redis加速wordpress长沙优化科技
MiMo-VL-7B模型的开发包含两个序贯训练过程:(1)四阶段预训练,涵盖投影器预热、视觉-语言对齐、通用多模态预训练及长上下文监督微调(SFT),最终生成MiMo-VL-7B-SFT模型;(2)后续的后训练阶段,我们引入混合策略强化学习(MORL)创新框架,该框架无缝整合了感知精度、视觉定位准度、逻辑推理能力及人类/AI偏好的多样化奖励信号,最终产出MiMo-VL-7B-RL模型。

我们开源了MiMo-VL-7B系列模型,包括监督微调(SFT)和强化学习(RL)阶段的检查点。相信本报告连同这些模型将为开发具有强大推理能力的视觉语言模型提供宝贵洞见,最终惠及更广泛的研究社区。

| 模型 | 描述 | 下载 (HuggingFace) | 下载 (ModelScope) |
|---|---|---|---|
| MiMo-VL-7B-SFT | VLM with extraordinary reasoning potential after 4-stage pre-training | 🤗 XiaomiMiMo/MiMo-VL-7B-SFT | 🤖️ XiaomiMiMo/MiMo-VL-7B-SFT |
| MiMo-VL-7B-RL | RL model leapfrogging existing open-source models | 🤗 XiaomiMiMo/MiMo-VL-7B-RL | 🤖️ XiaomiMiMo/MiMo-VL-7B-RL |
评估结果
通用能力
在通用视觉语言理解任务中,MiMo-VL-7B模型实现了最先进的开源成果。

推理任务
在多模态推理中,无论是监督微调模型还是强化学习模型,在这些基准测试中的表现都显著优于所有对比的开源基线。

GUI任务
MiMo-VL-7B-RL具有出色的GUI理解和接地能力。作为通用VL模型,MiMo-VL实现了与专用GUI模型相当甚至更优的性能。

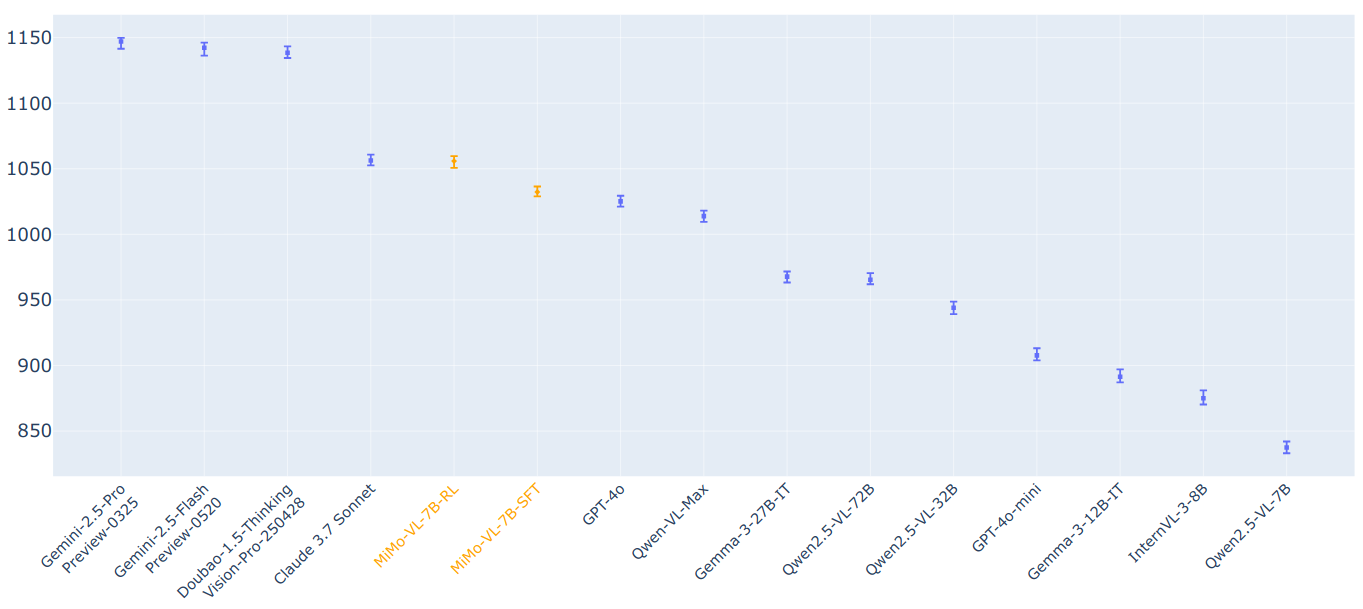
Elo评分
通过我们内部评估数据集和GPT-4o的评判,MiMo-VL-7B-RL在所有评估的开源视觉语言模型中获得了最高的Elo评分,在参数量从7B到72B的模型中排名第一。
快手上手
安装依赖
# It's highly recommanded to use `[decord]` feature for faster video loading.
pip install qwen-vl-utils[decord]==0.0.8
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor, BitsAndBytesConfig
from qwen_vl_utils import process_vision_infoquantization_config = BitsAndBytesConfig(load_in_4bit=True)# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("XiaomiMiMo/MiMo-VL-7B-SFT", torch_dtype="auto", device_map="auto",quantization_config=quantization_config
)# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-7B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )# default processer
processor = AutoProcessor.from_pretrained("XiaomiMiMo/MiMo-VL-7B-SFT")# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)messages = [{"role": "user","content": [{"type": "image","image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",},{"type": "text", "text": "Describe this image."},],}
]# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt",
)
inputs = inputs.to("cuda")# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)["<think>\nSo, let's describe the image. First, the scene is a beach at what looks like sunset or sunrise, with the sky having a soft, warm light. The ocean is in the background, with gentle waves. In the foreground, there's a woman and a dog. The woman is sitting on the sandy beach, wearing a plaid shirt and dark pants, barefoot. She's reaching out to give a high-five or shake hands with the dog. The dog is a light-colored Labrador, wearing a colorful harness, and it's sitting on the sand too. The sand has footprints, and the overall mood"]
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor, BitsAndBytesConfig
from qwen_vl_utils import process_vision_infoquantization_config = BitsAndBytesConfig(load_in_4bit=True)# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("XiaomiMiMo/MiMo-VL-7B-RL", torch_dtype="auto", device_map="auto",quantization_config=quantization_config
)# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-7B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )# default processer
processor = AutoProcessor.from_pretrained("XiaomiMiMo/MiMo-VL-7B-RL")# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)messages = [{"role": "user","content": [{"type": "image","image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",},{"type": "text", "text": "Describe this image."},],}
]# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt",
)
inputs = inputs.to("cuda")# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
["<think>\nSo, let's describe the image. First, the scene is a beach at sunset or sunrise, with the ocean in the background. The sky is light, maybe early morning or late afternoon. There's a woman and a dog. The woman is sitting on the sand, wearing a plaid shirt, dark pants, and no shoes. She's reaching out to high-five the dog. The dog is a light-colored Labrador, wearing a colorful harness, sitting on the sand too. The beach has smooth sand with some footprints, and the ocean waves are gentle. The lighting is warm, giving a serene and happy vibe"]