义乌建设局网站域名搜索引擎
什么是适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
可通俗理解,当我们出国旅游时国外插座我们无法直接使用,而需要一个交流电适配器来帮助我们使用自己的充电插头。而这个交流电适配器就是我们所说的适配器
1.stack的介绍
适配器的本质是复用
- stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
- stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
- stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
empty:判空操作
back:获取尾部元素操作
push_back:尾部插入元素操作
pop_back:尾部删除元素操作- 标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器,默认情况下使用deque
1.2.stack的使用
最小栈

如何获取栈中最小元素?
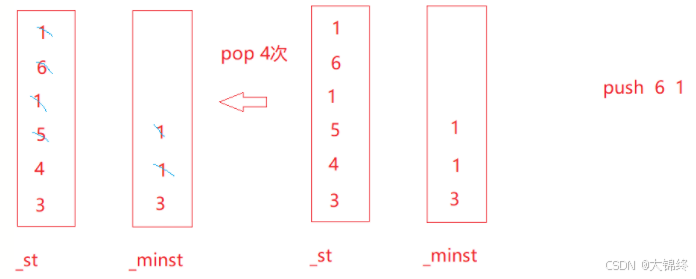
创建一个栈专门用来存储最小元素,首先栈中入一个元素,最小栈也入相同元素,接着栈中再入元素,若<=上个元素则入最小栈,否则继续在栈中入元素。
pop之后如何获取最小元素?
若栈顶元素等于最小栈顶元素,一起删除掉,否则只删除栈顶元素。这样能保持两个栈的同步性,最终会同时为空
假设最初push3451元素
class MinStack {
public:MinStack() {}void push(int val) {st.push(val);if(minst.empty()||st.top()<=minst.top()){minst.push(val);}}void pop() {if(st.top()==minst.top()){minst.pop();}st.pop();}//职责是返回栈顶元素,所以不是minst.top()//minst的是该类的对象,也可以调用该成员函数int top() {return st.top();}int getMin() {return minst.top();}private:stack<int> st;stack<int> minst;
};
栈的弹出压入序列
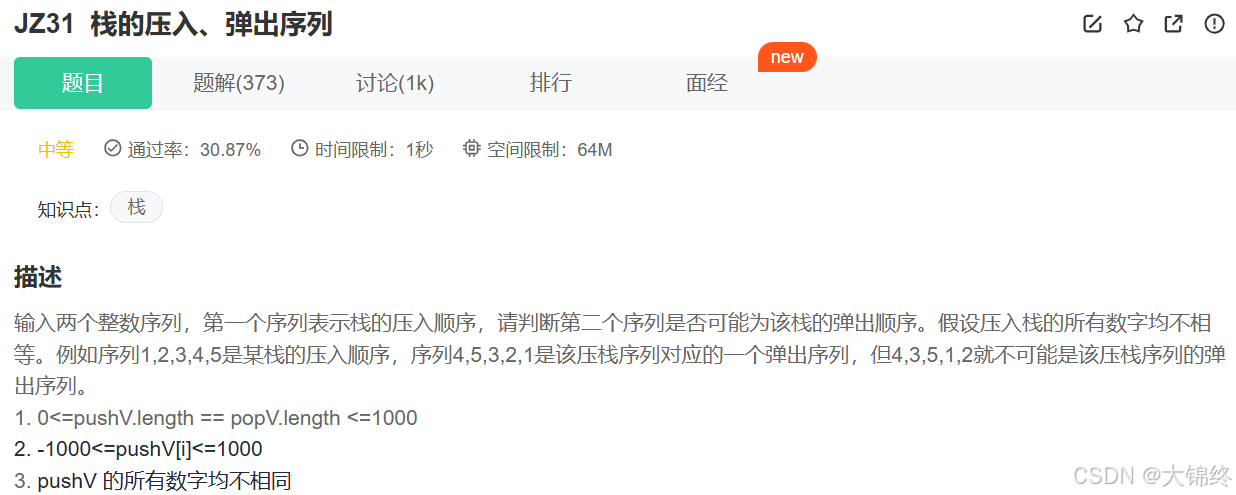
思路:
1.用一个栈来入数据,数据个数等于第一个序列(栈的压入顺序)
2.跟出栈序列匹配,若匹配把匹配的数据都pop掉,若不匹配则继续入数据直到匹配
3.最后用来入数据的栈若等于空,则该弹出顺序合理
bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {stack<int> st;int pushi=0,popi=0;while(pushi<pushV.size()){//先入一个看是否匹配st.push(pushV[pushi++]);if(st.top()!=popV[popi]){//不匹配情况,继续循环continue;}else {while(!st.empty()&&st.top()==popV[popi]){st.pop();popi++;}}}return st.empty();}
需要注意不要在条件判断中对索引进行自增或自减操作,避免条件判断失败而造成的索引变化。
通过创建一个stack<>的对象st来从pushV中入数据,再和popV中弹出序列进行比较
逆波兰表达式求值
逆波兰表达式是一种不包含括号的算术表达式,其中操作符(如加、减、乘、除)位于操作数的后面。这种表达式也被称为后缀表达式。
逆波兰表达式可以直接用栈(stack)数据结构进行计算,计算过程简单且高效。

如何将中缀表达式转化为后缀表达式?
1.操作数输出
2.操作符入栈进行比较
a,栈为空或操作符比栈顶的优先级高,继续入栈
b,栈不为空且当前操作符比栈顶的优先级低或相等,输出栈顶操作符
c,表达式结束后依次出栈里面的操作符
如何进行后缀表达式运算?
1.操作数入栈
2.操作符,取栈顶两个元素进行运算,运算结果继续入栈。
遇到括号问题?
与转化后缀表达式一样,只是遇到左括号时进行递归,结束标志为压入右括号。
class Solution {
public:int evalRPN(vector<string>& tokens) {stack<int> st;for(auto& str:tokens){if(str=="+"||str=="-"||str=="*"||str=="/"){int right=st.top();st.pop();int left=st.top();st.pop();switch(str[0]){case '+':st.push(left+right);break;case '-':st.push(left-right);break;case '*':st.push(left*right);break;case '/':st.push(left/right);break;}}else{st.push(stoi(str));}}return st.top();}
};
需要注意,因为栈后进先出的特性,所以左操作数先入栈,后取,先取的栈顶元素为右操作数
1.3.stack的模拟实现
#pragma once
#include<list>
#include<vector>
#include<deque>namespace ee
{template<class T,class container = deque<T>>class stack{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}T& top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:container _con;};
}
第二个模板参数给了一个容器缺省参数deque,没传值时默认使用。stack一般适配vector和list容器,核心成员函数中的函数二者对库中都有定义,可以直接复用。
注意:.h文件不会被编译,编译阶段直接在源文件中处理其展开的.h文件,编译器遵循向上寻找原则,注意命名空间和头文件的声明顺序。所以我们直接在需要使用的源文件包含头文件之前展开命名空间即可。
2.queue的介绍
- 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素。
- 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
- 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
empty:检测队列是否为空
size:返回队列中有效元素的个数
front:返回队头元素的引用
back:返回队尾元素的引用
push_back:在队列尾部入队列
pop_front:在队列头部出队列
- 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标准容器deque。
2.1.queue的使用
二叉树的层序遍历
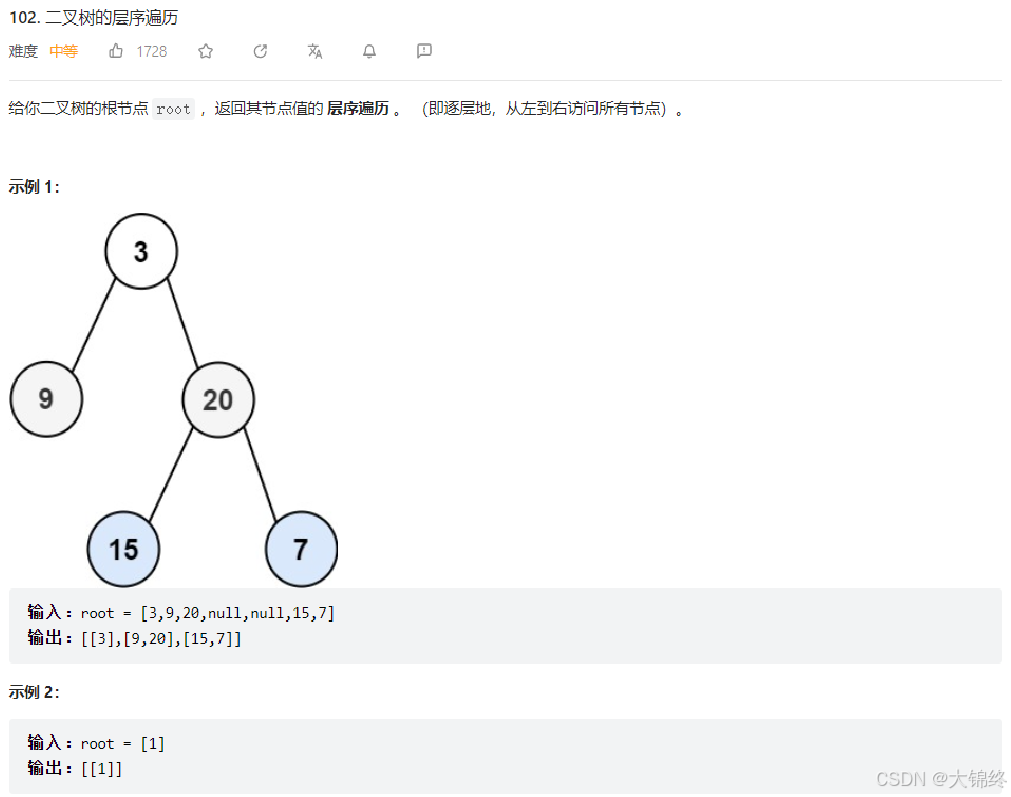
思路1:
双队列:一个队列1用于存储当前层节点,另一个2用来存储下一层的节点。取出根节点,将其左右节点存储到2中,当1为空时将2的节点转移到1中并清空2,开始处理下一层。
思路2:
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> vv; // 用于存储最终结果queue<TreeNode*> q; // 用于层序遍历的队列int levelSize = 0; // 当前层的节点数量if (root) {q.push(root); // 将根节点加入队列levelSize = 1; // 根节点所在的层有1个节点}while (!q.empty()) {vector<int> v; // 用于存储当前层的节点值for (int i = 0; i < levelSize; ++i) {TreeNode* front = q.front(); // 获取队列前端的节点q.pop(); // 移除队列前端的节点v.push_back(front->val); // 将节点值加入当前层的向量// 如果当前节点有左子节点,将其加入队列if (front->left) {q.push(front->left);}// 如果当前节点有右子节点,将其加入队列if (front->right) {q.push(front->right);}}vv.push_back(v); // 将当前层的节点值加入结果向量levelSize = q.size(); // 更新下一层的节点数量}return vv; // 返回层序遍历的结果}
};
层序遍历:使用while循环处理队列中的节点,直到队列为空。每次循环处理一层的节点:
创建一个向量v用于存储当前层的节点值。
使用for循环处理当前层的所有节点(levelSize次):
获取队列前端的节点。将节点值加入v。
如果节点有左子节点,将其加入队列。如果节点有右子节点,将其加入队列。
将v加入结果向量vv。核心:levelsize为当前队列的大小,每次层序遍历之后更新,一遍处理下一层
2.2.queue的模拟实现
queue接口中存在头删和尾删,用vector封装效率低下(会挪动数据),一般用list或deque来实现
#pragma once
#include<vector>
#include<list>
#include<deque>namespace ee
{template<class T,class container =deque<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();//vector容器强制适配,不推荐//_con.erase(_con.begin());}T& front(){return _con.front();}T& back(){return _con.back();}bool empty(){return _con.empty();}private:container _con;};}
复用list在stl库中的接口定义即可,deque都满足。
3.了解deque
deque的原理介绍
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。而且可以进行下标随机访问操作
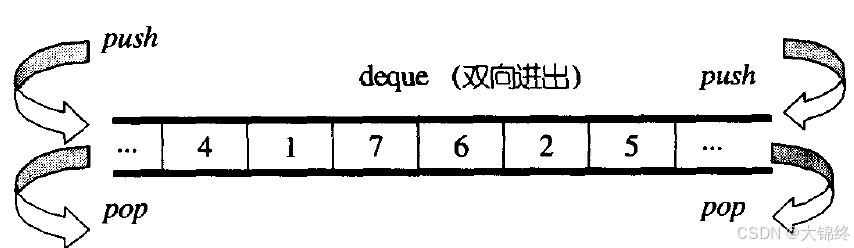
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
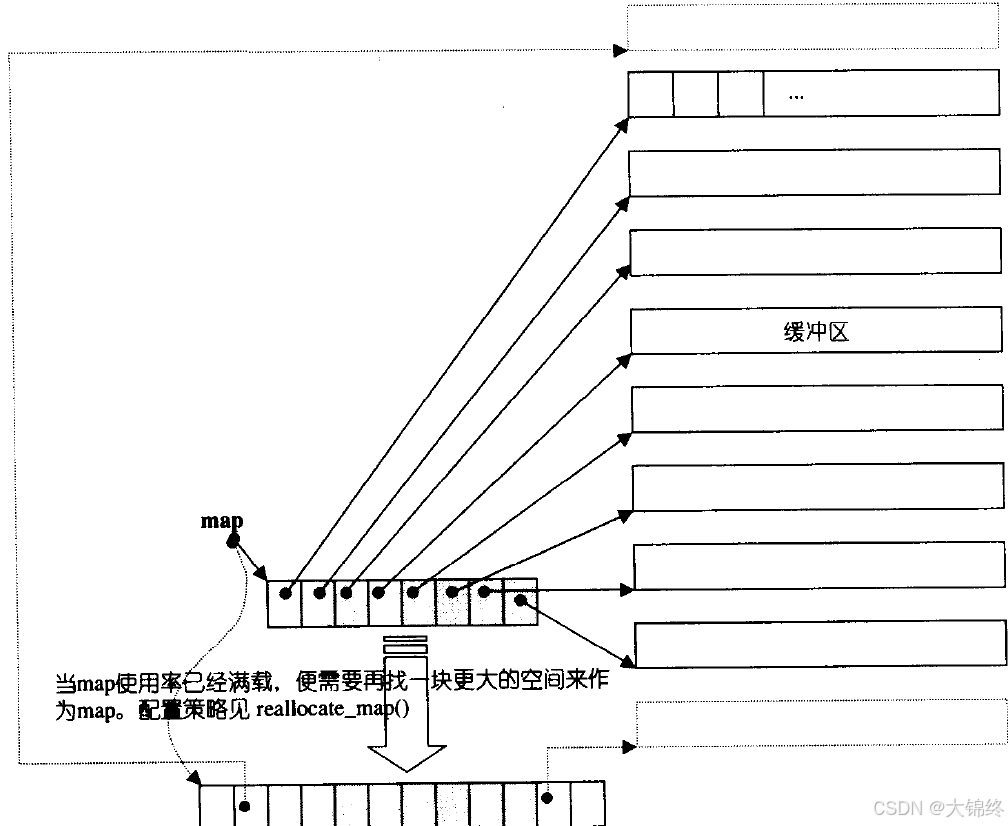
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂
deque迭代器中封装了四个指针,cur指向buffer中当前位置,first和last分别指向头尾位置,node用于指向不同的buffer,当firts等于last时node指向下一个buffer,如此往复进行遍历。
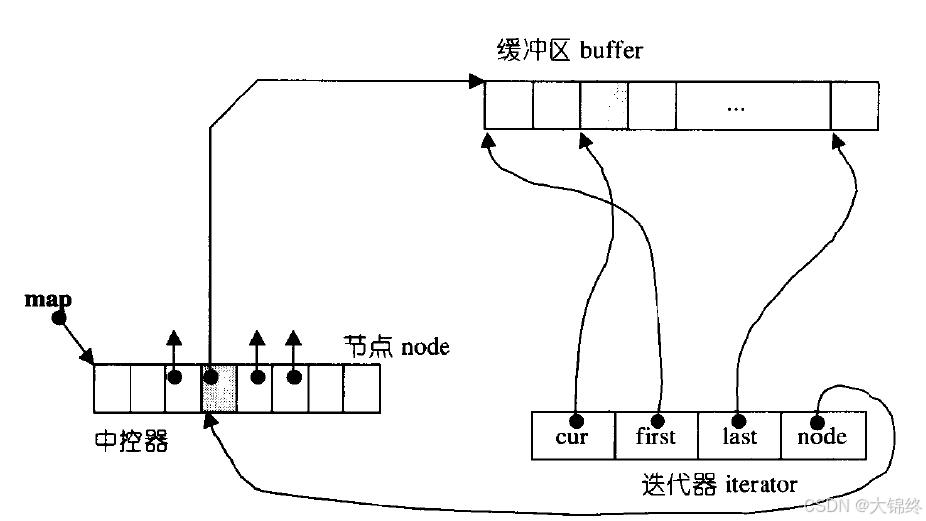
通俗理解如下
deque本质是指针数组,每个数组大小唯一。当指针数组满了,中控指针数组扩容即可。需注意头插时元素是从指针数组的尾部往头部去插入的对比:vector<vector>是对象数组,每个对象大小不一
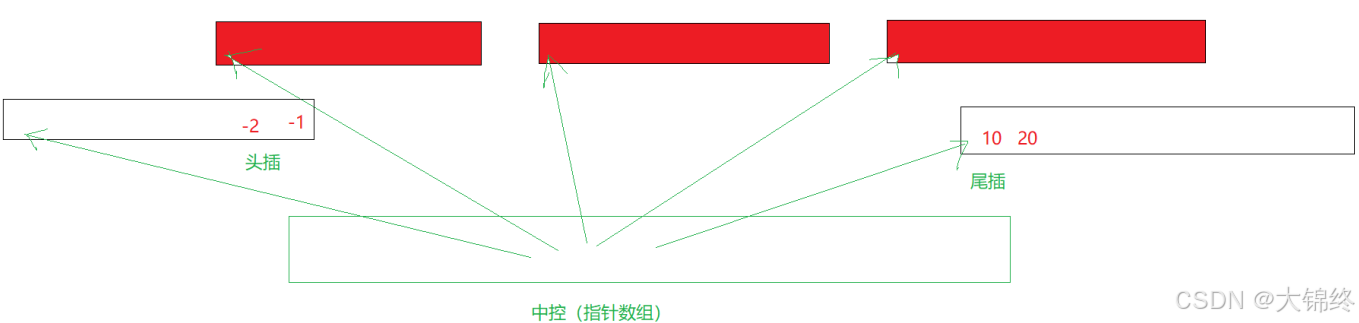
对比及缺陷
deque的功能大有集list与vector于一体的感觉,那为什么它不能代替它们而且实际应用场景不多呢?
vector
优势:下标随机访问效率高
劣势:扩容(异地)代价高,中间和头部插入效率问题(数据整体挪动)
list
优势:任意位置插入删除,空间按需申请释放
劣势:不支持下标随机访问
deque
相比vector
优势:极大缓解了扩容问题(复制指针数组无需拷贝数据代价低,头插头删问题(无需挪动数据)
劣势:[]下标访问不够极致,需要计算在哪个buffer,在哪个buffer中的第几个

测试deque的[]访问效率
void test_op()
{srand(time(0));const int N = 10000;vector<int> v1;vector<int> v2;v1.reserve(N);v2.reserve(N);deque<int> dq1;deque<int> dq2;for (int i = 0; i < N; ++i){auto e = rand();//v1.push_back(e);//v2.push_back(e);dq1.push_back(e);//间接测dq2.push_back(e);//直接测}// 拷贝到vector排序,排完以后再拷贝回来int begin1 = clock();// 先拷贝到vectorfor (auto e : dq1){v1.push_back(e);}// 排序sort(v1.begin(), v1.end());// 拷贝回去size_t i = 0;for (auto& e : dq1){e = v1[i++];}int end1 = clock();int begin2 = clock();//sort(v2.begin(), v2.end());sort(dq2.begin(), dq2.end());int end2 = clock();printf("deque copy vector sort:%d\n", end1 - begin1);printf("deque sort:%d\n", end2 - begin2);
}
这还只是通过vector帮忙排序后再拷贝会deque进行比较,已经做出牺牲但deque还是比不过,若直接与vector进行快排比较,随着数据量增大,将会一败涂地
相比list
优势:可支持下标随机访问,一段段小空间拼接而成的空间cpu高速缓存效率不错
劣势:中间插入效率低下。
1.内存块的固定大小:
每个内存块大小是固定的。当需要在中间插入元素时,可能需要在多个内存块之间移动元素,以腾出空间给新元素。这种操作涉及到大量的内存复制,效率较低。
2.元素的重新分配:
如果插入位置所在的内存块已满,可能需要重新分配内存块,并将现有元素复制到新的内存块中。这会导致额外的内存分配和复制操作,进一步降低效率。
3.指针的更新:
插入元素后,需要更新多个指针来维护内存块之间的链接关系。这增加了操作的复杂性和时间开销。
因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多
而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
原因:
1.stack和queue不需要遍历(因此stack和queue没有迭代器,设计目的限制了访问方式),只需要在固定的一端或者两端进行操作。
2.2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。结合了deque的优点,而完美的避开了其缺陷。