汽配公司的网站要怎么做如何提升网站搜索排名
SWE-Dev:开启自主特征驱动软件开发新纪元,重新定义大模型编码能力边界
在大语言模型(LLM)席卷软件工程领域的当下,代码补全、漏洞修复等任务已取得显著进展,但真实场景中占比高达40%的特征驱动开发(FDD)却长期被忽视。论文提出的SWE-Dev数据集,如同为AI编码系统打造的"实战训练场",不仅填补了这一空白,更通过14000个训练样本与500个测试样本,揭示了当前AI在复杂软件开发中的能力天花板与突破路径。
论文标题
SWE-Dev: Evaluating and Training Autonomous Feature-Driven Software Development
来源
arXiv:2505.16975v1 [cs.SE] + https://arxiv.org/abs/2505.16975v1
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
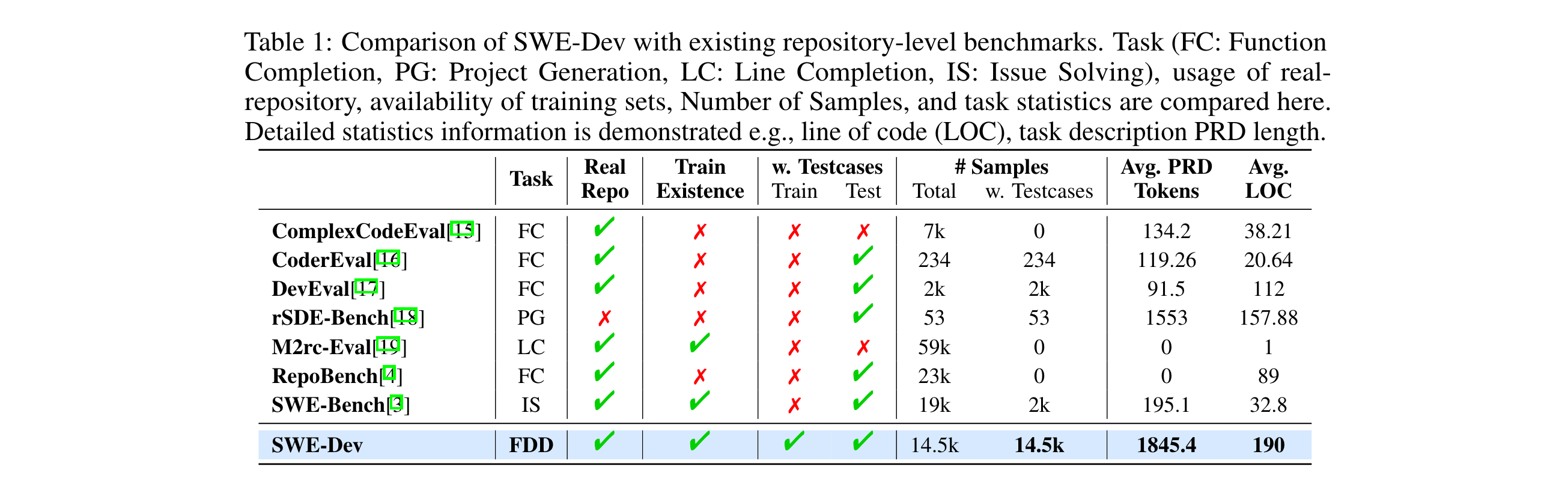
大语言模型(LLMs)在代码补全、漏洞修复和文档生成等软件工程任务中展现出强大能力。然而,在真实软件开发中占比达40%的特征驱动开发(FDD)却未被充分探索。FDD是现代软件持续进化的主要方式,涉及在大型现有代码库中解释需求并生成功能正确且集成的代码,需要处理跨文件依赖和长上下文等复杂情况。当前主流基准如SWE-Bench和RepoBench存在不足,无法有效评估LLMs在真实端到端开发场景中的表现,亟需专门针对FDD的评估和训练平台。
研究问题
-
真实场景覆盖不足:现有基准(如SWE-Bench、RepoBench)多聚焦局部功能完成或漏洞修复,无法模拟FDD中"需求理解-代码集成-功能验证"的端到端流程。
-
评估体系薄弱:多数基准依赖代码相似度等代理指标,缺乏可执行测试用例的功能正确性验证,导致评估结果与真实开发需求脱节。
-
训练范式受限:缺乏包含可执行环境与测试套件的大规模数据集,限制了监督微调(SFT)、强化学习(RL)及多智能体训练等先进范式在复杂开发任务中的应用。
主要贡献
-
首个FDD专用数据集:SWE-Dev包含14000个训练样本与500个测试样本,每个样本均基于真实开源项目,附带可运行环境与开发者编写的可执行单元测试,如同为AI配备"实战训练靶场",首次实现FDD任务的可验证训练与评估。
-
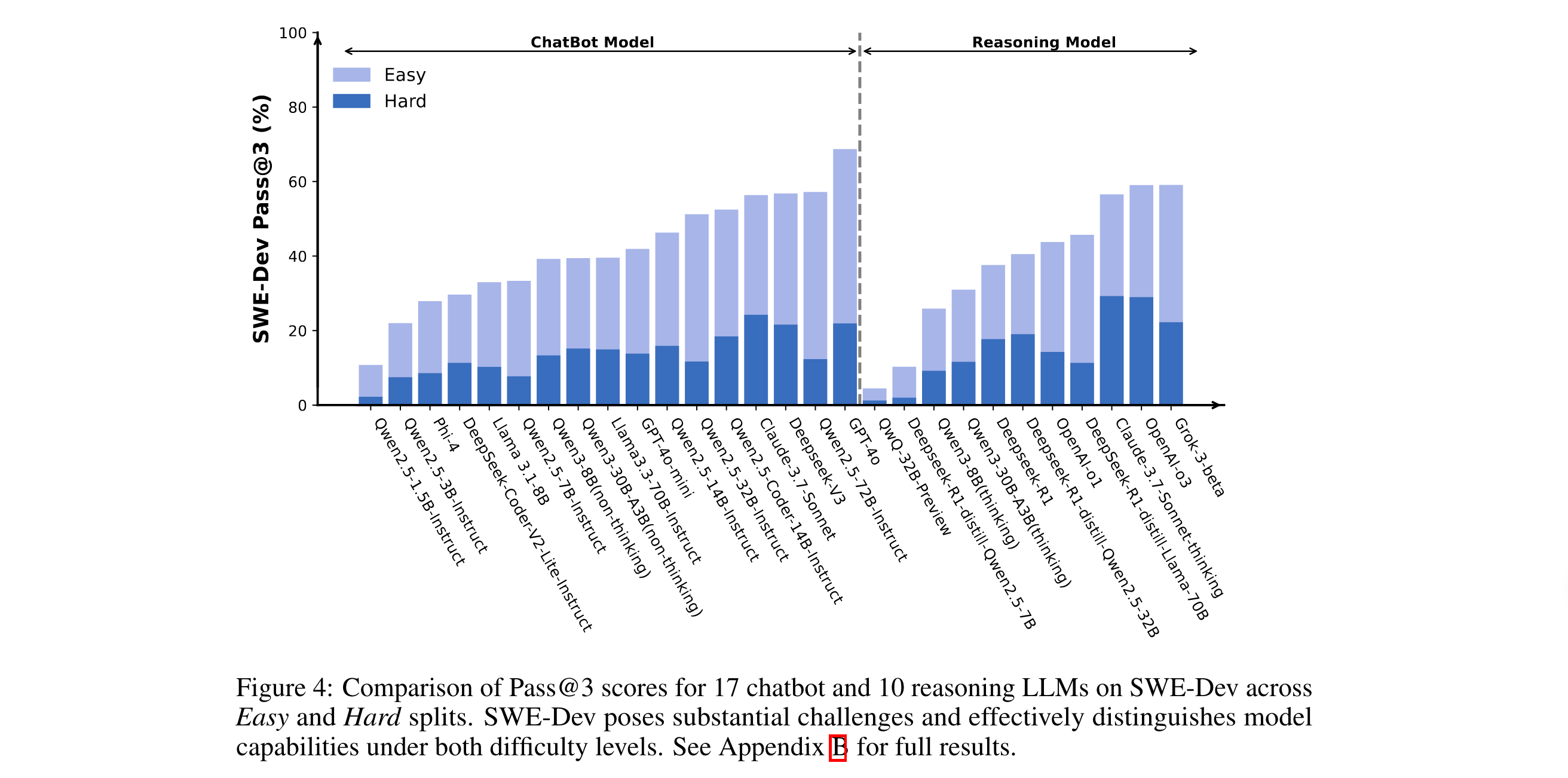
多维度能力边界揭示:通过对17个聊天机器人LLM、10个推理模型及10个多智能体系统(MAS)的评估发现,即使是Claude-3.7-Sonnet等先进模型,在硬难度测试集上的Pass@3仅为22.45%,暴露出现有AI在长上下文推理、跨文件依赖处理等方面的短板。
-
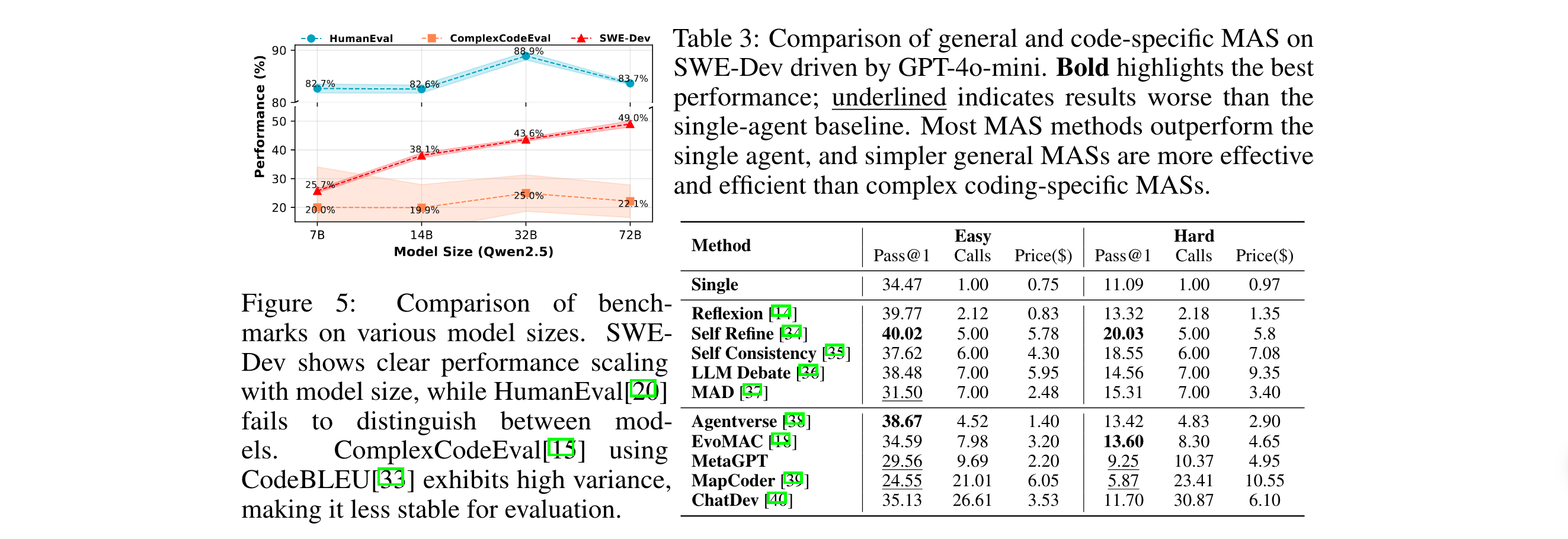
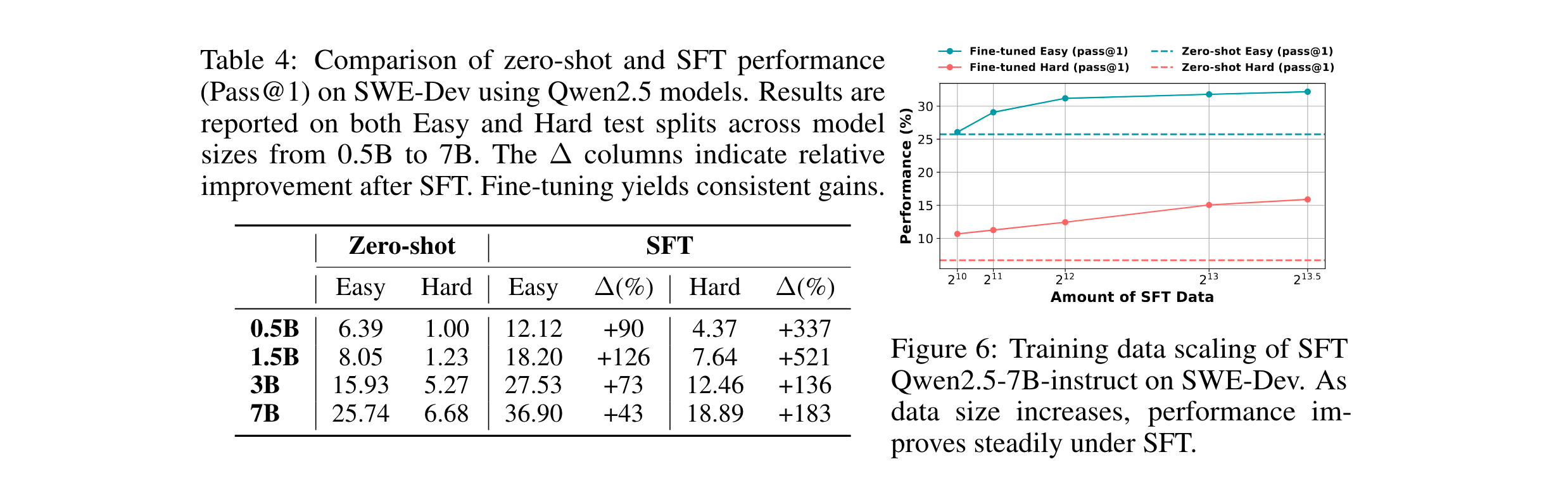
训练范式有效性验证:基于SWE-Dev的微调实验显示,70亿参数模型经任务特定训练后,在硬难度子集上性能可媲美GPT-4o,证明高质量FDD数据对模型能力提升的关键作用;多智能体训练中,简单策略(如Self-Refine)比复杂架构更高效,为轻量化开发协作提供新思路。

方法论精要
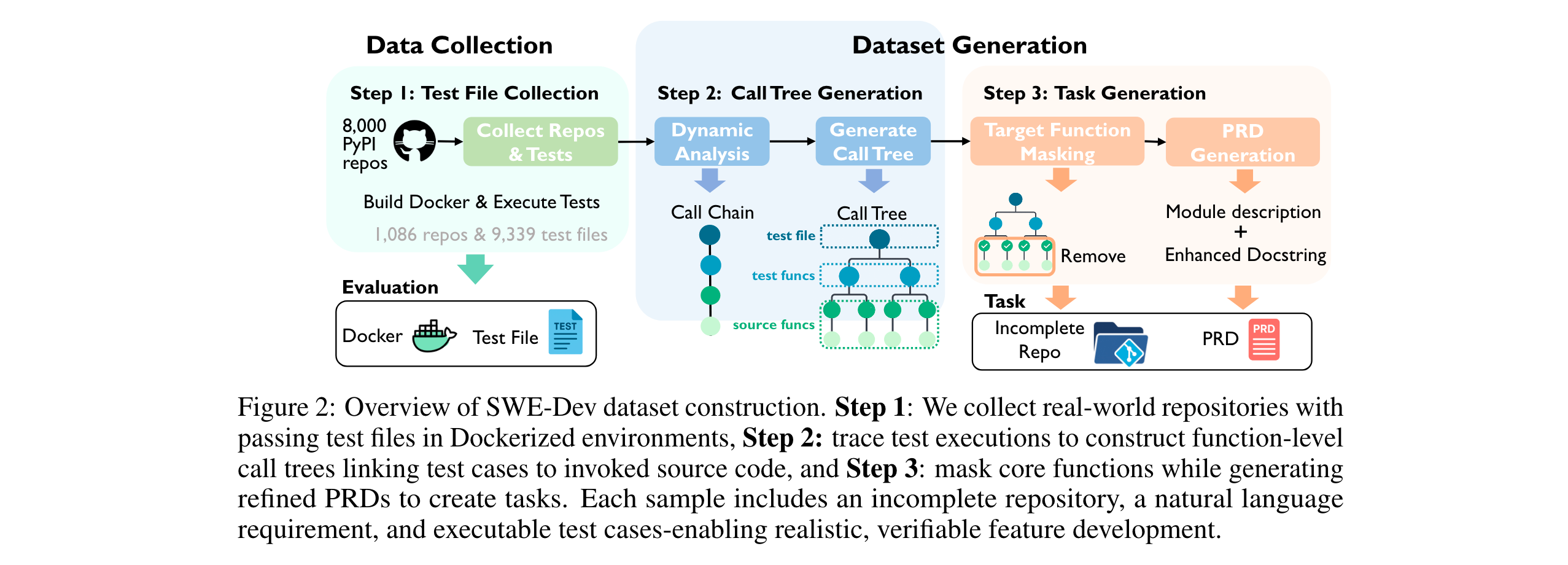
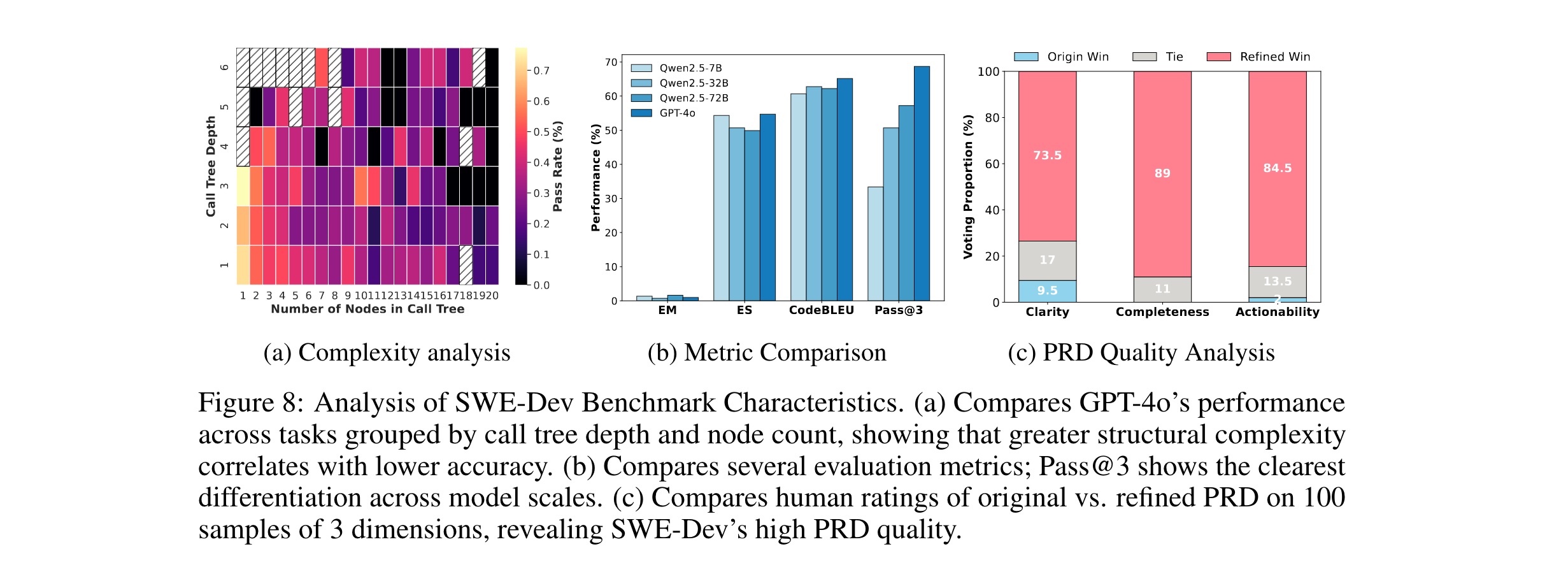
- 核心框架:动态追踪-任务生成流水线
- 通过动态分析PyPI仓库的测试用例执行轨迹,构建函数调用树,定位核心功能逻辑;
- 屏蔽目标函数并结合GPT-4o生成项目需求文档(PRD),形成"不完整代码库+自然语言需求+可执行测试"的标准任务格式,如同从真实项目中"裁剪"出待完成的开发任务。
- 关键设计原理
- 复杂度可控:基于调用树深度与节点数调节任务难度,如深度3以上的任务需处理多层函数嵌套,模拟复杂业务逻辑;
- 评估严谨性:直接使用开发者编写的pytest测试用例,通过执行结果(PASSED/FAILED)提供精确奖励信号,避免传统指标的"虚假相关"。
- 创新性技术组合
- 数据构建三元组:融合真实开源仓库(1086个)、动态调用链分析、GPT-4o精炼的PRD,形成"代码基座-逻辑映射-需求描述"的黄金三角;
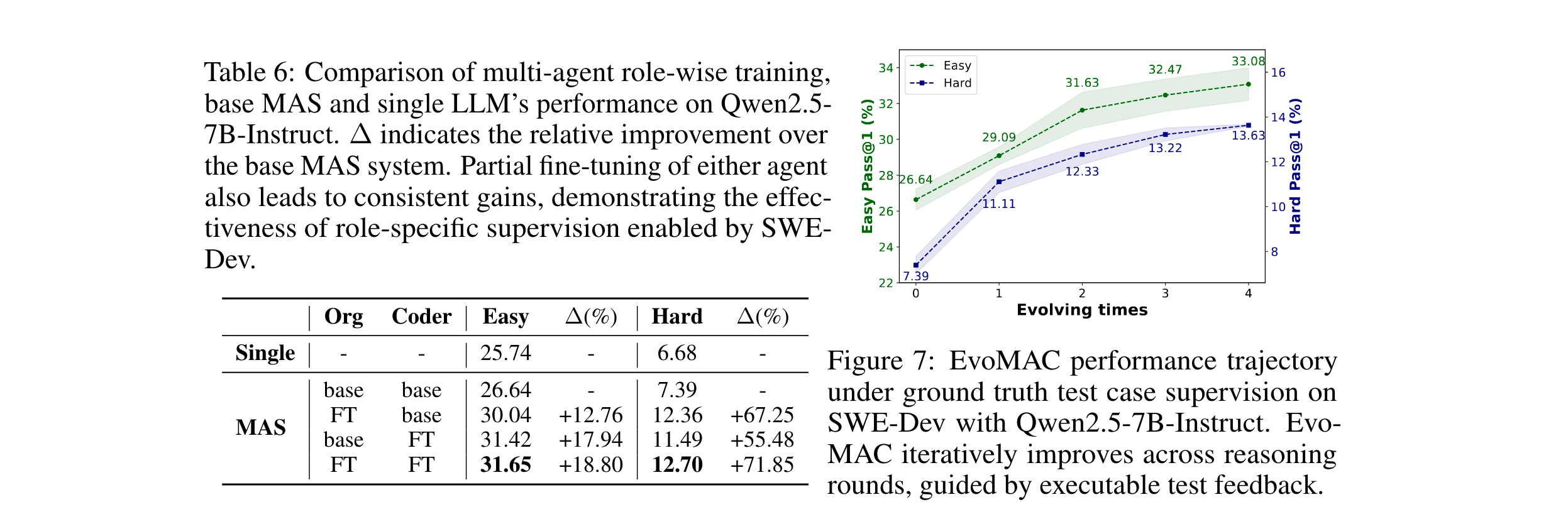
- 训练范式融合:支持SFT(监督微调)、在线RL(基于测试用例反馈优化)、离线RL及多智能体训练,如EvoMAC通过角色分工(组织者+编码者)与拒绝采样,实现迭代优化。
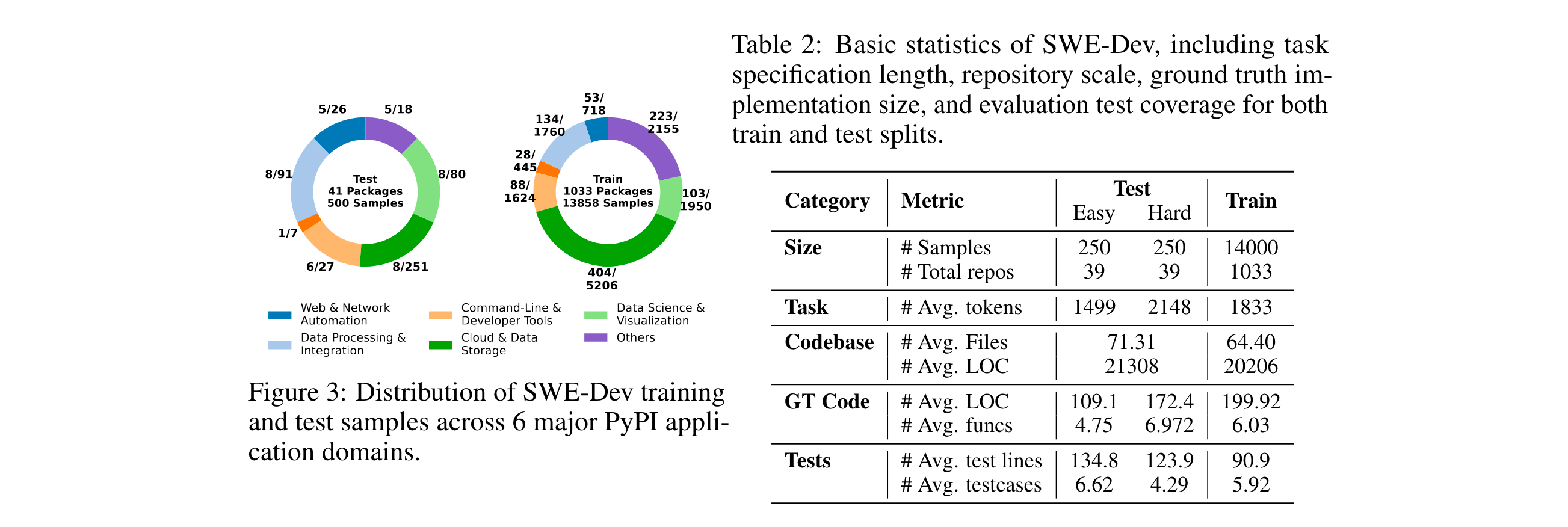
- 实验验证体系
- 数据集分层:测试集手动划分为Easy/Hard子集(各250例),Hard子集平均需修改172行代码,涉及6.97个函数,考验模型长上下文处理能力;
- 基线多样化:涵盖ChatGPT类聊天模型、DeepSeek-R1等推理专用模型、MetaGPT等多智能体系统,从单智能体到协作模式全面覆盖。
实验洞察
- 性能优势
- 模型规模效应:Qwen2.5系列模型随参数量从7B增至72B,Hard子集Pass@1从6.68%提升至19.76%,但Claude-3.7-Sonnet(非公开)以22.45% Pass@3仍为当前天花板;
- 多智能体增益:Self-Refine在Hard子集将Pass@1从单智能体的11.09%提升至20.03%,且仅需5次模型调用,成本效益优于ChatDev(30次调用仅11.7% Pass@1)。
- 效率突破
- 训练数据缩放律:Qwen2.5-7B经SFT后,Hard子集性能提升183%,且数据量从212例增至213例时,Pass@1仍持续增长,证明SWE-Dev数据的有效性;
- RL针对性优化:PPO在线RL在Hard子集Pass@1达12.25%,优于SFT的9.77%,但Pass@3提升有限,说明RL更擅长"一次答对"而非多轮探索。
- 数据分析
- 调用树复杂度影响:GPT-4o在调用树深度≥3的任务中Pass@3仅15.2%,而深度≤2的任务达42.7%,证实跨文件依赖是主要难点;
- PRD质量验证:经GPT-4o精炼的PRD在"可执行性"指标上比原始文档提升34.5%,人工评估显示其更易指导代码实现。