北京网站开发多少钱百度下载应用
本节代码主要为实现了一个简化版的 GPT(Generative Pre-trained Transformer)模型。GPT 是一种基于 Transformer 架构的语言生成模型,主要用于生成自然语言文本。
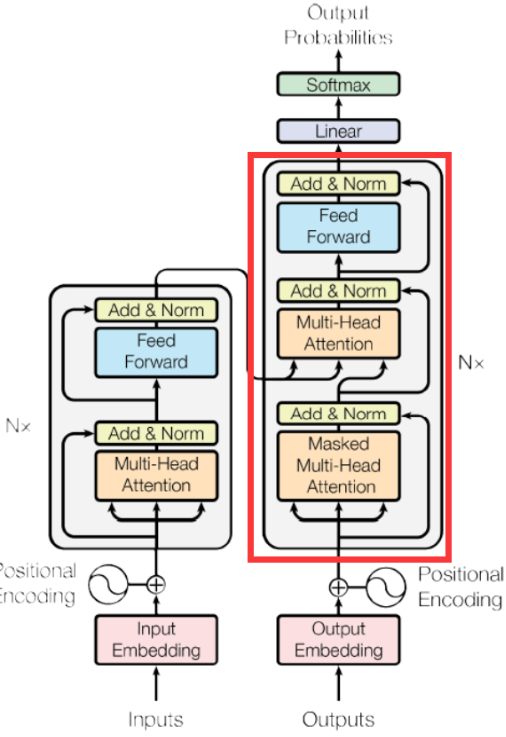
1. 模型结构
初始化部分
class GPT(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, dff, dropout):super().__init__()self.emb = nn.Embedding(vocab_size, d_model)self.pos = nn.Embedding(seq_len, d_model)self.layers = nn.ModuleList([TransformerDecoderBlock(d_model, dff, dropout)for i in range(N_blocks)])self.fc = nn.Linear(d_model, vocab_size)-
vocab_size:词汇表的大小,即模型可以处理的唯一词元(token)的数量。 -
d_model:模型的维度,表示嵌入和内部表示的维度。 -
seq_len:序列的最大长度,即输入序列的最大长度。 -
N_blocks:Transformer 解码器块的数量。 -
dff:前馈网络(Feed-Forward Network, FFN)的维度。 -
dropout:Dropout 的概率,用于防止过拟合。
组件说明
-
self.emb:词嵌入层,将输入的词元索引映射到d_model维的向量空间。 -
self.pos:位置嵌入层,将序列中每个位置的索引映射到d_model维的向量空间。位置嵌入用于给模型提供序列中每个词元的位置信息。 -
self.layers:一个模块列表,包含N_blocks个TransformerDecoderBlock。每个块是一个 Transformer 解码器层,包含多头注意力机制和前馈网络。 -
self.fc:一个线性层,将解码器的输出映射到词汇表大小的维度,用于生成最终的词元概率分布。
2. 前向传播
def forward(self, x, attn_mask=None):emb = self.emb(x)pos = self.pos(torch.arange(x.shape[1]))x = emb + posfor layer in self.layers:x = layer(x, attn_mask)return self.fc(x)步骤解析
-
词嵌入和位置嵌入:
-
self.emb(x):将输入的词元索引x转换为词嵌入表示emb,形状为(batch_size, seq_len, d_model)。 -
self.pos(torch.arange(x.shape[1])):生成位置嵌入pos,形状为(seq_len, d_model)。torch.arange(x.shape[1])生成一个从 0 到seq_len-1的序列,表示每个位置的索引。 -
x = emb + pos:将词嵌入和位置嵌入相加,得到最终的输入表示x。位置嵌入的加入使得模型能够区分序列中不同位置的词元。
-
-
Transformer 解码器层:
-
for layer in self.layers:将输入x逐层传递给每个TransformerDecoderBlock。 -
x = layer(x, attn_mask):每个解码器块会处理输入x,并应用因果掩码attn_mask(如果提供)。因果掩码确保模型在解码时只能看到当前及之前的位置,而不能看到未来的信息。
-
-
输出层:
-
self.fc(x):将解码器的输出x传递给线性层self.fc,生成最终的输出。输出的形状为(batch_size, seq_len, vocab_size),表示每个位置上每个词元的预测概率。
-
截止到本篇文章GPT简单复现完成,下面将附完整代码,方便理解代码整体结构
import math
import torch
import random
import torch.nn as nnfrom tqdm import tqdm
from torch.utils.data import Dataset, DataLoader'''
仿 nn.TransformerDecoderLayer 实现
'''class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_project = nn.Linear(d_model, d_model)self.k_project = nn.Linear(d_model, d_model)self.v_project = nn.Linear(d_model, d_model)self.o_project = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, attn_mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)atten_scores = Q @ K.transpose(2, 3) / math.sqrt(self.d_k)if attn_mask is not None:attn_mask = attn_mask.unsqueeze(1)atten_scores = atten_scores.masked_fill(attn_mask == 0, -1e9)atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ Vout = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)out = self.o_project(out)return self.dropout(out)class TransformerDecoderBlock(nn.Module):def __init__(self, d_model, dff, dropout):super().__init__()self.linear1 = nn.Linear(d_model, dff)self.activation = nn.GELU()# self.activation = nn.ReLU()self.dropout = nn .Dropout(dropout)self.linear2 = nn.Linear(dff, d_model)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)self.mha_block1 = MultiHeadAttention(d_model, num_heads, dropout)self.mha_block2 = MultiHeadAttention(d_model, num_heads, dropout)def forward(self, x, mask=None):x = self.norm1(x + self.dropout1(self.mha_block1(x, mask)))x = self.norm2(x + self.dropout2(self.mha_block2(x, mask)))x = self.norm3(self.linear2(self.dropout(self.activation(self.linear1(x)))))return xclass GPT(nn.Module):def __init__(self, vocab_size, d_model, seq_len, N_blocks, dff, dropout):super().__init__()self.emb = nn.Embedding(vocab_size, d_model)self.pos = nn.Embedding(seq_len, d_model)self.layers = nn.ModuleList([TransformerDecoderBlock(d_model, dff, dropout)for i in range(N_blocks)])self.fc = nn.Linear(d_model, vocab_size)def forward(self, x, attn_mask=None):emb = self.emb(x)pos = self.pos(torch.arange(x.shape[1]))x = emb + posfor layer in self.layers:x = layer(x, attn_mask)return self.fc(x)def read_data(file, num=1000):with open(file, "r", encoding="utf-8") as f:data = f.read().strip().split("\n")res = [line[:24] for line in data[:num]]return resdef tokenize(corpus):vocab = {"[PAD]": 0, "[UNK]": 1, "[BOS]": 2, "[EOS]": 3, ",": 4, "。": 5, "?": 6}for line in corpus:for token in line:vocab.setdefault(token, len(vocab))idx2word = list(vocab)return vocab, idx2wordclass Tokenizer:def __init__(self, vocab, idx2word):self.vocab = vocabself.idx2word = idx2worddef encode(self, text):ids = [self.token2id(token) for token in text]return idsdef decode(self, ids):tokens = [self.id2token(id) for id in ids]return tokensdef id2token(self, id):token = self.idx2word[id]return tokendef token2id(self, token):id = self.vocab.get(token, self.vocab["[UNK]"])return idclass Poetry(Dataset):def __init__(self, poetries, tokenizer: Tokenizer):self.poetries = poetriesself.tokenizer = tokenizerself.pad_id = self.tokenizer.vocab["[PAD]"]self.bos_id = self.tokenizer.vocab["[BOS]"]self.eos_id = self.tokenizer.vocab["[EOS]"]def __len__(self):return len(self.poetries)def __getitem__(self, idx):poetry = self.poetries[idx]poetry_ids = self.tokenizer.encode(poetry)input_ids = torch.tensor([self.bos_id] + poetry_ids)input_msk = causal_mask(input_ids)label_ids = torch.tensor(poetry_ids + [self.eos_id])return {"input_ids": input_ids,"input_msk": input_msk,"label_ids": label_ids}def causal_mask(x):mask = torch.triu(torch.ones(x.shape[0], x.shape[0]), diagonal=1) == 0return maskdef generate_poetry(method="greedy", top_k=5):model.eval()with torch.no_grad():input_ids = torch.tensor(vocab["[BOS]"]).view(1, -1)while input_ids.shape[1] < seq_len:output = model(input_ids, None)probabilities = torch.softmax(output[:, -1, :], dim=-1)if method == "greedy":next_token_id = torch.argmax(probabilities, dim=-1)elif method == "top_k":top_k_probs, top_k_indices = torch.topk(probabilities[0], top_k)next_token_id = top_k_indices[torch.multinomial(top_k_probs, 1)]if next_token_id == vocab["[EOS]"]:breakinput_ids = torch.cat([input_ids, next_token_id.view(1, 1)], dim=1)return input_ids.squeeze()if __name__ == "__main__":file = "/Users/azen/Desktop/llm/LLM-FullTime/dataset/text-generation/poetry_data.txt"poetries = read_data(file, num=2000)vocab, idx2word = tokenize(poetries)tokenizer = Tokenizer(vocab, idx2word)trainset = Poetry(poetries, tokenizer)batch_size = 16trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True)d_model = 512seq_len = 25 # 有特殊标记符num_heads = 8dropout = 0.1dff = 4*d_modelN_blocks = 2model = GPT(len(vocab), d_model, seq_len, N_blocks, dff, dropout)lr = 1e-4optim = torch.optim.Adam(model.parameters(), lr=lr)loss_fn = nn.CrossEntropyLoss()epochs = 100for epoch in range(epochs):for batch in tqdm(trainloader, desc="Training"):batch_input_ids = batch["input_ids"]batch_input_msk = batch["input_msk"]batch_label_ids = batch["label_ids"]output = model(batch_input_ids, batch_input_msk)loss = loss_fn(output.view(-1, len(vocab)), batch_label_ids.view(-1))loss.backward()optim.step()optim.zero_grad()print("Epoch: {}, Loss: {}".format(epoch, loss))res = generate_poetry(method="top_k")text = tokenizer.decode(res)print("".join(text))pass