专业做网站开发公司网络工程师是干什么的
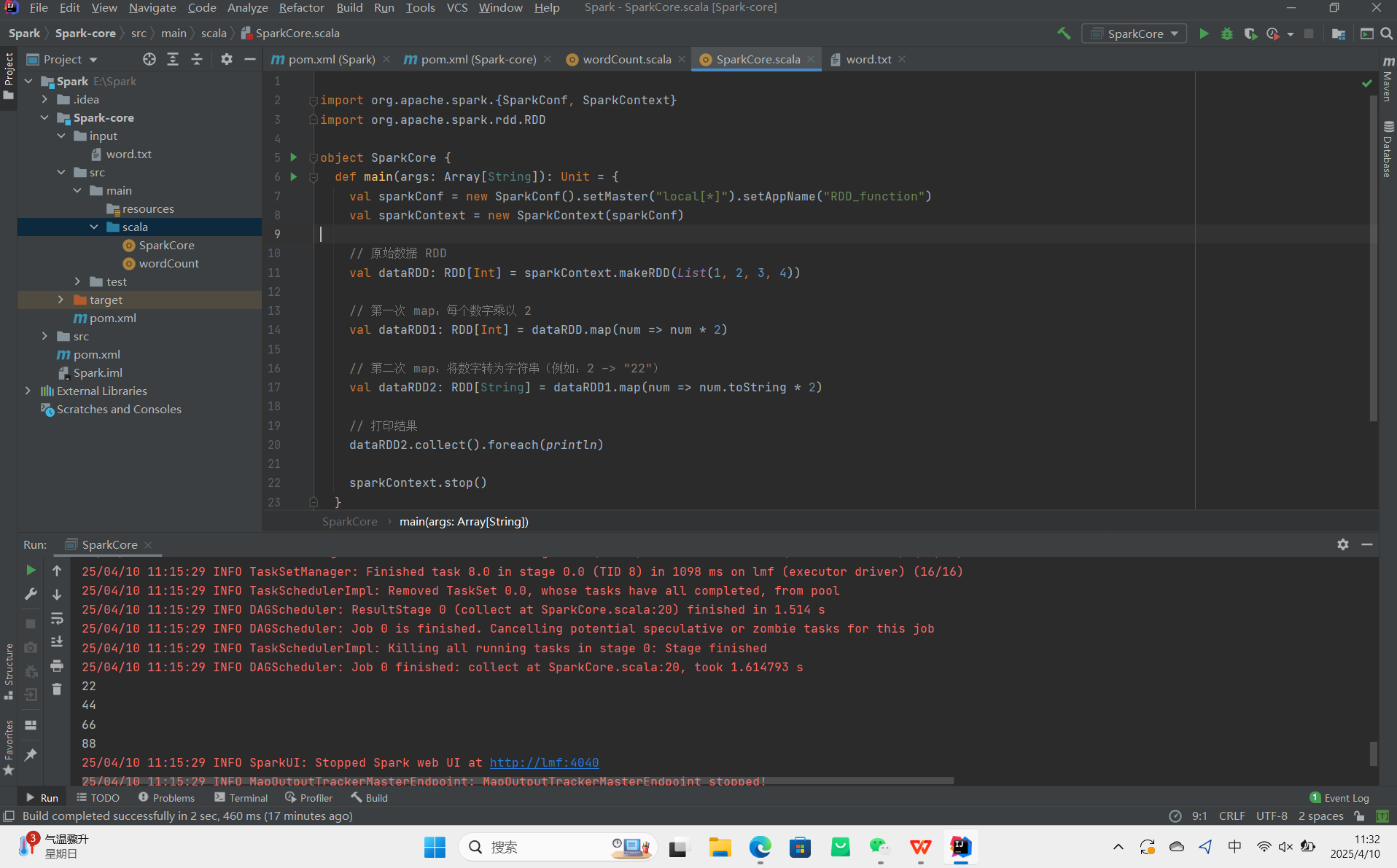
RDD转换算子
RDD 根据数据处理方式的不同将算子整体上分为 Value 类型、双 Value 类型和 Key-Value 类型。
Value类型:
map算子:用于映射转换,可以进行类型转换和值转换。
mapPartitions算子:在分区基础上进行映射,可以并行处理数据,提高处理速度,但可能占用更多内存。
mapPartitionsWithIndex算子:将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处理,哪怕是过滤数据,在处理时同时可以获取当前分区索引。
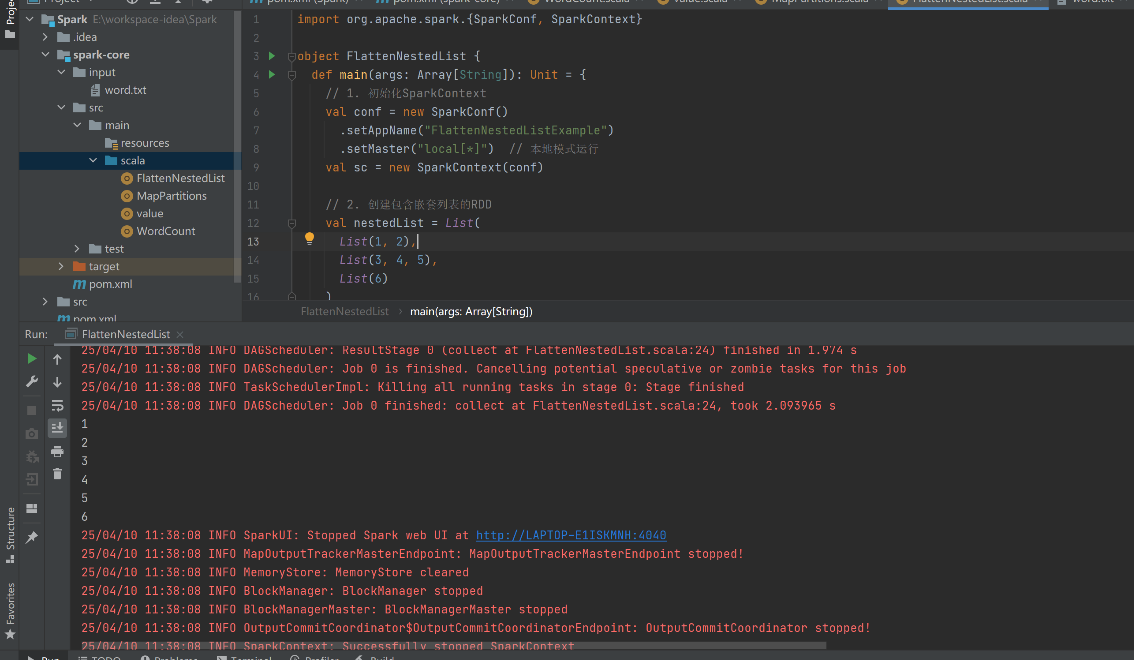
flatMap算子:先扁平化数据再映射,适用于嵌套数据的处理。
glom算子:将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变。
groupBy算子:根据指定规则进行分组,可能导致数据在不同分区之间重新分布。
flter算子:根据指定规则筛选数据,分区不变但数据分布可能不均衡。
sample算子:根据指定概率抽取数据,可以设置放回和不放回。
distinct算子:去重操作,可以选择是否分区。
coalesce算子:缩减分区数量,提高小数据集的执行效率。
repartition算子:调整分区数量,可以增加或减少分区。
sortBy算子:对数据进行排序,可以选择升序或降序,并指定分区数量。
区别:
map 和 mapPartitions 的区别:
数据处理角度:
Map 算子是分区内一个数据一个数据的执行,类似于串行操作。而 mapPartitions 算子是以分区为单位进行批处理操作。
功能的角度:
Map 算子主要目的将数据源中的数据进行转换和改变。但是不会减少或增多数据。MapPartitions 算子需要传递一个迭代器,返回一个迭代器,没有要求的元素的个数保持不变,所以可以增加或减少数据
性能的角度:
Map 算子因为类似于串行操作,所以性能比较低,而是 mapPartitions 算子类似于批处理,所以性能较高。但是 mapPartitions 算子会长时间占用内存,那么这样会导致内存可能不够用,出现内存溢出的错误。所以在内存有限的情况下,不推荐使用。使用 map 操作。
map和flatMap的区别:
map会将每一条输入数据映射为一个新对象。
flatMap包含两个操作:会将每一个输入对象输入映射为一个新集合,然后把这些新集合连成一个大集合。
双Value类型:
intersection算子:对源 RDD 和参数 RDD 求交集后返回一个新的 RDD。
union算子:对源 RDD 和参数 RDD 求并集后返回一个新的 RDD(重复数据不会去重)。
subtract算子:求两个RDD的差集,以第一个RDD为主,去掉重复元素(求差集)。
zip算子:将两个RDD的数据按位置配对,组成键值对形式,其中,键值对中的 Key 为第 1 个 RDD中的元素,Value 为第 2 个 RDD 中的相同位置的元素。
Key-Value类型:
partitionBy:将数据按照指定 Partitioner 重新进行分区。Spark 默认的分区器是 HashPartitioner。
groupByKey:将数据源的数据根据 key 对 value 进行分组。
reduceByKey:可以将数据按照相同的 Key 对 Value 进行聚合。
aggregateByKey:将数据根据不同的规则进行分区内计算和分区间计算。
foldByKey:当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey。
combineByKey:最通用的对 key-value 型 rdd 进行聚集操作的聚集函数(aggregation function)。类似于aggregate(),combineByKey()允许用户返回值的类型与输入不一致。
区别:
reduceByKey 和 groupByKey 的区别:
从 shuffle 的角度:
reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较高。
从功能的角度:
reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用 groupByKey。
reduceByKey、foldByKey、aggregateByKey、combineByKey 的区别:
reduceByKey:
相同 key 的第一个数据不进行任何计算,分区内和分区间计算规则相同
FoldByKey:
每一个key 对应的数据和初始值进行分区内计算,分区内和分区间计算规则相同。
AggregateByKey:
每一个 key 对应的数据和初始值进行分区内计算,分区内和分区间计算规则可以不相同。
CombineByKey:
当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构。分区内和分区间计算规则不相同。