做网站公司需要多少钱怎么找当地的地推团队
DAY 34 GPU训练及类的call方法
知识点回归:
CPU性能的查看:看架构代际、核心数、线程数
GPU性能的查看:看显存、看级别、看架构代际
GPU训练的方法:数据和模型移动到GPU device上
类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
作业
复习今天的内容,在巩固下代码。思考下为什么会出现这个问题。
# ------------------- 数据准备部分 -------------------
# 导入需要的库:sklearn用于数据处理,torch用于深度学习,matplotlib用于可视化
from sklearn.datasets import load_iris # 加载经典鸢尾花数据集
from sklearn.model_selection import train_test_split # 划分训练集和测试集
from sklearn.preprocessing import MinMaxScaler # 数据归一化工具
import torch # PyTorch深度学习框架
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
import matplotlib.pyplot as plt # 可视化库
import time # 用于计算训练时长# 加载鸢尾花数据集(4特征,3分类)
iris = load_iris()
X = iris.data # 特征数据(形状:[150, 4],150个样本,4个特征)
y = iris.target # 标签数据(形状:[150],0-2代表3种鸢尾花)# 划分训练集和测试集(80%训练,20%测试,random_state固定随机种子保证结果可复现)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 数据归一化(将特征值缩放到[0,1]区间,避免神经网络因输入尺度差异训练不稳定)
scaler = MinMaxScaler() # 创建归一化工具
X_train = scaler.fit_transform(X_train) # 用训练集拟合归一化参数并转换
X_test = scaler.transform(X_test) # 用训练集的参数转换测试集(保证数据分布一致)# 将数据转换为PyTorch张量(PyTorch模型只能处理张量数据)
# 特征数据用FloatTensor(32位浮点数),标签用LongTensor(64位整数,用于分类任务)
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)# ------------------- GPU设备配置 -------------------
# 检查是否有可用的GPU:若有则使用GPU加速,否则使用CPU(PyTorch会自动处理设备间数据迁移)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"当前使用的设备:{device}") # 打印当前设备,确认是否启用GPU# ------------------- 模型定义(全连接神经网络) -------------------
# 定义一个多层感知机(MLP)模型,继承自nn.Module(PyTorch所有模型的基类)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__() # 调用父类构造函数(必须)# 定义网络层:输入层→隐藏层→输出层self.fc1 = nn.Linear(4, 10) # 输入层(4特征)→隐藏层(10神经元):线性变换self.relu = nn.ReLU() # 激活函数(引入非线性,增强模型表达能力)self.fc2 = nn.Linear(10, 3) # 隐藏层(10神经元)→输出层(3类别):线性变换def forward(self, x):# 前向传播逻辑(模型如何从输入计算输出)x = self.fc1(x) # 输入层到隐藏层:4维特征→10维隐藏状态x = self.relu(x) # 激活函数:过滤负激活值,保留有用特征x = self.fc2(x) # 隐藏层到输出层:10维隐藏状态→3维输出(未归一化的分类分数)return x# ------------------- 模型与数据移动到GPU -------------------
# 将模型和数据迁移到GPU(若可用),GPU的并行计算能大幅加速训练
model = MLP().to(device) # 模型迁移到GPU/CPU(自动判断)
X_train = X_train.to(device) # 训练特征数据迁移到GPU
y_train = y_train.to(device) # 训练标签迁移到GPU
X_test = X_test.to(device) # 测试特征数据迁移到GPU
y_test = y_test.to(device) # 测试标签迁移到GPU# ------------------- 训练配置 -------------------
criterion = nn.CrossEntropyLoss() # 损失函数:交叉熵(适合多分类任务)
optimizer = optim.SGD(model.parameters(), lr=0.01) # 优化器:随机梯度下降(学习率0.01)
num_epochs = 20000 # 训练轮数(完整遍历训练集的次数)
losses = [] # 记录每轮训练的损失值(用于后续可视化)# ------------------- 训练循环 -------------------
# 记录训练开始时间(用于计算总时长)
start_time = time.time()for epoch in range(num_epochs):# 前向传播:模型根据输入数据计算预测值outputs = model(X_train) # 隐式调用__call__方法,等价于model.forward(X_train)# 计算损失:预测值与真实标签的差异(越小说明模型越好)loss = criterion(outputs, y_train)# 反向传播与参数更新optimizer.zero_grad() # 清空历史梯度(避免梯度累加)loss.backward() # 反向传播计算梯度(自动求导)optimizer.step() # 根据梯度更新模型参数(优化器核心操作)# 记录损失值(转换为Python标量,避免内存占用)losses.append(loss.item())# 每1000轮打印一次训练进度(方便观察训练是否收敛)if (epoch + 1) % 1000 == 0:print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}")# 计算训练总时长
end_time = time.time()
train_duration = end_time - start_time
print(f"\n训练完成!总训练时长:{train_duration:.2f} 秒")# ------------------- 可视化训练损失 -------------------
plt.figure(figsize=(10, 6)) # 设置画布大小
plt.plot(range(num_epochs), losses) # 绘制损失曲线(x轴:轮数,y轴:损失值)
plt.xlabel("Epoch") # x轴标签:训练轮数
plt.ylabel("Loss") # y轴标签:损失值
plt.title(f"Training Loss on {device}") # 图表标题:显示训练设备
plt.grid(True) # 显示网格线(方便观察趋势)
plt.show() # 显示图表# 在PyTorch中,所有自定义的模型(如 MLP 类)都继承自 nn.Module 。
# nn.Module 类内部实现了 __call__ 方法,其核心逻辑如下:
class Module:def __call__(self, *args, **kwargs):# 执行前向传播前的钩子(Hook)result = self.forward(*args, **kwargs) # 调用用户定义的forward方法# 执行前向传播后的钩子(Hook)return result
# 因此,当我们调用 model(X_train) 时,实际上触发了 __call__ 方法,
# 而 __call__ 方法内部会调用用户定义的 forward 方法。直接使用 model(x) 比显式调用 model.forward(x) 更推荐,
# 因为它会自动处理钩子(如梯度监控、中间变量记录等)。
# 总结
# - GPU训练的核心是将模型和数据移动到 device (通过 .to(device) 方法)。
# - nn.Module 的 __call__ 方法隐式调用 forward ,是PyTorch设计的关键机制,简化了代码编写。
# - 实际训练中,GPU能显著加速计算(尤其是大模型或大数据集),但需确保显卡显存足够(避免OOM错误)。'''
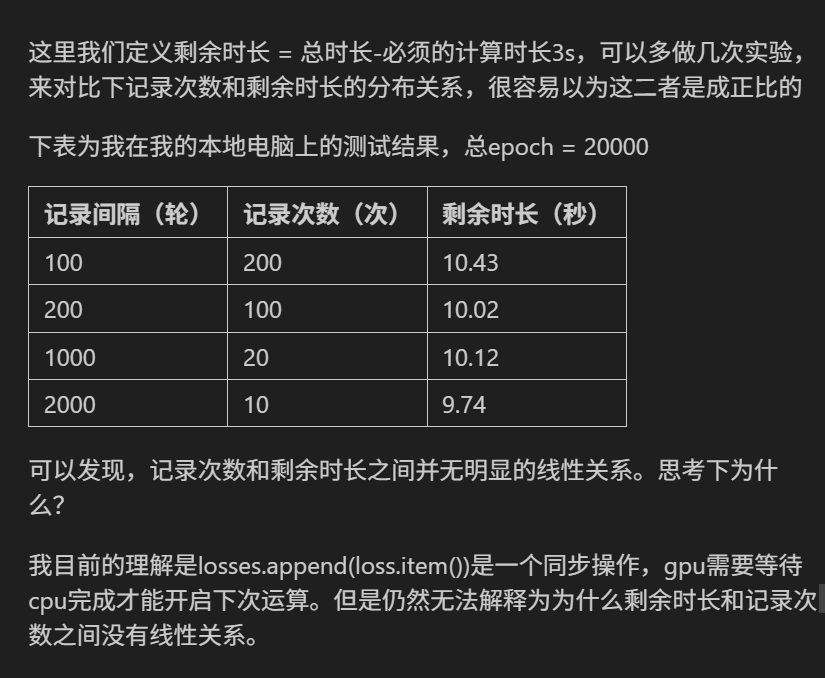
记录次数与剩余时长无明显线性关系的主要原因可从以下几个角度分析:
### 1. 核心计算耗时占比主导
训练总时长的核心瓶颈是GPU上的 前向传播、反向传播、参数更新 等计算操作(由 model(X_train) 、 loss.backward() 、
optimizer.step() 主导)。这些操作依赖GPU并行计算,速度远快于CPU的辅助操作(如 losses.append() 或 print )。
即使记录次数增加(如从10次到200次),CPU辅助操作的总耗时在整体训练时长中的占比极低(可能不足1%),
因此对剩余时长(总时长-3秒)的影响不显著。
### 2. GPU与CPU的异步性
PyTorch中,GPU计算(如模型推理、梯度计算)与CPU操作(如 loss.item() 将GPU张量转为CPU标量、 append 到列表)是
异步执行 的。当GPU完成一个epoch的计算后,CPU会快速处理记录操作(几微秒到几毫秒),
而GPU可能已开始下一个epoch的计算。这种异步机制使得CPU辅助操作不会阻塞GPU的核心计算,
因此记录次数的增加不会线性延长总时长。
### 3. Python列表操作的高效性
losses.append(loss.item()) 是Python列表的 O(1)时间复杂度操作 (均摊时间),
即使记录200次,总耗时也仅为几十毫秒(远小于单个epoch的GPU计算时间)。
而 print 语句的IO操作虽然可能有波动(如终端输出延迟),但在20000轮训练中,
这种波动会被平均化,导致剩余时长的变化不规律。
### 4. 简单模型的计算量过小
鸢尾花数据集(150样本、4特征)和MLP模型(仅2层全连接)的计算量极小,单个epoch的GPU计算时间可能仅需 几微秒到几十微秒 。
此时,记录操作的耗时(如 print 的IO延迟)可能与核心计算时间处于同一数量级,
导致剩余时长的波动(如10.43秒→9.74秒)更多由环境噪声(如系统进程调度、GPU温度)引起,而非记录次数本身。
### 结论
记录次数的增加带来的额外耗时(CPU辅助操作)在总训练时长中占比极低,
且受GPU异步计算和简单模型的影响,剩余时长与记录次数无显著线性关系。
这一现象符合“核心计算主导总时长”的规律,辅助操作的影响可忽略。
'''当前使用的设备:cpu
Epoch [1000/20000], Loss: 0.6529
Epoch [2000/20000], Loss: 0.3957
Epoch [3000/20000], Loss: 0.2886
Epoch [4000/20000], Loss: 0.2177
Epoch [5000/20000], Loss: 0.1712
Epoch [6000/20000], Loss: 0.1408
Epoch [7000/20000], Loss: 0.1204
Epoch [8000/20000], Loss: 0.1063
Epoch [9000/20000], Loss: 0.0961
Epoch [10000/20000], Loss: 0.0885
Epoch [11000/20000], Loss: 0.0827
Epoch [12000/20000], Loss: 0.0782
Epoch [13000/20000], Loss: 0.0746
Epoch [14000/20000], Loss: 0.0717
Epoch [15000/20000], Loss: 0.0693
Epoch [16000/20000], Loss: 0.0672
Epoch [17000/20000], Loss: 0.0655
Epoch [18000/20000], Loss: 0.0640
Epoch [19000/20000], Loss: 0.0627
Epoch [20000/20000], Loss: 0.0615训练完成!总训练时长:10.48 秒