旅游网站建设前期分析长沙关键词优化方法
说明
当前大模型与外部打交道的方式有两种,一种是 Prompt,一种是 Fuction Call。在 Prompt 方面,应用系统可以通过 Prompt 模版和补充上下文的方式,调整用户输入的提示语,使得大模型生成的回答更加准确。
RAG
RAG (Retrieval-Augmented Generation 检索增强生成)是一种结合了信息检索和大模型生成的技术框架,是通过相似度等算法从外部知识库中检索相关的信息,并将其作为 Prompt 输入大模型,以增强大模型处理知识密集型任务的能力。
系统是传统 RAG 和 智能体 RAG 的一个架构图(图片来源网络)。
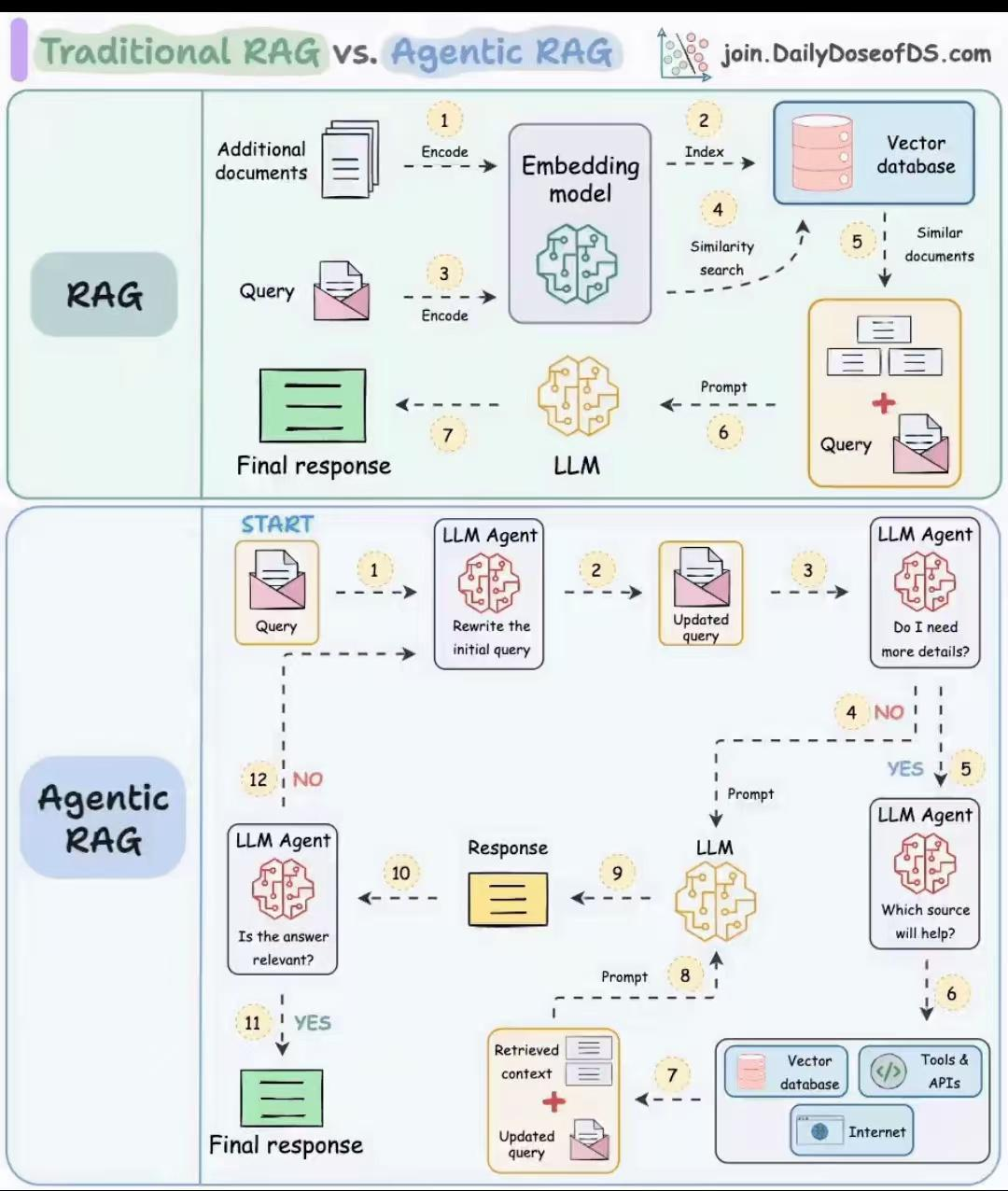
知识库
FastGPT 的《知识库基础原理的介绍》说明挺好的,https://doc.fastgpt.cn/docs/guide/knowledge_base/rag/ 。
相对于大模型,我们的系统称为应用。对于应用来说,主要做的是检索工作,就是从知识库(提供文档索检服务的对象)中找到相应的知识(文档)。
为了存储和读取文档,需要用到文档加载器和文档分割器。
- 文档加载器,比如,纯文本,PDF,Word, Markdown, html, excel 等格式的处理与加载。
- 文档分割器,当文档太大时,可以按文档的字数,段落,章节,主题等来分块。因此也就有了 JSON 格式拆分,正则表达式拆分,大小分割,拆分流水线等等。
为了查询相关文档,就需要检索算法的加持。主要分为向量检索和传统检索。在实际的应用是可以多种方式结合的,只要能检索到尽可能相关的数据即可。
- 向量检索:如 BERT向量等,它通过将文档和查询转化为向量空间中的表示,并使用相似度计算来进行匹配。向量检索的优势在于能够更好地捕捉语义相似性,而不仅仅是依赖于词汇匹配。
- 传统检索:如BM25,主要基于词频和逆文档频率(TF-IDF)的加权搜索模型来对文档进行排序和检索。BM25适用于处理较为简单的匹配任务,尤其是当查询和文档中的关键词有直接匹配时。
示例
这里我们继续使用 demo-ai02 中诊断的例子,尝试模拟一次简单的诊断,相对于demo-ai02,增加了获取病人的历史病人和病人自述相关的知识,用于演示知识库增加的例子。注意这里只是示例,并非真正的诊断流程。
依赖
build.gradle
dependencies {implementation platform(project(":demo-parent"))implementation("org.noear:solon-web")implementation("org.noear:solon-view-enjoy")implementation("org.noear:solon-ai")implementation("org.noear:solon-ai-repo-redis")implementation("org.noear:solon-logging-logback")implementation("org.noear:solon-openapi2-knife4j")implementation("org.noear:solon-web-rx")implementation("org.noear:solon-web-sse")implementation("org.noear:solon-flow")implementation("org.dromara.hutool:hutool-all")testImplementation("org.noear:solon-test")
}
Redis
这里需要用的redis的向量查询,需要安装 redis-stack 版本。
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/redis/redis-stack:latest
模型
这里需要向量化,需要增加嵌入模型,这些选了nomic-embed-text,自己根据实际情况选项,deepseek-r1:32b,也是一样的,根据需要调整。
ollama run deepseek-r1:32b
ollama run qwen2.5:7b
ollama run nomic-embed-text
配置
app.yml
增加嵌入模型和 reids 知识库的配置,其他的模型配置在流程编排中获取。
solon.flow:- "classpath:flow/*"demo.llm:embed:apiUrl: "http://127.0.0.1:11434/api/embed" # 使用完整地址(而不是 api_base)provider: "ollama" # 使用 ollama 服务时,需要配置 providermodel: "nomic-embed-text"repo:redis:server: "127.0.0.1:16379" # 改为你的 Redis 地址db: 0maxTotal: 200
LlmConfig
package com.example.demo.ai.llm.config;import org.noear.redisx.RedisClient;
import org.noear.solon.ai.embedding.EmbeddingConfig;
import org.noear.solon.ai.embedding.EmbeddingModel;
import org.noear.solon.ai.rag.repository.RedisRepository;
import org.noear.solon.annotation.Bean;
import org.noear.solon.annotation.Configuration;
import org.noear.solon.annotation.Inject;/*** @author airhead*/
@Configuration
public class LlmConfig {@Beanpublic EmbeddingModel embeddingModel(@Inject("${demo.llm.embed}") EmbeddingConfig config) {return EmbeddingModel.of(config).build();}@Beanpublic RedisRepository repository(EmbeddingModel embeddingModel, @Inject("${solon.llm.repo.redis}") RedisClient client) {return new RedisRepository(embeddingModel, client.openSession().jedis());}
}
流程
id: "ai-flow-01"
layout:- id: "开始"type: "start"- id: "病史"type: "execute"task: "@searchTask"- id: "诊断"type: "execute"meta.model: "deepseek-r1:32b"meta.apiUrl: "http://127.0.0.1:11434/api/chat"meta.provider: "ollama"meta.input: "prompt"meta.output: "intention"meta.systemTpl: "## 上下文\n\n#(ctx)\n\n## 任务\n\n根据用户的描述,判断用户最可能的三个健康问题,只要诊断名称,不需要其他解释,用 Markdown 的列表格式返回。\n\n"meta.userTpl: "## 病人自述\n\n#(prompt)\n\n## 历史病情\n\n#(history)\n\n"task: "@intentionTask"- id: "治疗建议"type: "execute"meta.model: "qwen2.5:7b"meta.apiUrl: "http://127.0.0.1:11434/api/chat"meta.provider: "ollama"meta.input: "intention"meta.output: "suggestion"meta.system: "## 角色\n\n你是一个经验丰富的医生\n\n## 任务\n根据用户提供的诊断信息,提供治疗建议"task: "@suggestionTask"- type: "end"
知识库管理
RepositoryController
package com.example.demo.ai.llm.controller;import com.example.demo.ai.llm.service.RepositoryService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import java.util.List;
import org.noear.solon.annotation.*;/*** @author airhead*/
@Controller
@Mapping("/repository")
@Api("知识库")
public class RepositoryController {@Inject private RepositoryService service;@ApiOperation("addDoc")@Post@Mapping("addDoc")public Boolean addDoc(String content) {return service.addDoc(content);}@ApiOperation("search")@Post@Mapping("search")public List<String> search(String query) {return service.search(query);}
}
RepositoryService
package com.example.demo.ai.llm.service;import java.io.IOException;
import java.util.Collections;
import java.util.List;
import org.noear.solon.ai.rag.Document;
import org.noear.solon.ai.rag.repository.RedisRepository;
import org.noear.solon.annotation.Component;
import org.noear.solon.annotation.Inject;/*** @author airhead*/
@Component
public class RepositoryService {@Inject RedisRepository repository;public Boolean addDoc(String content) {try {Document document = new Document(content);repository.insert(Collections.singletonList(document));return true;} catch (IOException e) {throw new RuntimeException(e);}}public List<String> search(String query) {try {List<Document> list = repository.search(query);return list.stream().map(Document::getContent).toList();} catch (IOException e) {throw new RuntimeException(e);}}public String history() {return "无其他慢性病";}
}
诊断
LlmDiagController
package com.example.demo.ai.llm.controller;import com.example.demo.ai.llm.service.LlmService;
import com.jfinal.kit.Kv;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import org.noear.solon.annotation.*;/*** @author airhead*/
@Controller
@Mapping("/llm")
@Api("聊天")
public class LlmDiagController {@Inject private LlmService service;@ApiOperation("diag")@Post@Mapping("diag")public Kv diag(String prompt) {return service.diag(prompt);}
}
LlmDiagService
package com.example.demo.ai.llm.service;import com.jfinal.kit.Kv;
import org.noear.solon.annotation.Component;
import org.noear.solon.annotation.Inject;
import org.noear.solon.flow.ChainContext;
import org.noear.solon.flow.FlowEngine;/*** @author airhead*/
@Component
public class LlmDiagService {@Inject private FlowEngine flowEngine;public Kv diag(String prompt) {try {ChainContext chainContext = new ChainContext();chainContext.put("prompt", prompt);Kv kv = Kv.create();chainContext.put("result", kv);flowEngine.eval("ai-flow-01", chainContext);return kv;} catch (Throwable e) {throw new RuntimeException(e);}}
}
验证
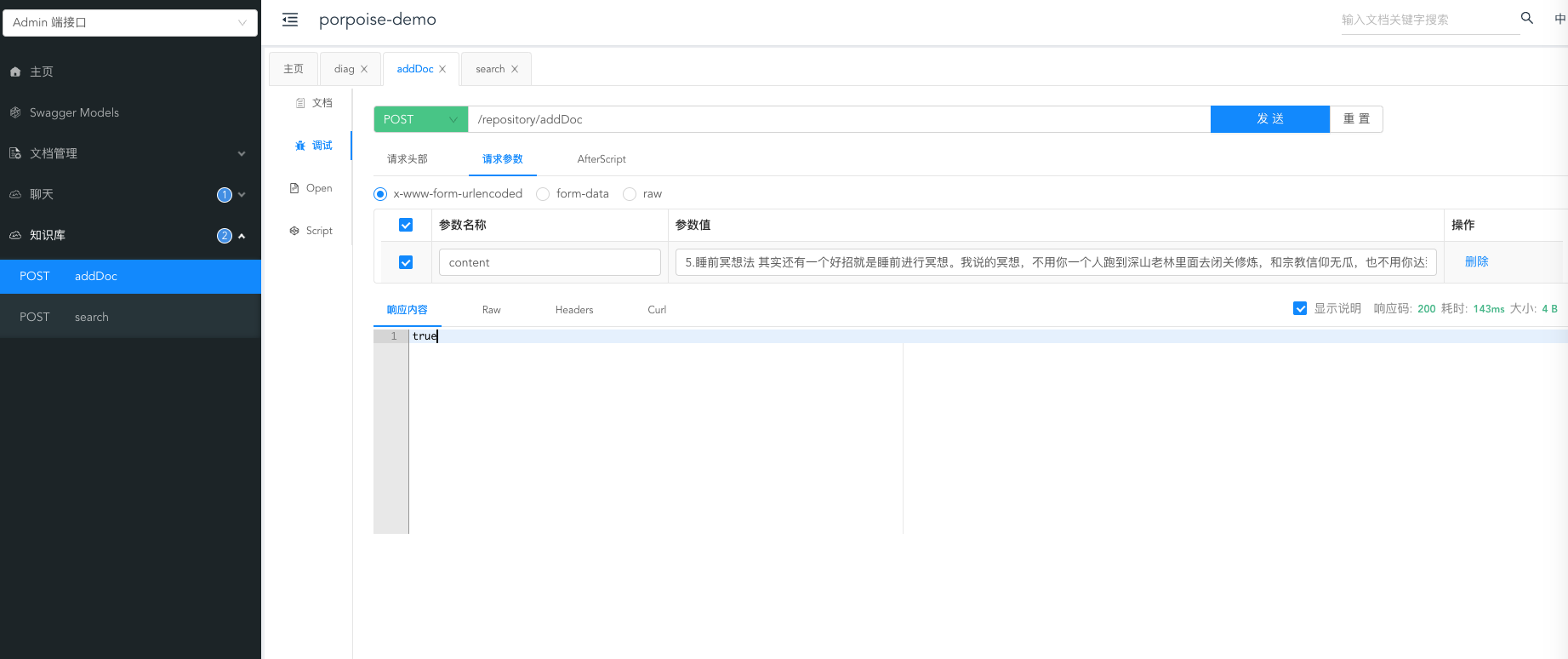
知识管理
通过接口写入一些文档,这里是一些睡眠的方法。
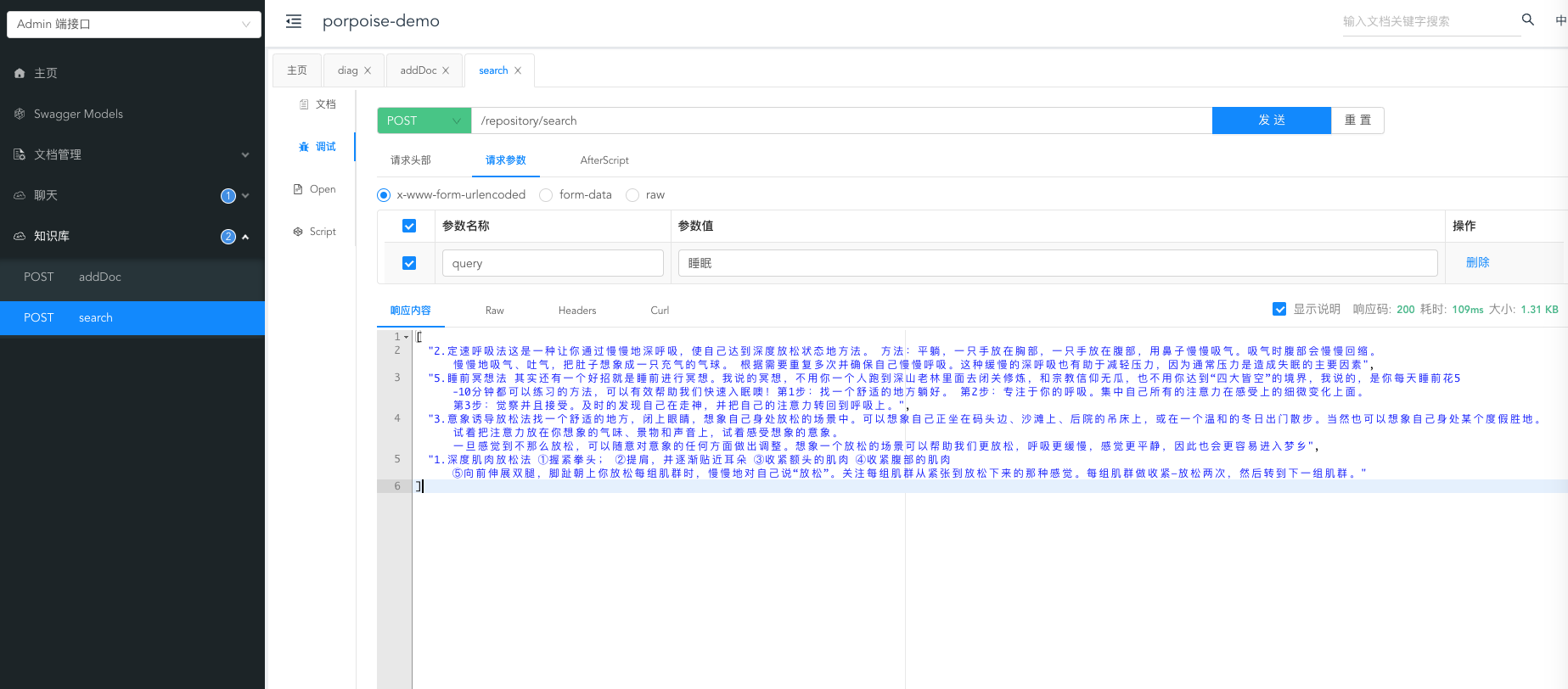
知识查询
通过查询睡眠
诊断服务
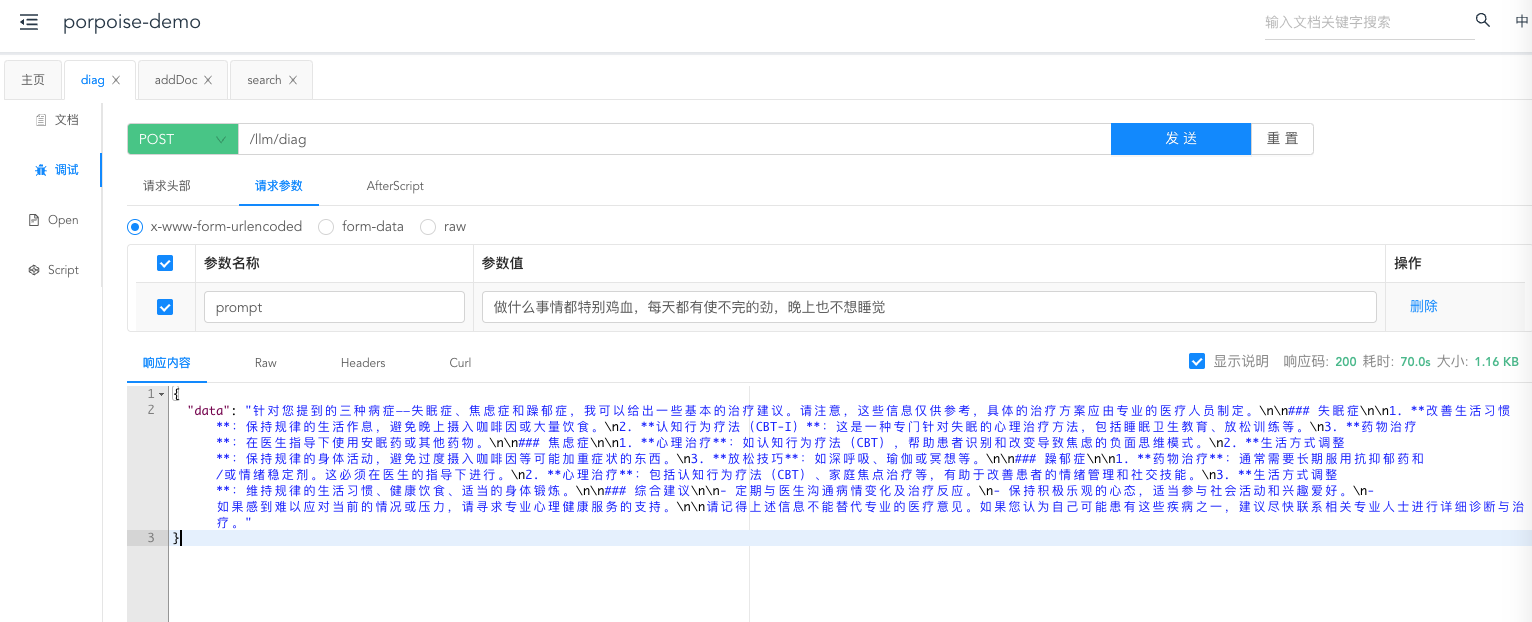
中间的调试信息,我们可以看到我们添加的知识库的信息被追加到提示信息中,提交给大模型。

小结
示例中没有对文档的拆分和文档不同文档类型的加载,但我们可以看到 Solon-ai 结合 solon-flow 已经能完整的支持 RAG 的知识库的开发了。当然如果要做一个完整的知识库系统还需要很多工作要做。