专业网站建设市场北京网站优化实战
Scrapy 中队列设计详解
1. 概述
Scrapy 的队列系统是其调度器(Scheduler)的核心组件之一,负责存储和管理待抓取的请求。Scrapy 实现了两种类型的队列:
- 内存队列:请求存储在内存中,重启后数据丢失
- 磁盘队列:请求序列化到磁盘,支持持久化存储
文件路径:/scrapy/squeues.py
设计模式:装饰器模式与Python中的装饰器
2. 队列的基本架构
2.1 队列类型
Scrapy 在 squeues.py 中定义了以下几种队列:
-
磁盘队列(使用 pickle 序列化):
PickleFifoDiskQueue: 先进先出磁盘队列PickleLifoDiskQueue: 后进先出磁盘队列(默认的磁盘队列类)
-
磁盘队列(使用 marshal 序列化):
MarshalFifoDiskQueue: 先进先出磁盘队列MarshalLifoDiskQueue: 后进先出磁盘队列
-
内存队列:
FifoMemoryQueue: 先进先出内存队列LifoMemoryQueue: 后进先出内存队列(默认的内存队列类)
2.2 核心设计模式
Scrapy 的队列设计采用了装饰器模式,主要包含以下几个层次:
- 基础队列装饰:
def _with_mkdir(queue_class):class DirectoriesCreated(queue_class):def __init__(self, path, *args, **kwargs):dirname = Path(path).parentif not dirname.exists():dirname.mkdir(parents=True, exist_ok=True)super().__init__(path, *args, **kwargs)return DirectoriesCreated
- 序列化装饰:
def _serializable_queue(queue_class, serialize, deserialize):class SerializableQueue(queue_class):def push(self, obj):s = serialize(obj)super().push(s)def pop(self):s = super().pop()if s:return deserialize(s)return Nonedef peek(self):try:s = super().peek()except AttributeError as ex:raise NotImplementedError("The underlying queue class does not implement 'peek'") from exif s:return deserialize(s)return Nonereturn SerializableQueue
3. 序列化实现
3.1 Pickle 序列化队列
Scrapy 使用 pickle 作为默认的序列化方案,实现如下:
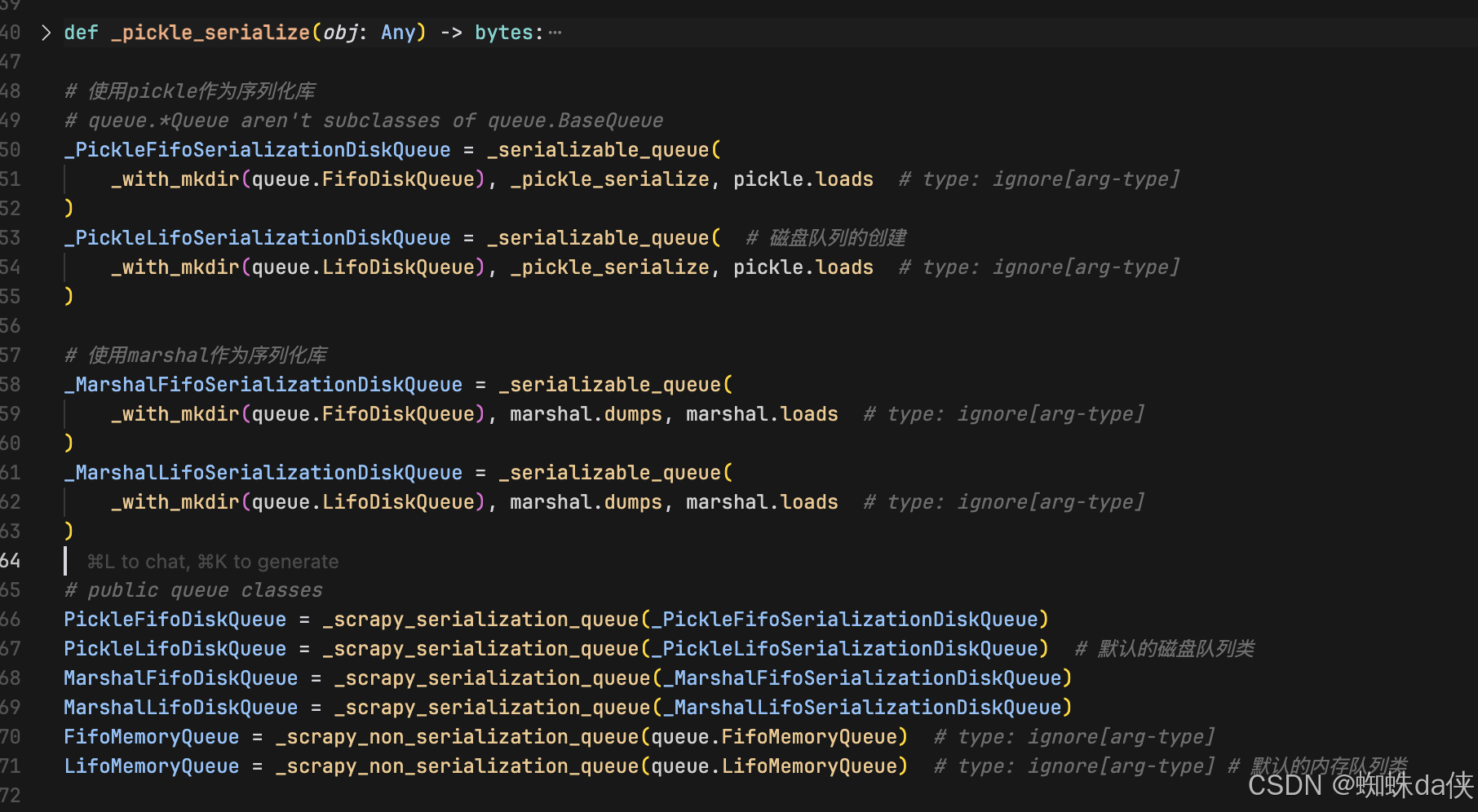
def _pickle_serialize(obj):try:return pickle.dumps(obj, protocol=4)except (pickle.PicklingError, AttributeError, TypeError) as e:raise ValueError(str(e)) from e# 创建 pickle 序列化的磁盘队列
_PickleFifoSerializationDiskQueue = _serializable_queue(_with_mkdir(queue.FifoDiskQueue), _pickle_serialize, pickle.loads
)_PickleLifoSerializationDiskQueue = _serializable_queue(_with_mkdir(queue.LifoDiskQueue), _pickle_serialize, pickle.loads
)
3.2 Marshal 序列化队列
Marshal 作为备选的序列化方案,实现如下:
# 创建 marshal 序列化的磁盘队列
_MarshalFifoSerializationDiskQueue = _serializable_queue(_with_mkdir(queue.FifoDiskQueue), marshal.dumps, marshal.loads
)_MarshalLifoSerializationDiskQueue = _serializable_queue(_with_mkdir(queue.LifoDiskQueue), marshal.dumps, marshal.loads
)
4. 序列化方案对比
4.1 Pickle vs Marshal 在 Scrapy 中的应用
-
Pickle 的优势:
- 支持更多的 Python 数据类型
- 可以序列化自定义类和对象
- 支持对象引用和循环引用
- 版本兼容性更好
-
Marshal 的优势:
- 序列化速度更快
- 内存占用更少
- 实现更简单,安全性较高
4.2 为什么提供两种序列化方案?
-
性能考虑:
- Marshal 序列化速度快,适合简单数据结构
- Pickle 功能更强大,适合复杂对象
-
兼容性考虑:
- Pickle 支持自定义类的序列化
- Marshal 只支持基本数据类型
-
安全性考虑:
- Marshal 更安全,不支持代码执行
- Pickle 需要注意安全风险
5. 队列的实际应用
5.1 在调度器中的使用
# 在 settings.py 中配置队列类型
SCHEDULER_DISK_QUEUE = "scrapy.squeues.PickleLifoDiskQueue"
SCHEDULER_MEMORY_QUEUE = "scrapy.squeues.LifoMemoryQueue"
5.2 队列选择策略
- 请求入队逻辑:
def enqueue_request(self, request):if not request.dont_filter and self.df.request_seen(request):return Falsedqok = self._dqpush(request) # 优先尝试放入磁盘队列if dqok:self.stats.inc_value("scheduler/enqueued/disk")else:self._mqpush(request) # 磁盘队列失败则放入内存队列self.stats.inc_value("scheduler/enqueued/memory")return True
- 请求出队逻辑:
def next_request(self):request = self.mqs.pop() # 优先从内存队列获取if request:self.stats.inc_value("scheduler/dequeued/memory")else:request = self._dqpop() # 内存队列为空则从磁盘队列获取if request:self.stats.inc_value("scheduler/dequeued/disk")return request
6. 最佳实践
-
队列类型选择:
- 小规模爬虫:使用内存队列即可
- 大规模爬虫:使用磁盘队列保证可靠性
- 需要暂停恢复:必须使用磁盘队列
-
序列化方案选择:
- 简单请求:可以使用 Marshal 序列化
- 复杂请求:建议使用 Pickle 序列化
- 注重性能:选择 Marshal
- 注重功能:选择 Pickle
-
性能优化:
- 合理设置并发数
- 适当调整队列类型
- 根据数据复杂度选择序列化方案
7. 注意事项
-
安全性:
- 使用 Pickle 时注意反序列化安全
- 不要处理不信任来源的序列化数据
-
性能:
- 磁盘队列会带来 I/O 开销
- 序列化/反序列化会消耗 CPU
-
可靠性:
- 定期备份磁盘队列数据
- 处理序列化异常
- 考虑磁盘空间限制