游戏开发软件手机版seo推广哪家公司好
语⾔模型及词向量相关知识
- ⾃然语⾔处理简介
- ⾃然语⾔理解(NLU)
- ⾃然语⾔⽣成(NLG)
- 发展趋势
- 信息检索技术
- 布尔检索与词袋模型
- 基于相关性的检索 / TF-IDF
- 举例:
- 语⾔模型 / Language Model
- 神经⽹络语⾔模型
- Word2Vec训练⽅法
- fasttext
⾃然语⾔处理简介
⾃然语⾔(NaturalLanguage)其实就是⼈类语⾔对⽐于程序设计语⾔,⾃然语⾔处理(NLP)就是利⽤计算机对⼈类语⾔进⾏处理。
在NLP领域中,针对⾃然语⾔处理核⼼任务的分类,⼀直存在着如下两种划分:
⾃然语⾔理解(Natural Language Understanding,NLU)
⾃然语⾔⽣成(Natural Language Generation,NLG)
⾃然语⾔理解(NLU)
研究如何让计算机理解⼈类语⾔的语义、语法和语境,将⾮结构化的⽂本转化为结构化的机器可处理的信息。
- 关键技术
- 句法分析:解析句⼦的语法结构(如主谓宾关系)。
- 语义分析:提取句⼦的深层含义,例如实体识别(NER)、关系抽取、事件抽取等。
- 意图识别:理解⽤⼾的真实需求(如对话系统中判断⽤⼾是询问天⽓还是订票)。
- 情感分析:判断⽂本的情感倾向(积极、消极、中性)
- 上下⽂处理:结合对话历史或背景知识消除歧义(如 “苹果ˮ 在不同语境中指⽔果或公司)。
- 典型应用
智能客服(意图识别):解析⽤⼾问题并进⾏分类。
搜索引擎(语义分析):理解查询意图并返回相关结果。
语⾳助⼿(语义分析):将语⾳指令转化为操作(如 “打开空调ˮ)。
⾃然语⾔⽣成(NLG)
研究如何让计算机根据结构化数据或意图⽣成符合⼈类语⾔习惯的⽂本。
- 关键技术
1.模板⽣成:基于预定义模板填充内容(如⽣成 “今⽇天⽓:晴,温度 25℃ˮ)。
2.统计⽣成:利⽤统计模型(如神经⽹络)学习语⾔模式,⽣成连贯⽂本。
3.逻辑到⽂本转换:将知识图谱、数据库等结构化数据转化为⾃然语⾔(如⽣成财
务报告)。
4.⻛格控制:⽣成符合特定⻛格(正式 / ⼝语化、幽默 / 严肃)的⽂本。 - 典型应⽤:
新闻稿⾃动⽣成:根据体育赛事数据撰写报道。
个性化推荐⽂案:根据⽤⼾⾏为⽣成商品描述。
聊天机器⼈回复:结合上下⽂⽣成⾃然流畅的对话。
发展趋势
- 预训练模型的影响:如 GPT4、BERT 等⼤模型的发展,同时推动了 NLU 和 NLG ⽅向的进步,⼤模型通过 “理解 + ⽣成ˮ 能⼒实现多轮对话、⻓⽂本⽣成等功能。
- 多模态融合:结合图像、语⾳等信息提升理解与⽣成的准确性(如根据图⽚⽣成描述)。
- 低资源场景:针对⼩语种或特定领域(如法律、医疗)的 NLP 需求,开发更⾼效的模型。
通过 NLU 和 NLG 的结合,计算机正逐步实现与⼈类⾃然、流畅的交流,未来将在智能助⼿、⾃动化写作、数据分析等领域发挥更⼤作⽤。
信息检索技术
布尔检索与词袋模型
检索技术的早期阶段。涉及的⽂档资料井不多,这个时间需要解决的是有⽆问题。因此,⼯程⼈员开发出了⼀种检索模型。可⽤于处理有⽆问题。
- 假设待检⽂件是⼀个⿊箱 / ⼝袋
检索词是⼝袋中的元素 / ⼩球
各检索词之间 地位平等、顺序⽆关、独⽴分布
- 提供⼀些描述检索词之间关系的操作符 / 布尔模型
a AND b
a OR b
NOT a
直到互联⽹搜索引擎的产⽣,基于简单布尔检索的模型再也⽆法适应数据增⻓的规模了。
需要⼀种让机器可以对信息的重要性打分的机制
基于相关性的检索 / TF-IDF
1971
Gerard Salton∕杰拉德 · 索尔顿,康奈尔⼤学,The SMART Retrieval System—Experiments in Automatic Document Processing(SMART 检索系统:⾃动⽂档处理实验)⽂中⾸次提到了把查询关键字和⽂档都转换成ˮ向量ˮ,并且给这些向量中的元素赋予不同的值。
Karen Spärck Jones / 卡伦 · 琼斯,A Statistical Interpreation of Term Speificity and Its
Application in Retrieval (从统计的观点看词的特殊性表及其在⽂档检索中的应⽤),第⼀次详细阐述了Inverse Document Frequency,IDF的应⽤。之后在 lndex Term Weighting
对 Term Frequency ,TF 与 IDF 的结合进⾏了论述。
卡伦是第⼀位从理论上对TF/IDF进⾏完整论证的计算机科学家。也被认为是TF与IDF的发明⼈。
- 词频(Term Frequency)
在文档d中,频率表示给定词t的实例数量。因此,我们可以看到当一个词在文本中出现时,它变得更相关,这是合理的。由于术语的顺序不重要,我们可以使用一个向量来描述基于词袋模型的文本。对于论文中的每个特定术语,都有一个条目,其值是词频。
在文档中出现的术语的权重与该术语的词频成正比。

- 延伸:BM25 TF 计算(Bese Match25 Term Frequency)
用于测量特定文档中词项的频率,同时进行文档长度和词项饱和度的调整。

- 文档频率(Document Frequency)
这测试了文本在整个语料库集合中的意义,与TF非常相似。唯一的区别在于,在文档d中,TF是词项t的频率计数器,而df是词项t在文档集N中的出现次数。换句话说,包含该词的论文数量即为DF。 - 倒排文档频率(Inverse Document Frequency)
主要用于测试词语的相关性。搜索的主要目标是找到符合需求的适当记录。由于tf认为所有术语同等重要,因此仅使用词频来衡量论文中术语的权重并不充分。

- 计算(Computation)
TF-IDF是确定一个词对于一系列文本或语料库的重要性的最佳度量之一。TF-IDF是一个加权系统,根据词频(TF)和逆文档频率(IDF)为文档中的每个词分配权重。具有更高权重得分的词被视为更重要。

举例:
数据来源:⾖瓣读书top250图书信息与热⻔评论数据集
原始数据格式转换
#修复后内容存盘文件
fixed = open("douban_comments_fixed.txt","w",encoding="utf-8")
#修复前内容文件
lines = [line for line in open("doubanbook_top250_comments.txt","r",encoding = "utf-8")]
print(len(lines))for i,line in enumerate(lines):#保存标题列if i == 0:fixed.write(line)prev_line = ''#上一行的书名置为空continue#提取书名和评论文本terms = line.split("\t")#当前行的书名 = 上一行的书名if terms[0] == prev_line.split("\t")[0]:#保存上一行的记录fixed.write(prev_line + '\n')prev_line = line.strip()#保存当前行else:if len(terms) == 6:#新书评论prev_line = line.strip()#保存当前行#保存上一行记录else:prev_line += line.strip()break
fixed.close()
- 计算TF-IDF并通过余弦相似度给出推荐列表
这里我们引用了两个模块,CSV和jieba
Python 的标准库模块 csv 提供了处理 CSV 文件的功能,其中 DictReader 类可以将每一行数据解析为字典形式。为了指定自定义的分隔符(如制表符 \t),可以通过传递参数 delimiter=‘\t’ 来实现。 - 参数设置
当创建 csv.DictReader 对象时,通过关键字参数 delimiter 设置所需的分隔符。对于制表符分隔的数据文件,应将其设为字符串 ‘\t’.
csv.DictReader() 就像一个超级高效的数据整理员,能自动将 CSV 文件转换成易读的字典格式。 - 关键特点
自动将第一行作为键(列名)
每一行变成一个字典
方便直接通过列名访问数据
重点
TF-IDF倾向于过滤掉常见的词语,保留重要的词语。TF-IDF分数越高,表示单词在一个文档中出现频繁(TF高),但在跨多文档中出现不是很频繁(IDF高)。
图书推荐
基于上述描述图书,进行推荐
import csv
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as npdef load_data(filename):# 图书评论信息集合book_comments = {} # {书名: “评论1词 + 评论2词 + ...”}with open(filename,'r') as f:reader = csv.DictReader(f,delimiter='\t') # 识别格式文本中标题列for item in reader:book = item['book']comment = item['body']comment_words = jieba.lcut(comment)if book == '': continue # 跳过空书名# 图书评论集合收集book_comments[book] = book_comments.get(book,[])book_comments[book].extend(comment_words)return book_commentsif __name__ == '__main__':# 加载停用词列表stop_words = [line.strip() for line in open("stopwords.txt", "r", encoding="utf-8")]# 加载图书评论信息book_comments = load_data("douban_comments_fixed.txt")print(len(book_comments))# 提取书名和评论文本book_names = []book_comms = []for book, comments in book_comments.items():book_names.append(book)book_comms.append(comments)# 构建TF-IDF特征矩阵vectorizer = TfidfVectorizer(stop_words=stop_words)tfidf_matrix = vectorizer.fit_transform([' '.join(comms) for comms in book_comms])# 计算图书之间的余弦相似度similarity_matrix = cosine_similarity(tfidf_matrix)# 输入要推荐的图书名称book_list = list(book_comments.keys())print(book_list)book_name = input("请输入图书名称:")book_idx = book_names.index(book_name) # 获取图书索引# 获取与输入图书最相似的图书recommend_book_index = np.argsort(-similarity_matrix[book_idx])[1:11]# 输出推荐的图书for idx in recommend_book_index:print(f"《{book_names[idx]}》 \t 相似度:{similarity_matrix[book_idx][idx]:.4f}")print()
-
常见参数
TfidfVectorizer具有多种参数,可以根据需求进行配置:stop_words: 可以选择去除停用词,如 `stop_words='english'` 来移除英语的常见停用词。max_features: 限制词汇表的最大特征数,例如 `max_features=10` 只保留出现频率最高的 10 个词。ngram_range: 设置 n-gram 范围,如 `(1, 2)` 表示提取单词和双词特征。smooth_idf: 设置为 `True` 以平滑 IDF 值,避免分母为零的情况。sublinear_tf: 设置为 `True`,采用对数缩放而不是原始的词频。 -
应用场景
TfidfVectorizer常用于以下场景:文本分类: 将文本数据转换为结构化格式,以便输入到机器学习模型中。信息检索: 在搜索引擎中,根据用户查询和文档 TF-IDF 值进行排序。关键词提取: 通过高 TF-IDF 值的单词来提取文本中的关键词。
语⾔模型 / Language Model
我们在⽂本识别的案例中(使⽤ DenseNet CTC Loss 的中⽂印刷体识别),已经遇到了需要进⼀步改进的问题。
需要引⼊新的机制对结果再次进⾏打分。
语⾔模型就是为了解决类似这样的问题⽽提出的。简单地说,语⾔模型就是⽤来计算⼀个句
⼦的概率的模型,即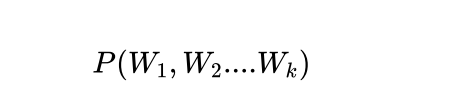
利⽤语⾔模型,可以确定哪个词序列的可能性更⼤,或者给定若⼲个词,可以预测下⼀个最
可能出现的词。
神经⽹络语⾔模型

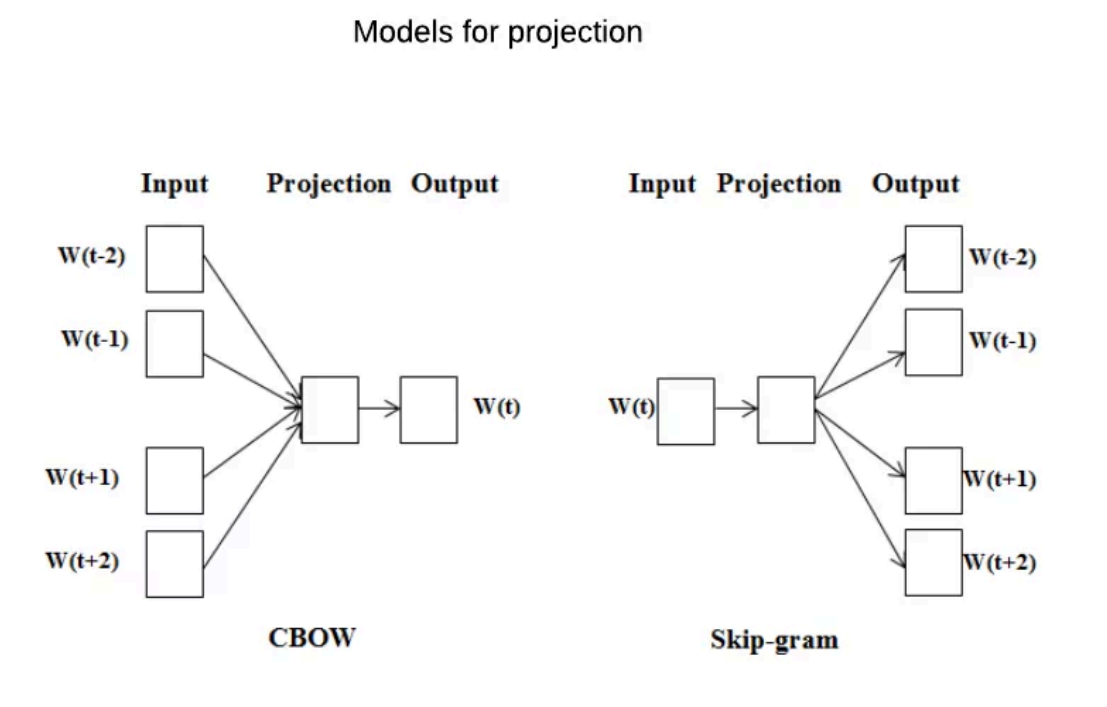
Word2Vec训练⽅法
- CBOW(通过附近词预测中⼼词)
- Skip-gram(通过中⼼词预测附近的词):


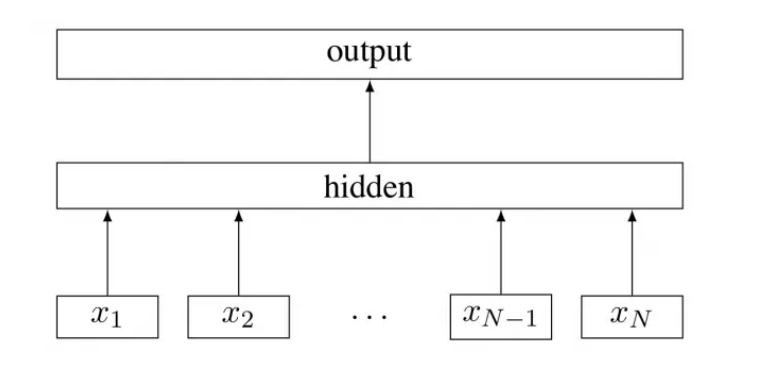
fasttext
模型的结构类似于CBOW(连续词袋模型)。模型由输⼊层,隐藏层,输出层组成,输出层的结果是⼀个特定的⽬标。
这两个任务的是同时完成的,更具体点描述就是:在训练⽂本分类模型的同时,也训练了对
应的词向量。⽽且FastText的训练速度⽐word2vec更快。
