基于PHP网站开发的管理系统设计与开发百度收录比较好的网站
目录
准备工作
编写爬虫代码
运行爬虫
查看结果
遇到的问题及解决
总结
前言和效果
本文记录了使用 Python 实现一个简单网页爬虫的过程,目标是爬取 quotes.toscrape.com 的名言和作者,并将结果保存到文本文件。以下是完整步骤,包含环境配置、依赖安装和代码运行。
网站截图:
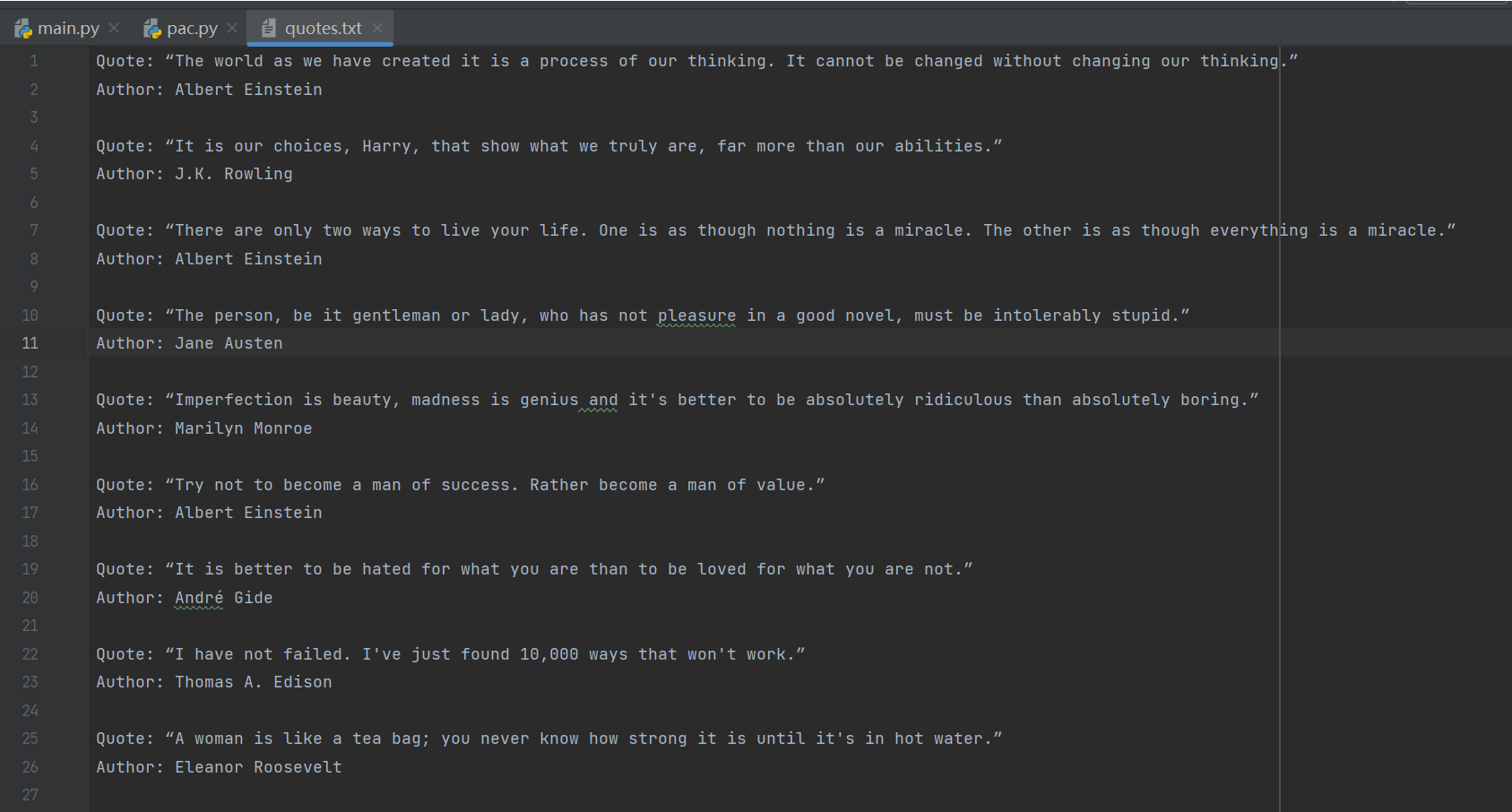
爬取到的内容截图如下:
准备工作
-
激活 Anaconda 虚拟环境
我的 Python 环境基于 Anaconda,使用的虚拟环境是SRCNN(路径:D:\Anaconda\envs\SRCNN)。首先,需要激活该环境:
conda activate SRCNN
运行后,命令行前缀变为 (SRCNN),表示成功切换到虚拟环境。
-
安装依赖包
爬虫需要两个库:requests(发送 HTTP 请求)和beautifulsoup4(解析 HTML)。在SRCNN环境中安装:
conda install requests beautifulsoup4
安装报错了,原因是未关闭科学上网,后关闭了这两个包就装好了。报错如下: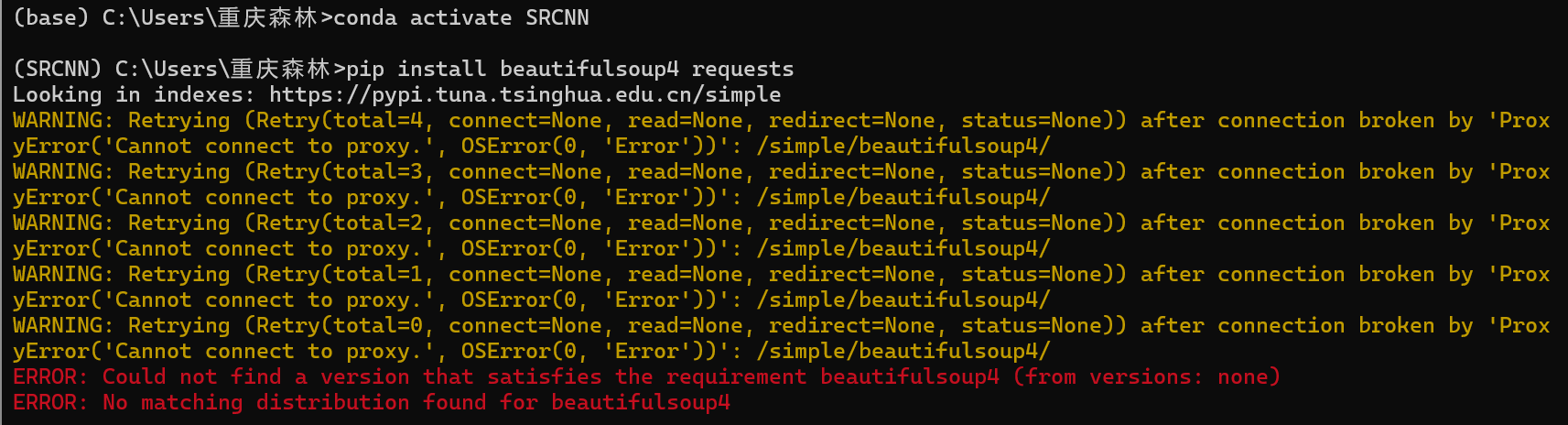
关闭科学上网后重新安装
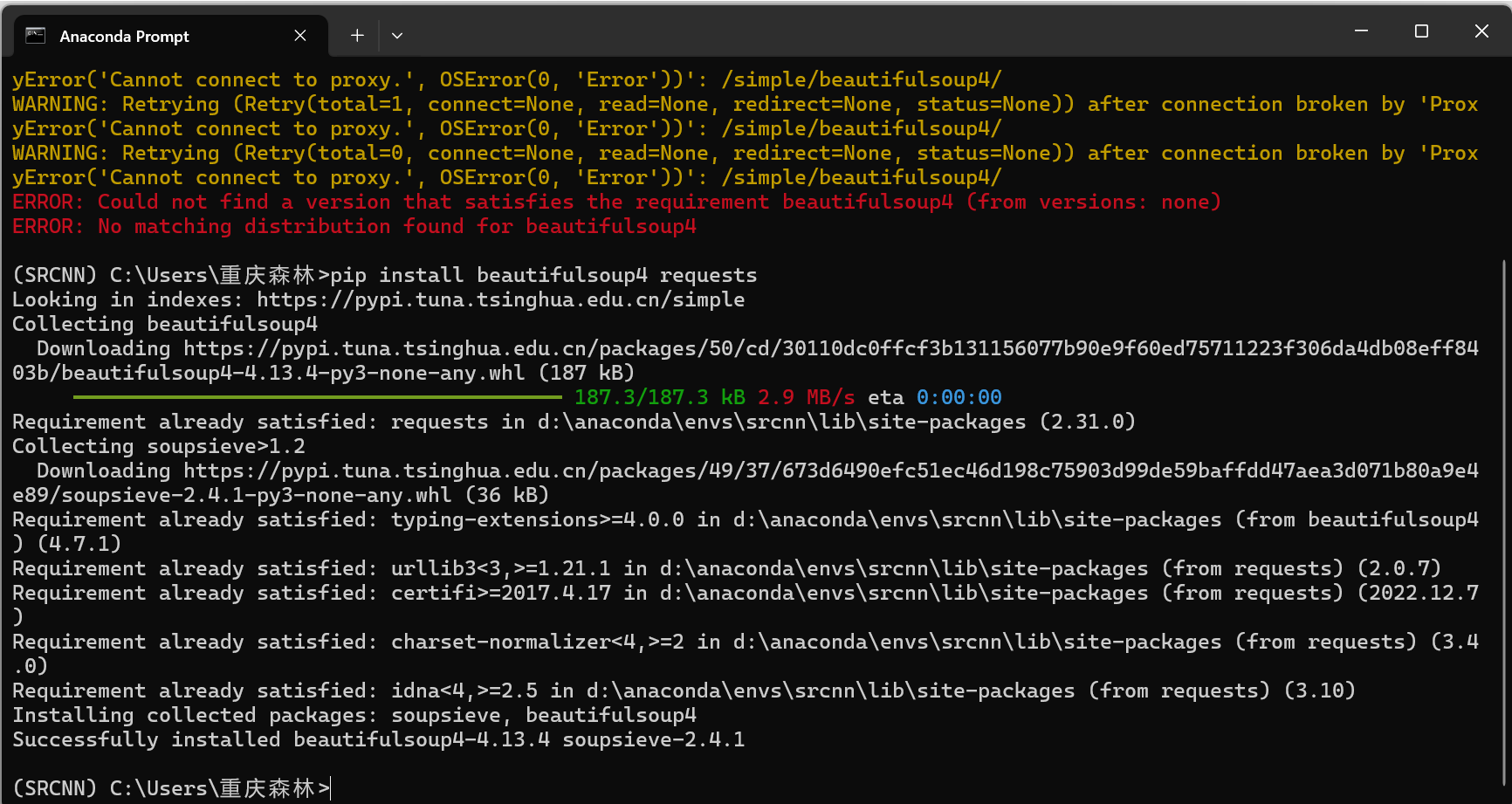
安装完成后,命令行显示安装成功的提示。
-
验证安装
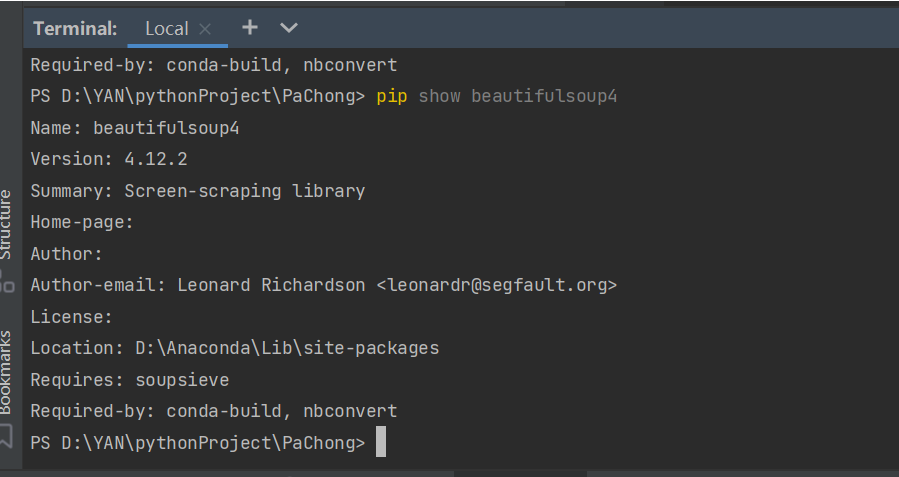
为确保beautifulsoup4正确安装在SRCNN环境中,运行以下命令检查:
pip show beautifulsoup4
输出显示模块版本为 4.12.2,安装路径为 D:\Anaconda\envs\SRCNN\Lib\site-packages,确认安装正确。
编写爬虫代码,完整代码:
以下是爬虫代码(pac.py),用于爬取 quotes.toscrape.com 的名言和作者,并保存到 quotes.txt:
import requests
from bs4 import BeautifulSoup# 目标网页
url = "http://quotes.toscrape.com/"try:# 发送 HTTP 请求response = requests.get(url)response.raise_for_status() # 检查请求是否成功# 解析 HTMLsoup = BeautifulSoup(response.text, "html.parser")# 提取名言和作者quotes = soup.find_all("div", class_="quote")results = []for quote in quotes:text = quote.find("span", class_="text").get_text()author = quote.find("small", class_="author").get_text()results.append({"quote": text, "author": author})# 保存到文件with open("quotes.txt", "w", encoding="utf-8") as f:for item in results:f.write(f"Quote: {item['quote']}\nAuthor: {item['author']}\n\n")print("爬取完成,结果已保存到 quotes.txt")except requests.RequestException as e:print(f"请求错误: {e}")
except Exception as e:print(f"发生错误: {e}")
代码说明:
-
使用
requests.get获取网页内容。 -
用
BeautifulSoup解析 HTML,提取class="quote"的<div>元素。 -
提取每条名言(
class="text")和作者(class="author"),保存到quotes.txt。
目标网站:
Quotes to Scrape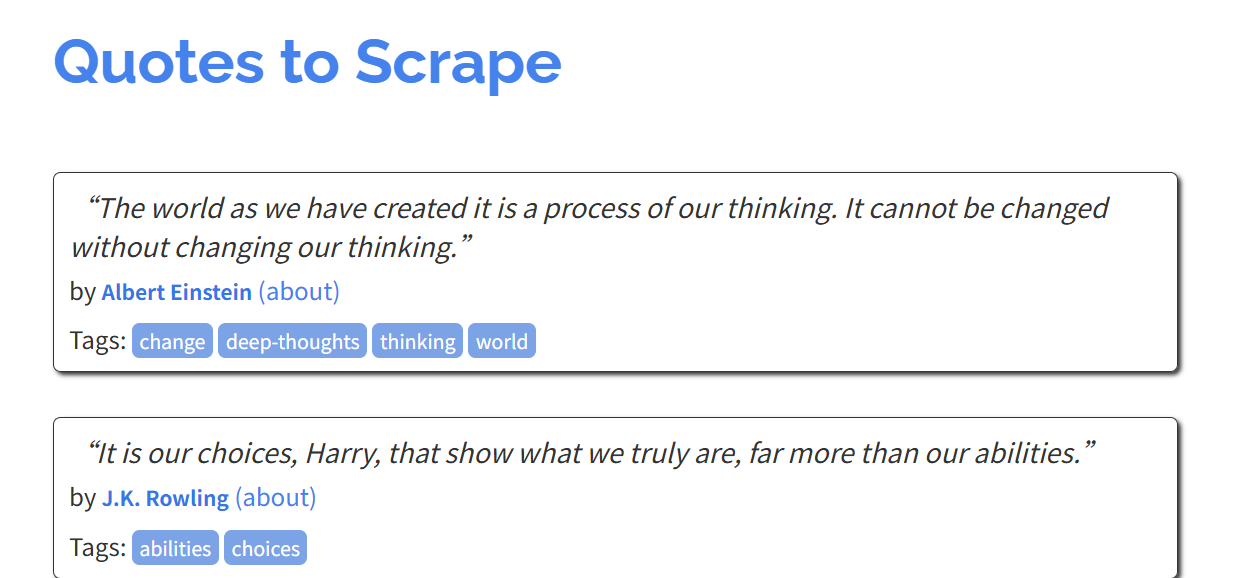
运行爬虫
在 SRCNN 环境中运行代码:
D:\Anaconda\envs\SRCNN\python.exe D:/YAN/pythonProject/PaChong/pac.py
运行后,程序输出“爬取完成,结果已保存到 quotes.txt”,表示成功。
查看结果
爬取结果保存在 D:/YAN/pythonProject/PaChong/quotes.txt,内容为每条名言及其作者。
遇到的问题及解决
最初运行时,提示 ModuleNotFoundError: No module named 'bs4',因为 beautifulsoup4 安装在 Anaconda 全局环境(D:\Anaconda\Lib\site-packages)而非 SRCNN 环境。解决方法是激活 SRCNN 环境并重新安装:
conda activate SRCNN
conda install beautifulsoup4
此外,确认 requests 已安装,避免类似错误。
总结
通过以上步骤,我成功实现了一个简单的 Python 爬虫:
-
激活
SRCNN虚拟环境。 -
安装
requests和beautifulsoup4。 -
编写并运行爬虫代码,爬取名言并保存到文本文件。
这个过程熟悉了 Anaconda 虚拟环境管理和爬虫开发,适合初学者参考。未来可扩展功能,如处理多页爬取或应对反爬机制。