灵璧做网站百度一下官网入口
基于CSDN第一篇文章,Python爬虫之入门保姆级教程,学不会我去你家刷厕所。
这篇文章是2021年作者发表的,由于此教程,网站添加了反爬机制,有作者通过添加cookie信息来达到原来的效果,Python爬虫添加Cookies以绕过反爬【仅供学习使用】
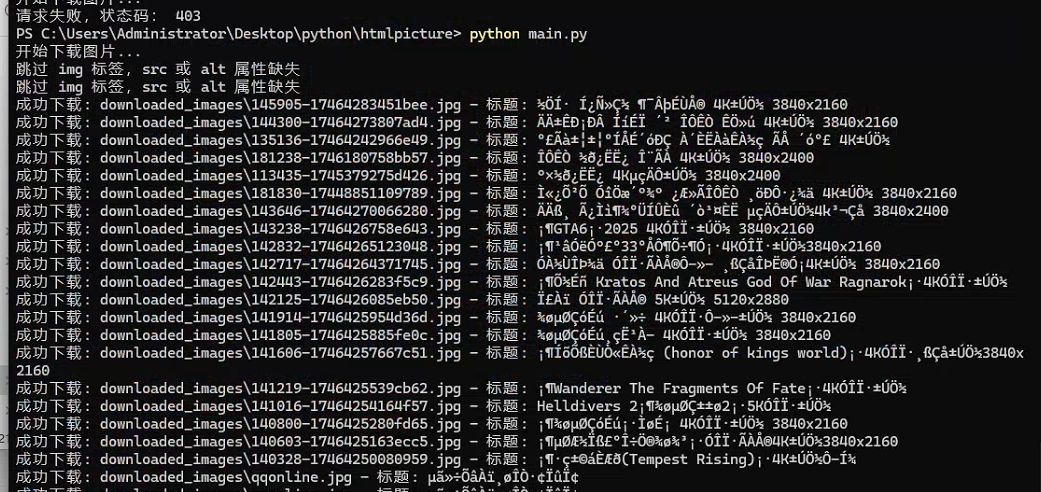
感谢两位前辈的教程,根据此教程访问时,会出现403的返回错误,证明访问被拒绝了。
此时需要多按几次ctrl+r刷新页面,拿到最新的cookie,因为网站毕竟只能做一次真人验证,拿到最新cookie复制到代码的cookie信息即可,这个上面的作者有说,但替换过后还是会出现403,那是因为请求头也要跟着换。

前三个属性,通过f12的页面找到对应属性,进行替换即可正常下载。
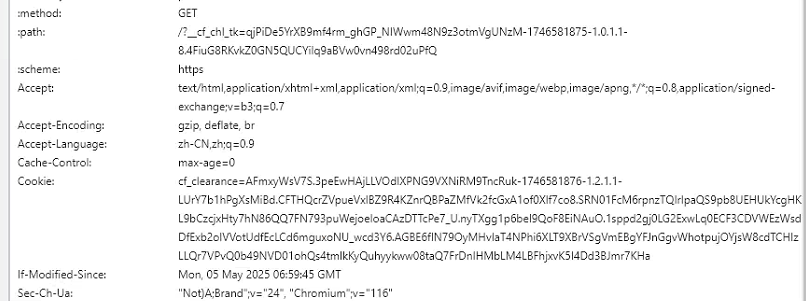
整体代码如下:
import requests
from bs4 import BeautifulSoup
import osprint('开始下载图片...')
# 使用你获取的 cookies
cookies = {'cf_clearance': 'AFmxyWsV7S.3peEwHAjLLVOdlXPNG9VXNiRM9TncRuk-1746581876-1.2.1.1-LUrY7b1hPgXsMiBd.CFTHQcrZVpueVxlBZ9R4KZnrQBPaZMfVk2fcGxA1of0Xlf7co8.SRN01FcM6rpnzTQIrlpaQS9pb8UEHUkYcgHKL9bCzcjxHty7hN86QQ7FN793puWejoeIoaCAzDTTcPe7_U.nyTXgg1p6beI9QoF8EiNAuO.1sppd2gj0LG2ExwLq0ECF3CDVWEzWsdDfExb2olVVotUdfEcLCd6mguxoNU_wcd3Y6.AGBE6fIN79OyMHvIaT4NPhi6XLT9XBrVSgVmEBgYFJnGgvWhotpujOYjsW8cdTCHIzLLQr7VPvQ0b49NVD01ohQs4tmlkKyQuhyykww08taQ7FrDnIHMbLM4LBFhjxvK5I4Dd3BJmr7KHa'# 更多 cookie...
}# 设置请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.5845.97 Safari/537.36 Core/1.116.489.400 QQBrowser/13.7.6351.400','Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','Accept-Language': 'zh-CN,zh;q=0.9','Connection': 'keep-alive','Upgrade-Insecure-Requests': '1'
}# 发送请求
base_url = 'https://pic.netbian.com/'
response = requests.get(base_url, headers=headers, cookies=cookies)# 检查响应
if response.status_code == 200:# 解析网页soup = BeautifulSoup(response.text, 'html.parser')images = soup.find_all('img') # 寻找所有 img 标签os.makedirs('downloaded_images', exist_ok=True)for img in images:# 检查 img 标签中是否包含 src 和 alt 属性image_path = img.get('src')title = img.get('alt')# 如果 img 标签没有 src,就跳过if image_path and title:full_url = base_url + image_pathtry:response = requests.get(full_url, headers=headers, cookies=cookies)response.raise_for_status() # 检查请求是否成功# 获取文件名并保存图片file_name = os.path.join('downloaded_images', os.path.basename(image_path))with open(file_name, 'wb') as file:file.write(response.content)print(f'成功下载: {file_name} - 标题: {title}')except requests.exceptions.RequestException as e:print(f'下载失败: {full_url} - 错误: {e}')else:print(f'跳过 img 标签,src 或 alt 属性缺失')
else:print("请求失败,状态码:", response.status_code)