网站建设dbd3推广方式
前言
之前的文章里,我已经介绍了传统的AE能够将高维输入压缩成低维表示,并重建出来,但是它的隐空间结构并没有概率意义,这就导致了传统的AE无法自行生成新的数据(比如新图像)。因此,我们希望:
- 隐空间向量
是连续、结构良好的
- 并且可以在隐空间中采样
这就是VAE的目标:构造一个“生成型AutoEncoder”。
一、回顾AE
前面的文章中,我已经详细介绍了AE,这里我们简单回顾一下AE干了什么,如下图所示:
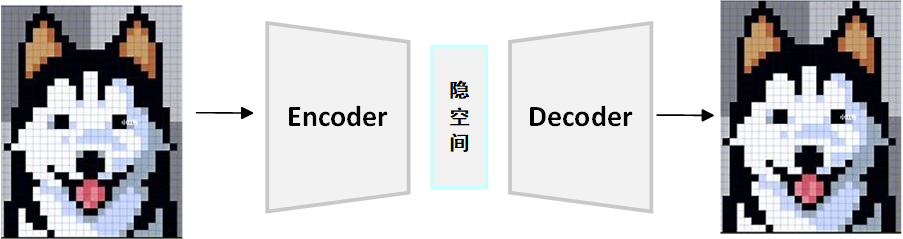
AE基于一个简单却新颖的概念:获取输入数据 ,将其压缩成低维表示,然后再将其重构成原始形式。拿图像举例,图像通常包含数万个数值,而低维表示通常是一个包含10-100维的向量,这些低维表示存储在更紧凑的隐空间中,使用训练好的AE,它可以根据隐空间表示来重建图像。
但是如何生成新图像呢?我们很容易想到的是从这个隐空间中随机采样一些点,然后通过AE的Decoder来生成图像,如下图所示:
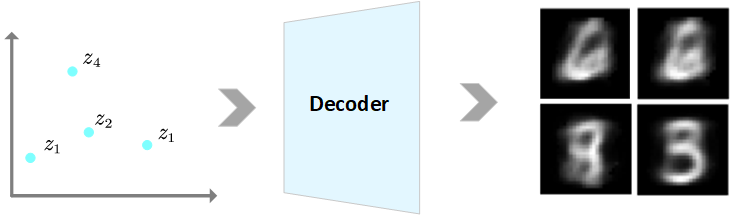
通过上图,虽然AE能够通过隐空间随机采样一些点,来生成新图像,但是,由于隐空间是无组织、不规则的,因此隐空间的大部分区域都不会产生有意义的新图像。
还有一种方式,就是取编码后的图像,然后对其隐空间附近的点进行采样,生成与原始图片相似的新图像:

但是,通过图片我们会发现,由于隐空间的结构太差,即时采样附近的点,也无法生成与原始图像同样意义的新图像或者只能生成与原始图像近似的图像。
总而言之,由于AE压缩的隐空间的结构具有缺陷,因此不能生成有意义的新数据。因此如果能生成一个连续、结构良好的隐空间,那么就能对采样点生成连贯的新数据了,这就是VAE要做的事了。
二、VAE所用的概率基础
1. 随机变量与概率密度函数(PDF)
给定一个随机变量 ,它的概率密度函数
描述了采样得到某个值
的相对可能性有多大:
- 概率密度
并不是概率本身,而是在一个非常小的区间
上,采样值落入这个区间的概率近似为
- 积分为1,:所有可能值的总概率为1,
2. 期望
从X中不断采样,会得到一组值的平均,称为期望:
它表示从分布中采样所期望的平均值
3. 联合分布
若我们有两个变量 和
,则它们的联合分布记为:
它给出了所有可能组合 的概率密度
4. 边缘分布
每个变量对自己的分布,可以通过联合分布进行积分(边缘化)得到:
- 对于
积分得到
的边缘分布:
- 对于
5. 条件概率密度
条件概率表示在已知某一变量的情况下,另一个变量的概率分布,根据贝叶斯公式,可以得到:
- 已知z,求 x 的条件概率
- 已知x,求 z 的条件概率
三、VAE的原理
2014年,Diederik P. Kingma在他的论文《Auto-Encoding Variational Bayes》里首次提出了变分自编码器,简称VAE,它的核心思想之一就是贝叶斯统计。
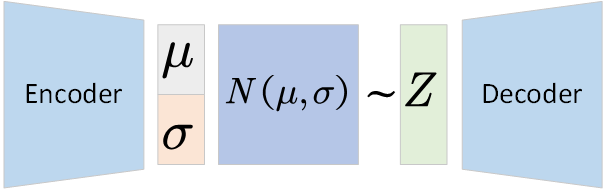
1. VAE的目标
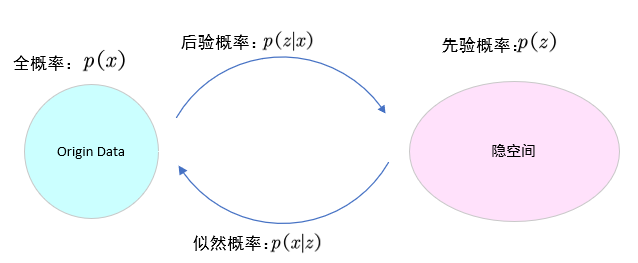
我们希望给定数据 ,能够学习隐空间
的分布,并能从
中生成“相似”的
,即从先验分布中采样
(
为先验概率),通过解码器生成
(
为似然概率)。由于VAE属于生成模型,因此我们关注的是:
如下所示:
核心思想就是如果能从后延分布中采样隐空间向量,这些隐空间向量由原始数据生成,来自原始数据分布 ,如果我们能够将这些隐空间向量重建回原数据,我们就能从原始数据分布中生成新的样本。由于我们不知道隐空间分布
的确切形状,因此我们假设隐空间分布是一个正态分布,然后就能计算似然概率
,它衡量从隐空间重建图像的可能性有多大,但是我们仍然不知道后验概率
,因此就需要使用“变分自编码器中的变分推断了”
2. 变分推断
上面我们已经知道了,不知道真实分布的后验概率 ,所以我们引入一个近似后验分布
来近似后验概率
,这个近似后验分布包括参数
和
,这个参数可以用Encoder来学习;然后我们使用一个Decoder从学习到的近似后验概率中采样隐空间向量来重构数据。
具体来说,我们使用变分下界(ELBO)来近似优化 :
根据Jensen不等式:
即:
这个下界Loss,就是我们用来训练模型的目标函数
3. 对下界(ELBO)推导
根据联合概率 ,代入目标函数:
这就是VAE的损失函数,由两部分组成:
重构项,表示从隐空间变量 z 重建原始输入 x 的可能性:
KL散度,也叫正则化项,用来衡量我们学到的近似后验分布 与先验分布
之间的差距:
4. VAE的整体流程:
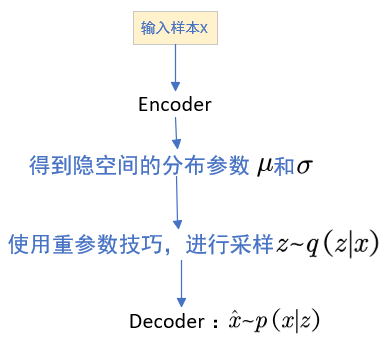
5. 重参数技巧
为了让采样过程可导,VAE使用重参数技巧,这样就可以把 z 写成可导的形式,就能训练模型了:
6. 最终VAE损失
在实际中,我们最大化ELBO(最小化负对数),因此最终优化的是:
其中,KL项可以表示为:
四、Pytroch具体实现
接下来,我使用MNIST手写数字数据集来简单训练一下VAE流程:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from torch.utils.data import DataLoadertransform = transforms.ToTensor()
train_dataset = datasets.MNIST('./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)class VAE(nn.Module):def __init__(self):super().__init__()self.fc1 = nn.Linear(784, 400)self.fc_mu = nn.Linear(400, 20)self.fc_logvar = nn.Linear(400, 20)self.fc2 = nn.Linear(20, 400)self.fc3 = nn.Linear(400, 784)def encode(self, x):h1 = F.relu(self.fc1(x))return self.fc_mu(h1), self.fc_logvar(h1)def reparameterize(self, mu, logvar):std = torch.exp(0.5 * logvar)eps = torch.randn_like(std)return mu + eps * stddef decode(self, z):h3 = F.relu(self.fc2(z))return torch.sigmoid(self.fc3(h3))def forward(self, x):x = x.view(-1, 784)mu, logvar = self.encode(x)z = self.reparameterize(mu, logvar)return self.decode(z), mu, logvardef loss_fn(recon_x, x, mu, logvar):BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())return BCE + KLD
总结
以上就是VAE的全部内容,相信小伙伴们看到这已经对VAE有了更深刻的理解:VAE将概率建模引入AE中,让模型可以从隐空间中采样生成新样本,它通过最大化变分下界ELBO优化目标函数,使用重参数技巧来使得采样过程可导。但是,VAE生成图像时较模糊。
如果小伙伴们觉得本文对各位有帮助,欢迎:👍点赞 | ⭐ 收藏 | 🔔 关注。我将持续在专栏《人工智能》中更新人工智能知识,帮助各位小伙伴们打好扎实的理论与操作基础,欢迎🔔订阅本专栏,向AI工程师进阶!