网站设计建设方案站长工具是什么
文章目录
- 图片查询优化
- 为什么要优化?
- 怎么去优化
- Redis分布式缓存
- 场景
- 优势
- 设计
- key
- value
- expire
- 实现
- Caffeine本地缓存
- 场景
- 优势
- 设计
- 实现
- 扩展
- 多级缓存
- 优势
- 设计
- 实现
- 扩展
- 为什么是上述优化技术?
- 有没有更好的方案?
- **(1) 引入 CDN 加速静态资源**
- **(2) 异构缓存组合**
- **(3) 预加载与热点预测**
- 怎么评估方案?
- 图片上传优化
- 压缩
- 场景
- 优势
- 设计
- 格式转换
- 质量压缩(不推荐)
- 实现
- 扩展-秒传
- 扩展-分点上传 和 断点续传
- 图片加载优化
- 缩略图 / 预览图
- 缩略图
- 预览图 添加字段
- 懒加载
- 扩展知识-渐进加载
- CDN
- 浏览器缓存
- CDN
- 浏览器缓存
图片查询优化
为什么要优化?
经常访问的数据,如果我们一直从磁盘读取,肯定是从内存读要慢的,所以我们可以将数据放到内存。
经常访问而且读多写少的数据,我们就放到缓存,比如Redis中。
更具体一点:
1.高频访问的数据:系统首页(图片首页)、热门推荐内容
2.计算成本较高的数据:复杂查询结果、大量数据的统计结果
3.允许短时间延迟的数据:如不需要实时更新的排行榜、图片列表等
怎么去优化
Redis分布式缓存
场景
优势
高性能:单点Redis 读写QPS 可达 10 w/s
多种数据存储方式:string,set,zset,list,hash,bitmap
分布式:Redis Cluster构建高可用、高性能的分布式缓存,还提供哨兵集群提升可用性、分片集群机制提高扩展
设计
首先对listPictrueVOByPage接口缓存,按照 key-value-expire设计
key
接口支持不同的查询条件-不同的数据
查询条件对象转换为json ,可以用哈希md5压缩
由于使用分步数缓存,数据可能由多个项目 / 业务共享,所以需要在key的开头拼接前缀隔离。
yupicture:listPictureVOByPage:${查询条件key}
value
缓存从数据库中查找到的Page分页对象,存储格式选择:
- JSON
- 二进制
Redis:String
expire
必须设计过期时间,根据实际业务场景 / 缓存空间大小 / 数据一致性要求
此处 由于 查询条件多,利用率低 而且频繁更新,所以设置1H 以内即可
实现
Java中有很多操作Redis的库,比如Jedis、Lettuce等。Spring提供了Spring Data Redis 作为更高层的抽象,默认用Lettuce。这里我们用SpringBoot整合的,开发成本低。
<!-- Redis -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>spring:# Redis 配置redis:database: 0host: 127.0.0.1port: 6379timeout: 5000Junit测试Redis连接是否正常
@SpringBootTest
public class RedisStringTest {@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Testpublic void testRedisStringOperations() {// 获取操作对象ValueOperations<String, String> valueOps = stringRedisTemplate.opsForValue();// Key 和 ValueString key = "testKey";String value = "testValue";// 1. 测试新增或更新操作valueOps.set(key, value);String storedValue = valueOps.get(key);assertEquals(value, storedValue, "存储的值与预期不一致");// 2. 测试修改操作String updatedValue = "updatedValue";valueOps.set(key, updatedValue);storedValue = valueOps.get(key);assertEquals(updatedValue, storedValue, "更新后的值与预期不一致");// 3. 测试查询操作storedValue = valueOps.get(key);assertNotNull(storedValue, "查询的值为空");assertEquals(updatedValue, storedValue, "查询的值与预期不一致");// 4. 测试删除操作stringRedisTemplate.delete(key);storedValue = valueOps.get(key);assertNull(storedValue, "删除后的值不为空");}
}接口
@PostMapping("/list/page/vo/cache")
public BaseResponse<Page<PictureVO>> listPictureVOByPageWithCache(@RequestBody PictureQueryRequest pictureQueryRequest,HttpServletRequest request) {long current = pictureQueryRequest.getCurrent();long size = pictureQueryRequest.getPageSize();// 限制爬虫ThrowUtils.throwIf(size > 20, ErrorCode.PARAMS_ERROR);// 普通用户默认只能查看已过审的数据pictureQueryRequest.setReviewStatus(PictureReviewStatusEnum.PASS.getValue());// 构建缓存 keyString queryCondition = JSONUtil.toJsonStr(pictureQueryRequest);String hashKey = DigestUtils.md5DigestAsHex(queryCondition.getBytes());String redisKey = "yupicture:listPictureVOByPage:" + hashKey;// 从 Redis 缓存中查询ValueOperations<String, String> valueOps = stringRedisTemplate.opsForValue();String cachedValue = valueOps.get(redisKey);if (cachedValue != null) {// 如果缓存命中,返回结果Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);return ResultUtils.success(cachedPage);}// 查询数据库Page<Picture> picturePage = pictureService.page(new Page<>(current, size),pictureService.getQueryWrapper(pictureQueryRequest));// 获取封装类Page<PictureVO> pictureVOPage = pictureService.getPictureVOPage(picturePage, request);// 存入 Redis 缓存String cacheValue = JSONUtil.toJsonStr(pictureVOPage);// 5 - 10 分钟随机过期,防止雪崩int cacheExpireTime = 300 + RandomUtil.randomInt(0, 300);valueOps.set(redisKey, cacheValue, cacheExpireTime, TimeUnit.SECONDS);// 返回结果return ResultUtils.success(pictureVOPage);
}使用后,缓存加载是500ms , 后续请求降低延迟至20ms左右,而查询数据库需要50~100ms
Caffeine本地缓存
场景
本地应用频繁查询的数据,更快,但是服务器之间无法共享数据,而且不方便扩容。
- 第一种:数据量有限的小型数据集
- 第二种:单机应用
- 第三种:高频低延迟的场景
优势
精确控制缓存数量、大小、过期、缓存淘汰策略、支持异步操作、线程安全
不需要引入额外中间件,成本更低。
设计
本地缓存和分布式缓存的设计基本一致,主要有两点区别:
1.本地缓存需要自己创建初始化缓存结构
2.尽量减少数据量,比如key可以精简一点
实现
<!-- 本地缓存 Caffeine -->
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>3.1.8</version>
</dependency>private final Cache<String, String> LOCAL_CACHE =Caffeine.newBuilder().initialCapacity(1024).maximumSize(10000L).expireAfterWrite(5L, TimeUnit.MINUTES).build();业务
// 构建缓存 key
String queryCondition = JSONUtil.toJsonStr(pictureQueryRequest);
String hashKey = DigestUtils.md5DigestAsHex(queryCondition.getBytes());
String cacheKey = "listPictureVOByPage:" + hashKey;
// 从本地缓存中查询
String cachedValue = LOCAL_CACHE.getIfPresent(cacheKey);
if (cachedValue != null) {// 如果缓存命中,返回结果Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);return ResultUtils.success(cachedPage);
}响应速度提升更加明显
扩展
我们发现,使用本地缓存和分布式缓存的流程基本是一致的。那么思考一下,如果你想灵活地切换使用本地缓存/ 分布式缓存,应该怎么实现呢。
策略 / 模板方法 模式
多级缓存
类似计组中的缓存
优势
结合了多种缓存,性能提升更加明显
提高容错,及时Redis宕机了,本地服务能够减少对数据库的依赖
设计
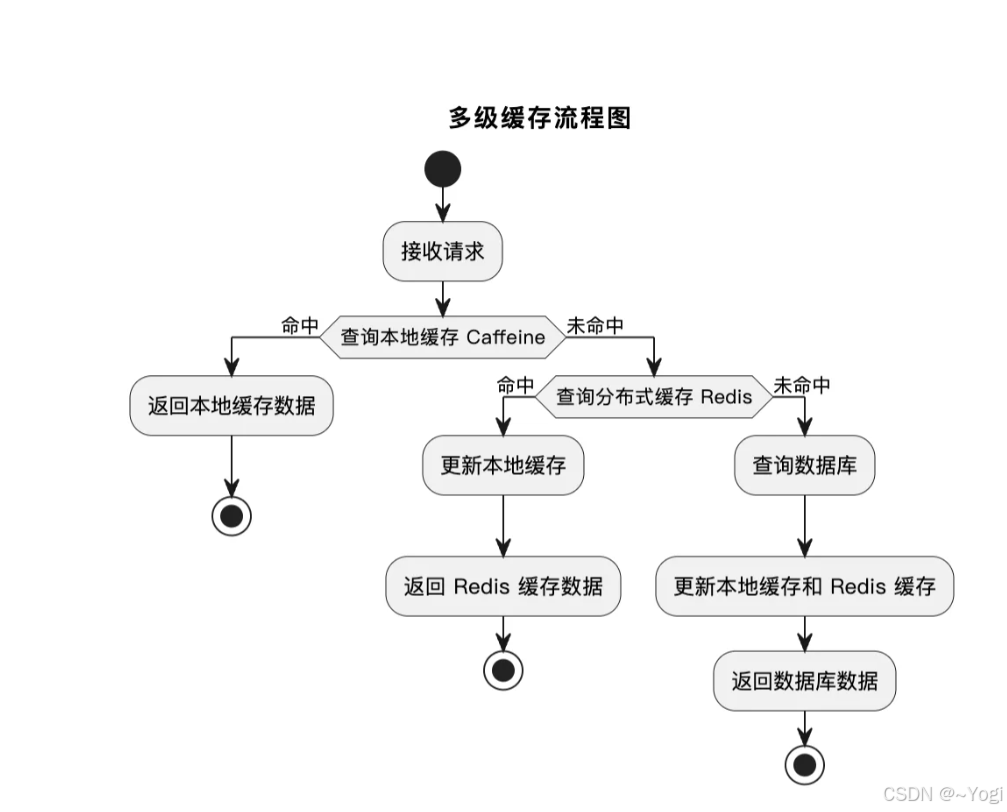
实现
// 构建缓存 key
String queryCondition = JSONUtil.toJsonStr(pictureQueryRequest);
String hashKey = DigestUtils.md5DigestAsHex(queryCondition.getBytes());
String cacheKey = "yupicture:listPictureVOByPage:" + hashKey;// 1. 查询本地缓存(Caffeine)
String cachedValue = LOCAL_CACHE.getIfPresent(cacheKey);
if (cachedValue != null) {Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);return ResultUtils.success(cachedPage);
}
// 2. 查询分布式缓存(Redis)
ValueOperations<String, String> valueOps = stringRedisTemplate.opsForValue();
cachedValue = valueOps.get(cacheKey);
if (cachedValue != null) {// 如果命中 Redis,存入本地缓存并返回LOCAL_CACHE.put(cacheKey, cachedValue);Page<PictureVO> cachedPage = JSONUtil.toBean(cachedValue, Page.class);return ResultUtils.success(cachedPage);
}
// 3. 查询数据库
Page<Picture> picturePage = pictureService.page(new Page<>(current, size),pictureService.getQueryWrapper(pictureQueryRequest));
Page<PictureVO> pictureVOPage = pictureService.getPictureVOPage(picturePage, request);// 4. 更新缓存
String cacheValue = JSONUtil.toJsonStr(pictureVOPage);
// 更新本地缓存
LOCAL_CACHE.put(cacheKey, cacheValue);
// 更新 Redis 缓存,设置过期时间为 5 分钟
valueOps.set(cacheKey, cacheValue, 5, TimeUnit.MINUTES);扩展
1.手动刷新
在某些情况下,数据更新较为频繁,但自动刷新机制可能存在延迟 ,可以通过手动刷新来解决。
比如:
- 提供一个刷新缓存的接口,仅管理员可用
- 提供管理后台,支持管理员手动刷新指定缓存
2.缓存三件套预防
缓存击穿:热点数据过期后,大量请求直接打到数据库。
解决方案:设置热点数据超长过期时间 / 互斥锁Redisson 控制缓存刷新
缓存穿透:用户频繁请求不存在的数据,导致大量请求直接触发数据库查询
解决方案:对无效查询结果进行缓存比如设置空值缓存 / boolean过滤器
缓存雪崩:大量缓存同时过期,导致请求直接打到数据库,系统崩溃。
解决方案:设置不同的缓存过期时间 / 使用多级缓存
3.热点图片缓存识别
采用热key探测技术,实时对图片的访问量进行统计,并自动将热点图片添加到内存缓存,以应对大量的高频访问。
4.查询优化
建立合适的索引尽量命中索引/覆盖索引
5.代码优化
为什么是上述优化技术?
- Caffeine(本地缓存):
- 低延迟:本地内存缓存(Caffeine)直接运行在应用服务器上,避免了网络开销,响应时间可缩短到 毫秒级(甚至微秒级)。
- 减少 Redis 负载:高频访问的热点数据(如热门图片)存储在本地,减少 Redis 的查询压力。
- 抗抖动:本地缓存能抵御网络波动或 Redis 服务短暂不可用的情况。
- 数据结构灵活:Caffeine 支持按需配置淘汰策略(如 LRU、LFU),适合应用层细粒度控制。
- Redis(分布式缓存):
- 高并发与分布式支持:Redis 是内存数据库,支持 毫秒级响应,且天然支持分布式部署(如集群模式),适合多节点应用共享缓存。
- 持久化与高可用:Redis 的 RDB/AOF 持久化可防止数据丢失,主从复制和哨兵模式可实现高可用。
- 丰富的数据结构:Redis 支持哈希(Hash)、列表(List)等结构,适合存储图片元数据(如缩略图路径、标签、访问频率)。
- 全局一致性:Caffeine 是本地缓存,无法跨节点共享数据,而 Redis 可作为全局缓存层。
- MySQL(持久化存储):
- 数据安全与完整性:MySQL 提供事务支持和 ACID 特性,适合存储原始图片数据(如 BLOB 字段)和元数据(如图片标签、用户信息)。
- 复杂查询能力:MySQL 支持 SQL 查询,适合处理多条件组合查询(如按标签、用户、时间范围筛选图片)。
- 扩展性:通过分库分表、读写分离等方案,可应对大规模数据存储需求。
有没有更好的方案?
(1) 引入 CDN 加速静态资源
-
适用场景:图片访问量极高且地理位置分散。
-
优势
:
- CDN 可缓存静态资源(如图片)到全球节点,减少回源请求,降低延迟。
- 与 Redis 结合,可将 CDN 缓存失效策略与 Redis 的 TTL 对齐。
-
知识库关联:知识库 [2] 提到 MySQL 存储图片时需考虑传输效率,CDN 可弥补 MySQL 的网络延迟问题。
(2) 异构缓存组合
-
方案
:
- Caffeine + Redis + Memcached:Memcached 的内存效率更高,适合纯 Key-Value 缓存;
- Redis + 分布式文件缓存(如 Ceph):结合 Redis 的元数据缓存和分布式文件系统的块存储。
(3) 预加载与热点预测
-
方案
:
- 预加载:根据用户行为(如热门标签)提前将数据加载到 Caffeine 或 Redis;
- 机器学习预测:通过历史访问数据预测热点图片,动态调整缓存策略。
怎么评估方案?
- 性能:优先保证热点数据的低延迟;
- 成本:平衡存储和计算资源的投入;
- 扩展性:支持未来数据量增长和高并发场景。
图片上传优化
压缩
场景
优势
设计
格式转换
1.Webp
2.AVIF
质量压缩(不推荐)
实现
1.本地图像处理库操作
2.第三方云服务
3.对已上传的图片进行压缩处理
这里我们使用数据万象的服务,它提供了两种方式: 访问实时/上传实时
修改CosManager
public PutObjectResult putPictureObject(String key, File file) {PutObjectRequest putObjectRequest = new PutObjectRequest(cosClientConfig.getBucket(), key,file);// 对图片进行处理(获取基本信息也被视作为一种处理)PicOperations picOperations = new PicOperations();// 1 表示返回原图信息picOperations.setIsPicInfo(1);List<PicOperations.Rule> rules = new ArrayList<>();// 图片压缩(转成 webp 格式)String webpKey = FileUtil.mainName(key) + ".webp";PicOperations.Rule compressRule = new PicOperations.Rule();compressRule.setRule("imageMogr2/format/webp");compressRule.setBucket(cosClientConfig.getBucket());compressRule.setFileId(webpKey);rules.add(compressRule);// 构造处理参数picOperations.setRules(rules);putObjectRequest.setPicOperations(picOperations);return cosClient.putObject(putObjectRequest);
}修改PictureUploadTemplate,从图片处理结果中获取缩略图,并设置到返回结果中
try {// 创建临时文件file = File.createTempFile(uploadPath, null);// 处理文件来源(本地或 URL)processFile(inputSource, file);// 上传图片到对象存储PutObjectResult putObjectResult = cosManager.putPictureObject(uploadPath, file);ImageInfo imageInfo = putObjectResult.getCiUploadResult().getOriginalInfo().getImageInfo();ProcessResults processResults = putObjectResult.getCiUploadResult().getProcessResults();List<CIObject> objectList = processResults.getObjectList();if (CollUtil.isNotEmpty(objectList)) {CIObject compressedCiObject = objectList.get(0);// 封装压缩图返回结果return buildResult(originFilename, compressedCiObject);}// 封装原图返回结果return buildResult(originFilename, file, uploadPath, imageInfo);
} catch (Exception e) {log.error("图片上传到对象存储失败", e);throw new BusinessException(ErrorCode.SYSTEM_ERROR, "上传失败");
}编写新的封装返回结果方法,从压缩图中获取图片信息
private UploadPictureResult buildResult(String originFilename, CIObject compressedCiObject) {UploadPictureResult uploadPictureResult = new UploadPictureResult();int picWidth = compressedCiObject.getWidth();int picHeight = compressedCiObject.getHeight();double picScale = NumberUtil.round(picWidth * 1.0 / picHeight, 2).doubleValue();uploadPictureResult.setPicName(FileUtil.mainName(originFilename));uploadPictureResult.setPicWidth(picWidth);uploadPictureResult.setPicHeight(picHeight);uploadPictureResult.setPicScale(picScale);uploadPictureResult.setPicFormat(compressedCiObject.getFormat());uploadPictureResult.setPicSize(compressedCiObject.getSize().longValue());// 设置图片为压缩后的地址uploadPictureResult.setUrl(cosClientConfig.getHost() + "/" + compressedCiObject.getKey());return uploadPictureResult;
}压缩后原图288KB ->135.5KB 效果显著
扩展-秒传
文件秒传是基于文件的唯一标识 (如MD5、SHA-256)对文件内容进行快速校验,避免重复上传的方法,在大型文件传输场景下非常重要。可以提高性能、节约贷款和存储资源。
实现方案
1.客户端生成文件唯一标识:上传前,通过客户端计算文件的hash,生成一个指纹/版本号
2.服务端校验,查询是否已存在文件
- 若存在相同文件,则直接返回文件的存储路径
- 若不存在相同文件,则接收并存储新文件,同时记录指纹信息
demo
// 计算文件指纹
String md5 = SecureUtil.md5(file);
// 从数据库中查询已有的文件
List<Picture> pictureList = pictureService.lambdaQuery().eq(Picture::getMd5, md5).list();
// 文件已存在,秒传
if (CollUtil.isNotEmpty(pictureList)) {// 直接复用已有文件的信息,不必重复上传文件Picture existPicture = pictureList.get(0);
} else {// 文件不存在,实际上传逻辑
}为什么这里不适合
1.文件小、而且不易重复
2.使用COS对象对象存储,只能通过唯一地址取文件,无法完全自定义文件的存储结构,也不支持文件快捷方式。因此秒传的地址必须用和原文件相同的对象路径,可能导致用户A上传的地址,等于B的地址
扩展-分点上传 和 断点续传
图片加载优化
目的
提升页面加载速度、减少带宽消耗
缩略图 / 预览图
缩略图
修改CosManager的图片上传,补充对缩略图的处理
public PutObjectResult putPictureObject(String key, File file) {PutObjectRequest putObjectRequest = new PutObjectRequest(cosClientConfig.getBucket(), key,file);// 对图片进行处理(获取基本信息也被视作为一种处理)PicOperations picOperations = new PicOperations();// 1 表示返回原图信息picOperations.setIsPicInfo(1);List<PicOperations.Rule> rules = new ArrayList<>();// 图片压缩(转成 webp 格式)String webpKey = FileUtil.mainName(key) + ".webp";PicOperations.Rule compressRule = new PicOperations.Rule();compressRule.setRule("imageMogr2/format/webp");compressRule.setBucket(cosClientConfig.getBucket());compressRule.setFileId(webpKey);rules.add(compressRule);// 缩略图处理,仅对 > 20 KB 的图片生成缩略图
if (file.length() > 2 * 1024) {PicOperations.Rule thumbnailRule = new PicOperations.Rule();thumbnailRule.setBucket(cosClientConfig.getBucket());String thumbnailKey = FileUtil.mainName(key) + "_thumbnail." + FileUtil.getSuffix(key);thumbnailRule.setFileId(thumbnailKey);// 缩放规则 /thumbnail/<Width>x<Height>>(如果大于原图宽高,则不处理)thumbnailRule.setRule(String.format("imageMogr2/thumbnail/%sx%s>", 128, 128));rules.add(thumbnailRule);}// 构造处理参数picOperations.setRules(rules);putObjectRequest.setPicOperations(picOperations);return cosClient.putObject(putObjectRequest);
}修改PictureUploadTemplate上传图片,获取缩略图
ProcessResults processResults = putObjectResult.getCiUploadResult().getProcessResults();
List<CIObject> objectList = processResults.getObjectList();
if (CollUtil.isNotEmpty(objectList)) {CIObject compressedCiObject = objectList.get(0);// 缩略图默认等于压缩图CIObject thumbnailCiObject = compressedCiObject;// 有生成缩略图,才得到缩略图if (objectList.size() > 1) {thumbnailCiObject = objectList.get(1);}// 封装压缩图返回结果return buildResult(originFilename, compressedCiObject, thumbnailCiObject);
}修改封装返回结果,将缩略图路径设置
private UploadPictureResult buildResult(String originFilename, CIObject compressedCiObject, CIObject thumbnailCiObject) {UploadPictureResult uploadPictureResult = new UploadPictureResult();// ...// 设置缩略图uploadPictureResult.setThumbnailUrl(cosClientConfig.getHost() + "/" + thumbnailCiObject.getKey());return uploadPictureResult;
}同步修改Service方法
// 构造要入库的图片信息
Picture picture = new Picture();
picture.setUrl(uploadPictureResult.getUrl());
picture.setThumbnailUrl(uploadPictureResult.getThumbnailUrl());
String picName = uploadPictureResult.getPicName();预览图 添加字段
使用Thumbnailator 库做图片的压缩
使用webp-imageio库来压缩转换webp格式
依赖
<!-- https://mvnrepository.com/artifact/net.coobird/thumbnailator -->
<dependency><groupId>net.coobird</groupId><artifactId>thumbnailator</artifactId><version>0.4.20</version>
</dependency><!-- https://mvnrepository.com/artifact/org.sejda.imageio/webp-imageio -->
<dependency><groupId>org.sejda.imageio</groupId><artifactId>webp-imageio</artifactId>
<version>0.1.6</version>
</dependency>
测试
@SpringBootTest
@Slf4j
public class PictureProcessTest {/*** 生成缩略图*/@Testpublic void toThumbnailImage() throws IOException {/** size(width,height) 若图片横比256小,高比256小,不变*/// jpg 格式Thumbnails.of("/static/test.jpg").size(256, 256).toFile("/static/toThumbnailImage.jpg");// png 格式Thumbnails.of("/static/test.png").size(256, 256).toFile("/static/toThumbnailImage_png.png");Thumbnails.of("/static/test.webp").size(256, 256).toFile("/static/toThumbnailImage_webp.webp");log.info("图片压缩缩略图成功");}/*** 生成压缩图(webp)预览图*/@Testpublic void toPreviewImage() {// 旧文件地址// String oldFile = "/static/test.jpg";// String newFile = "/static/toPreviewImage_jpg.webp";// String oldFile = "/static/test.png";// String newFile = "/static/toPreviewImage_png.webp";String oldFile = "/static/test.webp";String newFile = "/static/toPreviewImage_webp.webp";try {// 获取原始文件的编码BufferedImage image = ImageIO.read(new File(oldFile));// 创建WebP ImageWriter实例ImageWriter writer = ImageIO.getImageWritersByMIMEType("image/webp").next();// 配置编码参数WebPWriteParam writeParam = new WebPWriteParam(writer.getLocale());// 设置压缩模式writeParam.setCompressionMode(WebPWriteParam.MODE_DEFAULT);// 配置ImageWriter输出writer.setOutput(new FileImageOutputStream(new File(newFile)));// 进行编码,重新生成新图片writer.write(null, new IIOImage(image, null, null), writeParam);log.info("图片转Webp成功");} catch (Exception e) {log.error("异常");}}
}工具类
@Component
@Slf4j
public class PictureProcessUtils {/*** 转换缩略图* - 格式:256 * 256* - 如果原图宽高小于设定值,不修改* - (Thumbnails的缩略宽高小于设定值默认好像是不会修改的,为了清晰一点,自己又添加一个判断逻辑)** @param originalImage 原图*/public void toThumbnailImage(File originalImage, File thumbnailFile) {try {// 获取原图的宽高BufferedImage image = ImageIO.read(originalImage);int originalWidth = image.getWidth();int originalHeight = image.getHeight();// 设置目标尺寸int targetWidth = 256;int targetHeight = 256;// 如果目标尺寸大于原图的尺寸,不进行缩放if (targetWidth > originalWidth || targetHeight > originalHeight) {targetWidth = originalWidth;targetHeight = originalHeight;}// 生成缩略图Thumbnails.of(originalImage).size(targetWidth, targetHeight).toFile(thumbnailFile);} catch (IOException e) {log.error("生成缩略图失败", e);throw new BusinessException(ErrorCode.SYSTEM_ERROR, "生成缩略图是失败");}}/*** 转换为压缩图(预览图)* - webp 格式** @param originalImage 原图* @param previewImage 生成的预览图*/public void toPreviewImage(File originalImage, File previewImage) {ImageWriter writer = null;FileImageOutputStream outputStream = null;try {// 读取原始图片BufferedImage image = ImageIO.read(originalImage);// 获取 ImageWriter 实例writer = ImageIO.getImageWritersByMIMEType("image/webp").next();// 配置编码参数WebPWriteParam writeParam = new WebPWriteParam(writer.getLocale());writeParam.setCompressionMode(WebPWriteParam.MODE_DEFAULT);// 创建输出流outputStream = new FileImageOutputStream(previewImage);writer.setOutput(outputStream);// 编码并生成新图片writer.write(null, new IIOImage(image, null, null), writeParam);} catch (IOException e) {log.error("生成压缩图(预览图)失败,原图路径:{},预览图路径:{}", originalImage.getAbsolutePath(), previewImage.getAbsolutePath(), e);throw new BusinessException(ErrorCode.SYSTEM_ERROR, "生成压缩图(预览图)失败");} finally {// 确保资源被正确关闭if (outputStream != null) {try {outputStream.close();} catch (IOException e) {log.error("关闭 FileImageOutputStream 时发生错误", e);}}if (writer != null) {writer.dispose();}}}懒加载
懒加载可以避免一次性加载所有图片,只有当资源需要显示时候才加载。比如对于图片列表来说,仅在用户滚动到图片所在区域额才会加载图片资源
扩展知识-渐进加载
渐进式加载和懒加载技术类似,先加载低分辨率或低质量的占位资源(如模糊的图片缩略图),在用户访问或等待期间逐步加载高分辨率的完整资源,加载完成后再替换掉占位资源。
适用于超清图片加载、用户体验要求较高的页面,在网络环境较差时,效果会更明显。Ant Design Vue 的 lmage 图片组件 支持渐进加载功能
CDN
1.什么是CDN
CDN 内容分发网络,是通过将图片文件分发到全球各地的节点,用户访问时从离自己近的节点获取资源的技术。
2.CDN优势
CDN相比于COS更倾向于请求。
如果文件存储容量较大,但是访问频率低用对象存储性价比更高;反之CDN更好
浏览器缓存
通过设置 HTTP 头信息(如 Cache-Control),可以让用户的浏览器将资源缓存在本地。在用户再次访问同样的资源时,直接从本地缓存加载资源,而无需再次请求服务器。
所有缓存在使用时的注意事项基本都是类似的:
1)设置合理的缓存时间。常用的几种设置参数是:
-
静态资源使用长期缓存,比如:cache-contro1:public,max-age=31536088 表示缓存一年,适合存储图片等静态资源。
-
动态内容使用验证缓存,比如:cache-control:private,no-cache 表示缓存可被客户端存储,但每次使用前需要与服务器验证有效性。适合会动态变化内容的页面,比如用户个人中心。
-
敏感内容禁用缓存,比如:Cache-Contro1:no-store 表示不允许任何形式的缓存,适合安全性较高的场景比如登录页面、支付页面
2)要能够及时更新缓存。可以给图片的名称添加“版本号”(如文件名中包含 hash 值),这样哪怕上传相同的图片,由于版本号不同,得到的图片地址也不同,下次访问时就会重新加载。
对于我们的项目,图片资源是非常适合长期缓存在浏览器本地的,也已经通过给文件名添加日期和随机数防止了重复。由于图片是从对象存储云服务加载的,如果需要使用缓存,可以接入CDN 服务,直接在云服务的控制台配置缓存,参考文档。
资源。
适用于超清图片加载、用户体验要求较高的页面,在网络环境较差时,效果会更明显。Ant Design Vue 的 lmage 图片组件 支持渐进加载功能
CDN
1.什么是CDN
CDN 内容分发网络,是通过将图片文件分发到全球各地的节点,用户访问时从离自己近的节点获取资源的技术。
2.CDN优势
CDN相比于COS更倾向于请求。
如果文件存储容量较大,但是访问频率低用对象存储性价比更高;反之CDN更好
浏览器缓存
通过设置 HTTP 头信息(如 Cache-Control),可以让用户的浏览器将资源缓存在本地。在用户再次访问同样的资源时,直接从本地缓存加载资源,而无需再次请求服务器。
所有缓存在使用时的注意事项基本都是类似的:
1)设置合理的缓存时间。常用的几种设置参数是:
-
静态资源使用长期缓存,比如:cache-contro1:public,max-age=31536088 表示缓存一年,适合存储图片等静态资源。
-
动态内容使用验证缓存,比如:cache-control:private,no-cache 表示缓存可被客户端存储,但每次使用前需要与服务器验证有效性。适合会动态变化内容的页面,比如用户个人中心。
-
敏感内容禁用缓存,比如:Cache-Contro1:no-store 表示不允许任何形式的缓存,适合安全性较高的场景比如登录页面、支付页面
2)要能够及时更新缓存。可以给图片的名称添加“版本号”(如文件名中包含 hash 值),这样哪怕上传相同的图片,由于版本号不同,得到的图片地址也不同,下次访问时就会重新加载。
对于我们的项目,图片资源是非常适合长期缓存在浏览器本地的,也已经通过给文件名添加日期和随机数防止了重复。由于图片是从对象存储云服务加载的,如果需要使用缓存,可以接入CDN 服务,直接在云服务的控制台配置缓存,参考文档。