门户网站建设 突出服务推广软文300字范文
一、技术背景
近年来,大语言模型(LLM)如 GPT-4、Qwen、DeepSeek-R1 等不断刷新参数规模和推理能力,对算力和部署架构提出了极高要求。随着 AI 推理负载从实验室走向生产环境,如何高效发挥高端 GPU 集群(如 H800)性能,支撑超大参数模型的推理服务,成为业界关注的热点。本实验选取了最新的 2 台单机 8 卡 H800 配置,主存高达 1.5T,基于 vLLM 框架,对 DeepSeek-R1-0528-685B 这一 6850 亿参数级别的大模型进行了部署和性能评测
二、技术介绍
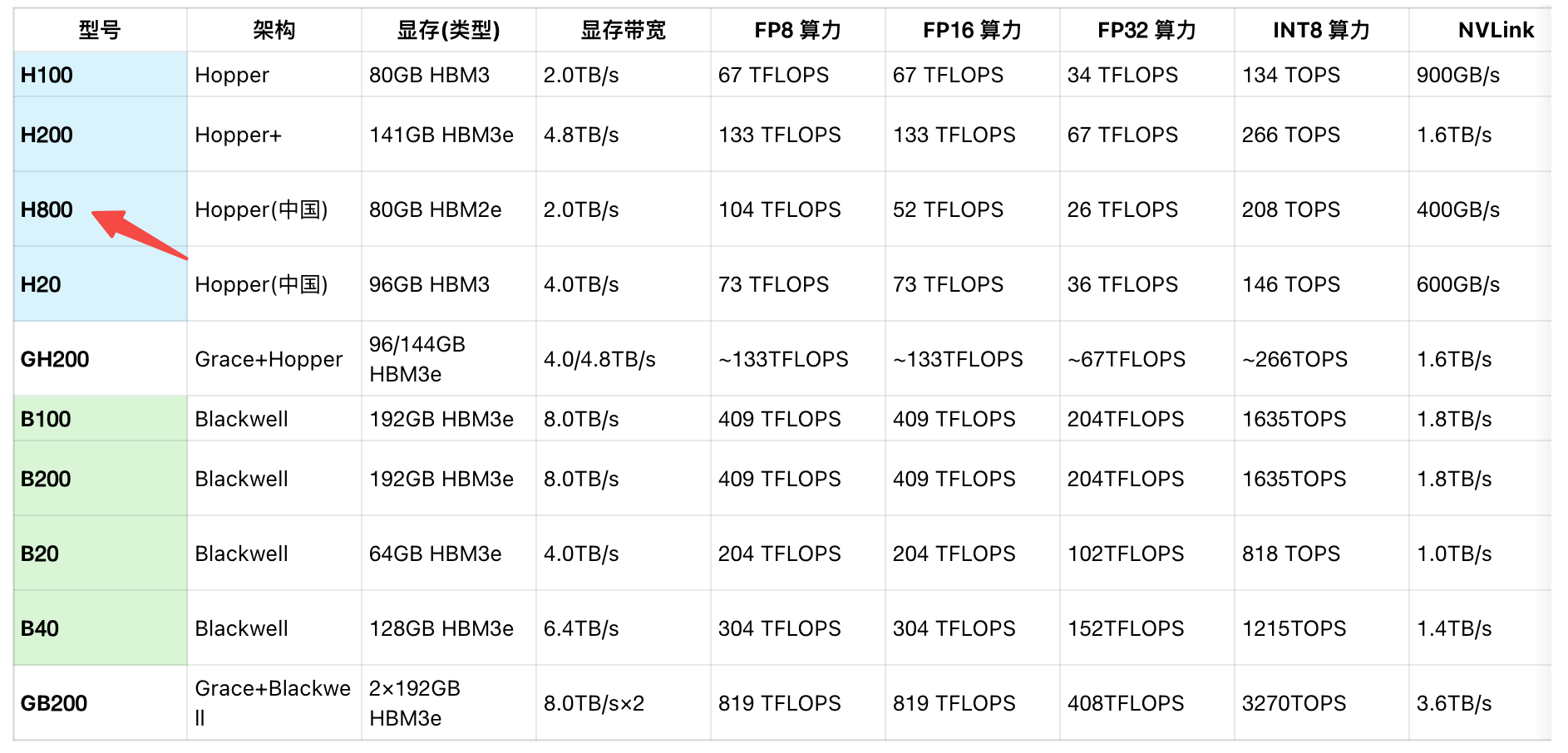
2.1 H800 简介
H800 是英伟达面向大规模 AI 推理/训练场景推出的高性能数据中心 GPU,具备以下核心特点:
-
算力强大:单卡 FP16 算力高达 52 TFLOPS,支持最新的 Tensor Core 和 Transformer Engine。
-
内存充裕:每卡 80GB HBM3 高带宽显存,带宽可达 2TB/s,适合大模型加载与高吞吐推理。
-
互联高速:支持 NVLink 及 PCIe Gen5,显著提升多卡互联带宽,降低跨卡通信延迟。
-
能效优异:针对中国市场合规优化,兼顾性能和功耗。
2.2 vLLM 简介
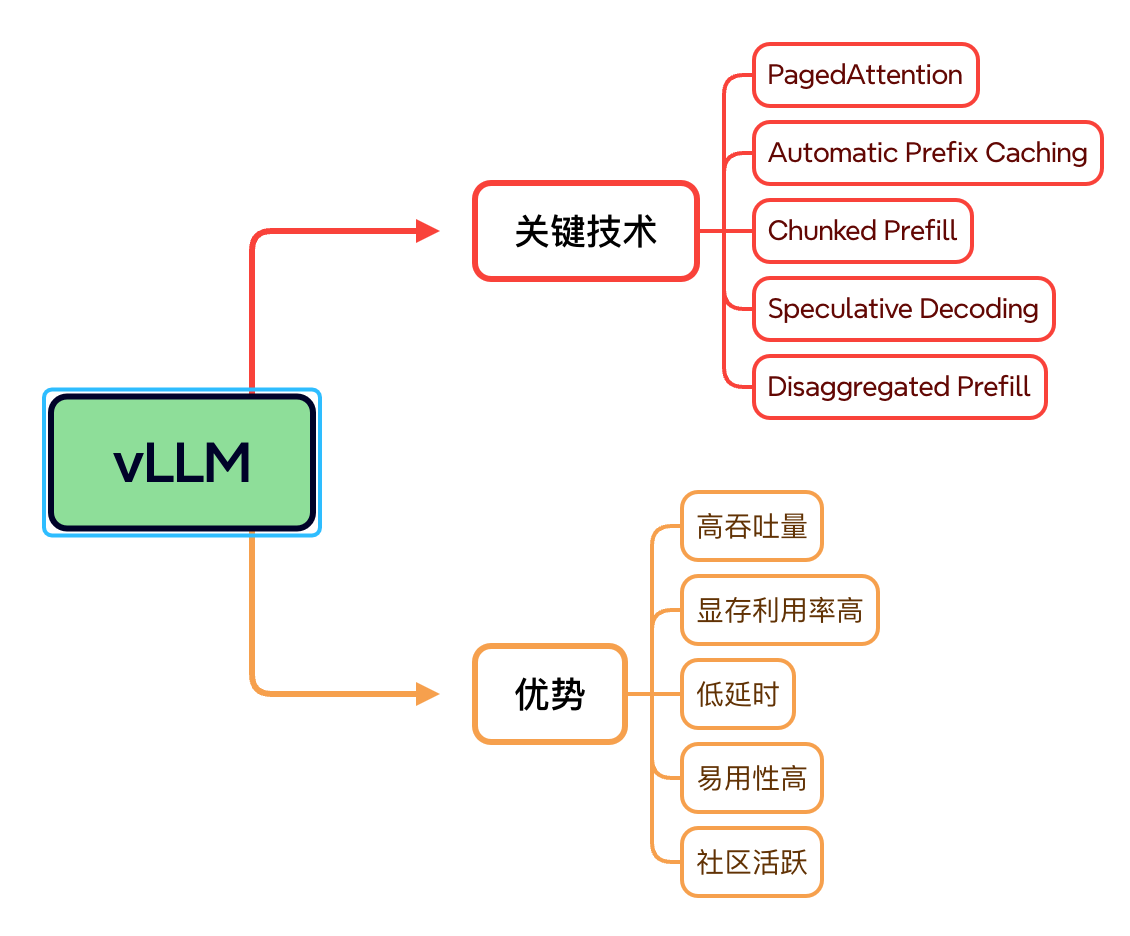
vLLM(Versatile LLM Serving System)是当前领先的大模型推理推理框架,核心优势:
-
高吞吐与低延迟:创新的 Continuous Batch Prefill 和 Token Swapping KV-Cache 技术,有效提升推理并发和显存利用率。
-
灵活并行策略:支持 Tensor Parallel(TP)、Pipeline Parallel(PP)等多种分布式并行方案,轻松应对超大模型跨多机多卡部署。
-
接口友好:兼容 OpenAI API 和 HuggingFace 接口,易于无缝接入现有推理服务架构。
-
易用与可扩展性:开箱即用的部署脚本和监控工具,方便大规模场景自动化运维
-
2.3 DeepSeek-R1 简介
DeepSeek-R1 是 DeepSeek 团队发布的千亿级参数中文/多语言大模型。其 0528-685B 版本拥有高达 6850 亿参数,主打以下特性:
-
中文能力强:大规模高质量中文语料训练,优于同规模 GPT-4、Qwen 等在中文任务上的表现。
-
多语言支持:兼容多语言语境,适应全球化需求。
-
开放社区生态:模型权重开放,便于二次开发与企业级应用落地。
DeepSeek-R1-0528 推理模型文件拆解分析-CSDN博客文章浏览阅读891次,点赞27次,收藏18次。以非人工智能科班,跨界研发人员的视角拆解分析 deepseek r1 的推理模型文件的层次结构,希望能从最小的计算机实体存在的方式认识推理模型为何物?通过直观的认识再去了解大模型相关 https://blog.csdn.net/weixin_39403185/article/details/1484719992.4 部署策略
https://blog.csdn.net/weixin_39403185/article/details/1484719992.4 部署策略
面对 DeepSeek-R1-0528-685B 这样超大模型,部署策略需兼顾内存、显存与带宽,核心思路如下:
-
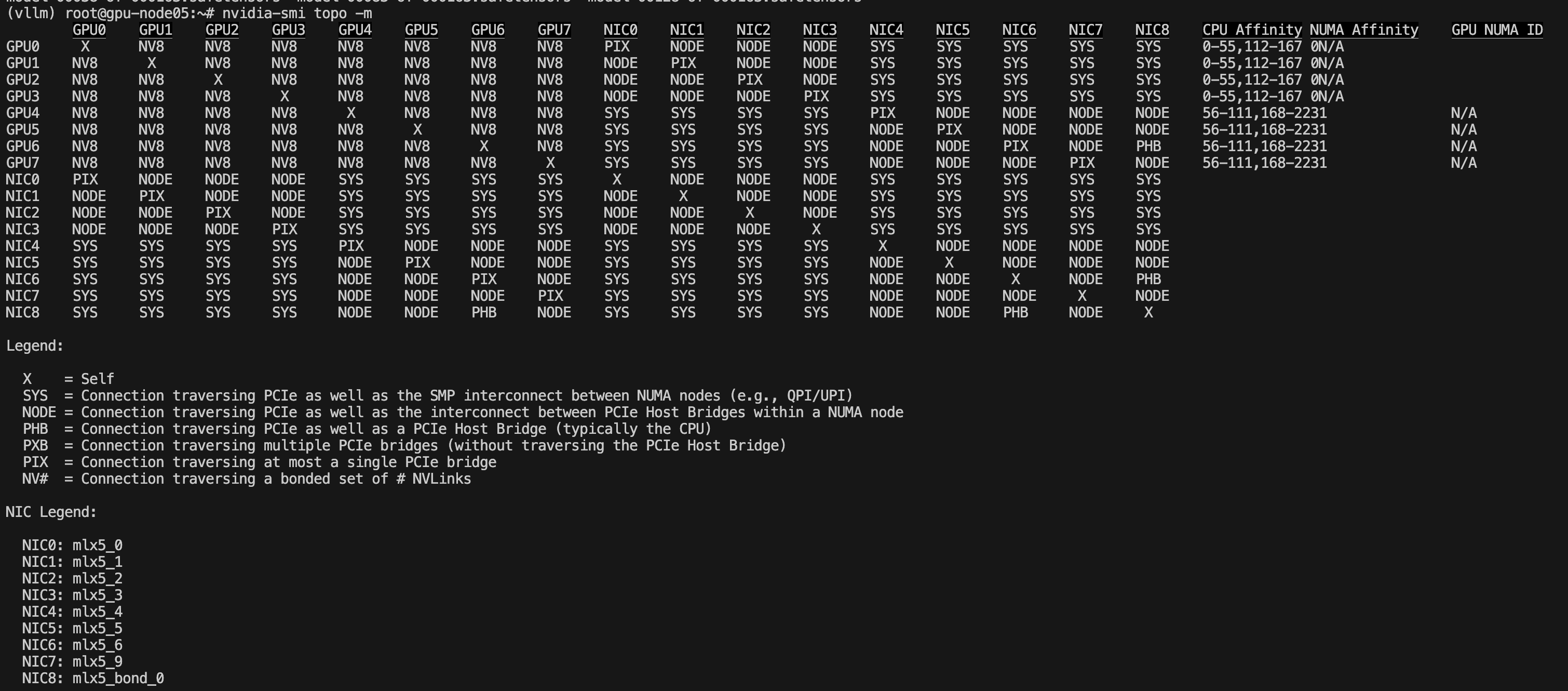
硬件分布:采用 2 台服务器,每台 8 张 H800,总计 16 张 GPU,单机 1.5T 内存,满足模型权重与 KV-Cache 分布式加载需求。
-
并行策略:vLLM 启用 Tensor Parallel(TP=16),每张卡分担约 428 亿参数,充分利用 NVLink 带宽和主存带宽,提升并行效率。
-
模型加载:采用模型分片加载,权重分散于多卡并行计算,主存承担权重预读取与数据缓存,显存集中处理实时推理数据。
-
KV-Cache 优化:结合 vLLM 的高效 KV-Cache 管理,降低 Prefill/Decode 阶段的显存消耗,支持大批量并发推理。
-
网络通信:单机内部通过 NVLink/PCIe 直连,跨机通过高速以太网或 InfiniBand 保证通信带宽和低延迟。
三、vLLM DS-R1-fp16 并行策略
3.1 基础环境
# 安装 conda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh -b -p /data/miniconda3echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
echo 'source /data/miniconda3/bin/activate' >> ~/.bashrc
echo 'conda activate vllm' >> ~/.bashrc
source ~/.bashrcconda create -n vllm python=3.10 -ysource /root/miniconda3/bin/activate
conda activate vllmpip install ray[default]
pip install vllm[all]
pip install locust tiktoken3.2 Ray 启动
ray stop --force
export VLLM_HOST_IP=10.1.4.72
ray start --head \--node-ip-address=10.1.4.72 \--port=6379ray stop --force
export VLLM_HOST_IP=10.1.4.74
ray start --address=10.1.4.72:6379 \--node-ip-address=10.1.4.74rm -rf /tmp/ray/session_*3.3 vLLM 部署
nohup bash -c '# —— 环境变量 —— export GLOO_SOCKET_IFNAME=ibs108export NCCL_SOCKET_IFNAME=ibs108## 强制 NCCL/RDMA 只走 mlx5_0 export NCCL_IB_HCA=mlx5_0export NCCL_IB_DISABLE=0# UCX(Ray 在内部会用到 UCX 通道) export UCX_NET_DEVICES="mlx5_0:1"export UCX_TLS="rc,tcp,cuda_copy" export UCX_IB_PCI_RELAXED_ORDERING=onexport VLLM_WORKER_MULTIPROC_METHOD=spawn# vLLM / Ray 通信export VLLM_USE_V1=1export VLLM_HOST_IP=10.1.4.72export RAY_ADDRESS=10.1.4.72:6379# —— 启动命令 —— python3 -m vllm.entrypoints.openai.api_server \--model /Ds/DeepSeek-R1-0528 \--served-model-name deepseek-reasoner \--host 0.0.0.0 \--port 30000 \--trust-remote-code \--distributed-executor-backend ray \--tensor-parallel-size 8 \--pipeline-parallel-size 2 \--enable-expert-parallel \--max-model-len 16384 \--max-num-seqs 512 \--max-num-batched-tokens 40960 \--gpu-memory-utilization 0.9 \--dtype float16 \--swap-space 32 \--block-size 32 \--enable-prefix-caching \--disable-log-requests \--disable-log-stats
' > ds.log 2>&1 &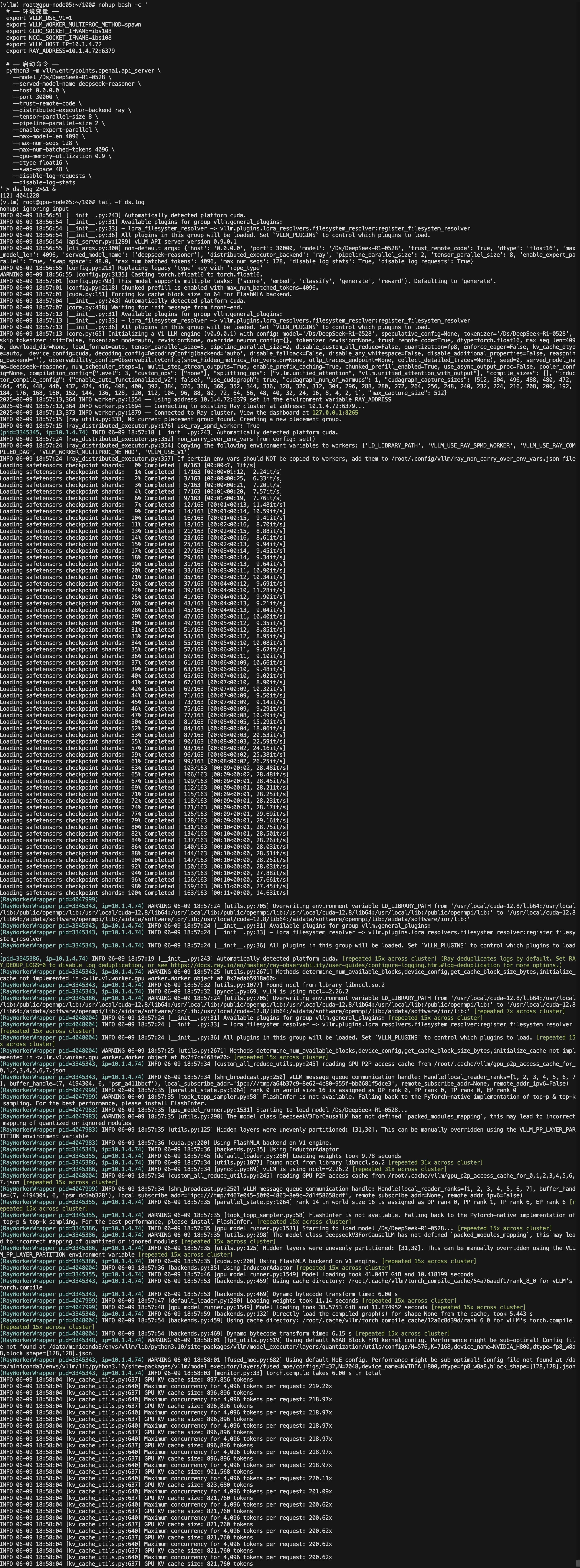
四、性能测试
4.1 简单测试
curl http://10.1.4.72:30000/v1/models | jq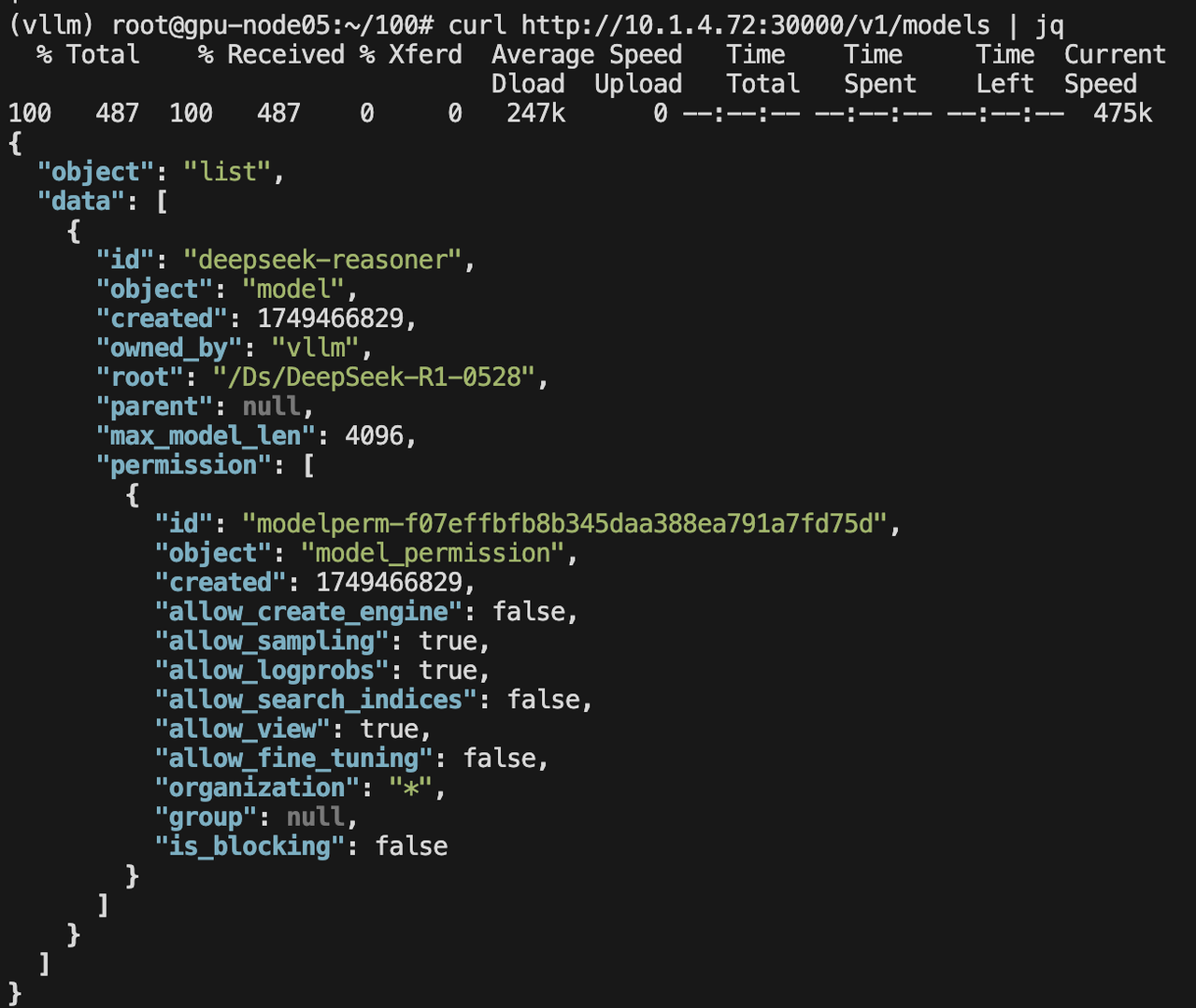
curl -s -X POST http://10.1.4.72:30000/v1/completions \-H "Content-Type: application/json" \-d '{"model": "deepseek-reasoner","prompt": "请介绍deepseek-r1","max_tokens": 128,"temperature": 0.6}' | jq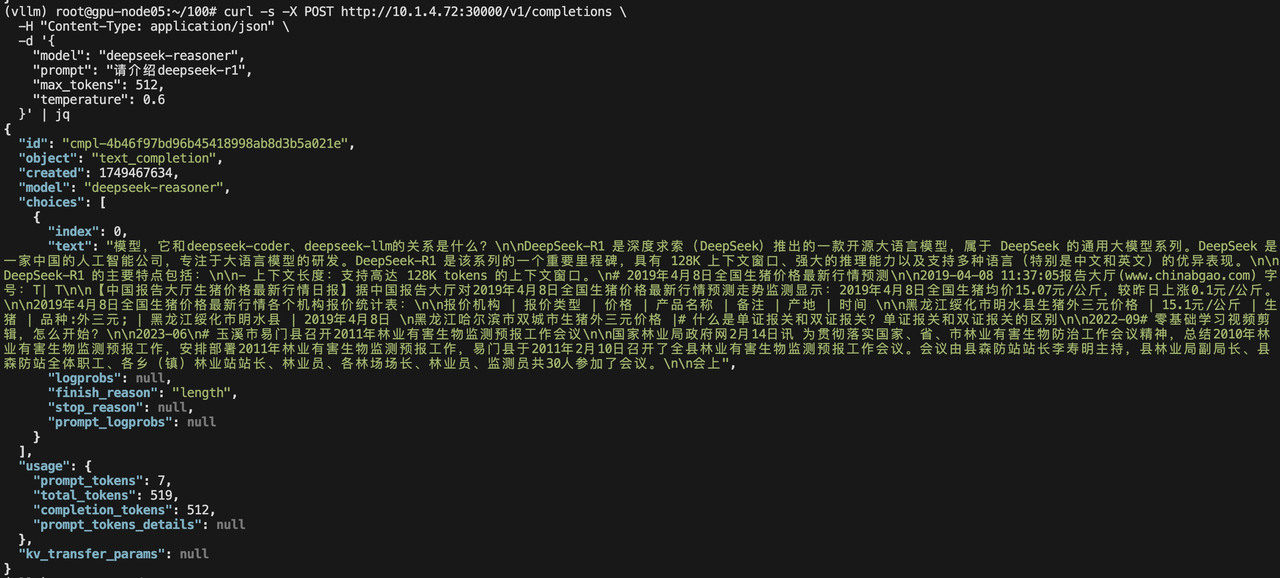 4.2 基准测试
4.2 基准测试
MODEL="deepseek-reasoner" PROMPT_LENGTH="32" MAX_TOKENS="64" \
locust -f locustfile.py --headless --host http://10.1.4.72:30000 \--master-bind-host=10.1.4.72 \--master-host=10.1.4.72 \--processes 8 \-u 10 -r 2 --run-time 180s并发量 u=10 r=2
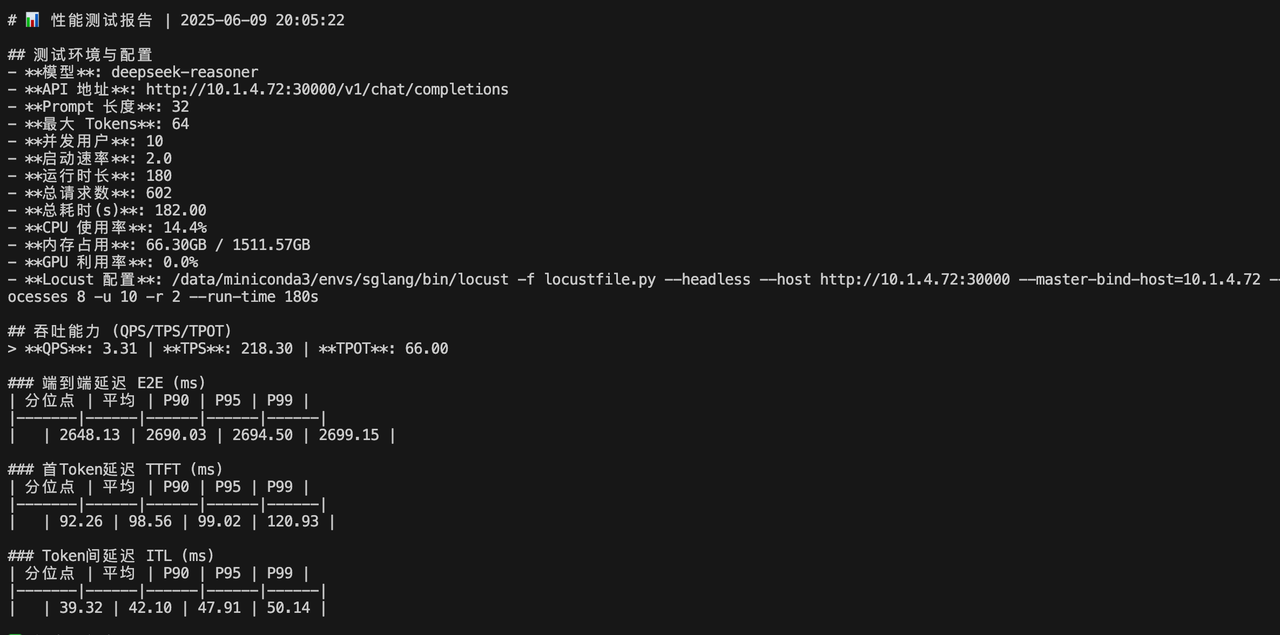
并发量 u=50 r=5
MODEL="deepseek-reasoner" PROMPT_LENGTH="32" MAX_TOKENS="64" \
locust -f locustfile.py --headless --host http://10.1.4.72:30000 \--master-bind-host=10.1.4.72 \--master-host=10.1.4.72 \--processes 12 \-u 50 -r 5 --run-time 180s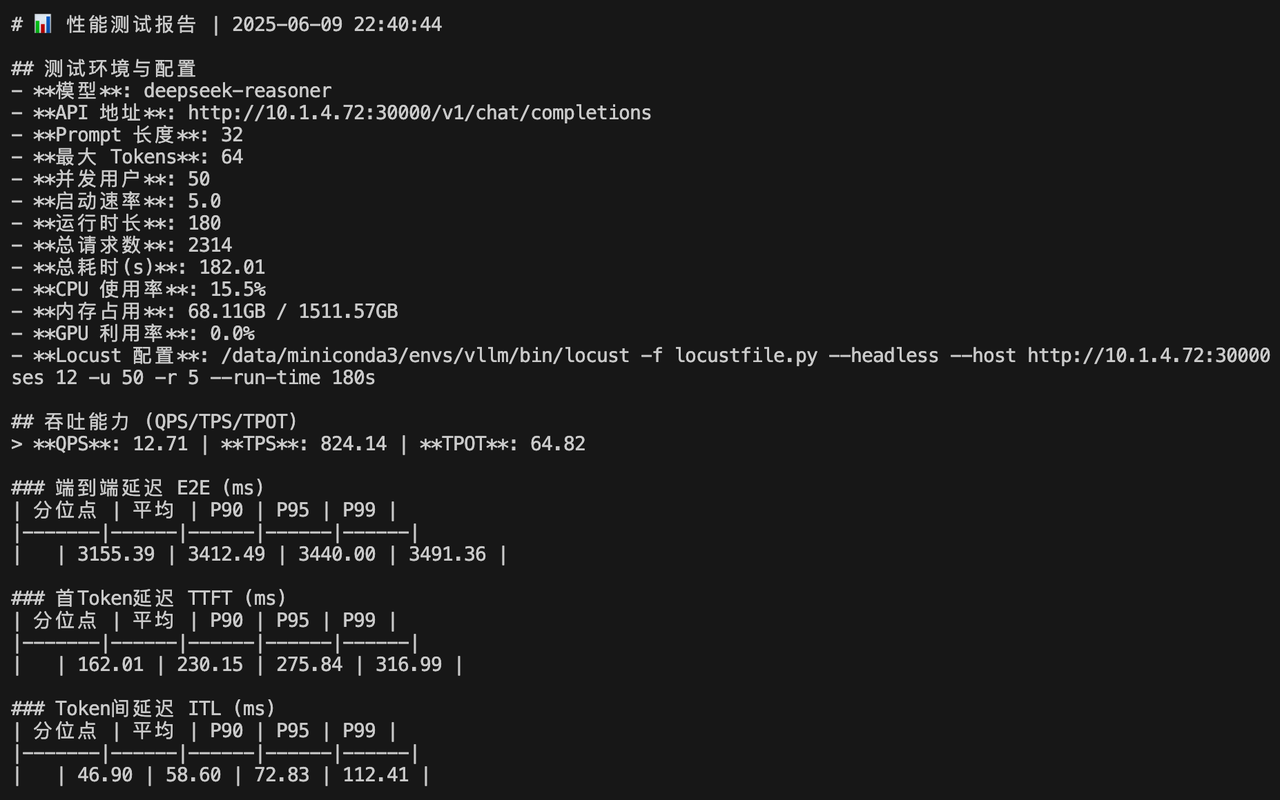
并发量 100 r=10
MODEL="deepseek-reasoner" PROMPT_LENGTH="32" MAX_TOKENS="64" \
locust -f locustfile.py --headless --host http://10.1.4.72:30000 \--master-bind-host=10.1.4.72 \--master-host=10.1.4.72 \--processes 16 \-u 100 -r 10 --run-time 180s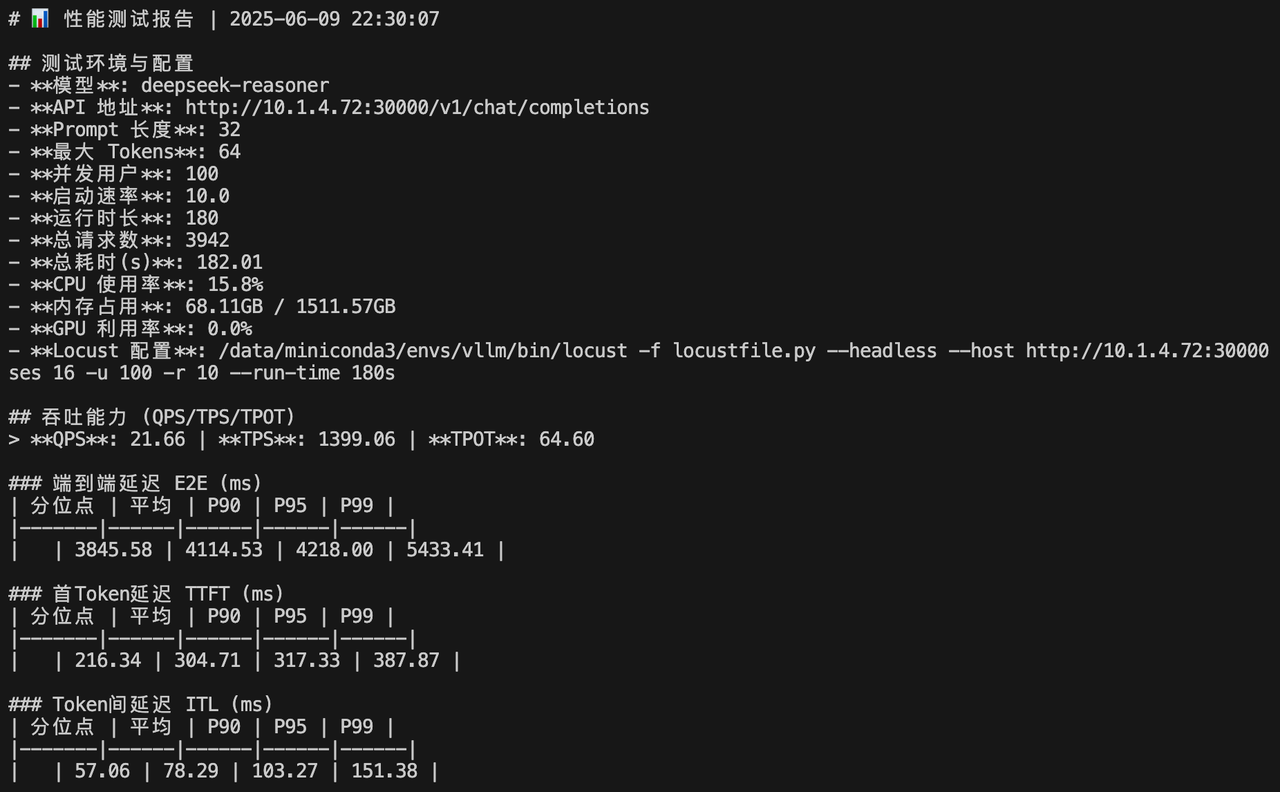 并发量 150 r=10
并发量 150 r=10
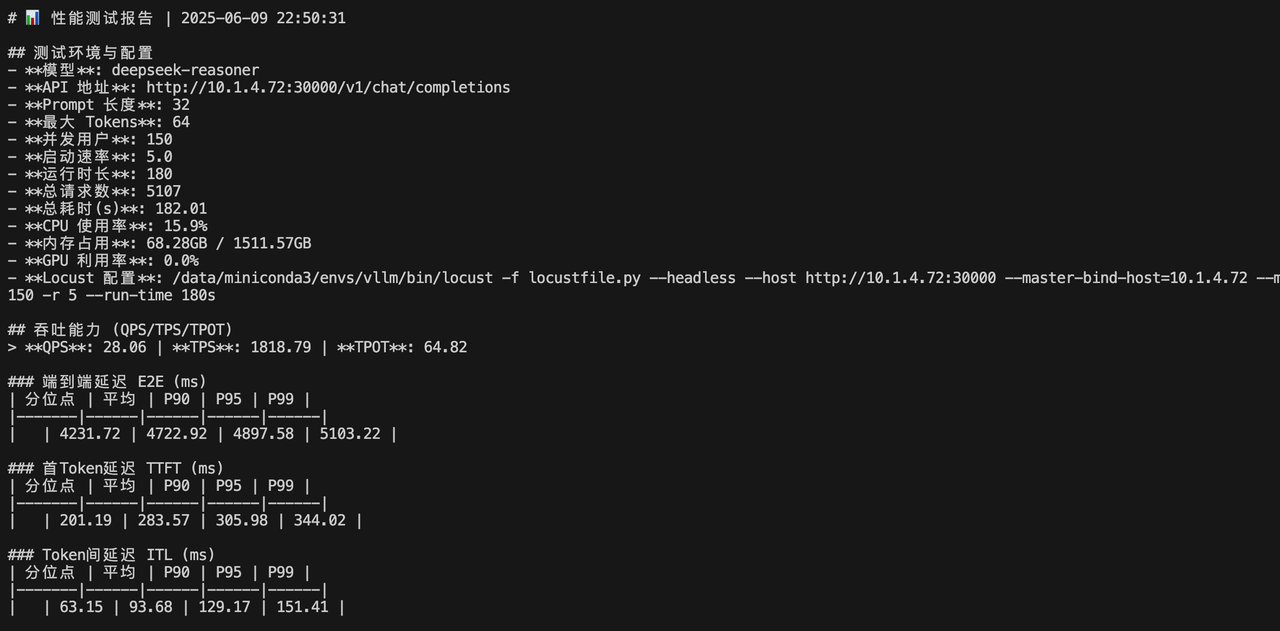
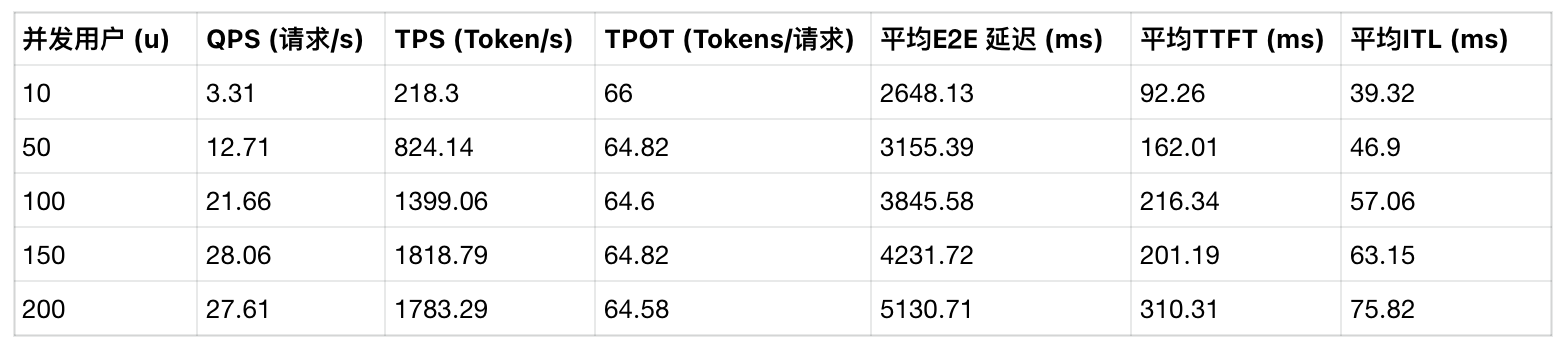 五、小结
五、小结
本次实验基于国产高性能 H800 集群,利用 vLLM 框架顺利完成了 DeepSeek-R1-0528-685B 的推理部署与性能验证。实验结果表明:
-
大模型上 H800 的落地具备可行性,特别是在主存资源充裕、NVLink 通信优化的场景下,可以实现高吞吐低延迟的服务能力。
-
vLLM 框架的分布式和 KV-Cache 优化技术,显著降低了推理资源消耗,提高了大规模用户并发支持能力。
-
DeepSeek-R1 的实际推理能力和资源需求,为今后千亿级参数模型的生产部署提供了参考依据。
随着 AI 硬件和推理框架不断升级,未来在更大规模集群下,进一步提升模型服务的经济性和稳定性,将成为工程实践的新课题。欢迎关注后续更大规模、多任务协同推理的技术演进。
参考:
vLLM - vLLM![]() https://docs.vllm.ai/en/latest/https://github.com/vllm-project/vllm
https://docs.vllm.ai/en/latest/https://github.com/vllm-project/vllm![]() https://github.com/vllm-project/vllm
https://github.com/vllm-project/vllm