER_PARTITION作用:设置每个分区的最小向量数,低于此值的分区会被合并或剔除。取值范围:0 ≤ 值 ≤ 总向量数。示例:MIN_VECTORS_PER_PARTITION 100。避免过小的分区(例如设置 ≥100),以提高搜索效率。设为 0 表示不进行分区剪裁。- PARALLEL(可选)
作用:指定索引构建时的并行度(如多线程或分布式加速)。
示例:PARALLEL 8 表示使用 8 个并行线程。
参考:
Manage the Different Categories of Vector Indexes
向量索引示例
SQL> CREATE TABLE documents_hnsw (2 id NUMBER PRIMARY KEY,3 content VARCHAR2(4000),4 embedding VECTOR5 );表已创建。SQL> INSERT INTO documents_hnsw (id, content, embedding)2 VALUES3 (1, '自然语言处理技术', VECTOR('[0.1, 0.3, 0.8]')),4 (2, '机器学习算法', VECTOR('[0.2, 0.5, 0.7]')),5 (3, '人工智能应用', VECTOR('[0.4, 0.6, 0.9]'));已创建 3 行。SQL> -- HNSW索引(基于内存图)
SQL> CREATE VECTOR INDEX idx_docs_hnsw2 ON documents_hnsw (embedding)3 ORGANIZATION INMEMORY NEIGHBOR GRAPH4 DISTANCE COSINE5 WITH TARGET ACCURACY 956 PARAMETERS (7 TYPE HNSW,8 NEIGHBORS 64, -- 每层最大邻居数9 EFCONSTRUCTION 500 -- 构建时候选数10 )11 PARALLEL 4;索引已创建。SQL> select owner, index_name, index_organization, allocated_bytes, used_bytes, num_vectors2 from v$vector_index where index_organization = 'INMEMORY NEIGHBOR GRAPH';OWNER
--------------------------------------------------------------------------------
INDEX_NAME
--------------------------------------------------------------------------------
INDEX_ORGANIZATION
--------------------------------------------------------------------------------
ALLOCATED_BYTES USED_BYTES NUM_VECTORS
--------------- ---------- -----------
VECTOR
IDX_DOCS_HNSW
INMEMORY NEIGHBOR GRAPH1179648 65660 3SQL> drop INDEX idx_docs_hnsw;索引已删除。SQL> -- IVF索引(基于分区)
SQL> CREATE VECTOR INDEX idx_docs_ivf2 ON documents_hnsw (embedding)3 ORGANIZATION NEIGHBOR PARTITIONS4 DISTANCE COSINE5 WITH TARGET ACCURACY 906 PARAMETERS (7 TYPE IVF,8 NEIGHBOR PARTITIONS 100, -- 分区数9 SAMPLES_PER_PARTITION 500, -- 每个分区采样数10 MIN_VECTORS_PER_PARTITION 50 -- 最小向量数/分区11 )12 PARALLEL 4;索引已创建。参考
Oracle AI Vector Search User’s Guide
6 Create Vector Indexes and Hybrid Vector Indexes
CREATE_INDEX
Getting Started with Oracle Database 23ai AI Vector Search
Getting started with vectors in 23ai
Using HNSW Vector Indexes in AI Vector Search
Hybrid Vector Index - a combination of AI Vector Search with Text Search