永康建设局网站种子搜索神器下载
1. 心理学
- 动物需要在复杂环境下有效关注值得注意的点
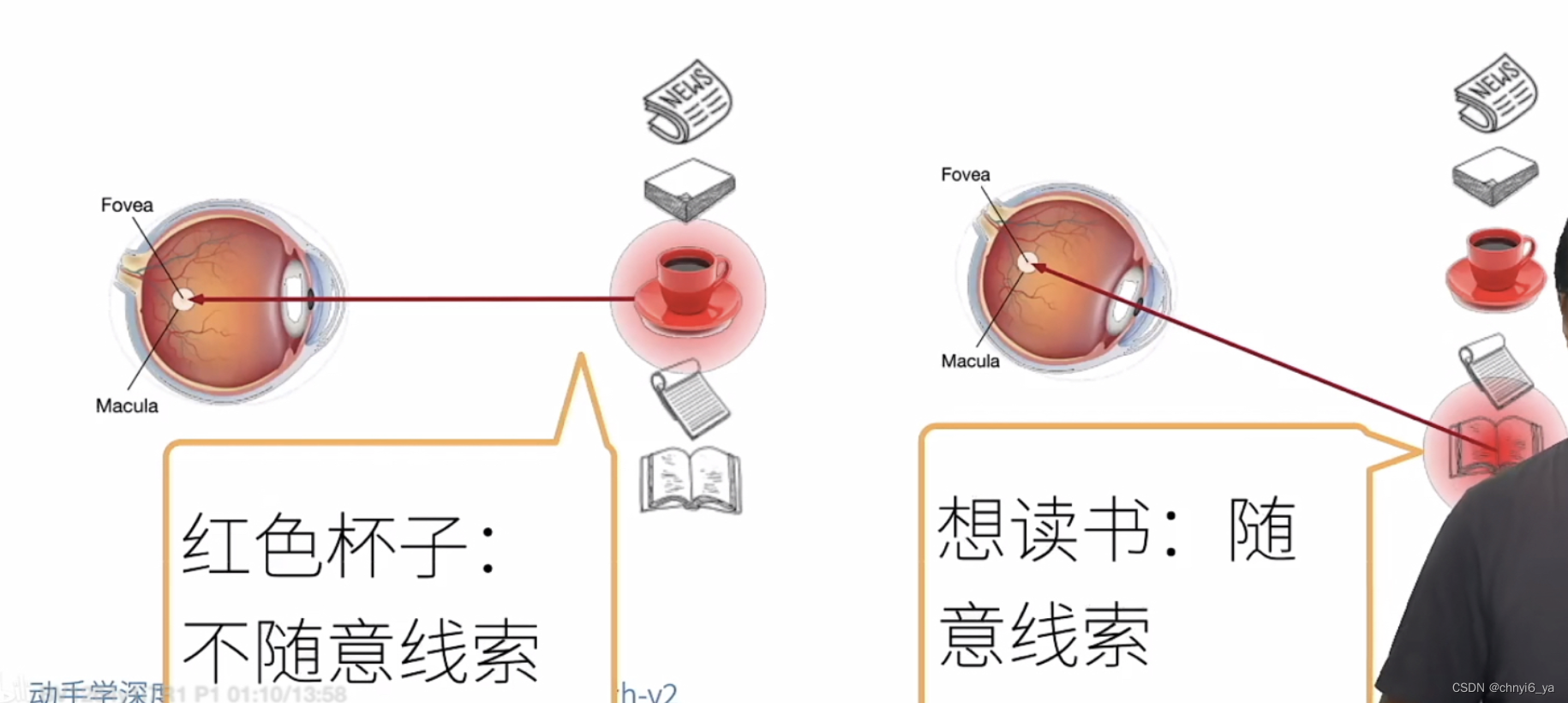
- 心理学框架:人类根据随意线索和不随意线索选择注意点
随意:随着自己的意识,有点强调主观能动性的意味。
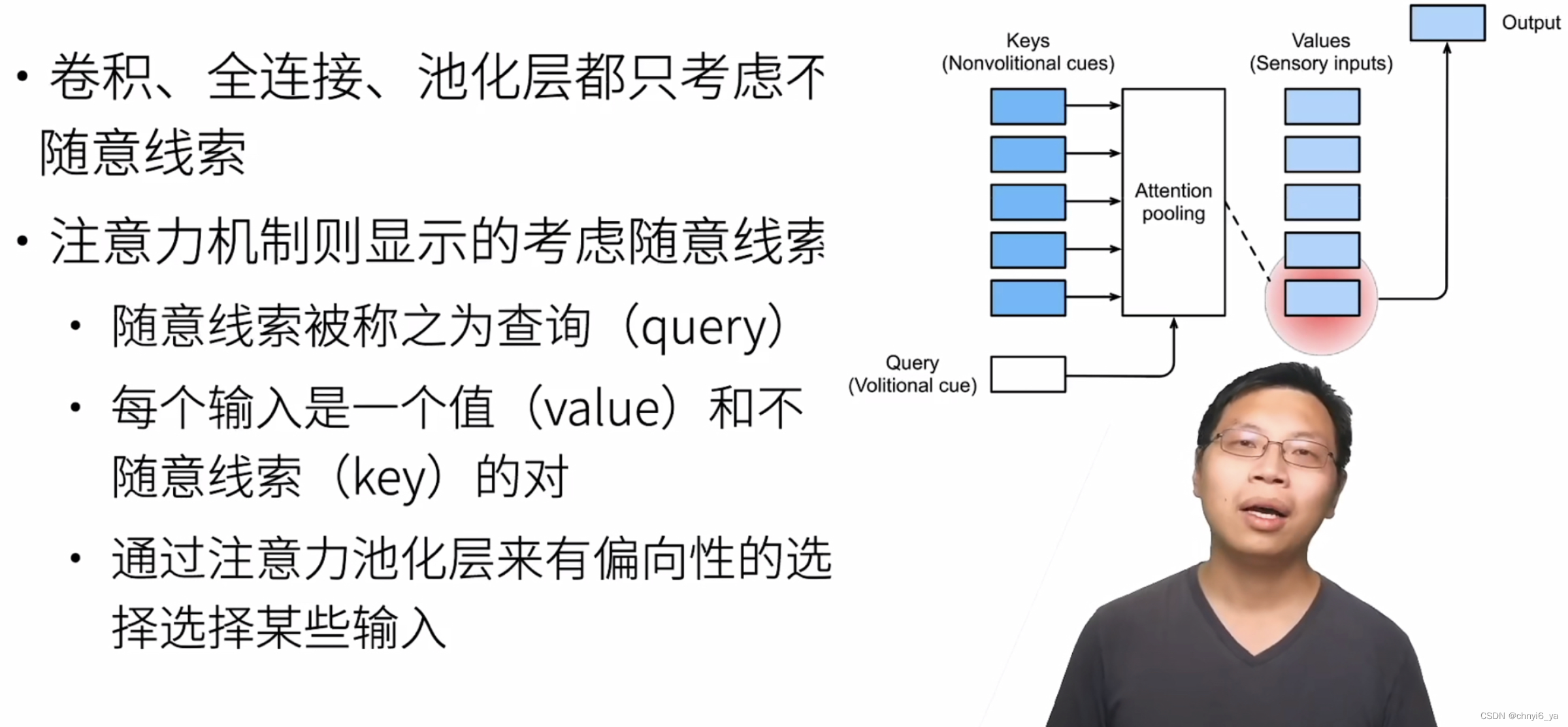
2. 注意力机制
2. 非参注意力池化层
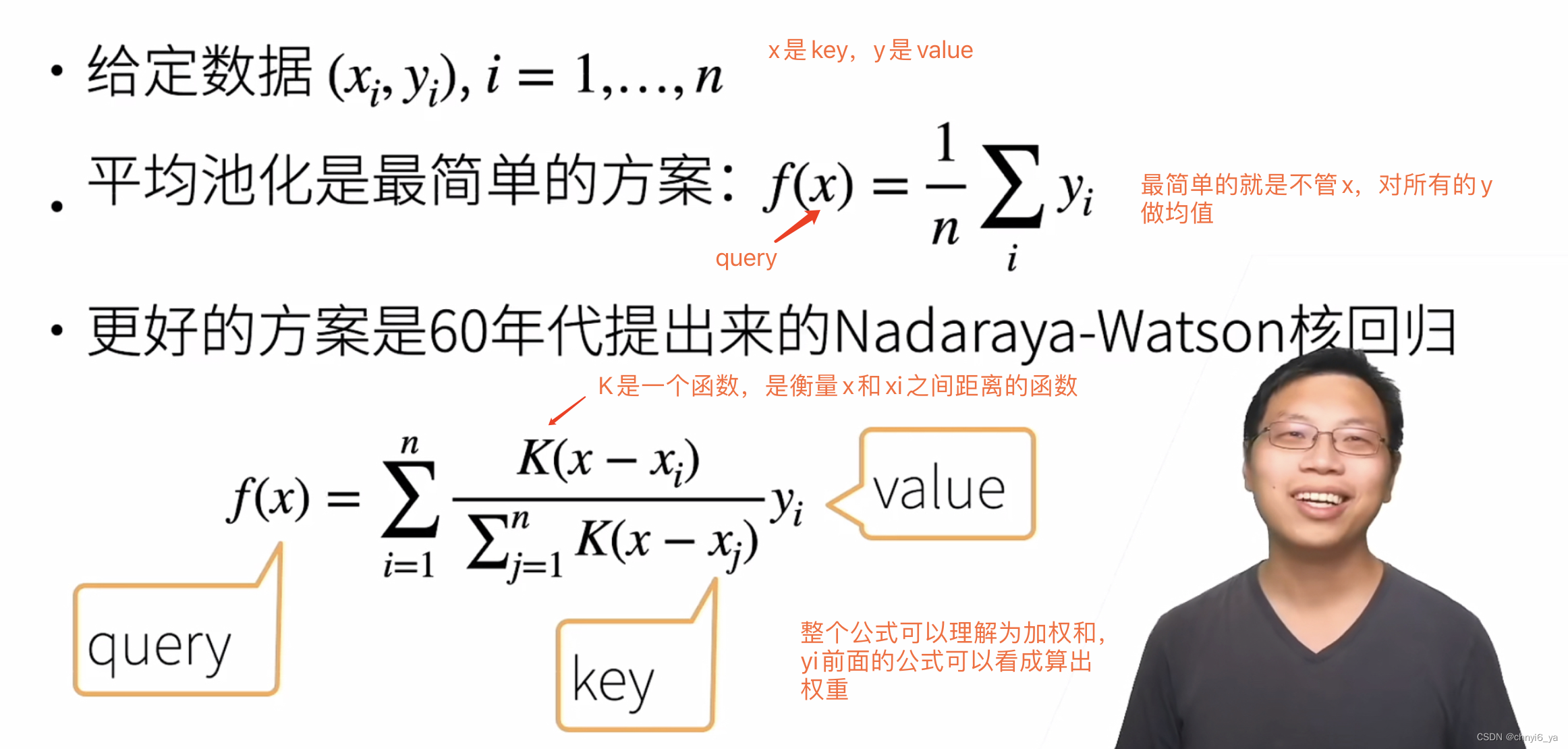
3. Nadaraya-Waston 核回归
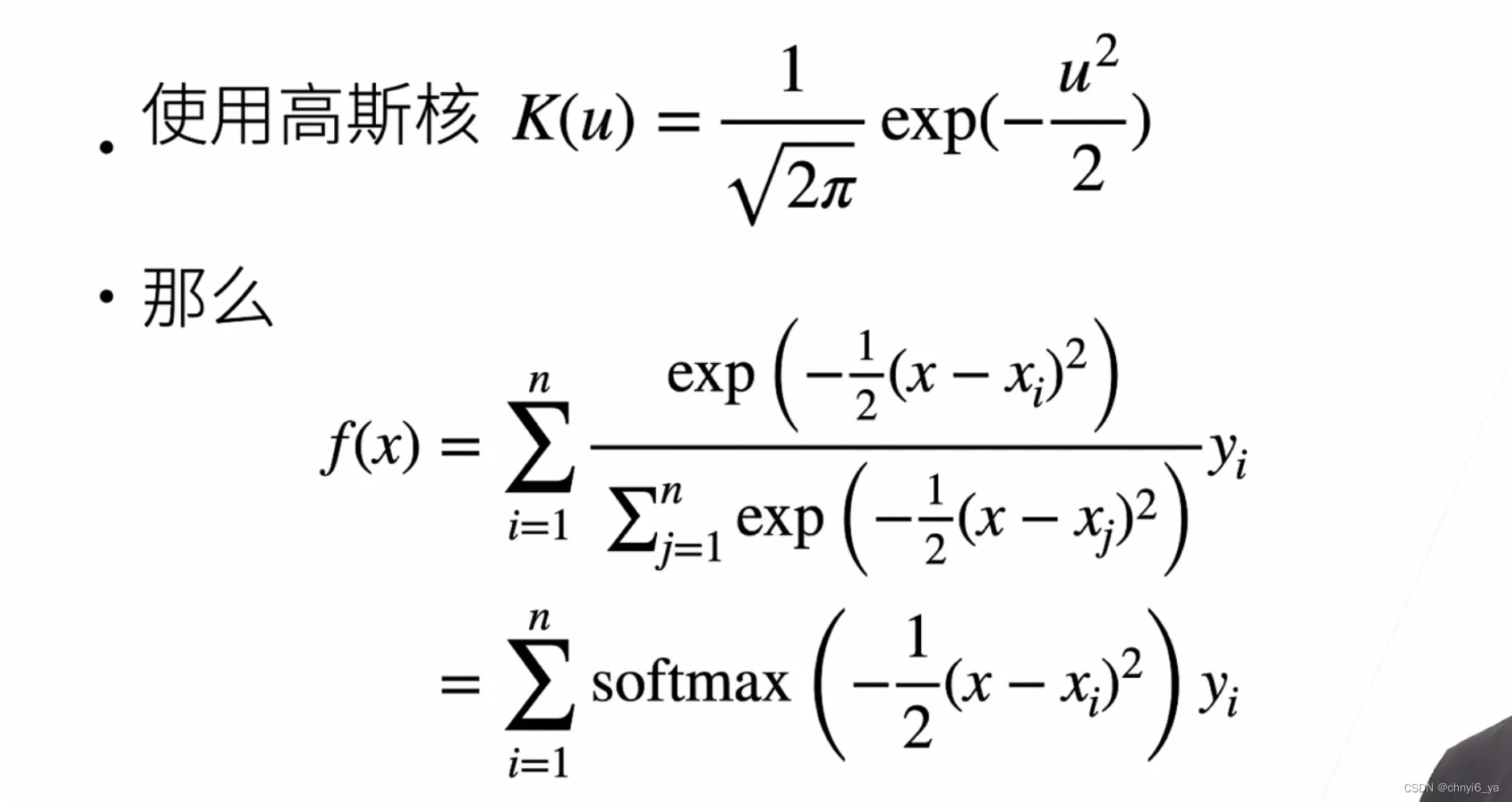
4. 参数化的注意力机制

5. 总结

6. 代码实现注意力汇聚:Nadaraya-Waston 核回归
import torch
from torch import nn
from d2l import torch as d2l
6.1 生成数据集

n_train = 50 # 训练样本数
x_train, _ = torch.sort(torch.rand(n_train) * 5) # 排序后的训练样本
def f(x):return 2 * torch.sin(x) + x**0.8y_train = f(x_train) + torch.normal(0.0, 0.5, (n_train,)) # 训练样本的输出
x_test = torch.arange(0, 5, 0.1) # 测试样本
y_truth = f(x_test) # 测试样本的真实输出
n_test = len(x_test) # 测试样本数
n_test
下面的函数将绘制所有的训练样本(样本由圆圈表示), 不带噪声项的真实数据生成函数 𝑓 (标记为“Truth”), 以及学习得到的预测函数(标记为“Pred”)。
def plot_kernel_reg(y_hat):d2l.plot(x_test, [y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'],xlim=[0, 5], ylim=[-1, 5])d2l.plt.plot(x_train, y_train, 'o', alpha=0.5);
6.2 平均汇聚
先使用最简单的估计器来解决回归问题。 基于平均汇聚来计算所有训练样本输出值的平均值:
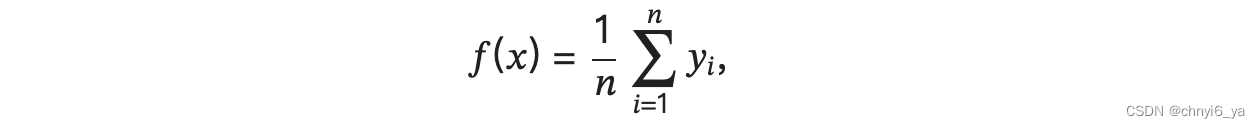
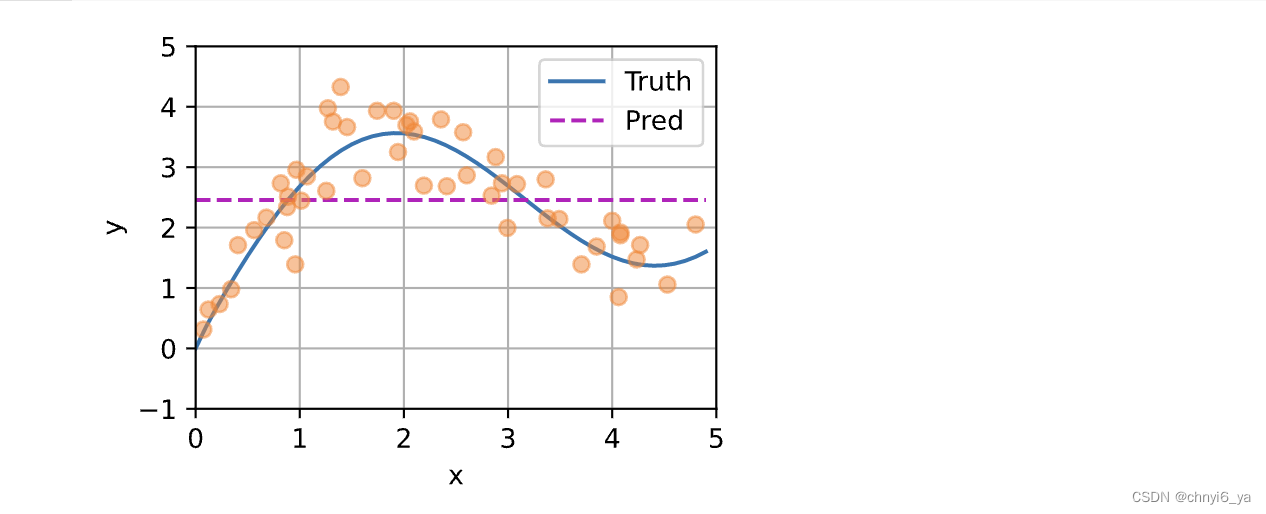
如下图所示,这个估计器确实不够聪明。 真实函数 𝑓 (“Truth”)和预测函数(“Pred”)相差很大。
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
plot_kernel_reg(y_hat)
6.3 非参数注意力汇聚
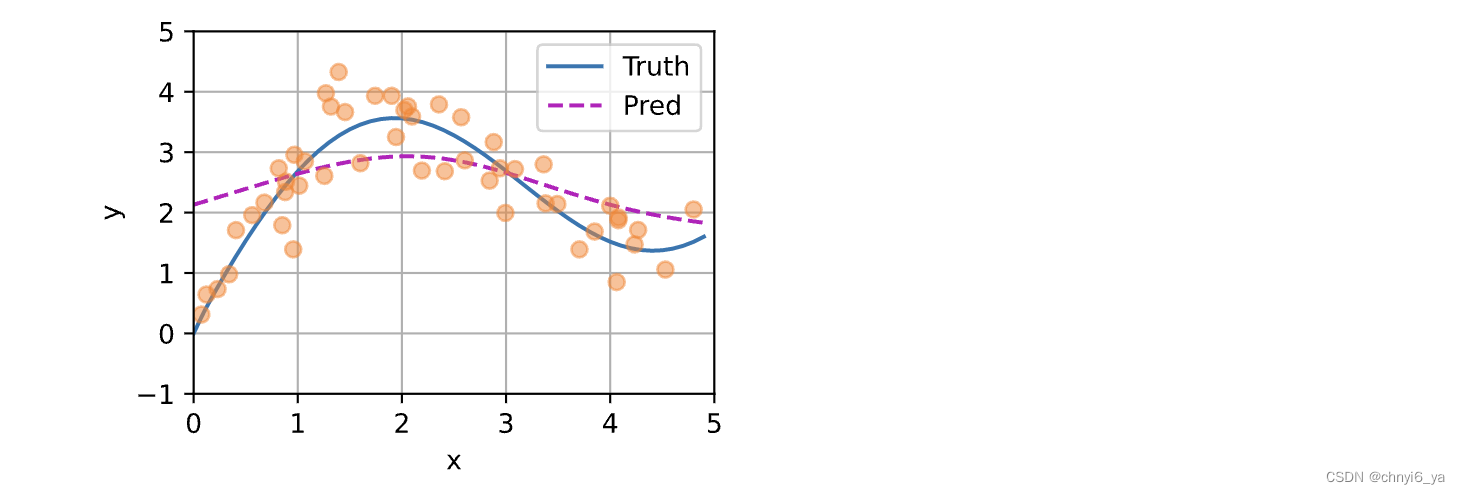
接下来,我们将基于这个非参数的注意力汇聚模型来绘制预测结果。 从绘制的结果会发现新的模型预测线是平滑的,并且比平均汇聚的预测更接近真实。
# X_repeat的形状:(n_test,n_train),
# 每一行都包含着相同的测试输入(例如:同样的查询)
X_repeat = x_test.repeat_interleave(n_train).reshape((-1, n_train))
# x_train包含着键。attention_weights的形状:(n_test,n_train),
# 每一行都包含着要在给定的每个查询的值(y_train)之间分配的注意力权重
attention_weights = nn.functional.softmax(-(X_repeat - x_train)**2 / 2, dim=1)
# y_hat的每个元素都是值的加权平均值,其中的权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
plot_kernel_reg(y_hat)
运行结果:
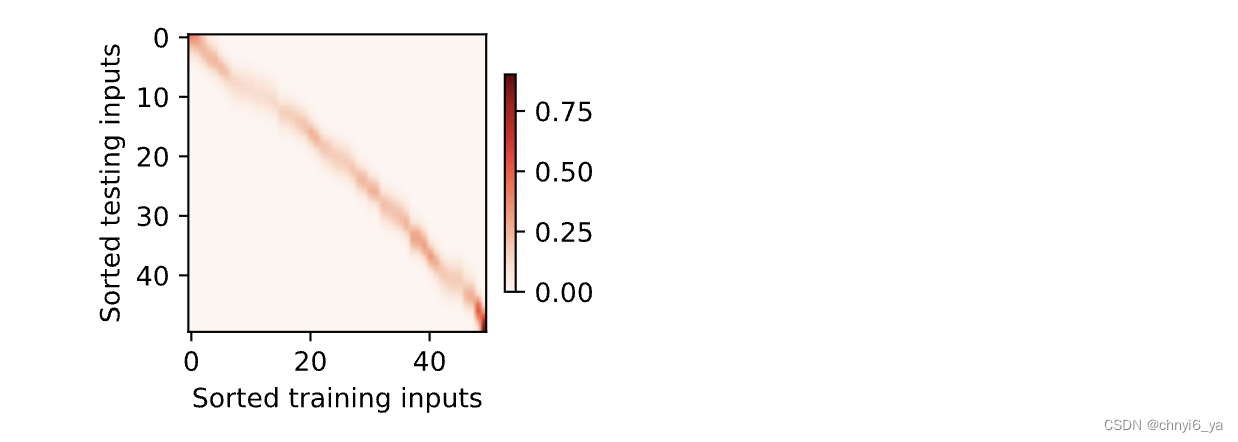
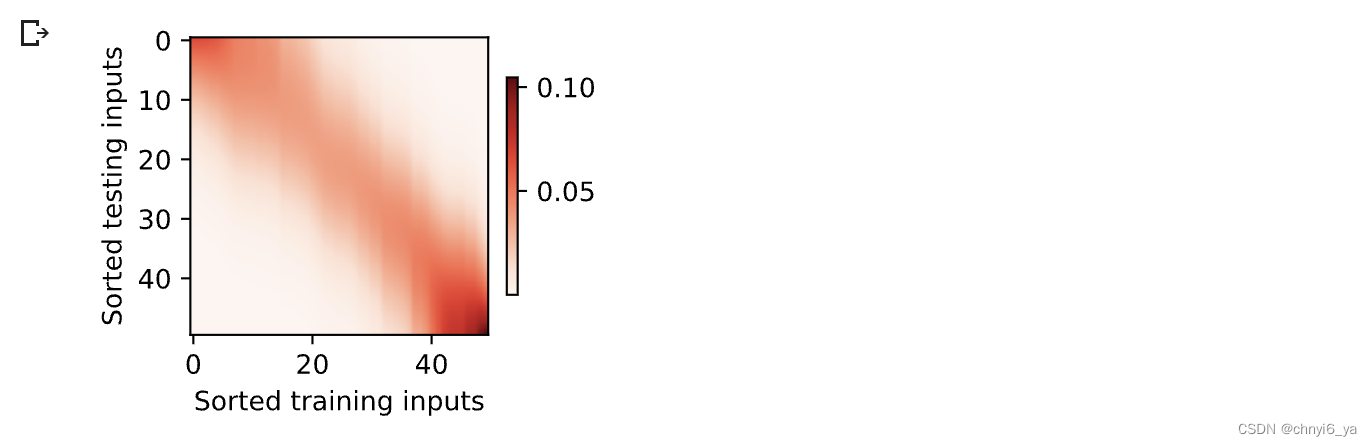
现在来观察注意力的权重。 这里测试数据的输入相当于查询,而训练数据的输入相当于键。 因为两个输入都是经过排序的,因此由观察可知“查询-键”对越接近, 注意力汇聚的注意力权重就越高。
d2l.show_heatmaps(attention_weights.unsqueeze(0).unsqueeze(0),xlabel='Sorted training inputs',ylabel='Sorted testing inputs')
运行结果:
6.4 带参数注意力汇聚
1. 批量矩阵乘法
因此,假定两个张量的形状分别是 (𝑛,𝑎,𝑏) 和 (𝑛,𝑏,𝑐) , 它们的批量矩阵乘法输出的形状为 (𝑛,𝑎,𝑐)
X = torch.ones((2, 1, 4))
Y = torch.ones((2, 4, 6))
torch.bmm(X, Y).shape
运行结果:

在注意力机制的背景中,我们可以使用小批量矩阵乘法来计算小批量数据中的加权平均值。
weights = torch.ones((2, 10)) * 0.1
values = torch.arange(20.0).reshape((2, 10))
torch.bmm(weights.unsqueeze(1), values.unsqueeze(-1))
运行结果:

2. 定义模型
基于带参数的注意力汇聚,使用小批量矩阵乘法, 定义Nadaraya-Watson核回归的带参数版本为:
class NWKernelRegression(nn.Module):def __init__(self, **kwargs):super().__init__(**kwargs)self.w = nn.Parameter(torch.rand((1,), requires_grad=True))def forward(self, queries, keys, values):# queries和attention_weights的形状为(查询个数,“键-值”对个数)queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))self.attention_weights = nn.functional.softmax(-((queries - keys) * self.w)**2 / 2, dim=1)# values的形状为(查询个数,“键-值”对个数)return torch.bmm(self.attention_weights.unsqueeze(1),values.unsqueeze(-1)).reshape(-1)
3. 训练
接下来,将训练数据集变换为键和值用于训练注意力模型。 在带参数的注意力汇聚模型中, 任何一个训练样本的输入都会和除自己以外的所有训练样本的“键-值”对进行计算, 从而得到其对应的预测输出。
# X_tile的形状:(n_train,n_train),每一行都包含着相同的训练输入
X_tile = x_train.repeat((n_train, 1))
# Y_tile的形状:(n_train,n_train),每一行都包含着相同的训练输出
Y_tile = y_train.repeat((n_train, 1))
# keys的形状:('n_train','n_train'-1)
keys = X_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
# values的形状:('n_train','n_train'-1)
values = Y_tile[(1 - torch.eye(n_train)).type(torch.bool)].reshape((n_train, -1))
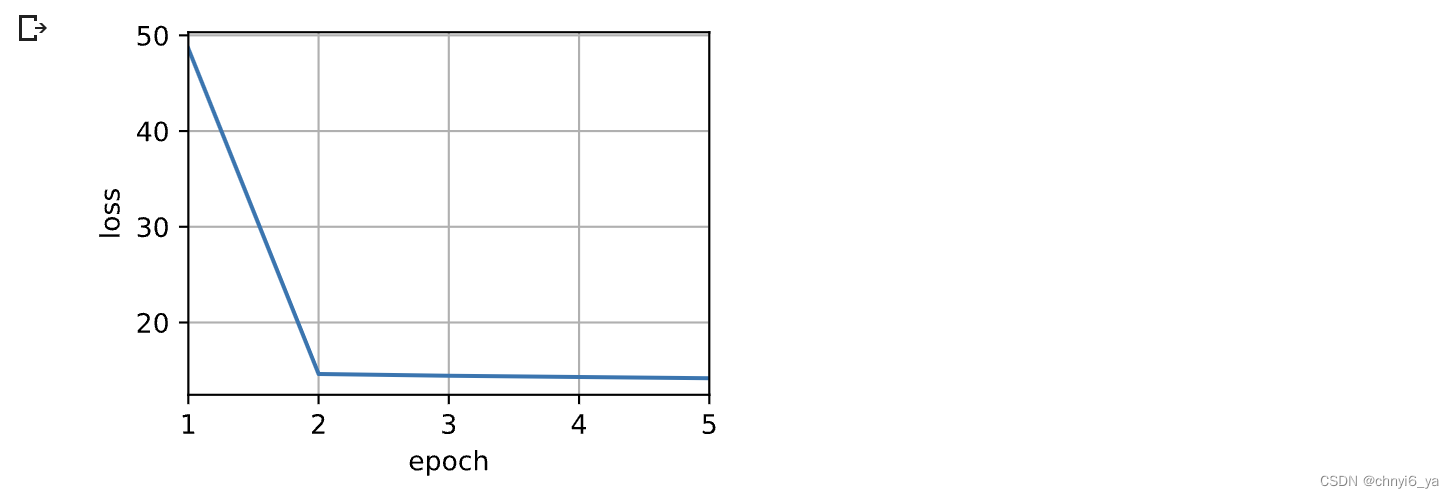
训练带参数的注意力汇聚模型时,使用平方损失函数和随机梯度下降。
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5])for epoch in range(5):trainer.zero_grad()l = loss(net(x_train, keys, values), y_train)l.sum().backward()trainer.step()print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')animator.add(epoch + 1, float(l.sum()))
运行结果:
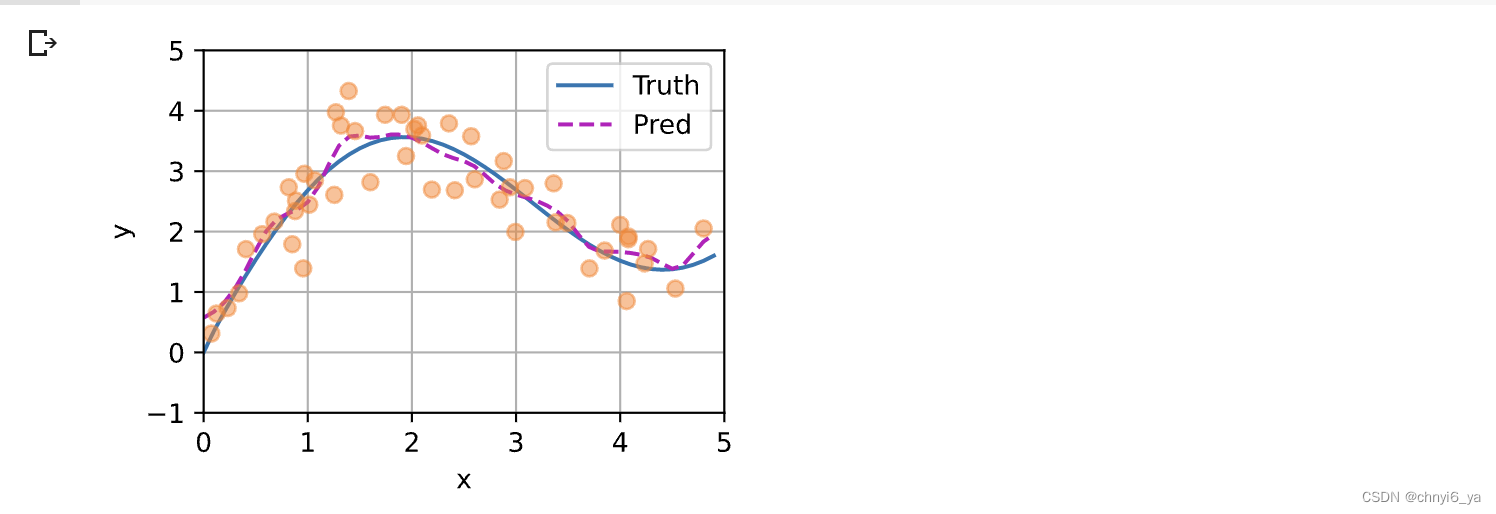
如下所示,训练完带参数的注意力汇聚模型后可以发现: 在尝试拟合带噪声的训练数据时, 预测结果绘制的线不如之前非参数模型的平滑。
# keys的形状:(n_test,n_train),每一行包含着相同的训练输入(例如,相同的键)
keys = x_train.repeat((n_test, 1))
# value的形状:(n_test,n_train)
values = y_train.repeat((n_test, 1))
y_hat = net(x_test, keys, values).unsqueeze(1).detach()
plot_kernel_reg(y_hat)
运行结果:
为什么新的模型更不平滑了呢? 下面看一下输出结果的绘制图: 与非参数的注意力汇聚模型相比, 带参数的模型加入可学习的参数后, 曲线在注意力权重较大的区域变得更不平滑。
d2l.show_heatmaps(net.attention_weights.unsqueeze(0).unsqueeze(0),xlabel='Sorted training inputs',ylabel='Sorted testing inputs')
运行结果: