清远做网站公司长沙官网seo收费
一 RAG
(一)什么是RAG
当岳不群相当武林的盟主时候,你的给他一个葵花宝典(秘籍==RAG)

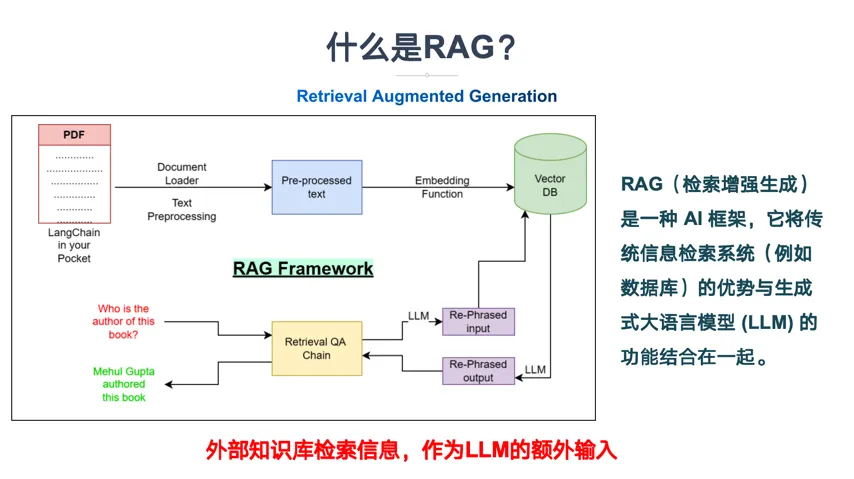
(二)RAG的原理
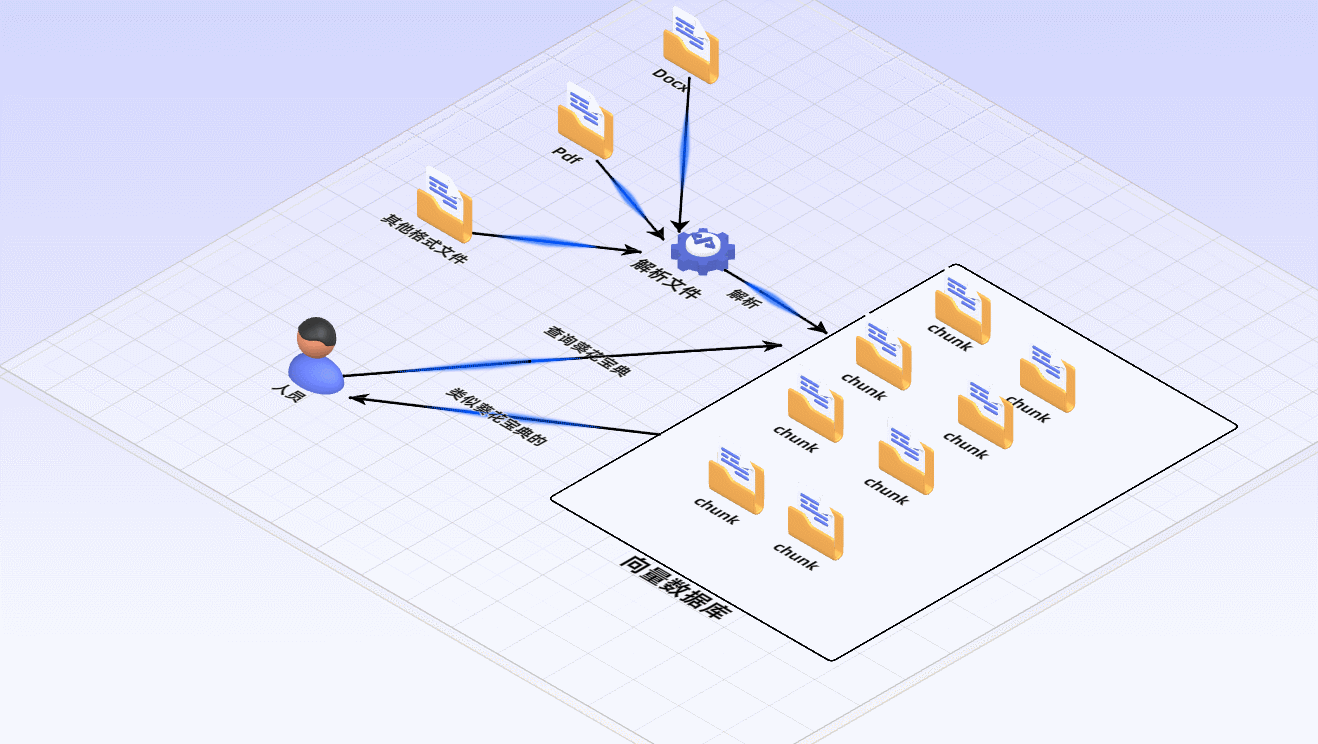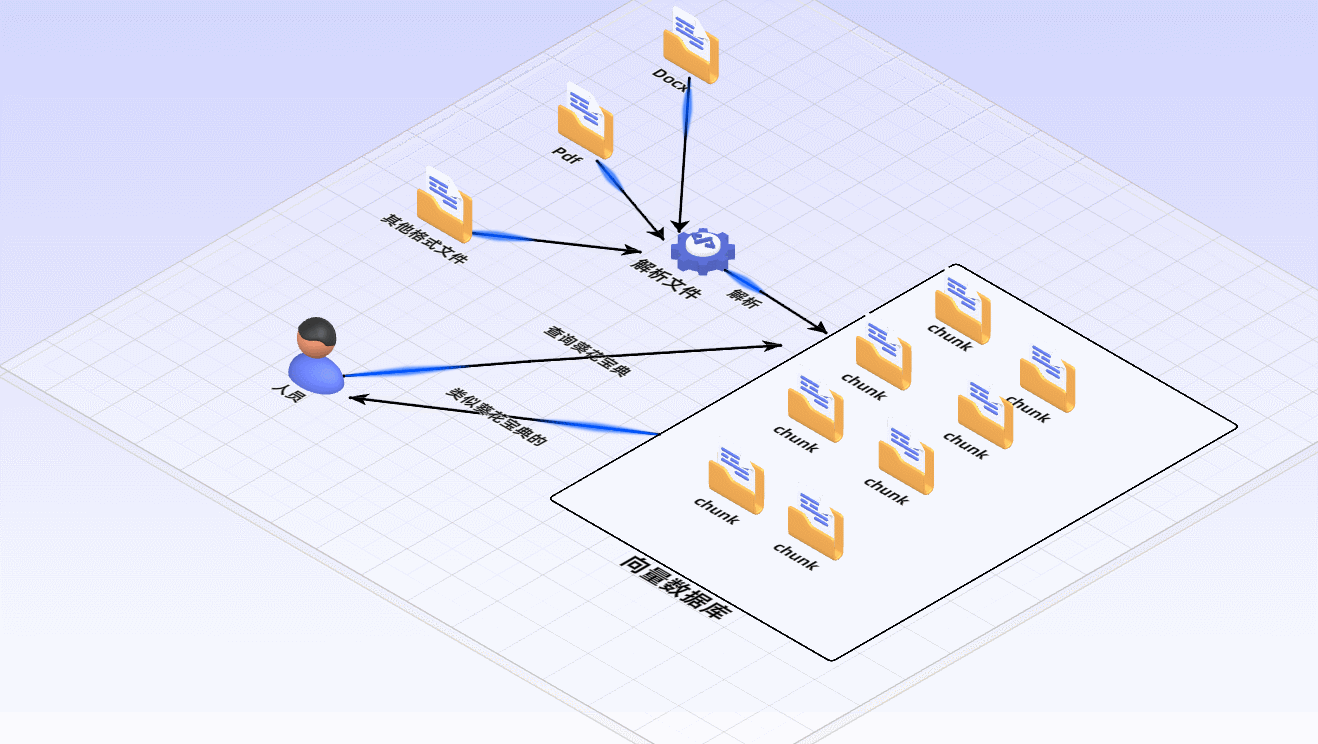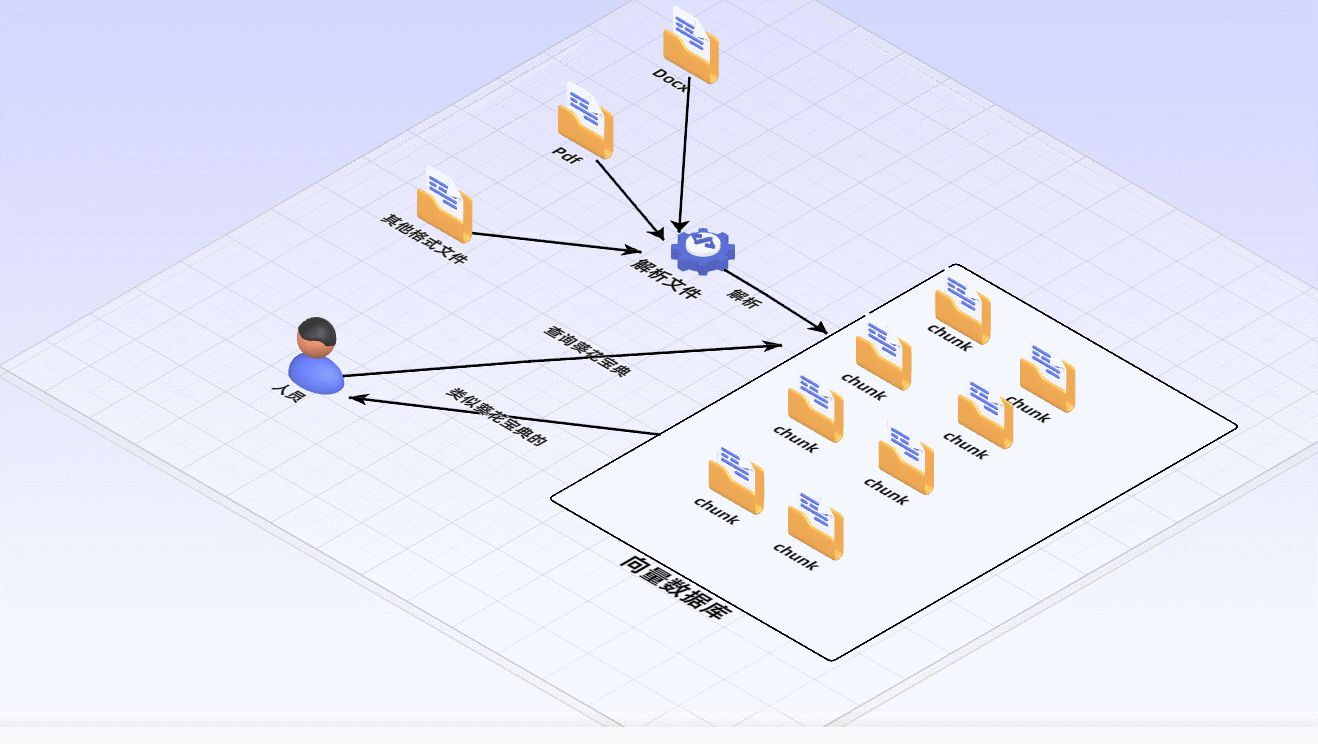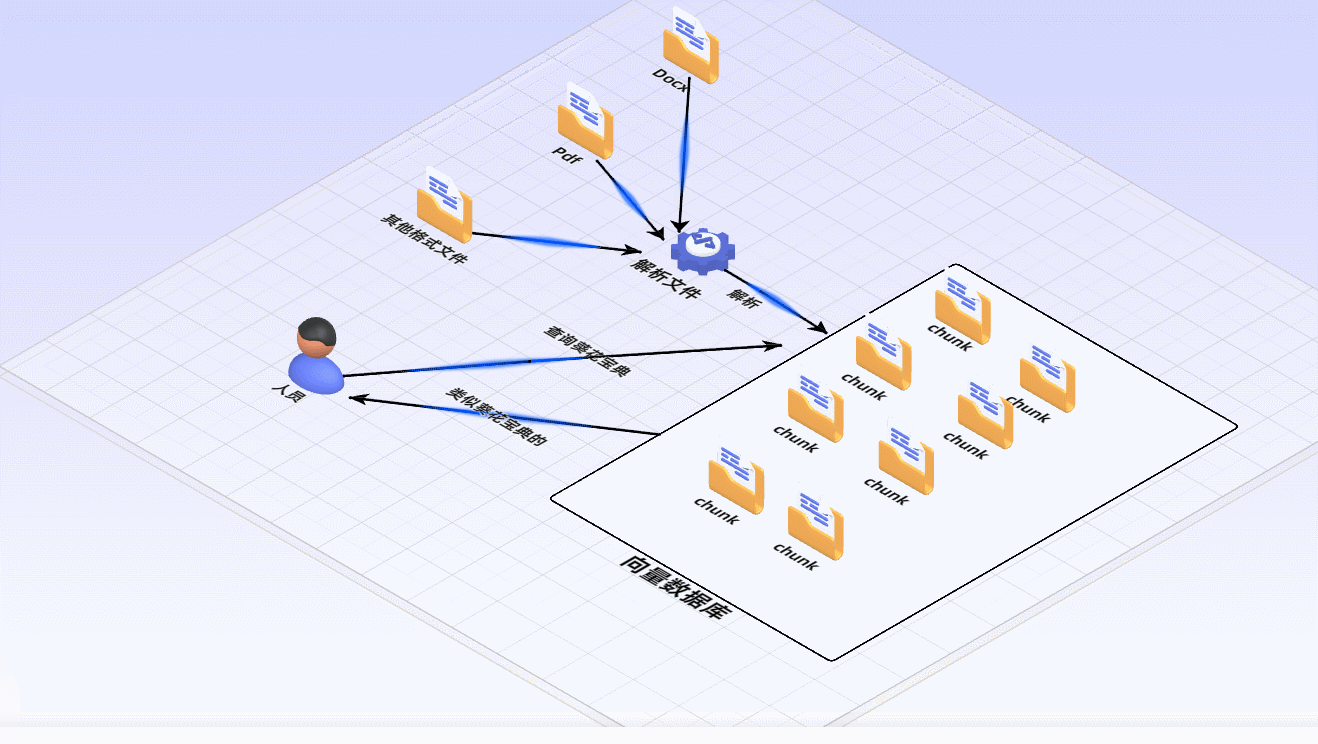
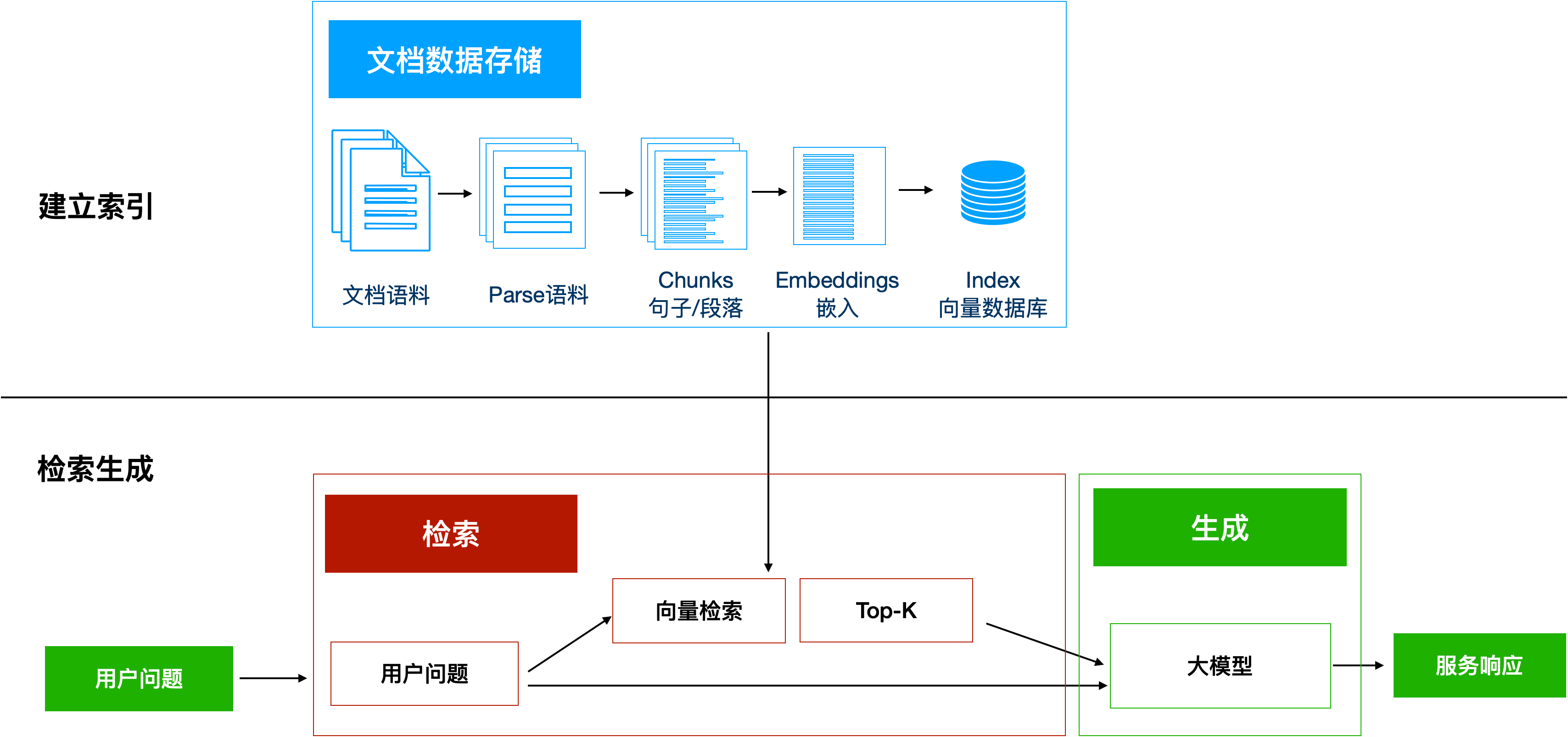
1 建立索引:
首先要清洗和提取原始数据,将 PDF、Docx等不同格式的文件解析为纯文本数据
然后将文本数据分割成更小的片段(chunk);
最后将这些片段经过嵌入模型转换成向量数据(此过程叫做embedding)
并将原始语料块和嵌入向量以键值对形式存储到向量数据库中,以便进行后续快速且频繁的搜索。
2 检索生成:
系统会获取到用户输入,随后计算出用户的问题与向量数据库中的文档块之间的相似度,选择相似度最高的K个文档块(K值可以自己设置)作为回答当前问题的知识。知识与问题会合并到提示词模板中提交给大模型,大模型给出回复。这就是检索生成的过程。
(三)如何持续改进RAG应用效果
1 问题比较抽象或者概念比较模糊**,导致大模型没有准确理解使用者的问题
问题精准性:
| 提问 | 答复 | |
|---|---|---|
| 精准性的问题 | 如何成为武林盟主 | 葵花宝典就能成为武林盟主 |
| 非精准性问题 | 盟主 | 不明确什么问题 |
2 知识库没有检索到问题的答案,
查无此人,库中没有你要找的葵花宝典

3 缺少对答案做兜底验证的机制
库中结果未有验证,谁也没练过葵花宝典
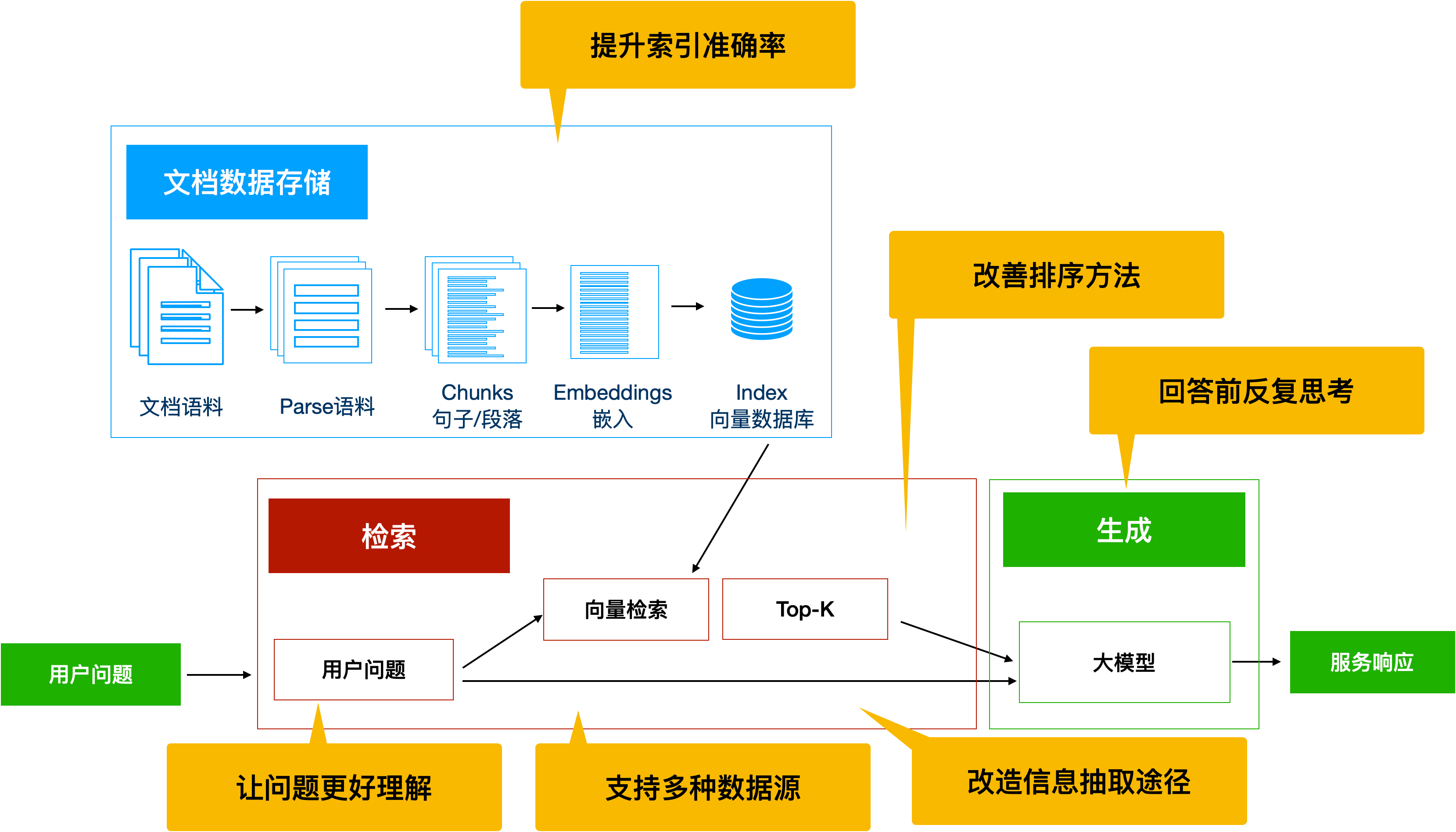
(四)索引准确率
1 构建知识库的时候,我们首先需要正确的从文档中提取有效语料
2 优化chunk切分模式
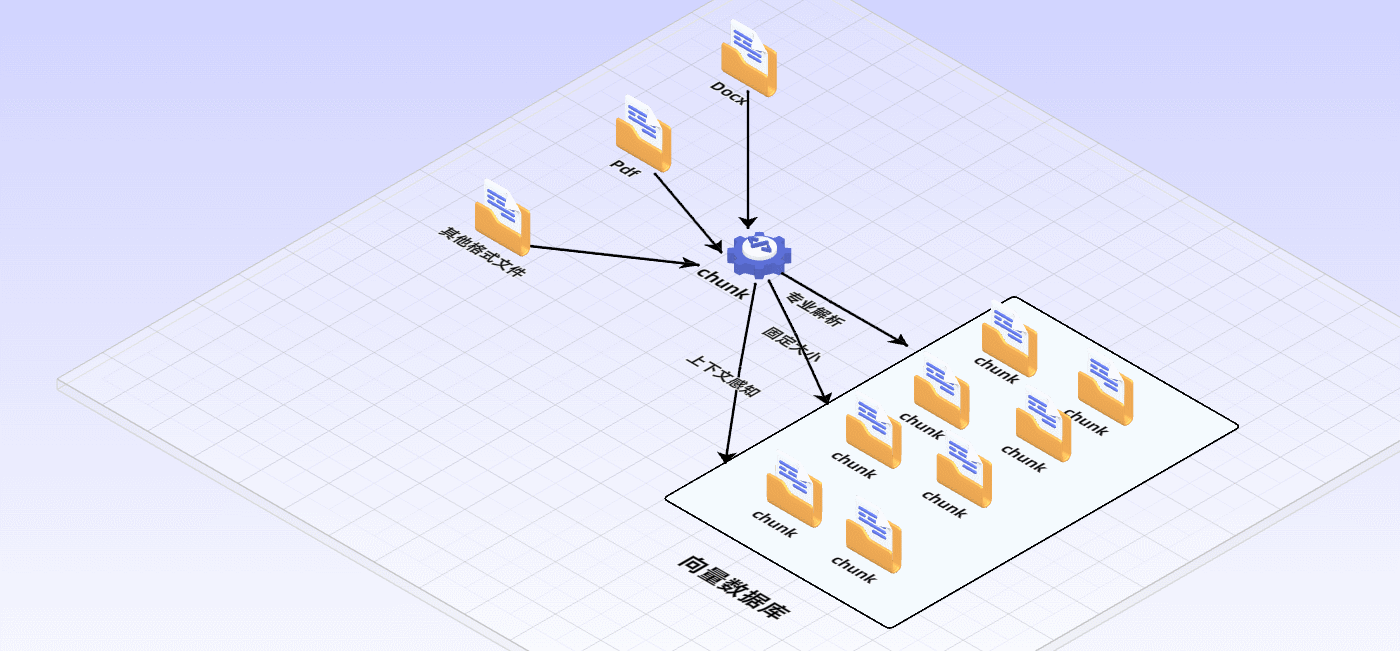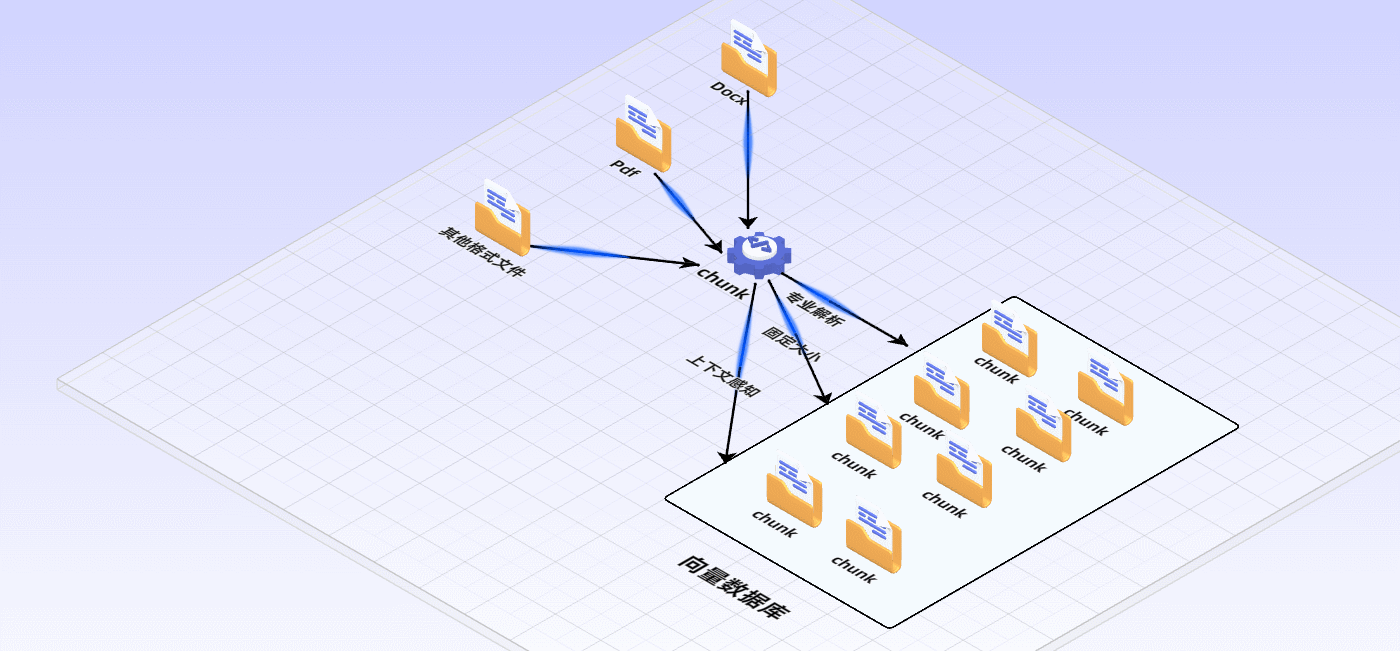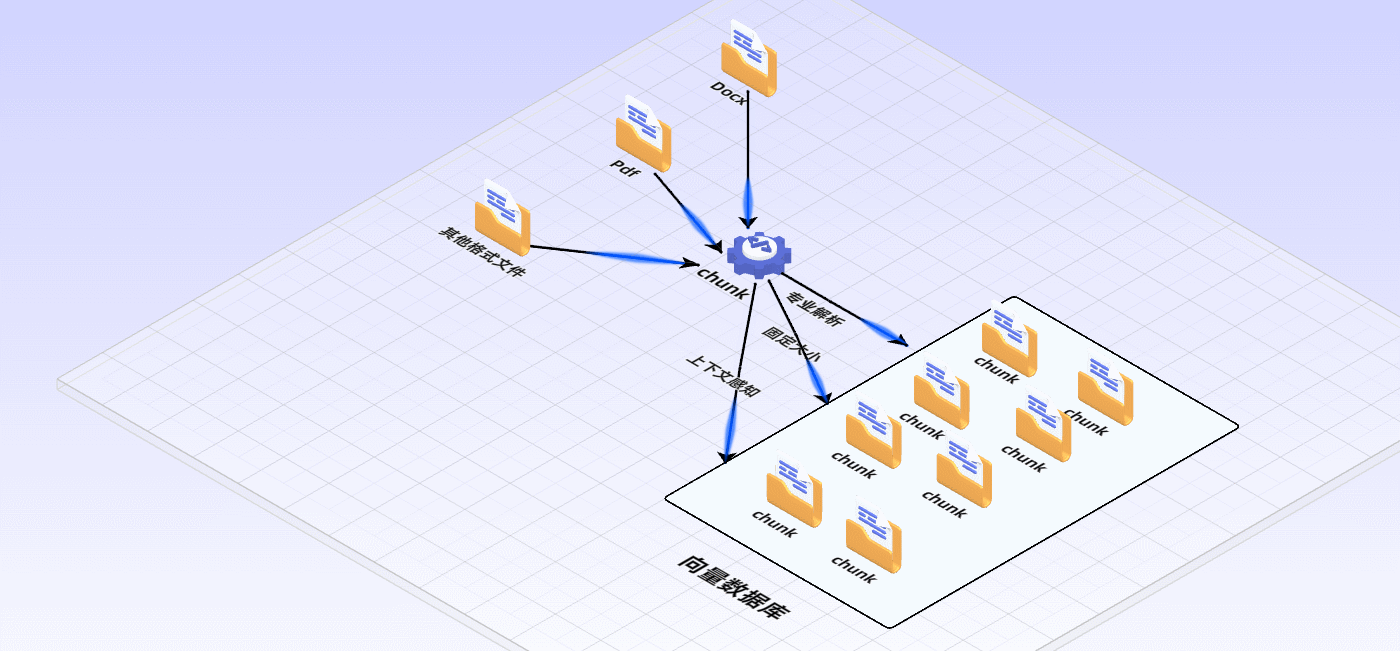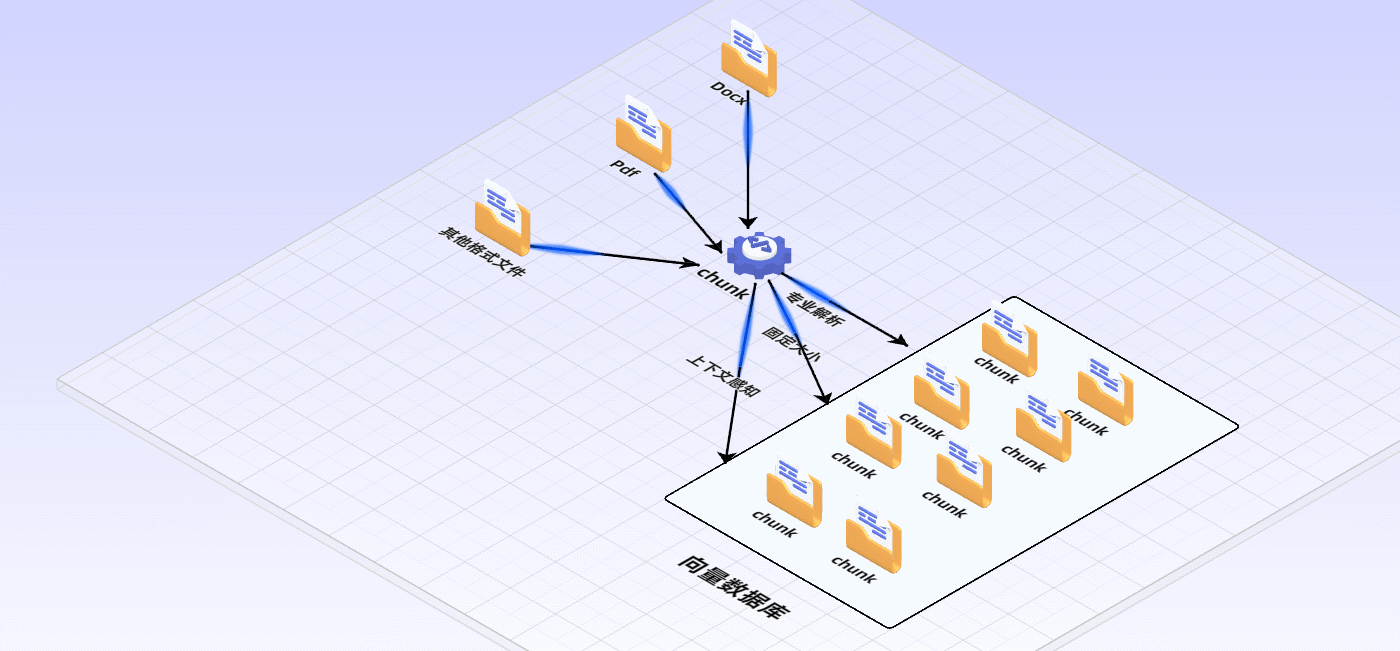
- 利用领域知识:针对特定领域的文档,利用领域专有知识进行更精准的切分。例如,在法律文档中识别段落编号、条款作为切分依据。
- 基于固定大小切分:比如默认采用128个词或512个词切分为一个chunk,可以快速实现文本分块。缺点是忽略了语义和上下文完整性。
- 上下文感知:在切分时考虑前后文关系,避免信息断裂。可以通过保持特定句对或短语相邻,或使用更复杂的算法识别并保留语义完整性。最简单的做法是切分时保留前一句和后一句话。你也可以使用自然语言处理技术识别语义单元,如通过句子相似度计算、主题模型(如LDA)或BERT嵌入聚类来切分文本,确保每个chunk内部语义连贯,减少跨chunk信息依赖。通义实验室提供了一种文本切割模型,输入长文本即可得到切割好的文本块,详情可参考:中文文本分割模型。
3 句子滑动窗口检索
这个策略是通过设置window_size(窗口大小)来调整提取句子的数量,当用户的问题匹配到一个chunk语料块时,通过窗函数提取目标语料块的上下文,而不仅仅是语料块本身,这样来获得更完整的语料上下文信息,提升RAG生成质量。

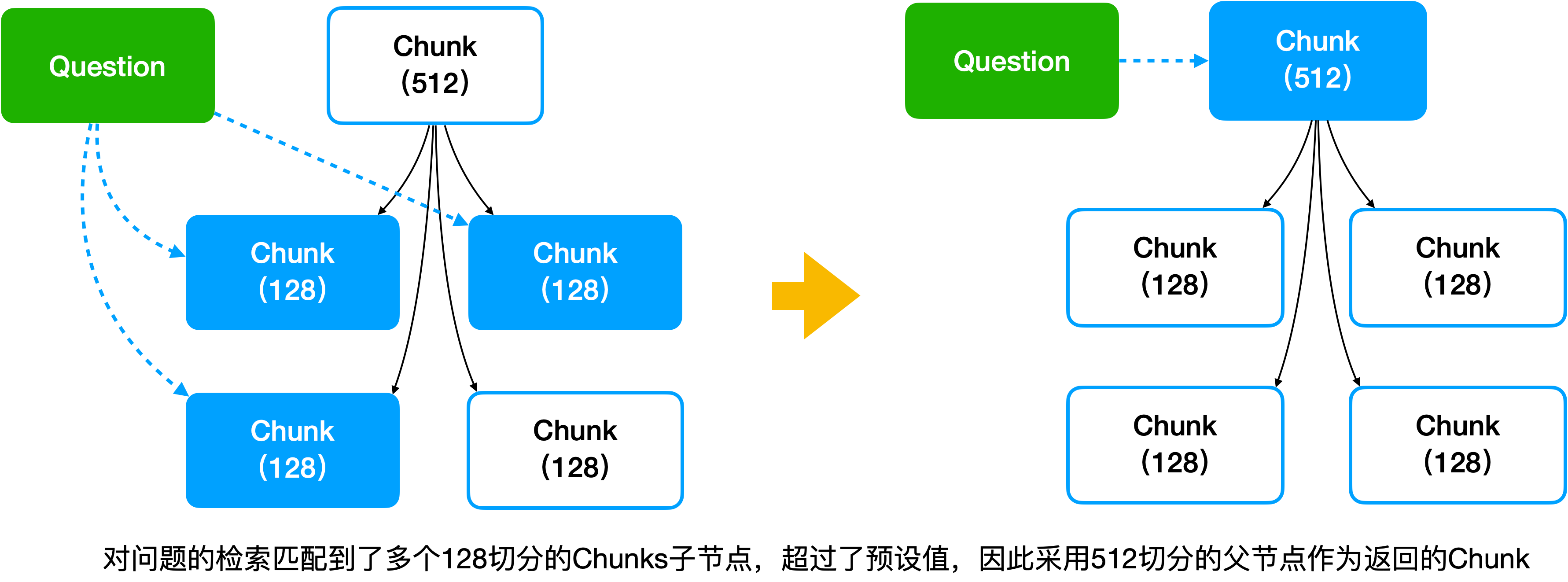
4 自动合并检索
将文档分块,建成一棵语料块的树
5 选择更适合业务的Embedding模型(嵌入式)
chunk语料块由原来的文本内容转换为机器可以用于比对计算的一组数字,即变为Embedding向量
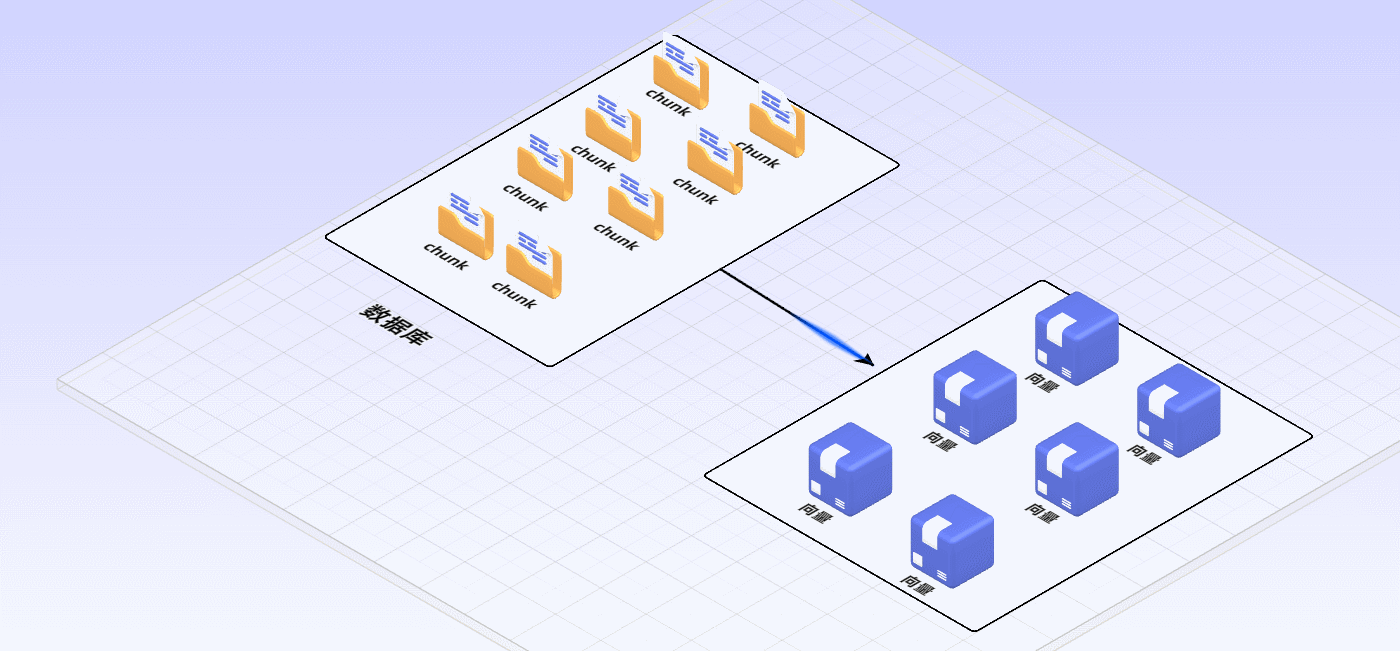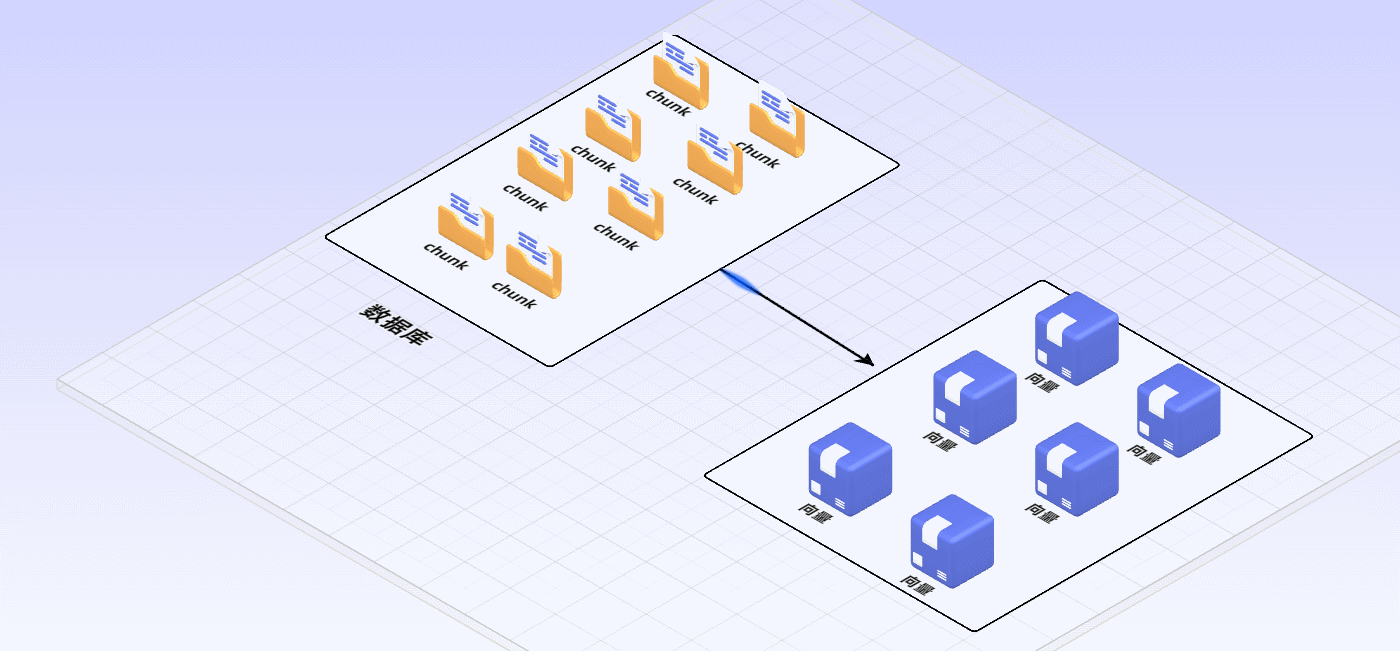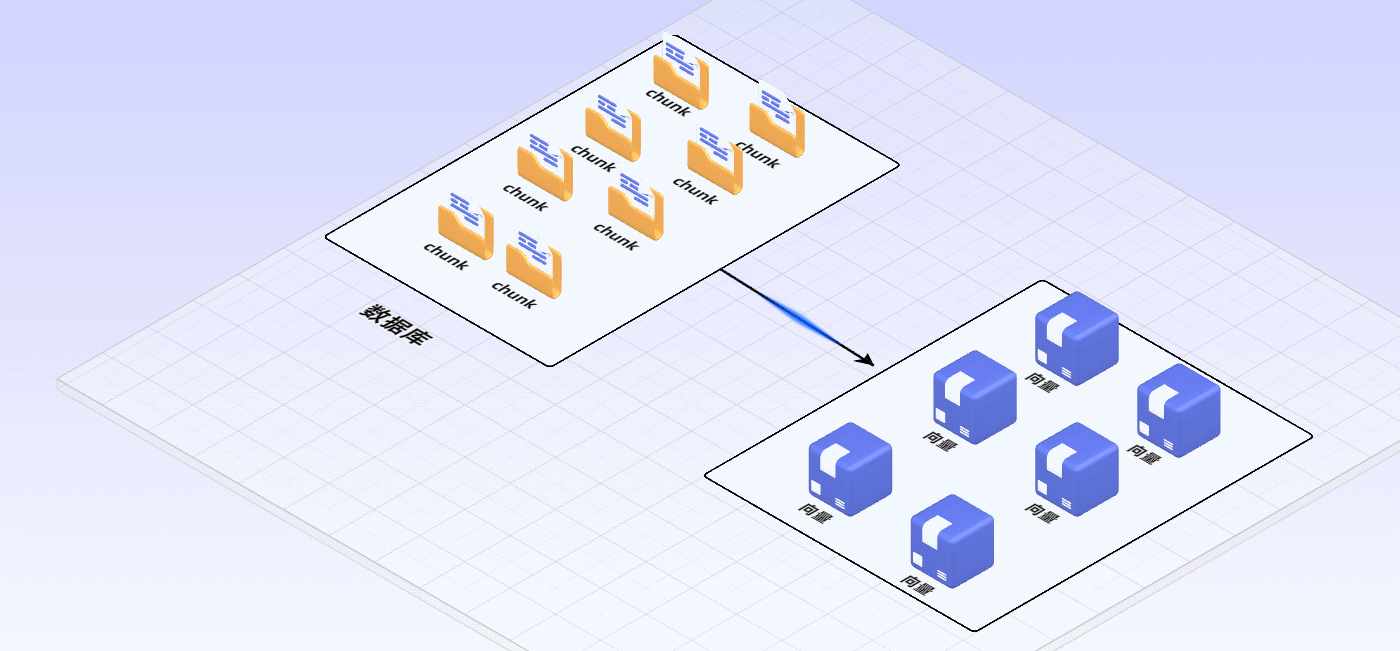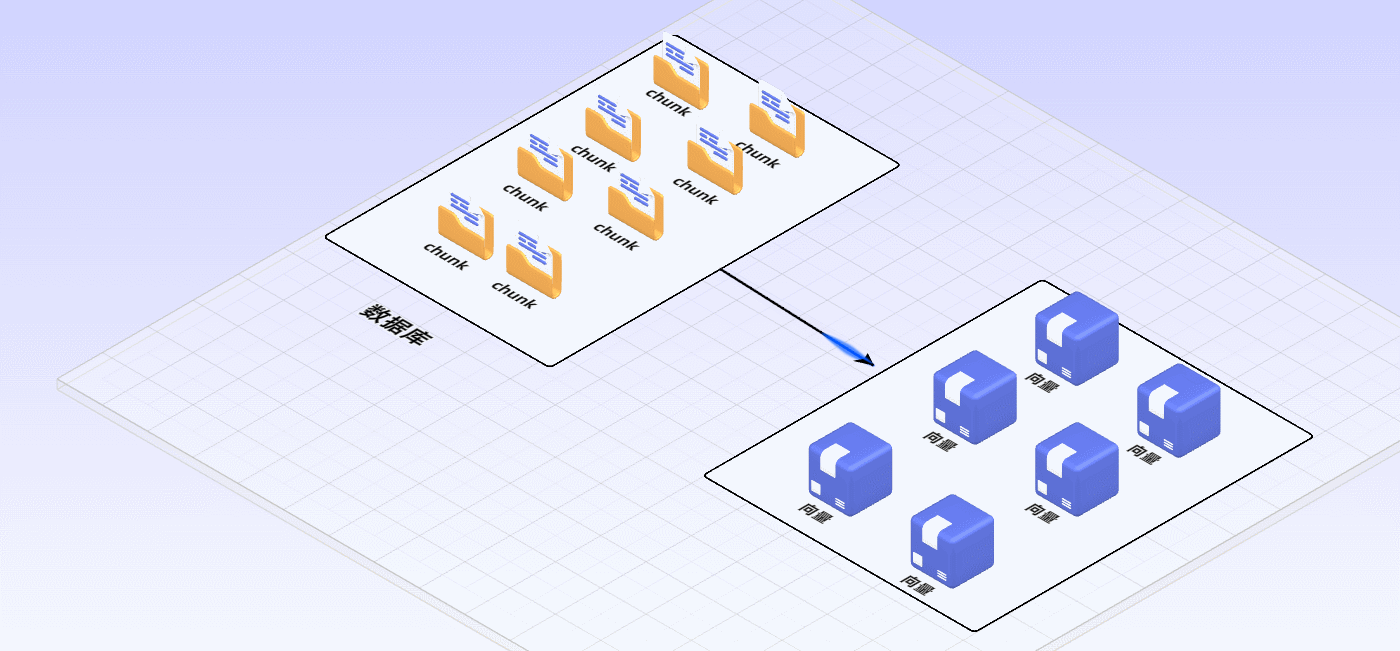
6 更适合业务的ReRank模型(重排序)模型
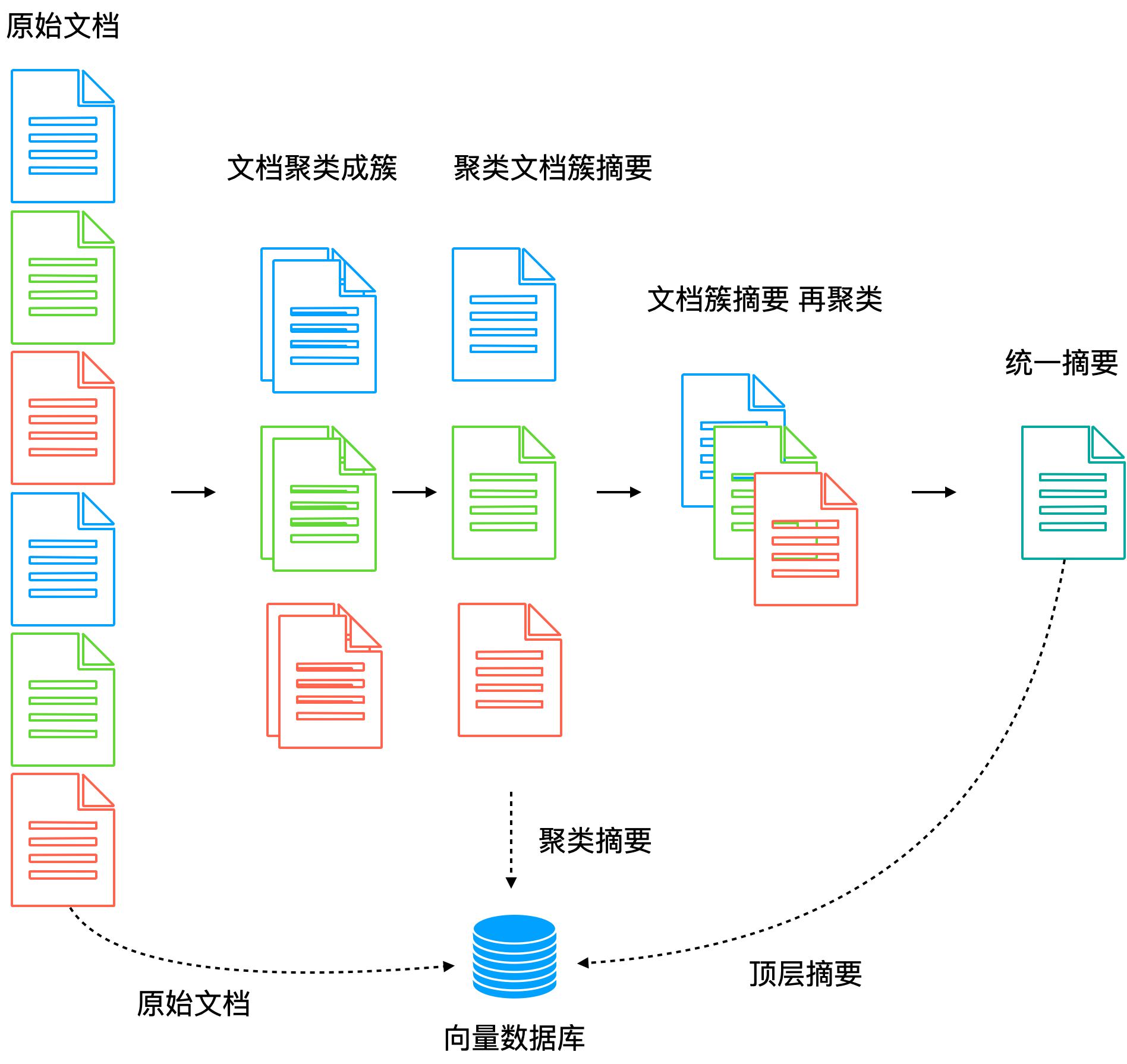
7 Raptor 用聚类为文档块建立索引
做法是采用无监督聚类来生成文档索引。这就像通过文档的内容为文档自动建立目录的过程
(五) 让问题更好理解
1 完善用户问题
- 一种理想的通过多轮对话补全需求的方案。该设想是通过大模型多次主动与用户沟通,不断收集信息,完善对用户真实意图的理解,补全执行用户需求所需的各项参数
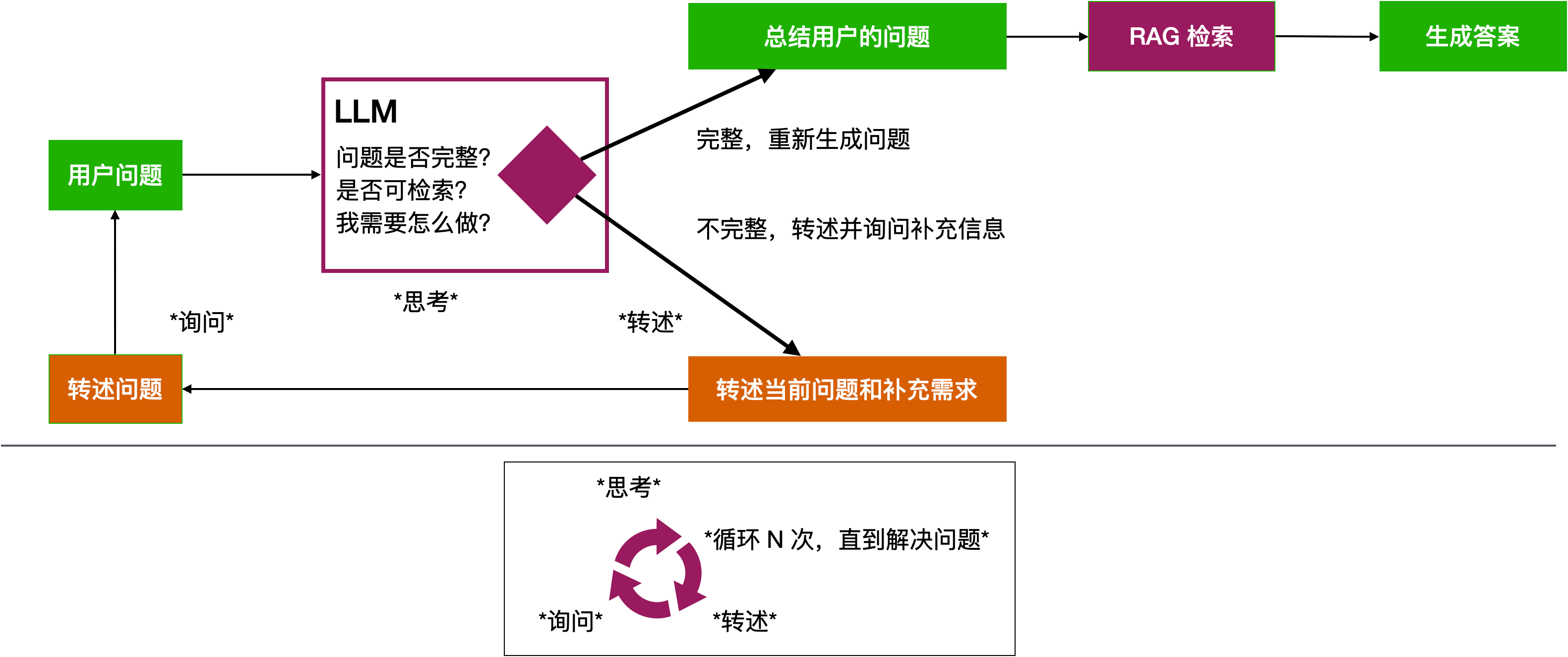
用大模型转述回答,再进行RAG回答,类似指示词思路,让大模型转述用户的问题

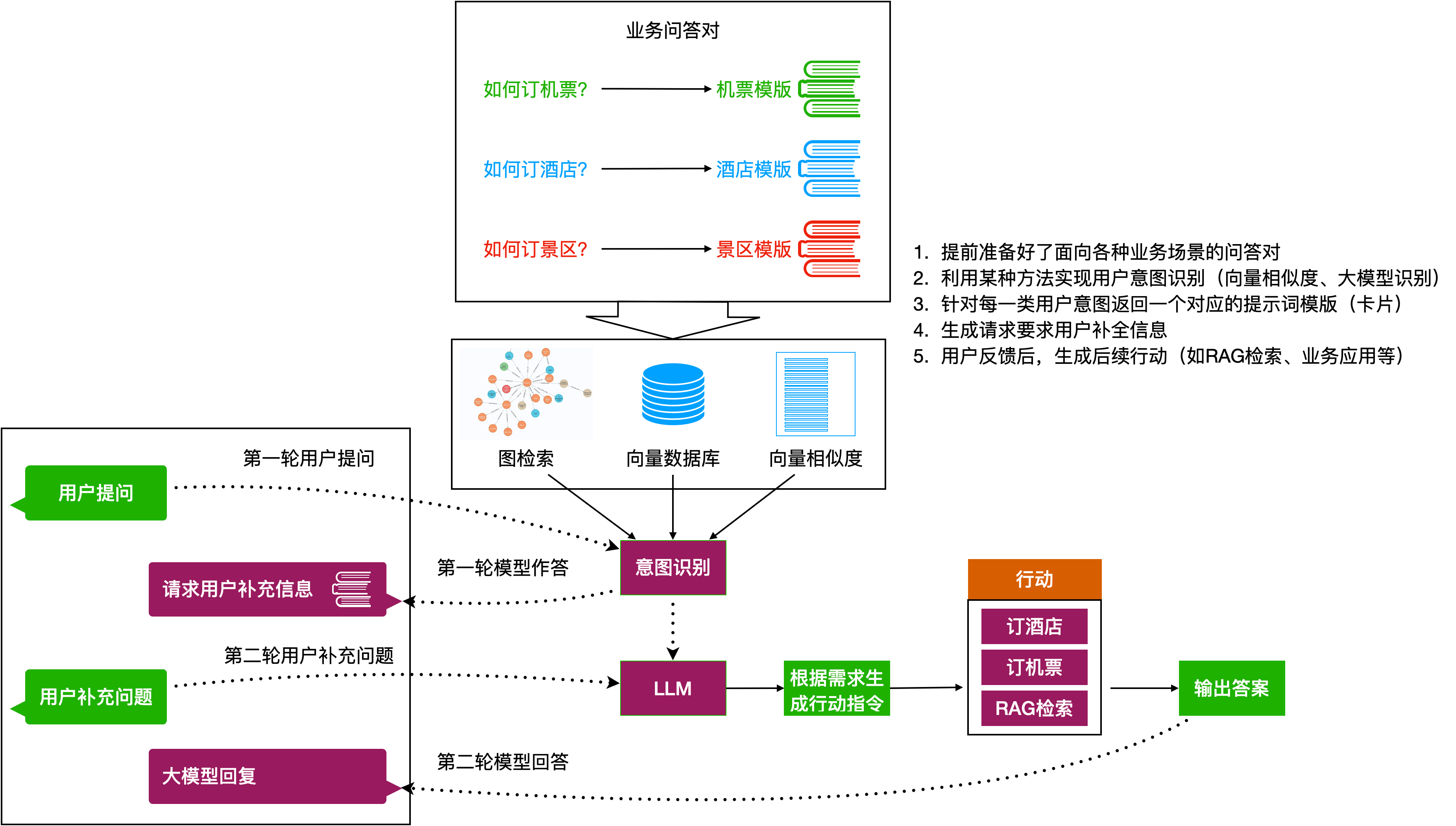
2 让用户补全信息辅助业务调用
有一些应用场景需要大量的参数支撑,(比如订火车票需要起点、终点、时间、座位等级、座位偏好等等),我们还可以进一步完善上面的思路,一次性告诉用户系统需要什么信息,让用户来补全
3 Multi-Query 多路召回
给客户几个问题的选择

| 用户问“烤鸭店在哪里?”,大模型会生成: |
|---|
 |
4 假设问题答案方法
推荐一家烤鸭店”,第一时间想到了“全聚德烤鸭店不错,我前两天刚吃过!”

(六)改造信息抽取途径
- 向量相似度,我们用检索信息得到的向量相似度分来判断。判断每个语料块与用户问题的相似度评分,是否高过某个阈值,如果搜索到的语料块与用户问题的相似度都比较低,就代表知识库中的信息与用户问题不太相关;
- 直接问大模型,我们可以先将知识库检索到的信息交给大模型,让大模型自主判断,这些资料是否能回答用户的问题。

1 回答前反复思考
- 相关性:我获取的这些材料和问题相关吗?
- 无幻觉:我的答案是不是按照材料写的来讲,还是我自己编造的?
- 已解答:我的答案是不是解答了问题?
(七)从多种数据源中获取资料**
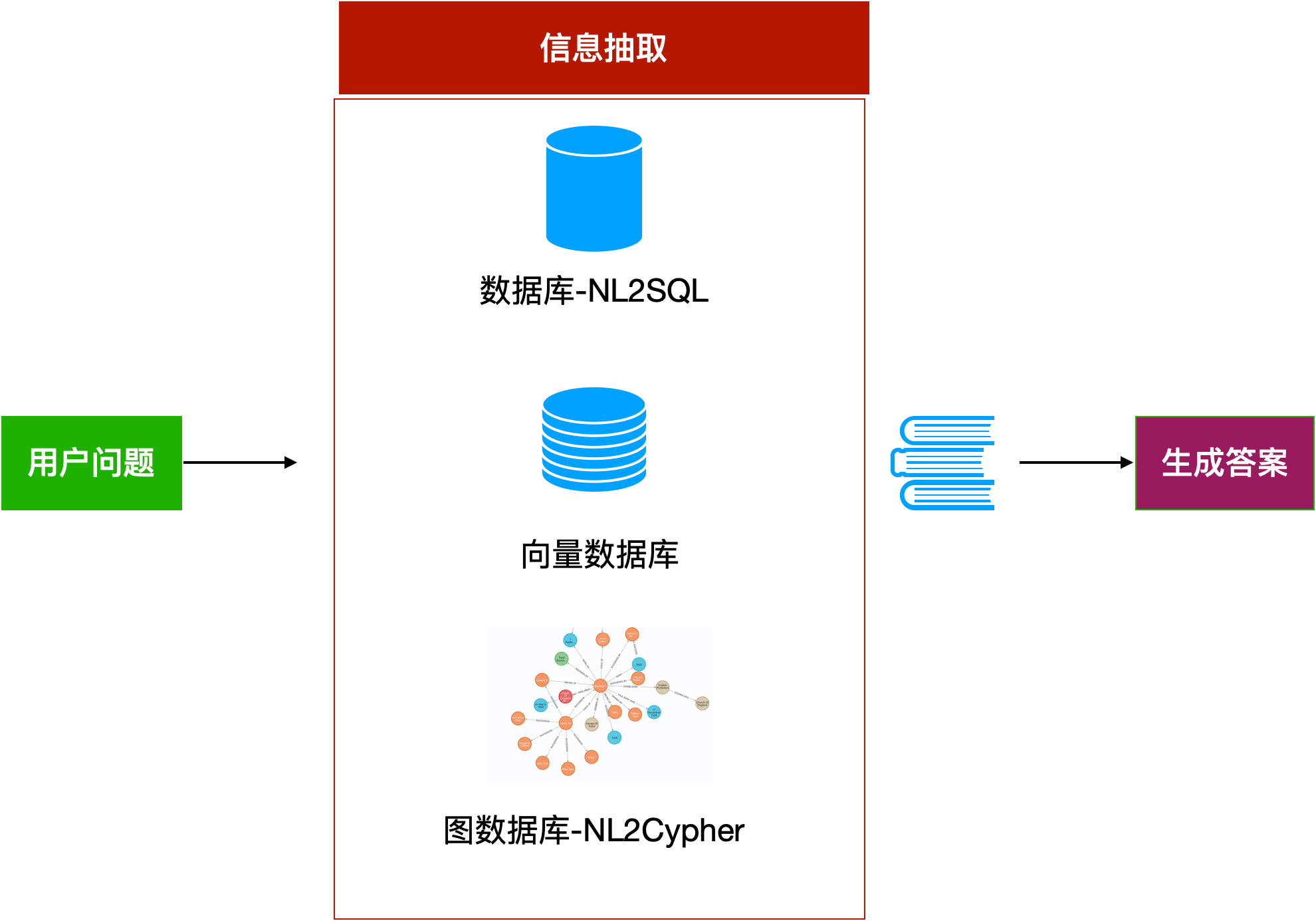
(八)从知识图谱中获取数据
Neo4j是一款图数据库引擎,可以为我们提供知识图谱构建和计算服务