工程建设合同湖南专业seo优化
学习笔记(24): 机器学习之数据预处理Pandas和转换成张量格式[2]
学习机器学习,需要学习如何预处理原始数据,这里用到pandas,将原始数据转换为张量格式的数据。
学习笔记(23): 机器学习之数据预处理Pandas和转换成张量格式[1]-CSDN博客
下面介绍下:处理缺失值(删除法)
为什么要这样做?
这种处理缺失值的策略很实用,当某列的缺失值比例过高时,保留该列可能会对后续分析造成负面影响。删除缺失值最多的列可以避免在缺失值填充时引入过多噪声,提高数据质量。
原始数据:
NumRoos Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
1、处理缺失值(删除法)
“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在这里,我们将考虑删除法。
1.1、代码
# 处理缺失值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
# 转换 NumRoos 列为数值类型(将 'NA' 转为 NaN)
inputs['NumRoos'] = pd.to_numeric(inputs['NumRoos'],errors='coerce')# 计算每列的缺失值数量
miss_counts = inputs.isna().sum()
print("\n各列缺失值数量:")
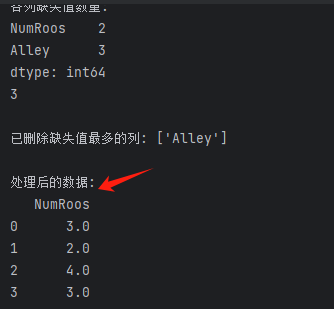
print(miss_counts)# 找出缺失值最多的列
if not miss_counts.empty:max_miss = miss_counts.max() # 计算最大缺失值数量,结果为3(Alley列有3个缺失值print(max_miss)clos_drop = miss_counts[miss_counts ==max_miss].index.tolist() #筛选出缺失值数量等于最大值的列,miss_counts == max_miss 返回布尔 Seriesinputs = inputs.drop(columns=clos_drop) #删除筛选出的列print(f"\n已删除缺失值最多的列: {clos_drop}")# 用均值填充 NumRoos 列的缺失值
inputs['NumRoos'] = inputs['NumRoos'].fillna(inputs['NumRoos'].mean())print("\n处理后的数据:")
print(inputs)代码解析如下
1. 数据分割:提取输入特征和输出标签
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]inputs:提取数据的前两列(索引 0 和 1)作为特征(NumRoos和Alley)。
outputs:提取第三列(索引 2)作为目标变量(Price)。
2. 将NumRoos列转换为数值类型
inputs['NumRoos'] = pd.to_numeric(inputs['NumRoos'], errors='coerce')pd.to_numeric(..., errors='coerce'):将字符串类型的数值转换为数字,无法转换的(如NA)会被转为NaN(缺失值)。
3. 计算每列的缺失值数量
miss_counts = inputs.isna().sum()
print("\n各列缺失值数量:")
print(miss_counts)
inputs.isna():返回一个布尔型 DataFrame,标记每个位置是否为缺失值。
.sum():统计每列的True(缺失值)数量。
#筛选出缺失值数量等于最大值的列
clos_drop = miss_counts[miss_counts == max_miss].index.tolist()
这行代码主要做了三件事:筛选、提取索引、转换为列表。
1、筛选操作
missing_counts[...]miss_counts == max_miss 返回布尔 Series
miss_counts[...] 筛选出值为True的行(即Alley)。# 结果:
# NumRoos False
# Alley True
# dtype: bool2、
.index获取列名筛选结果是一个新的 Series,我们需要它的索引(也就是列名)
# 结果:
# Index(['Alley'], dtype='object')3、
.tolist()转换为列表.index.tolist() 将列名转为列表 ['Alley']。
为什么要转换为列表?
你可能会问:为什么不直接用索引对象,而非要转成列表呢?这主要是为了兼容drop()方法。drop()方法的columns参数可以接受列名列表或索引对象,但列表更灵活,方便后续处理。
关键细节总结
1、缺失值处理策略:
优先删除缺失比例最高的列(Alley列缺失率 75%)。
对剩余列(NumRoos)用均值填充。
2、数据类型转换:
pd.to_numeric(..., errors='coerce') 是处理含缺失值的数值列的常用方法。
3、边缘情况处理:
当有多个列缺失值数量相同时(如两列均有 3 个缺失值),会同时删除这些列。
if not miss_counts.empty 确保无缺失值时不会报错。
# 用均值填充 NumRoos 列的缺失值
inputs['NumRoos'] = inputs['NumRoos'].fillna(inputs['NumRoos'].mean())
inputs['NumRoos'].mean():计算NumRoos列的均值(结果为 3.0,因为有效数值为 2 和 4)。
.fillna(...):将NumRoos列的缺失值(NaN)填充为均值 3.0。
1.2、执行结果
2、转换为张量格式
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。
2.1、代码
import torch
print("\n转换成张量数据:")
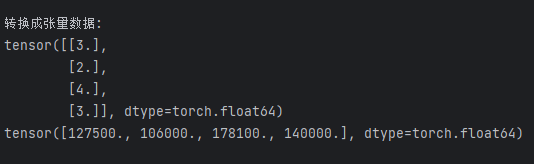
x = torch.tensor(inputs.to_numpy(dtype=float))
print(x)
y = torch.tensor(outputs.to_numpy(dtype=float))
print(y)2.2、执行结果
-
pandas软件包是Python中常用的数据分析工具中,pandas可以与张量兼容。 -
用
pandas处理缺失的数据时,我们可根据情况选择用插值法和删除法。