涿鹿镇做网站营销推广手段有什么
目录
一、空值和缺失值的处理
(一)、检测
识别缺失值的isnull()方法
识别非缺失值的notnull()方法
(二)、处理缺失值
1. 删除法
dropna()方法
2、替换法
fillna()缺失值替换
用平均值做填充
用特定值填充
3、插值法
二、重复值的处理
(一)、检测与处理重复值
1、数据重复
drop_duplicates
#对下载意愿进行删除---完全重复项
#删除某列---基于特定行列
2、特征重复
2.1、corr()相似度的计算方法为
2.2、equals()
三、异常值的处理
四、更改数据类型
一、空值和缺失值的处理
(一)、检测
识别缺失值的isnull()方法
识别非缺失值的notnull()方法
这两种方法在使用时返回的都是布尔值,即True和False。
结合sum函数、isnull()方法和notnull()方法,可以检测数据中缺失值的分布以及数据中一共含有多少缺失值。 isnull()方法和notnull()方法的结果正好相反,因此使用其中任意一个都可以识别出数据是否存在缺失值。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
filepath = "D:/Desktop/data/user_all_info.csv"
data = pd.read_csv(filepath)
print(data.head())a = data.isnull().sum()
print("使用isnnull()方法检测非缺失值:\n",a)
b = data.notnull().sum()
print("使用notnull()方法检测非缺失值:\n",b)
(二)、处理缺失值
1. 删除法
删除法是指将含有缺失值的特征或记录删除。
删除法分为删除观测记录和删除特征两种,它属于通过减少样本量来换取信息完整度的一种方法,是一种较为简单的缺失值处理方法。
dropna()方法
删除缺失值的,通过控制参数,既可以删除观测记录,又可以删除特征。
pandas.DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
| 参数名称 | 参数说明 |
| axis | 接收0或1。表示轴向,0为删除观测记录(行),1为删除特征(列)。默认为0 |
| how | 接收特定str。表示删除的形式,当取值为any时,表示只要有缺失值存在就执行删除操作;当取值为all时,表示当且仅当全部为缺失值时才执行删除操作。默认为any |
| subset | 接收array。表示进行去重的列/行。默认为None |
| inplace | 接收bool。表示是否在原表上进行操作。默认为False |
#数据量很大,空值很少
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
filepath = "D:/Desktop/data/user_all_info.csv"
data = pd.read_csv(filepath)
print(data.head())
print("删除之前:",data.shape)
c = data.dropna(axis=0,how="any")
print("行删除之后:",c.shape)
d = data.dropna(axis=1,how="any")
print("列删除之后:",d.shape)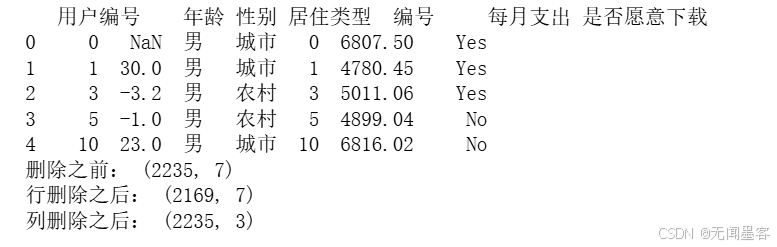
2、替换法
替换法是指用一个特定的值替换缺失值。
特征可分为数值型和类别型,两者出现缺失值时的处理方法也是不同的。
当缺失值所在特征为数值型时,通常利用其均值、中位数或众数等描述其集中趋势的统计量来代替缺失值。
当缺失值所在特征为类别型时,则选择使用众数来替换缺失值。
fillna()缺失值替换
pandas.DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
| 参数名称 | 参数说明 |
| value | 接收scalar、dict、Series或DataFrame。表示用于替换缺失值的值。默认为None |
| method | 接收特定str。表示填补缺失值的方式。 当取值为“backfilll”或“bfill”时表示使用下一个非缺失值来填补缺失值; 当取值为“pad”或“ffill”时表示使用上一个非缺失值来填补缺失值。默认为None |
| axis | 接收0或1。表示轴向。默认为None |
| inplace | 接收bool。表示是否在原表上进行操作。默认为False |
| limit | 接收int。表示填补缺失值个数上限,超过则不进行填补。默认为None |
| downcast | 接收dict。表示转换数据类型。默认为None |
用平均值做填充
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
filepath = "D:/Desktop/data/user_all_info.csv"
data = pd.read_csv(filepath)
print(data.head())
data_mean = data['每月支出'].mean()
data['每月支出'] = data['每月支出'].fillna(data_mean)
print(data['每月支出'].isnull().sum())
#保存
data.to_csv('D:/Desktop/data/0331.csv')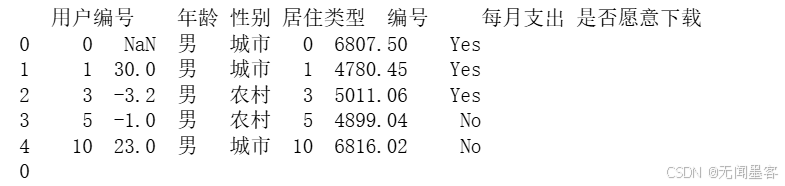
用特定值填充
df = pd.DataFrame({'A': [1, 2, np.nan, 4],'B': [np.nan, 5, 6, np.nan]})df_filled = df.fillna(0) #用0填充缺失值
print(df_filled)# 计算每列的平均值(注意排除NaN值)
mean_A = df['A'].mean()
mean_B = df['B'].mean()# 分别用平均值填充每列的缺失值
df['A'] = df['A'].fillna(mean_A)
df['B'] = df['B'].fillna(mean_B)
print(df)3、插值法
线性插值是一种较为简单的插值方法,它针对已知的值求出线性方程,通过求解线性方程得到缺失值。
多项式插值是利用已知的值拟合一个多项式,使得现有的数据满足这个多项式,再利用这个多项式求解缺失值,常见的多项式插值又分有拉格朗日插值和牛顿插值等。
样条插值是以可变样条来做出一条经过一系列点的光滑曲线的插值方法。插值样条由一些多项式组成,每一个多项式都由相邻两个数据点决定,这样可以保证两个相邻多项式及其导数在连接处连续。
从拟合结果可以看出,在多项式插值和样条插值两种情况下的拟合都非常出色,线性插值法只在自变量和因变量为线性关系的情况下拟合才较为出色。
在实际分析过程中,由于自变量与因变量的关系是线性的情况非常少见,所以在大多数情况下,多项式插值和样条插值是较为合适的选择。
SciPy库中的interpolate模块除了提供常规的插值法外,还提供了如在图形学领域具有重要作用的重心坐标插值(BarycentricInterpolator)等。在实际应用中,需要根据不同的场景选择合适的插值方法。
import numpy as np
from scipy.interpolate import interp1d
import matplotlib.pyplot as plt
# 创建自变量x
x = np.array([1, 2, 3, 4, 5, 8, 9, 10])
# 创建因变量y1
y1 = np.array([2, 8, 18, 32, 50, 128, 162, 200])
# 创建因变量y2
y2 = np.array([3, 5, 7, 9, 11, 17, 19, 21])
# 线性插值拟合x、y1
linear_ins_value1 = interp1d(x, y1, kind='linear')
# 线性插值拟合x、y2
linear_ins_value2 = interp1d(x, y2, kind='linear')
# 要插值的x值
x_new = np.array([6, 7])
# 计算插值结果
y1_new = linear_ins_value1(x_new)
y2_new = linear_ins_value2(x_new)
# 打印插值结果
print('当x为6、7时,使用线性插值y1为:', y1_new)
print('当x为6、7时,使用线性插值y2为:', y2_new)
# 绘制原始数据点和插值结果
plt.figure(figsize=(10, 5))
# 绘制y1的数据点和插值线
plt.subplot(1, 2, 1)
plt.scatter(x, y1, label='Original y1 data', color='blue')
plt.plot(x_new, y1_new, 'ro-', label='Interpolated y1 at x=6,7')
plt.xlabel('x')
plt.ylabel('y1')
plt.legend()
plt.title('Linear Interpolation of y1')
# 绘制y2的数据点和插值线
plt.subplot(1, 2, 2)
plt.scatter(x, y2, label='Original y2 data', color='green')
plt.plot(x_new, y2_new, 'ro-', label='Interpolated y2 at x=6,7')
plt.xlabel('x')
plt.ylabel('y2')
plt.legend()
plt.title('Linear Interpolation of y2')
# 显示图形
plt.tight_layout()
plt.show()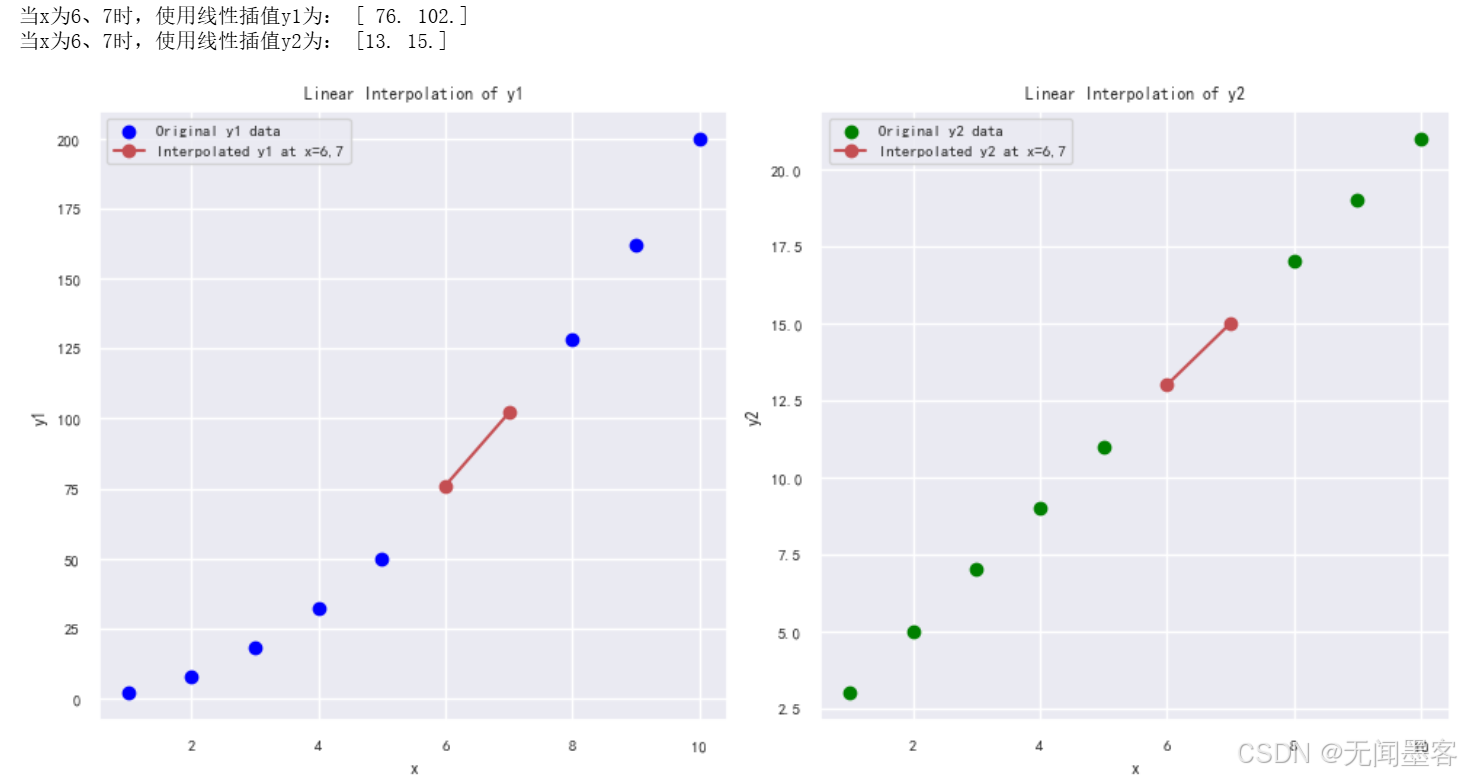
二、重复值的处理
(一)、检测与处理重复值
1、数据重复
drop_duplicates
使用该方法进行去重不会改变数据原始排列,并且兼具代码简洁和运行稳定的特点。
不仅支持单一特征的数据去重,还能够依据DataFrame的其中一个或多个特征进行去重操作
pandas.DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
| 参数名称 | 参数说明 |
| subset | 接收str或sequence。表示进行去重的列。默认为None |
| keep | 接收特定str。表示重复时保留第几个数据,“first”表示保留第一个;“last”表示保留最后一个;False表示只要有重复都不保留。默认为first |
| inplace | 接收bool。表示是否在原表上进行操作。默认为False |
| ignore_index | 接收bool。表示是否忽略索引。默认为False |
#对下载意愿进行删除---完全重复项
#对下载意愿进行删除---完全重复项
import pandas as pd
download = pd.DataFrame({'id': [1, 2, 3, 4, 4, 5],'name': ['小铭', '小月月', '彭岩', '刘华', '刘华', '周华'],'age': [18, 18, 29, 58, 58, 36],'height': [180, 180, 185, 175, 175, 178],'gender': ['女', '女', '男', '男', '男', '男']})
print("原始数据",download)
download_select = download.drop_duplicates()
print("依照 drop_duplicate 方法去重:\n",download_select) 
#删除某列---基于特定行列
#删除某列---基于特定行列
import pandas as pd
download = pd.DataFrame({'id': [1, 2, 3, 4, 5, 6],'name': ['小铭', '小月月', '彭岩', '刘华', '刘华', '周华'],'age': [18, 18, 29, 58, 58, 36],'height': [180, 180, 185, 175, 175, 178],'gender': ['女', '女', '男', '男', '男', '男']})
print("原始数据",download)
download_select = download.drop_duplicates(subset=['name','age'])
print("依照 drop_duplicate 方法去重:\n",download_select)
2、特征重复
要去除连续的特征重复,可以利用特征间的相似度将两个相似度为1的特征去除其中一个
2.1、corr()相似度的计算方法为
2.2、equals()
pandas.DataFrame.equals(other)
| 参数名称 | 参数说明 |
| other | 接收Series或DataFrame。表示要与第一个进行比较的另一个Series或DataFrame。无默认值 |