太原网站建设360淘宝权重查询入口
上一篇文章说明了交换机,队列和绑定在数据库中的存储,本篇文章来说明消息在硬盘上的存储。
消息不放在数据库,而放在文件中的原因:
- 消息操作并不涉及到复杂的增删改查
- 消息的数量可能会非常多,数据库的访问效率是并不高的
- 文件通常更容易被复制和迁移
存储和构成
消息具体如何在文件中存储
- 消息是依附于队列的,因此存储的时候,就把消息按照队列的维度进行展开,此处已经有了个data目录(meta.db就在这个目录中),在data中创建一些子目录,每个队列有一个子目录,子目录的名字就是队列名
- 每个队列队列的子目录下,再分配两个文件,来存储消息,第一个文件是queue_data.txt,保存消息的内容,第二个文件:queue_stat.txt,保存消息的统计信息
注:queue_data是一个二进制格式的文件,这个文件包含若干个消息,每个消息都以二进制的方式存储,每个消息由以下几个部分构成:
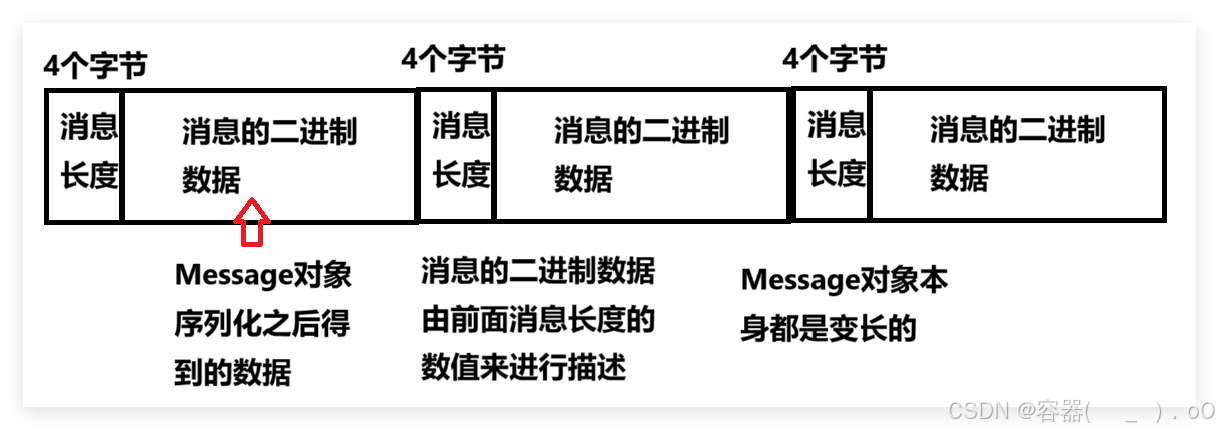
由Message类的构成来看也是支持Message对象本身是变长的:
 其中,消息的二进制数据格式是Java标准库的序列化来实现的,构成如下:
其中,消息的二进制数据格式是Java标准库的序列化来实现的,构成如下:

其中的isVaild属性用来标识当前这个消息在文件中是否有效,对于Broker Server来说,消息是需要新增和删除的,生产者生产一个消息过来,就需要新增这个消息,消费者把这个消息消费掉,这个消息就删除了,新增和删除对于内存来说 ,可以使用一些集合类。新增消息对于文件来说,可以把新的消息追加到文件末尾,如果是删除中间的元素,就需要涉及到类似于“顺序表搬运”这样的操作,效率低下,因此可以使用逻辑删除的模式,isVaild为1设为有效消息,isVaild为0设为无效消息。那么这样子文件会越来越大,而且大部分是无效的消息,这是就要考虑对当前的数据文件进行垃圾回收。
在Message类中的offsetBeg和offsetEnd这两个参数用来描述消息二进制数据的偏移位置:

Message对象是在内存中记录一份,硬盘上也记录一份,内存中这一份要记录offsetBeg和offsetEnd,随时找到内存中的Message对象,就能找到对应的硬盘的Message对象了。
垃圾回收的设计
复制算法进行垃圾回收
将可用内存划分为两个部分,每次只使用其中一部分。当这部分内存用完时,GC会暂停程序运行,然后将存活的对象复制到另一部分内存区域,并释放原来的内存区域。此方法效率高,但需要额外的内存开销。
这里就是之间遍历原有消息的数据文件,把所有有效的数据拷贝到一个新的文件中,再把之前整个旧的文件都删除。由于复制算法比较适用的前提是当前的空间有效的数据不多,大部分都是无效的数据,因此可以这样子约定,当总的消息数目超过两千并且有效的消息低于50%,就触发一次GC,这样子也可以避免频繁的GC。
那么像总消息数量和有效消息数量应该如何去获取,这就使用到了上面的queue_stat.txt,使用它保存消息的统计信息,一个是总消息数目,一个是有效消息数目。
那么这种情况呢?某个队列中的消息特别多,而且都是有效的数据,这时就会导致消息的数据文件特别大,对于这个文件的各种操作就会特别耗时,对于RabbitMQ来说,就是把一个大的文件拆成若干个小的文件。文件拆分,当单个文件长度达到一定阈值时,拆成两个文件。文件合并:每个文件单独进行GC,如果GC之后,发现文件变小很多,就合并相邻文件。关于此的设计思路:专门的数据结构,存储当前队列中有多少个数据文件,每个文件大小是多少,消息数目和无效消息时多少,什么时候触发拆分,什么时候触发合并。
统计文件的读写
每个队列都有自己的目录,每个目录下有统计文件,因此读的时候可以传入队列名进行读取。

private Stat readStat(String queueName) {// 由于是文本文件,所以可以直接读取文件内容Stat stat = new Stat();try(InputStream inputStream = new FileInputStream(getQueueStatPath(queueName))) {Scanner scanner = new Scanner(inputStream);stat.totalCount = scanner.nextInt();stat.validCount = scanner.nextInt();return stat;} catch (IOException e) {throw new RuntimeException(e);}}private void writeStat(String queueName, Stat stat) {// PrintWriter进行写文件// OutputStream打开文件,默认是覆盖写try (OutputStream outputStream = new FileOutputStream(getQueueStatPath(queueName)){PrintWriter printWriter = new PrintWriter(outputStream);printWriter.write(stat.totalCount + "\t" + stat.validCount);printWriter.flush();}catch (IOException e) {throw new RuntimeException(e);}}由于是依据目录层级结构进行设计,故在使用已编写的方法前,需首先创建与队列相对应的文件及目录。代码如下:
// 创建队列对应的文件和目录public void createQueue(String queueName) throws IOException {// 1. 队列对应的创建消息目录File baseDir = new File(getQueueDir(queueName));if (!baseDir.exists()) {boolean ok = baseDir.mkdirs();if (!ok) {throw new IOException("创建队列目录失败! baseDir = " + baseDir.getAbsolutePath());}}// 2. 创建消息数据文件File queueDataFile = new File(getQueueDataPath(queueName));if (!queueDataFile.exists()) {boolean ok = queueDataFile.createNewFile();if (!ok) {throw new IOException("创建队列数据文件失败! queueDataFile = " + queueDataFile.getAbsolutePath());}}// 3. 创建消息统计文件File queueStatFile = new File(getQueueStatPath(queueName));if (!queueStatFile.exists()) {boolean ok = queueStatFile.createNewFile();if (!ok) {throw new IOException("创建队列统计文件失败! queueStatFile = " + queueStatFile.getAbsolutePath());}}// 4. 初始化统计文件,0\t0Stat stat = new Stat();stat.totalCount = 0;stat.validCount = 0;writeStat(queueName, stat);}按照这样的逻辑,还需要写 删除创建与队列相对应的文件及目录以及 检查创建与队列相对应的文件及目录。这里就不再赘述了。
消息数据文件的读写
消息序列化和反序列化的实现
所谓的消息序列化是指把一个对象(结构化的数据)转成一个字符串/字节数组,这样序列化完成之后,对象信息不丢失的,这样以后才能进行反序列化,序列化是为了方便存储(一般存储在文件中,文件只能存字符串/二进制数据)和传输(网络)。
由于Message里面存储的body部分,是二进制数据,不太方便使用JSON进行序列化,因为JSON序列化得到的结果是文本数据,无法存储二进制。原因是:JSON 格式中有很多特殊符号,:"{}这些符号会影响 json 格式的解析,如果存文本,你的键值对中不会包含上述特殊符号.,如果存二进制,那就不好说.万一某个二进制的字节正好就和 上述特殊符号 的 ascii 一样了,此时就可能会引起 json 解析的格式错误。如果想使用json表示二进制数据,可以针对二进制数据进行base64编码,base64的作用就是用4个字节表示3个字节的信息,会保证4个字节都是使用文本字符。这里直接使用二进制的序列化方式。
二进制的序列化方式
- Java标准库提供的序列化方案:ObjectInputStream和ObjectOutputStream
- Hessian
- protobuffer
- thrift
这里为了方便采用第一种形式,由于序列化和反序列化是很多模块用到的,这里写到公共模块,通过类名直接调用,序列化的反序列化方法上加上static,为了解决数组长度不确定的问题,可以使用ByteArrayOutputStream,这个流对象相当于一个变长的字节数组,可以把obj序列化的数据逐渐写入到这个流中,再统一转成字节数组。为了保证数据的完整性和资源释放,流对象需要关闭,最终序列化代码如下:
public static byte[] toBytes(Object obj) throws IOException {// 解决数组长度不确定的问题// 这个流对象相当于一个变长的字节数组,可以把obj序列化的数据逐渐写入到这个流中,再统一转成字节数组try(ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()) {try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream)) {// writeObject会把obj进行序列化,生产二进制字节数据,然后写入到objectOutputStream中// 由于ObjectOutputStream 关联到 ByteArrayOutputStream 最终写入ByteArrayOutputStream中objectOutputStream.writeObject(obj);}// 二进制数据转为字节数组return byteArrayOutputStream.toByteArray();}}反序列化时是从输出流中读取对象
public static Object toObject(byte[] bytes) throws IOException, ClassNotFoundException {Object obj = null;try (InputStream inputStream = new ByteArrayInputStream(bytes)){try (ObjectInputStream objectInputStream = new ObjectInputStream(inputStream)) {// readObject就是从bytes这个字节数组中读取数据,反序列化出一个对象obj = objectInputStream.readObject();}}return obj;}注意:要实现序列化和反序列化,需要实现Serializable接口,这里指Message
消息写入文件
首先检查要写入的队列对应的文件是否存在,不存在则抛出自定义异常,之后调用前面写的序列化,将对象转成二进制字节数组。之后获取当前队列数据文件的文件长度,计算出改对象的offsetBeg和offsetEnd,就是表明要写入文件的那个位置,一般是写入到文件的末尾。
这里写入文件应该是追加写,否则写入新的数据就会覆盖掉之前的,首先写入消息的长度,4个字节,可不可以如下,不行,这样写的是一个字节。
outputStream.write(messageBinary.length);

可以使用位运算分别取出,一个字节一个字节的写入: 还可以这样子
还可以这样子

最后更新统计页。
如果多个线程同时调用这个写方法,引发线程安全问题,图解如下:
 可以通过加锁用来解决线程安全问题,当前以队列对象加锁即可,如果两个线程往一个队列中写消息,此时要阻塞等待,如果两个线程往不同队列中写消息,此时不需要阻塞等待
可以通过加锁用来解决线程安全问题,当前以队列对象加锁即可,如果两个线程往一个队列中写消息,此时要阻塞等待,如果两个线程往不同队列中写消息,此时不需要阻塞等待
删除消息
此时是逻辑删除,把消息的状态设置为无效,思路,先把文件这一段消息读出来,还原为Message对象,然后把isVaild改为0,最终把消息写回文件,注意,此时这个参数的message对象必须包含有效的offsetBeg和offsetEnd,否则后续写的找不到写入的位置在哪里.
之前用的FileputStream和FileputOutputStream都是从文件头进行读写的,此时需要的时在文件的指定位置进行读写,随机访问需要使用到RandomAccessFile。其中的seek可以调整当前文件光标所在位置,也就是当前读写文件的位置。
此时也有线程安全问题,因此进行加锁。
加载文件中的所有消息到内存中
当程序重启,内存中的原始数据消失,但是硬盘中不会消失,因此这个方法,准备在程序启动的时候进行调用。使用LinkedList,主要为了后续进行头删操作。
// 读取所有的消息的内存,加载到内存中// 这个方法是为了初始化的时候,把消息加载到内存中// 这里的调用使其在程序启动时,不涉及多线程,所以不需要加锁,因此不需要锁对象,传入queueName即可
public LinkedList<Message> loadMessageFromQueue(String queueName) throws IOException, ClassNotFoundException {LinkedList<Message> messages = new LinkedList<>();try (InputStream inputStream = new FileInputStream(getQueueDataPath(queueName))) {try (DataInputStream dataInputStream = new DataInputStream(inputStream)) {// 记录当前文件光标long currentOffset = 0;// 一个文件包含多个消息,此处需要循环读取while (true) {// 1. 读取消息长度,这里可能读到文件末尾// readInt()会抛出 EOFException 异常int messageLength = dataInputStream.readInt();// 2. 读取消息体byte[] messageBinary = new byte[messageLength];int actualLength =dataInputStream.read(messageBinary);if (actualLength != messageLength) {// 不匹配,说明文件有问题,格式错乱throw new IOException("【MessageFileManager】 消息文件格式错误! queueName = " + queueName);}// 3. 反序列化,把字节数组转成Message对象Message message = (Message) BinaryTool.toObject(messageBinary);// 4. 判断消息是否有效if (message.getIsValid() != 0x1) {// 虽然是无效,但是光标还是需要移动的currentOffset += (4+messageLength);continue;}// 5. 有效数据,则需要把这个 Message 对象加入到链表中。加入之前还需要填写 offsetBeg 和 offsetEnd//进行计算 offset 的时候,需要知道当前文件光标的位置的。由于当下使用的 DataInputStream 并不方便//因此就需要手动计算下文件光标。message.setOffsetBeg(currentOffset+4);message.setOffsetEnd(currentOffset+4+messageLength);// 移动光标currentOffset += (4+messageLength);messages.add(message);}}catch (EOFException e) {// 说明已经读到文件末尾了System.out.println("【MessageFileManager】 恢复Message成功! ");}}return messages;}垃圾回收
由于当前会不停的往消息文件中写入新消息,并且删除消息只是逻辑删除,这就可能导致消息文件越来越大,并且里面又包含大量的无效消息。此处的垃圾回收,使用 复制算法,判定,当文件中消息总数超过 2000,并且有效消息的数目不足 50%, 就要触发垃圾回收。就把文件中所有有效的消息取出来,单独的再写入到一个新的文件中,删除旧文件,使用新文件代替,
// 检查当前队列消息数据是否需要进行垃圾回收public boolean checkGC(String queueName) {// 判断是否要进行垃圾回收,根据队列的统计信息来判断,即总消息数和有效消息数Stat stat = readStat(queueName);// 有效消息数小于总消息数的一半,并且总消息大于2000return stat.validCount < stat.totalCount / 2 && stat.totalCount > 2000;}// 新文件的位置private String getQueueDataNewPath(String queueName) {return getQueueDir(queueName) + "queue_data_new.txt";}// 进行垃圾回收,把无效的消息删除,把有效消息重新写入到新文件中// 记得把新文件重命名为旧文件名以及更新消息统计信息// 需要加锁,GC过程中,不允许有其他线程进行消息的写入和删除,否则会导致数据不一致,而且GC比较耗时public void gc(MSGQueue queue) throws IOException, ClassNotFoundException, MqException {synchronized (queue) {// 0. 由于GC比较耗时,统计下执行时间long startTime = System.currentTimeMillis();// 1. 创建新文件File queueDataNewFile = new File(getQueueDataNewPath(queue.getName()));if (queueDataNewFile.exists()) {// 如果新文件已经存在,说明上次GC没有执行完,程序异常退出了throw new MqException("【MessageFileManager】 上次GC没有执行完,程序异常退出了! queueName = " + queue.getName());}boolean ok = queueDataNewFile.createNewFile();if (!ok) {throw new MqException("【MessageFileManager】 创建新文件失败! queueDataNewName = " + queueDataNewFile.getAbsolutePath());}// 2. 读取旧文件,读取所有的有效消息对象,调用上述方法LinkedList<Message> messages = loadAllMessageFromQueue(queue.getName());// 3. 有效消息写入新文件,如果调用前面的sendMessage方法,需要使其支持文件名,以后可以改改,当作扩展try (OutputStream outputStream = new FileOutputStream(queueDataNewFile)) {try (DataOutputStream dataOutputStream = new DataOutputStream(outputStream)) {for (Message message : messages) {byte[] buffer = BinaryTool.toBytes(message);dataOutputStream.writeInt(buffer.length);dataOutputStream.write(buffer);}}}// 4. 删除+重命名新文件为旧文件名File queueDataOldFile = new File(getQueueDataPath(queue.getName()));ok = queueDataOldFile.delete();if (!ok) {throw new MqException("【MessageFileManager】 删除旧文件失败! queueDataOldFile = " + queueDataOldFile.getAbsolutePath());}ok = queueDataNewFile.renameTo(queueDataOldFile);if (!ok) {throw new MqException("【MessageFileManager】 重命名新文件失败! queueDataNewFile = " + queueDataNewFile.getAbsolutePath()+ ",queueDataOldFile = " + queueDataOldFile.getAbsolutePath());}// 5. 更新消息统计信息Stat stat = readStat(queue.getName());stat.totalCount = messages.size();stat.validCount = messages.size();writeStat(queue.getName(), stat);long endTime = System.currentTimeMillis();System.out.println("【MessageFileManager】 GC执行完毕!queueName=: " + queue.getName() + ",time=" + (endTime - startTime) + "ms");}}