太原网站建设技术外包长春seo代理
Prefix tuning 、P-tuning v2、P-tuning还在傻傻分不清。
到底有什么区别,本文希望说明白这些区别,如有错误欢迎指出。
一、为什么需要提示学习?
从全参微调到参数高效微调(PEFT),这些微调方法的思想都是重新训练模型的参数以适应下游任务。而提示学习的思想则是用下游任务去适应大语言模型(Large language model,LLM)。其利用预训练模型已经学到的语言知识,避免增加模型额外参数来提高大模型在少样本的学习能力。GPT2认为越大的模型参数和数据量会有更好的效果,在该工作中提出了zero shot以及GPT3中提出了few shot 和one shot的概念。可以说,小样本学习的出现促使了提示学习的发展。
二、提示学习先祖: PET(Pattern Exploiting Training)
这里不介绍概念,直接上例子说明其实现思想。PET步骤:
1.构建模板 (Template): 生成与给定句子相关的一个含有[MASK]标记的模板. 例如It was [MASK], 并拼接到原始的文本中,获得Prompt-Tuning的输入:[CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]. 将其喂入BERT模型中,并复用预训练好的MLM分类器,即可直接得到[MASK]预测的各个token的概率分布。
2.标签词映射 (Verbalizer): 因为[MASK]只对部分词感兴趣,因此需要建立一个映射关系. 例如如果[MASK]预测的词是“great”,则认为是positive类,如果是“terrible”,则认为是negative类。
3.训练: 根据Verbalizer,则可以获得指定label word的预测概率分布,并采用交叉信息熵进行训练。此时因为只对预训练好的MLM head进行微调,所以避免了过拟合问题。
总的来说就是根据不同任务设计prompt模板,然后,mask部分词,做好mask词对应分类的标签映射并训练。
不同的句子应该有不同的template和label word,因此如何最大化的寻找当前任务更加合适的template和label word是PET非常重要的挑战。
三、从PET的hard Prompt 到 soft Prompt
上述PET其实是一种hard Prompt的形式,其显然存在一个缺点就是需要根据不同任务设计不同的模板。
因此 soft Prompt 应运而生。
首先,什么是hard Prompt呢。
Hard Prompt也称为离散提示: 是一种固定的提示模板,通过将特定的关键词或短语(真实的文本字符串)直接嵌入到文本中,引导模型生成符合要求的文本.特点: 提示模板是固定的,不能根据不同的任务和需求进行调整.缺陷:依赖人工,改变prompt中的单个单词会给实验结果带来巨大的差异. 比如:
案例:情感分类任务• 任务:电影评论情感分类• 输入:我很喜欢迪士尼的电影。• 模板:这部电影真是[MASK]。• 拼接后:我很喜欢迪士尼的电影。这部电影真是[MASK]。• 输出:如果 [MASK] 预测为 棒极了,则是正向情感;如果预测为 糟透了,则是负向情感。Soft Prompt也称为连续提示:是指通过给模型输入一个可参数化的提示模板,从而引导模型生成符合特定要求的文本。特点: 提示模板中的参数可以根据具体任务和需求进行调整,以达到最佳的生成效果。优点:不需要显式地指定这些模板中各个token具体是什么,而只需要在语义空间中表示一个向量即可。
案例:情感分类任务
• 输入句子: “我喜欢这部电影。”
• 拼接: [可训练的连续Prompt 向量] + 我喜欢这部电影。 + [MASK]
• 模型预测: [MASK] = “棒极了” → 分类结果为“正向”。四、如何去优化提示模板?
这里参考[1]中的分析来说明提示模板优化的角度有哪些,再来介绍具体的提示词方法。
1.模板的任务是使得下游任务跟预训练任务一致,这样才能更加充分地利用原始预训练模型,起到更好的零样本、小样本学习效果。我们并不关心模板是不是自然语言,而是只需要知道模版
由哪些token组成
有多少个token
该插入到哪里
插入后能不能完成我们的下游任务
输出的候选空间是什么。
因此优化提示词可以从下述三个角度考虑:
1. 对virtual token的处理:随机初始化或者基于一个可训练学习的模型编码
2. 需要参与微调的参数:某一层、全量或者其他选择
3. 调整适配下游任务的方式
五、各种指示学习方法
指示学习的具体发展时间线:
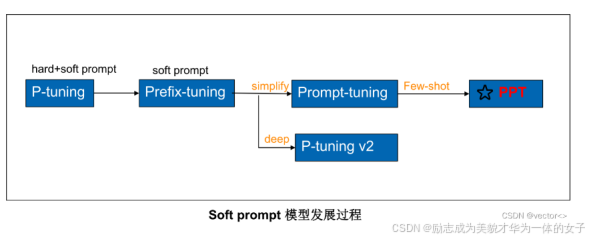
(一)P-Tuing
1.一种hard+soft的连续提示方法(有部分提示词不需要训练)。
2.先经过MLP或者LSTM选择virtual token然后输入给模型。
3.将Prompt转换为可以学习的Embedding层。只训练embedding中virtual token部分的权重。
4.virtual token的位置可选。
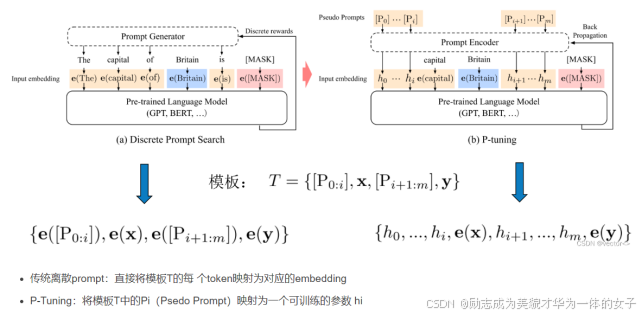
(二)Prefix Tuing
1.对virtual token的编码方式
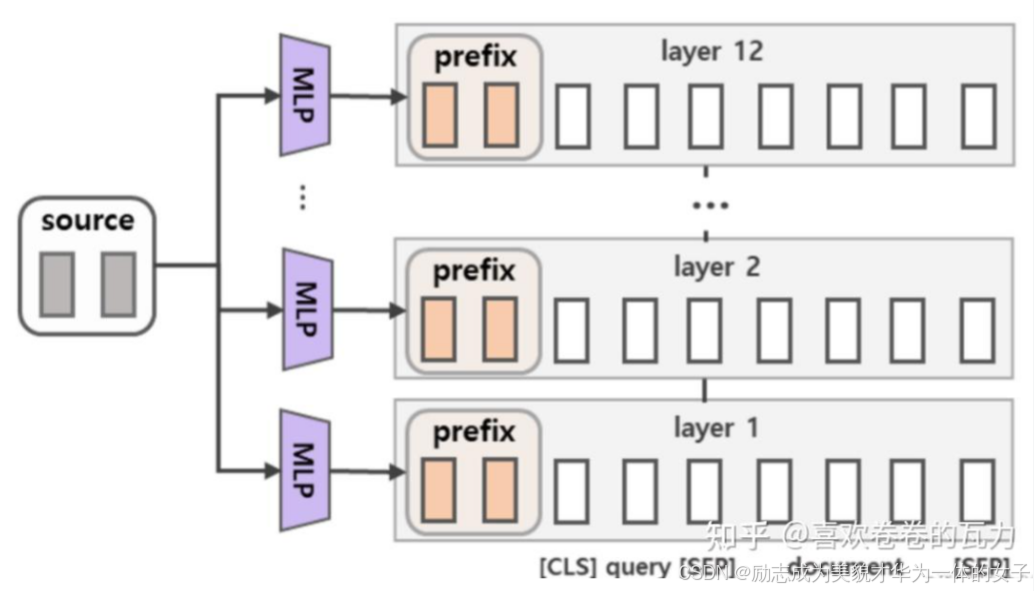
为了防止直接更新 Prefix 的参数导致训练不稳定和性能下降的情况,在 Prefix 层前面加了 MLP 结构,训练完成后,只保留 Prefix 的参数。
2.只调整embedding层的表现力不够,将导致性能显著下降,因此,在每层都加了prompt的参数,改动较大。
prefix tuning将多个prompt vectors 放在每个multi-head attention的key矩阵和value矩阵之前。
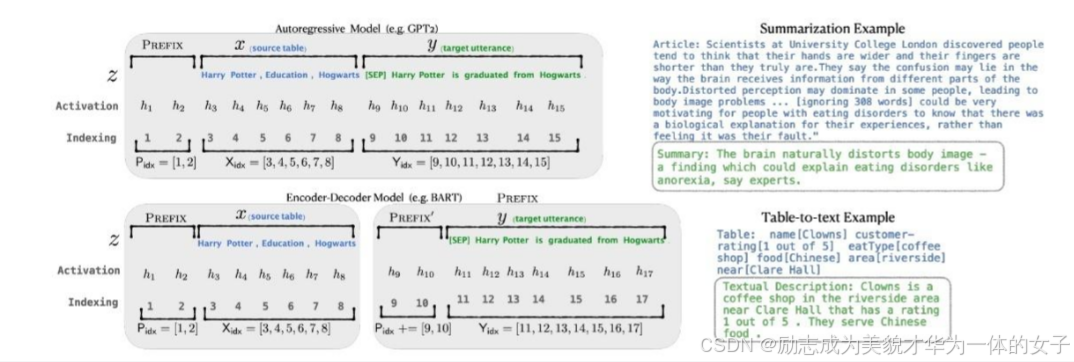
3.适配不同任务的prefix构造形式
对于Decoder-only的GPT,prefix只加在句首,对于Encoder-Decoder的BART,不同的prefix同时加在编码器和解码器的开头。
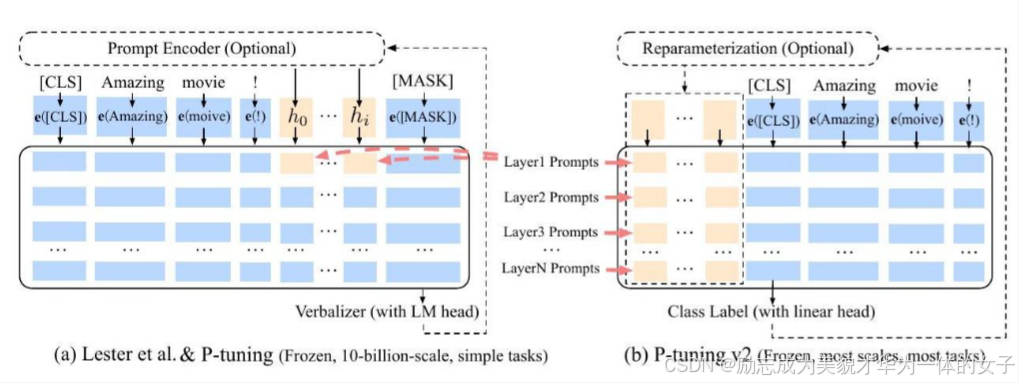
(三)P-Tuing V2
Prefix Tuing和P-Tuing中存在缺少深度提示优化的问题,即在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。(1)由于序列长度的限制,可调参数的数量是有限的。(2)输入embedding对模型预测只有相对间接的影响。
1.Ptuning v2,在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层。使得模型有更多的可训练参数以及使得Prompt能给模型预测带来更直接的影响。(这里与prefix tuing的区别是,Ptuning v2是每一层都加的初始embedding,prefix 是按层数走下来的embedding。)
2.取消了MLP的前缀微调和LSTM的P-tuning。
参考说明
[1]
[大模型微调实践——Prompt tuning、PET、Prefix tuning、P-tuning的原理、区别与代码解析(二) - 知乎