呼市网站制作招聘甘肃网站推广
1 原理
VideoRag在LightRag基础上增加了对视频的处理,详细的分析参考LightRag的兄弟项目VideoRag系统分析-CSDN博客。
Quipus的底层的知识库的构建的核心流程与LightRag类似,但在技术栈的选择和处理有所不同。Quipus对于视频的处理实现,与VideoRag有所不同。本文重点描述Quipus的知识库的构建过程。
Quipus系统的介绍参考:Quipus,LightRag的Go版本的实现_golang lightrag-CSDN博客
1.1 文本知识库的构建
分为以下几个步骤:chunk、知识图谱构建、知识总结。
1.1.1 chunk
文本知识库在构建时,支持txt,doc,docx,html,pdf等类型。在处理时,读取文件的方式,分为三类:
文本类:直接读取
二进制文件:doc\docx\pdf等,为了便于统一处理,同时也为了避免文件加载时避免格式差异导致的失败,通过调用liboffice将doc\docx转换为pdf,再调用pdf工具按页读取pdf文档。
html:用户指定网页链接,在获取网页后,调用LLM服务,直接提取网页中的文本内容。
在chunk时,为避免超过llm模型的处理能力,需要计算token的数量,在达到预设的值时,进行切分。为了提高效率,在quipus中作了以下的优化:
假设token的数量为T,先加载3T长度的文本,计算3T长度的文本的token数量A,计算R=T-A。
然后计算后续的R长度文本,为了避免截取半个汉字,计算的token数量时,按句子的结束标点符号去要计算的文本段,当超过了token预设值,即为一个chunk,将该chunk添加到向量数据库中,在计算向量时,通过embedding计算Dim。
1.1.2 知识图谱的构建
知识图谱的知识的提取过程与LightRag类似。
知识提取时,需要将1.1.1所述的chunk取出来,向大模型请求,提取出Entity和Relation。
并以此创建需要存储Entity和Relation。
Entity中包含有:指定的知识库的Id,文件的Id,Entity的描述信息
Relation包含:srcEntity,targetEntity和关系描述
具体步骤如下:
1、遍历chunk库,从chunk向量库中取出知识,通过LLM进行知识结构的提取,提取出知识的Entity和Relation.将Entity和Relation存储到向量数据库中。
2、将Entity存储到图数据库中,将Relation存储到数据库,并与srcEntity指向的Entity,以及targetEntity指向的entity关联起来。在存储的时候,要先检索是否有实体或关系已存在,如果存在的话,则将知识进行比较,如果不同,则在知识后面进行追加,否则否略,在追加后进行知识的更新;否则进行知识的添加
1.1.3 知识总结
1、遍历chunk库,将chunk发送到LLM进行知识总结,对每个chunk进行总结,总结的知识为二级结构:一级为总的结论,二级为若干个知识点
2、将每个chunk的知识点打包,然后再送往LLM进行总结,总结的即为该文章的知识总结。总结的知识为二级:一级为该文章的总的结论,二级为该文章的若干知识点。
1.2 视频知识库的构建
对于视频知识库的构建,与文本库的差异点在于,前面的从视频中提取知识的困难。在从视频中根据音频和视频提出文本后,后续的文本处理过程为1.1相同。
因此这里重点关注音视频的处理。
在这里重点是使用ffmpeg进行音视的切分处理。
处理过程如下:
1、首先,获得文件的probe信息,从probe信息可以得到媒体文件的基本信息。
2、如果有音频,首先处理音频信息。按步长(例如120s),读取音频的内容,并将内容送到LLM识别音频内容,并将其存在transaction向量库中,id设置为文件名-starttime-endtime
3、如果有视频,将在指定的视频段时,按每5s(也可以设置更长或更短)进行抽帧,如果按步120s,则是抽取24帧到缓存,然后调用LLM,进行图像识别,得到相应的结果,再取出transaction向量库中中相同位置的音频的识别文本,组装结构体:
{"audio":"xxxx","video":"xxx"},存储chunk库
后续的知识图谱的提取和短识的总结和1.1相同。
1.3 知识召回
知识召回有两种模式:向量方式,知识图谱增强方式。在进行向量检索时,距离越大意味知识的关联性越差,为避免召回知识的关联度偏低,设置距离差距到达一定值时,丢弃召回的知识,避免知识污染。
1.3.1 向量检索方式
(1)调用LLM服务分析关键词,调用llm embedding模型计算向量
(2)根据计算的向量从chunk向量库中检索内容。
(3)从检索内容中根据距离,从小到大,拼接召回的知识。计算拼接内容的长度不能超过预设的token的限制。设置token的限制时,要考虑prompt模板的长度。
(4)再将召回的知识,根据system prompt模板生成system prompt
(5)创建chat req,设置system role对应的内容为system prompt, user role对应的内容为用户的问题
(6)请求llm服务,得到答案。
1.3.2 知识图谱增加方式
(1)向LLM服务请求分析用户问题的关键词
(2)根据关键词从entitydb和relation db中分别检索实体和关系
(3)根据relation从图数据库,取出两端的entity,添加到entity列中
(4)根据entity 从图数据库,检索与之有关的relation,以及relation另一端的srcEntity或targetEntity,计算enttity与之有关联的relation的数量作为rank值
(4) 根据rank进行排序,rank值越大,越放在前面
(5)根据entity中的值,从chunk中找到相应的chunk值
(6)组装知识:包括entity中的内容、realtion中的内容,chunk文本,生成csv文本
(7)组装的知识,根据system prompt模板生成system prompt
(8) 创建chat req,设置system role对应的内容为system prompt, user role对应的内容为用户的问题
(9)请求llm服务,得到答案。
2 使用的关键组件
项目本身使用的语言为golang,因此在选择相关的组件时,倾向使用有go-sdk的组件。
向量库使用Milivus
图数据库使用Dgraph
媒体处理使用开源的ffmpeg-go,实际上这是对ffmpeg命令的一个封装的库
3 与当前一些系统的区别
目前大多数的rag并不支持video的知识的提取,而quipus支持文本、doc文档、pdf、图片、音频、视频的处理。
核心处理流程参考LightRag,在视频处理与VideoRag有所不同。
4 使用过程
安装过程参考Quipus,LightRag的Go版本的实现_golang lightrag-CSDN博客
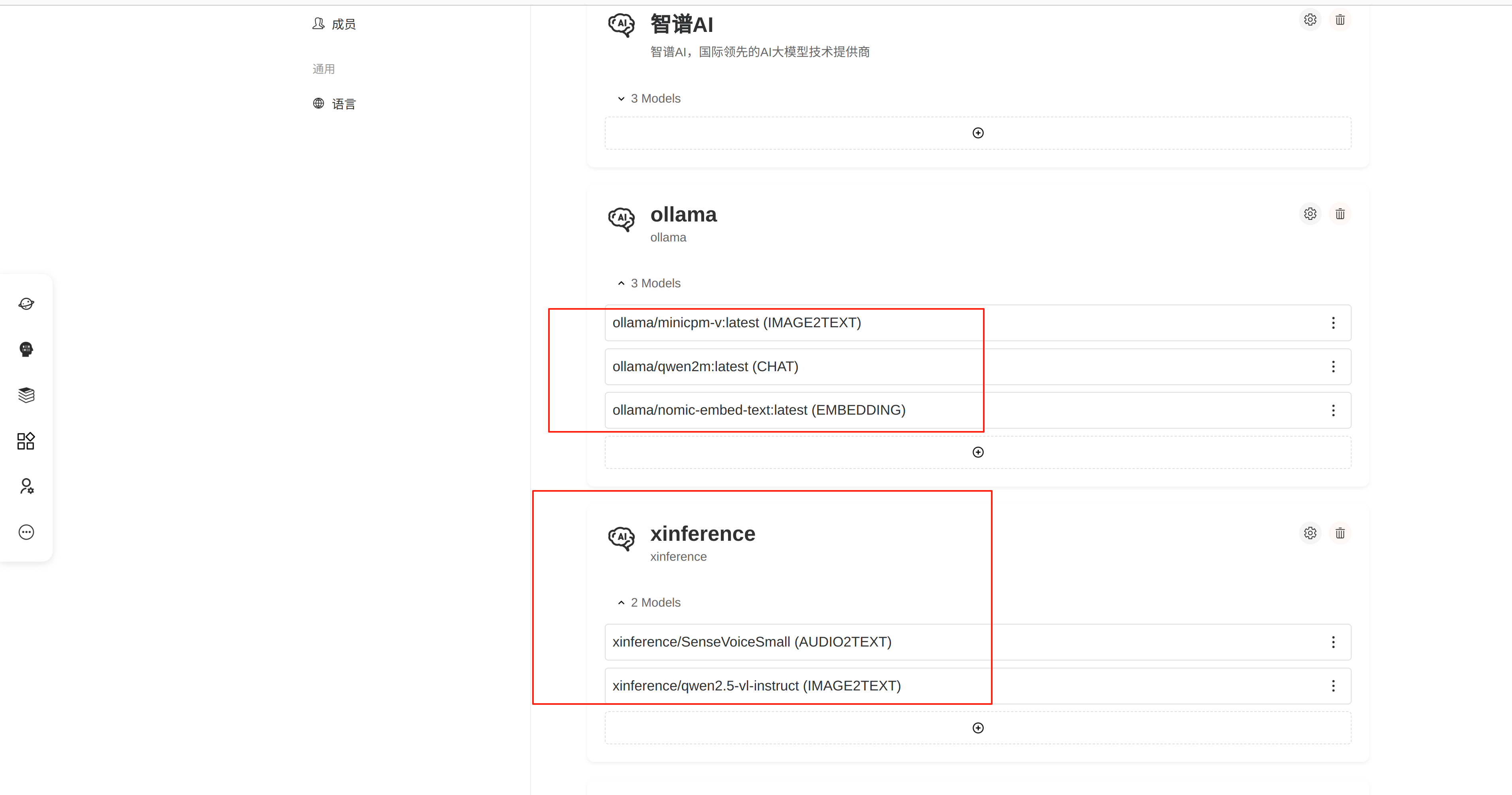
ollama目前尚不支持语音识别,但支持图片的识别
xinference支持openai模型,支持语音的识别,也支持图像识别。
这里的举例,配置语音识别使用xinference的语音识别,图像识别使用ollama,embedding使用ollama的nomic-embed-text
4.1 基础环境准备
4.1.1 安装xinference部署语音识别模型
通过容器部署xinfrence:
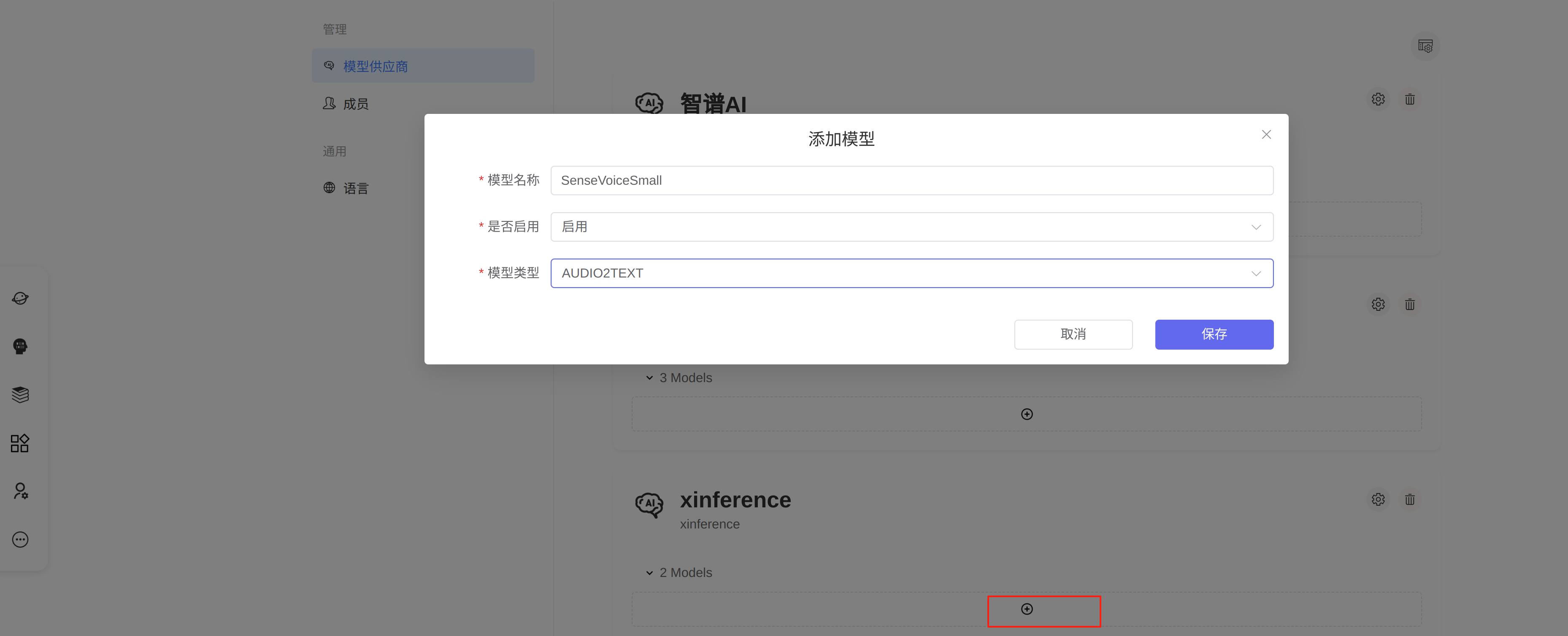
docker run --name xinference -d -p 9997:9997 -e XINFERENCE_HOME=/data -v /data/xinference:/data --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.0打开浏览器输入地址http://127.0.0.1:9997/打开管理页面,点击启动模型->音频模型,选择
SenseVoiceSmall
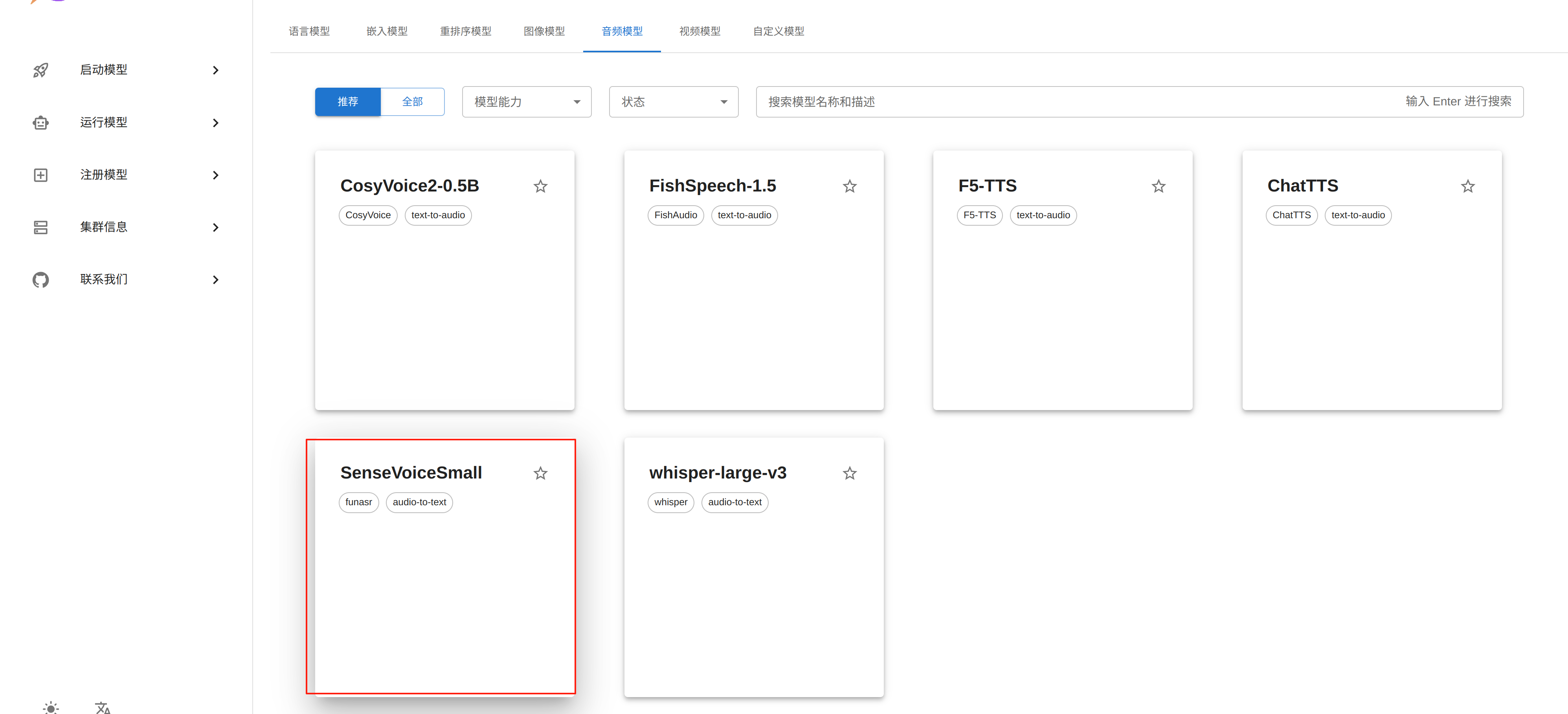
下载中心选择modelscope,然后点击左下角小火箭,开始部署。xinference自动从modelsocpe下载模型,并部署
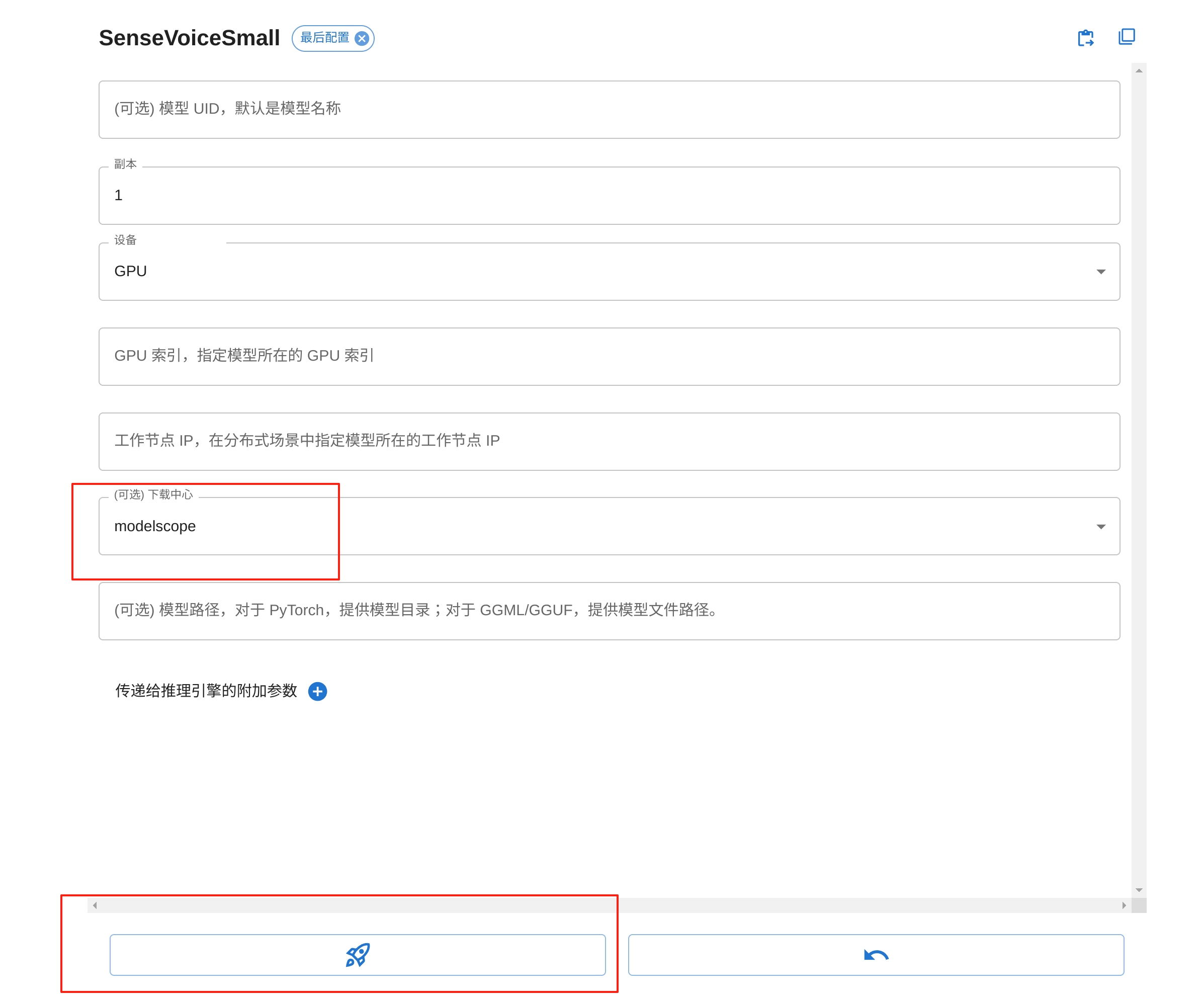
部署成功后,可以点击运行模型->音频模型,看到正在运行的SenseVoiceSmall

4.1.2 安装ollama部署图像识别模型、embedding模型、chat模型
用户可以自己下载ollama容器,也可以自动下载代码编译。
docker run -d --netowk host -v /ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama下载图像识别模型
docker exec -it ollama ollama pull minicpm-v:latest下载embedding模型
docker exec -it ollama ollama pull nomic-embed-text:latest下载chat模型
docker exec -it ollama ollama pull qwen2:latest
docker ollama show --modelfile qwen2 > /ollama/Modelfile
修改模型文件Modelfile
PARAMETER num_ctx 32768
重新创建模型
docker ollama create -f /root/.ollama/Modelfile qwen2m4.2 配置模型
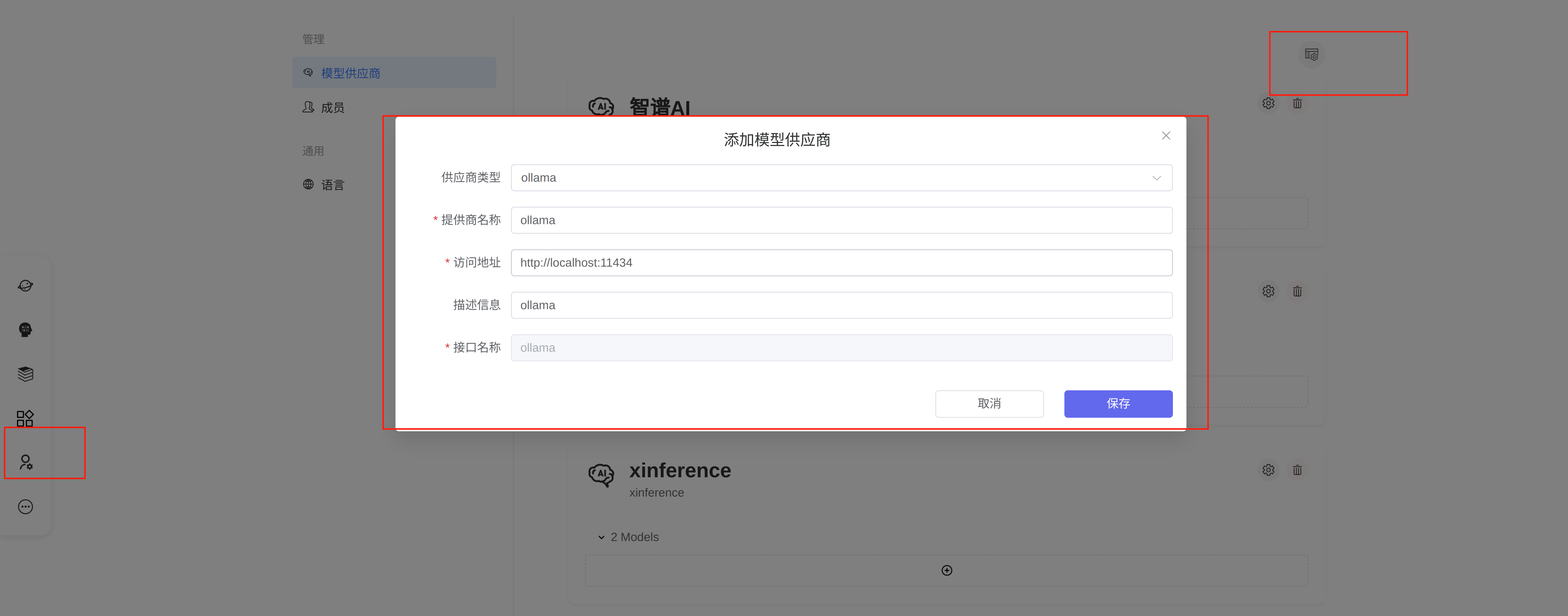
点击配置-供应商,可以添加供应商,在添加供应商之后,选择相应的供应商后,添加相应的模型
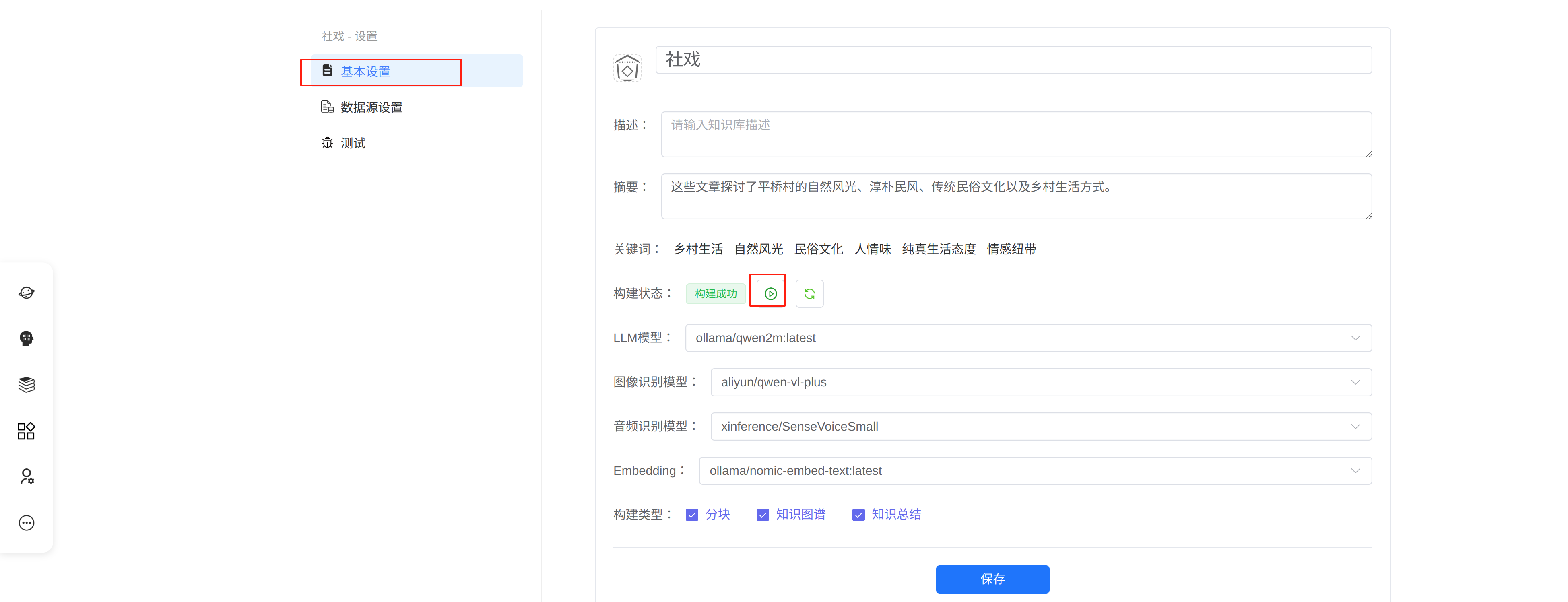
4.3 创建知识库
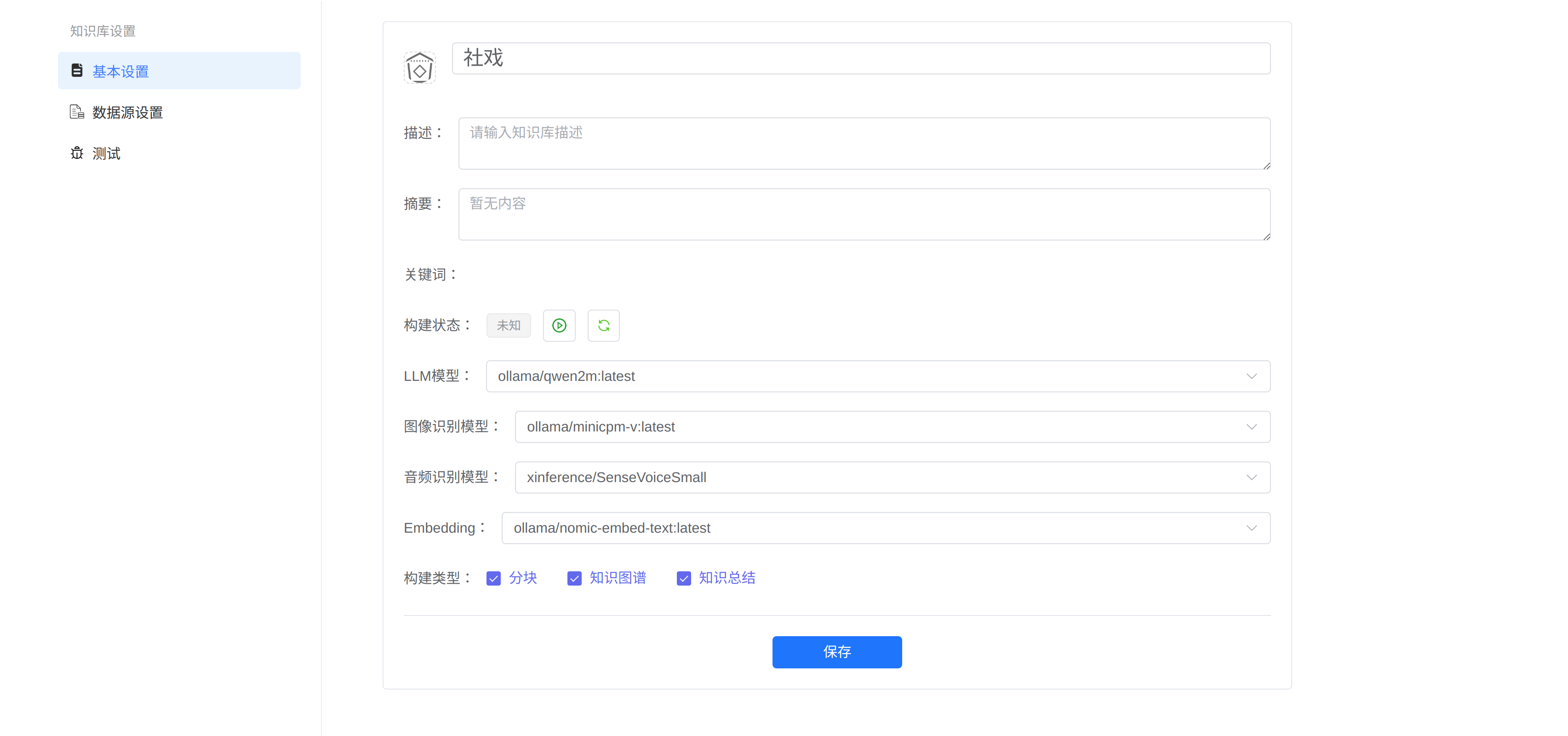
点击知识库按钮->创建按钮,准备创建知识库

在这里输入知识库的名称,选择模型和构建的类型,分块无论是否选择,都是必须要做的。摘要和关键在知识总结后,才会有内容。点击保存后,空白的知识库创建完成,用户可以准备好上传的文件。
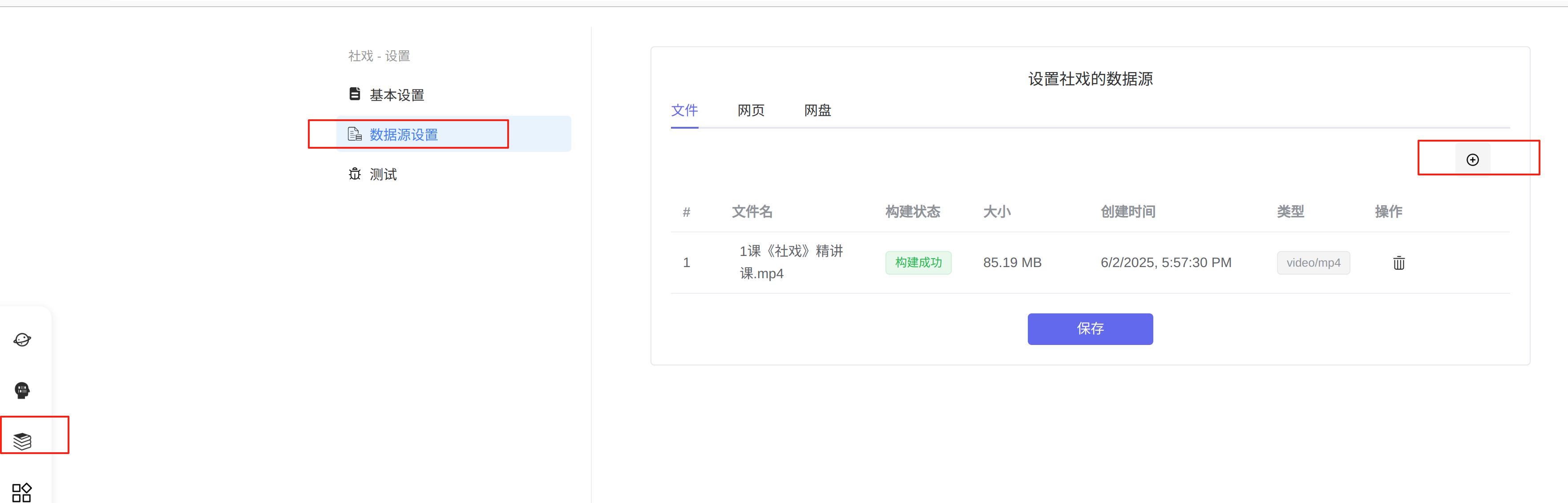
4.4 上传视频
4.5 开始构建
开始构建,构建有两种方式:增量构建和全量构建,全量构建是会删除之前的构建内容,从头开始,增量构建并不会删除以前的内容,而是处理未处理的文件。
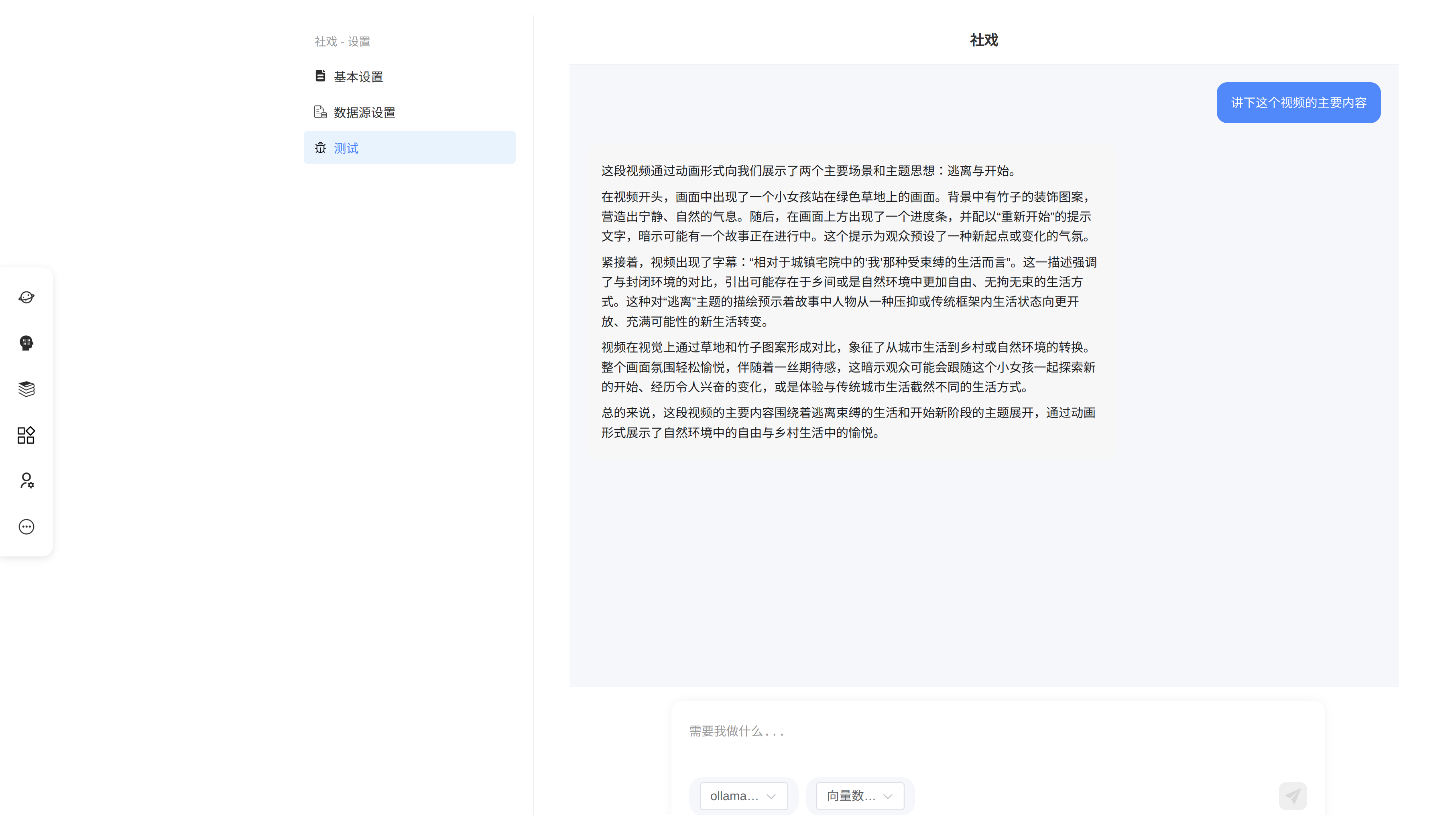
4.6 进行知识问答测试
用户选择适当的chat模型进行测试,如果不选择,则默认是知识库进行知识提取时的模型。