
教程总体简介:1.1 推荐系统简介 学习目标 1 推荐系统概念及产生背景 2 推荐系统的工作原理及作用 3 推荐系统和Web项目的区别 1.3 推荐算法 1 推荐模型构建流程 2 最经典的推荐算法:协同过滤推荐算法(Collaborative Filtering) 3 相似度计算(Similarity Calculation) 4 协同过滤推荐算法代码实现: 二 根据用户行为数据创建ALS模型并召回商品 2.0 用户行为数据拆分 2.1 预处理behavior_log数据集 2.2 根据用户对类目偏好打分训练ALS模型 三 CTR预估数据准备 3.1 分析并预处理raw_sample数据集 1.3 Hadoop优势 4.4 大数据产品与互联网产品结合 4.5 大数据应用--数据分析 4.6 数据分析案例 5.3 HBase 的安装与Shell操作 1 HBase的安装 2.3 HDFS设计思路 4.3 Hive 函数 1 内置运算符 2 内置函数 3 Hive 自定义函数和 Transform MapReduce实战 3.3.1 利用MRJob编写和运行MapReduce代码 3.3.2 运行MRJOB的不同方式 3.3.3 mrjob 实现 topN统计(实验) spark-core RDD常用算子练习 3.1 RDD 常用操作 3.2 RDD Transformation算子 3.4 Spark RDD两类算子执行示意 3、JSON数据的处理 3.1 介绍 3.2 实践 3.1 静态json数据的读取和操作 5.4 HappyBase操作Hbase 4.4 hive综合案例 四 LR实现CTR预估 4.1 Spark逻辑回归(LR)训练点击率预测模型 4、数据清洗 5.6 HBase组件 1、sparkStreaming概述 spark-core实战 5.1通过spark实现ip地址查询 五 离线推荐数据缓存 5.1离线数据缓存之离线召回集 1.4 案例--基于协同过滤的电影推荐 1 User-Based CF 预测电影评分 3 spark 安装部署及standalone模式介绍 1 spark 安装部署 3 spark 集群相关概念 六 实时产生推荐结果 6.1 推荐任务处理 推荐系统基础 Hadoop Hive HBase Spark SQL 1.6 推荐系统的冷启动问题 2 处理推荐系统冷启动问题的常用方法 一 个性化电商广告推荐系统介绍 1.2 项目效果展示 1.3 项目实现分析 1.4 点击率预测(CTR--Click-Through-Rate)概念 资源调度框架 YARN 3.1.1 什么是YARN 3.1.2 YARN产生背景 3.1.3 YARN的架构和执行流程 基于回归模型的协同过滤推荐 基于矩阵分解的CF算法 基于矩阵分解的CF算法实现(二):BiasSvd 基于内容的推荐算法(Content-Based) 基于内容的电影推荐:物品画像 基于TF-IDF的特征提取技术 基于内容的电影推荐:为用户产生TOP-N推荐结果 2、DataFrame 分布式处理框架 MapReduce 3.2.1 什么是MapReduce
完整笔记资料代码:https://gitee.com/yinuo112/Backend/tree/master/Python/嘿马推荐系统全知识和项目开发教程/note.md
感兴趣的小伙伴可以自取哦~
全套教程部分目录:

部分文件图片:
1.4 案例--基于协同过滤的电影推荐
学习目标
- 应用基于用户的协同过滤实现电影评分预测
- 应用基于物品的协同过滤实现电影评分预测
1 User-Based CF 预测电影评分
-
数据集下载
-
下载地址:[MovieLens Latest Datasets Small](
-
建议下载[ml-latest-small.zip](
-
加载ratings.csv,转换为用户-电影评分矩阵并计算用户之间相似度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import osimport pandas as pd
import numpy as npDATA_PATH = "./datasets/ml-latest-small/ratings.csv"dtype = {"userId": np.int32, "movieId": np.int32, "rating": np.float32}# 加载数据,我们只用前三列数据,分别是用户ID,电影ID,已经用户对电影的对应评分ratings = pd.read_csv(data_path, dtype=dtype, usecols=range(3))# 透视表,将电影ID转换为列名称,转换成为一个User-Movie的评分矩阵ratings_matrix = ratings.pivot_table(index=["userId"], columns=["movieId"],values="rating")#计算用户之间相似度user_similar = ratings_matrix.T.corr()
|
- 预测用户对物品的评分 (以用户1对电影1评分为例)
评分公式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # 1. 找出uid用户的相似用户similar_users = user_similar[1].drop([1]).dropna()# 相似用户筛选规则:正相关的用户similar_users = similar_users.where(similar_users>0).dropna()# 2. 从用户1的近邻相似用户中筛选出对物品1有评分记录的近邻用户ids = set(ratings_matrix[1].dropna().index)&set(similar_users.index)
finally_similar_users = similar_users.ix[list(1)]# 3. 结合uid用户与其近邻用户的相似度预测uid用户对iid物品的评分numerator = 0 # 评分预测公式的分子部分的值
denominator = 0 # 评分预测公式的分母部分的值
for sim_uid, similarity in finally_similar_users.iteritems():# 近邻用户的评分数据sim_user_rated_movies = ratings_matrix.ix[sim_uid].dropna()# 近邻用户对iid物品的评分sim_user_rating_for_item = sim_user_rated_movies[1]# 计算分子的值numerator += similarity * sim_user_rating_for_item# 计算分母的值denominator += similarity# 4 计算预测的评分值predict_rating = numerator/denominator
print("预测出用户<%d>对电影<%d>的评分:%0.2f" % (1, 1, predict_rating))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def predict(uid, iid, ratings_matrix, user_similar):
'''
预测给定用户对给定物品的评分值
:param uid: 用户ID
:param iid: 物品ID
:param ratings_matrix: 用户-物品评分矩阵
:param user_similar: 用户两两相似度矩阵
:return: 预测的评分值
'''print("开始预测用户<%d>对电影<%d>的评分..."%(uid, iid))# 1. 找出uid用户的相似用户similar_users = user_similar[uid].drop([uid]).dropna()# 相似用户筛选规则:正相关的用户similar_users = similar_users.where(similar_users>0).dropna()if similar_users.empty is True:raise Exception("用户<%d>没有相似的用户" % uid)# 2. 从uid用户的近邻相似用户中筛选出对iid物品有评分记录的近邻用户ids = set(ratings_matrix[iid].dropna().index)&set(similar_users.index)finally_similar_users = similar_users.ix[list(ids)]# 3. 结合uid用户与其近邻用户的相似度预测uid用户对iid物品的评分numerator = 0 # 评分预测公式的分子部分的值denominator = 0 # 评分预测公式的分母部分的值for sim_uid, similarity in finally_similar_users.iteritems():# 近邻用户的评分数据sim_user_rated_movies = ratings_matrix.ix[sim_uid].dropna()# 近邻用户对iid物品的评分sim_user_rating_for_item = sim_user_rated_movies[iid]# 计算分子的值numerator += similarity * sim_user_rating_for_item# 计算分母的值denominator += similarity# 计算预测的评分值并返回predict_rating = numerator/denominatorprint("预测出用户<%d>对电影<%d>的评分:%0.2f" % (uid, iid, predict_rating))return round(predict_rating, 2)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def predict_all(uid, ratings_matrix, user_similar):
'''
预测全部评分
:param uid: 用户id
:param ratings_matrix: 用户-物品打分矩阵
:param user_similar: 用户两两间的相似度
:return: 生成器,逐个返回预测评分
'''# 准备要预测的物品的id列表item_ids = ratings_matrix.columns# 逐个预测for iid in item_ids:try:rating = predict(uid, iid, ratings_matrix, user_similar)except Exception as e:print(e)else:yield uid, iid, rating
if __name__ == '__main__':for i in predict_all(1, ratings_matrix, user_similar):pass
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def top_k_rs_result(k):results = predict_all(1, ratings_matrix, user_similar)return sorted(results, key=lambda x: x[2], reverse=True)[:k]
if __name__ == '__main__':from pprint import pprintresult = top_k_rs_result(20)pprint(result)
|
2 Item-Based CF 预测电影评分
- 加载ratings.csv,转换为用户-电影评分矩阵并计算用户之间相似度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| import osimport pandas as pd
import numpy as npDATA_PATH = "./datasets/ml-latest-small/ratings.csv"dtype = {"userId": np.int32, "movieId": np.int32, "rating": np.float32}# 加载数据,我们只用前三列数据,分别是用户ID,电影ID,已经用户对电影的对应评分ratings = pd.read_csv(data_path, dtype=dtype, usecols=range(3))# 透视表,将电影ID转换为列名称,转换成为一个User-Movie的评分矩阵ratings_matrix = ratings.pivot_table(index=["userId"], columns=["movieId"],values="rating")#计算用户之间相似度item_similar = ratings_matrix.corr()
|
- 预测用户对物品的评分 (以用户1对电影1评分为例)
评分公式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # 1. 找出iid物品的相似物品similar_items = item_similar[1].drop([1]).dropna()# 相似物品筛选规则:正相关的物品similar_items = similar_items.where(similar_items>0).dropna()# 2. 从iid物品的近邻相似物品中筛选出uid用户评分过的物品ids = set(ratings_matrix.ix[1].dropna().index)&set(similar_items.index)
finally_similar_items = similar_items.ix[list(ids)]# 3. 结合iid物品与其相似物品的相似度和uid用户对其相似物品的评分,预测uid对iid的评分numerator = 0 # 评分预测公式的分子部分的值
denominator = 0 # 评分预测公式的分母部分的值
for sim_iid, similarity in finally_similar_items.iteritems():# 近邻物品的评分数据sim_item_rated_movies = ratings_matrix[sim_iid].dropna()# 1用户对相似物品物品的评分sim_item_rating_from_user = sim_item_rated_movies[1]# 计算分子的值numerator += similarity * sim_item_rating_from_user# 计算分母的值denominator += similarity# 计算预测的评分值并返回predict_rating = sum_up/sum_down
print("预测出用户<%d>对电影<%d>的评分:%0.2f" % (uid, iid, predict_rating))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def predict(uid, iid, ratings_matrix, user_similar):
'''
预测给定用户对给定物品的评分值
:param uid: 用户ID
:param iid: 物品ID
:param ratings_matrix: 用户-物品评分矩阵
:param user_similar: 用户两两相似度矩阵
:return: 预测的评分值
'''print("开始预测用户<%d>对电影<%d>的评分..."%(uid, iid))# 1. 找出uid用户的相似用户similar_users = user_similar[uid].drop([uid]).dropna()# 相似用户筛选规则:正相关的用户similar_users = similar_users.where(similar_users>0).dropna()if similar_users.empty is True:raise Exception("用户<%d>没有相似的用户" % uid)# 2. 从uid用户的近邻相似用户中筛选出对iid物品有评分记录的近邻用户ids = set(ratings_matrix[iid].dropna().index)&set(similar_users.index)finally_similar_users = similar_users.ix[list(ids)]# 3. 结合uid用户与其近邻用户的相似度预测uid用户对iid物品的评分numerator = 0 # 评分预测公式的分子部分的值denominator = 0 # 评分预测公式的分母部分的值for sim_uid, similarity in finally_similar_users.iteritems():# 近邻用户的评分数据sim_user_rated_movies = ratings_matrix.ix[sim_uid].dropna()# 近邻用户对iid物品的评分sim_user_rating_for_item = sim_user_rated_movies[iid]# 计算分子的值numerator += similarity * sim_user_rating_for_item# 计算分母的值denominator += similarity# 计算预测的评分值并返回predict_rating = numerator/denominatorprint("预测出用户<%d>对电影<%d>的评分:%0.2f" % (uid, iid, predict_rating))return round(predict_rating, 2)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def predict_all(uid, ratings_matrix, item_similar):
'''
预测全部评分
:param uid: 用户id
:param ratings_matrix: 用户-物品打分矩阵
:param item_similar: 物品两两间的相似度
:return: 生成器,逐个返回预测评分
'''# 准备要预测的物品的id列表item_ids = ratings_matrix.columns# 逐个预测for iid in item_ids:try:rating = predict(uid, iid, ratings_matrix, item_similar)except Exception as e:print(e)else:yield uid, iid, ratingif __name__ == '__main__':for i in predict_all(1, ratings_matrix, item_similar):pass
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def top_k_rs_result(k):results = predict_all(1, ratings_matrix, item_similar)return sorted(results, key=lambda x: x[2], reverse=True)[:k]
if __name__ == '__main__':from pprint import pprintresult = top_k_rs_result(20)pprint(result)
|
3
1.5 推荐系统评估
学习目标
1 推荐系统的评估指标
- 好的推荐系统可以实现用户, 服务提供方, 内容提供方的共赢
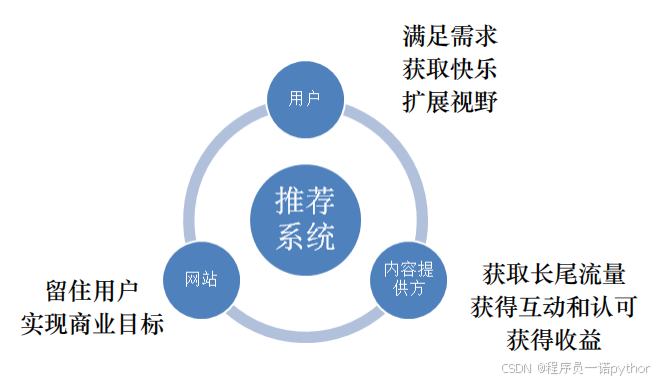
• 准确性 • 信任度 • 满意度 • 实时性 • 覆盖率 • 鲁棒性 • 多样性 • 可扩展性 • 新颖性 • 商业⽬标 • 惊喜度 • ⽤户留存
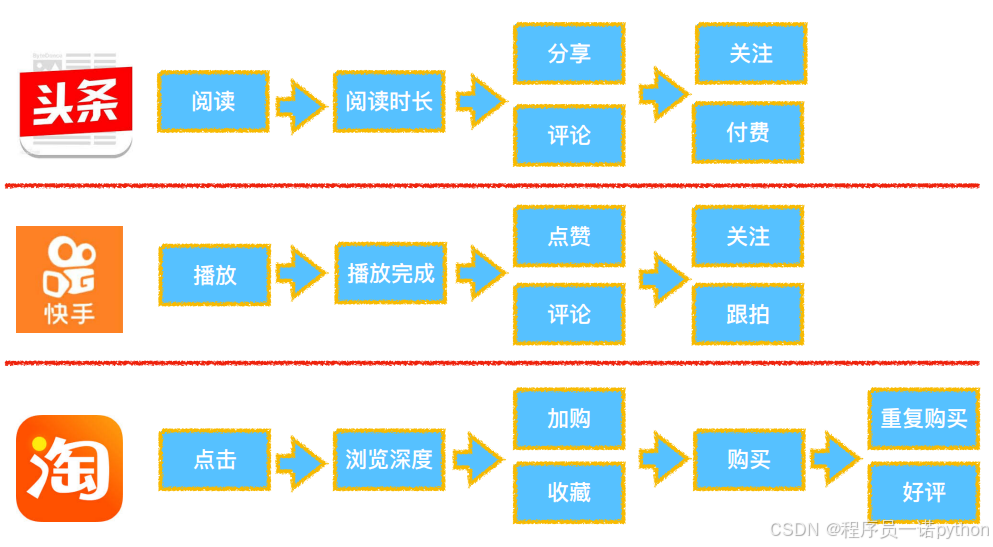
2 推荐系统评估方法