做网站建网站廊坊今日头条新闻
1.预训练阶段是否已经接近极限?
预训练阶段的数据扩展虽然已经取得了一定成果,但仍有提升空间。未来,优化方向将转向后训练阶段,尤其是利用强化学习(RL)来进一步挖掘模型潜力。强化学习可以通过交互和策略优化,弥补数据增长的局限性。
2.在预训练中文本数据还是多模态数据更容易达到极限?
对于纯语言模型,文本数据的规模和质量是关键,但多模态数据(如图片、视频)的增长空间尚未达到极限。多模态数据需要更复杂的数据处理,但其潜力巨大。理想情况下,多模态模型应同时具备数据理解和高质量生成的能力。
3.强化学习之前的后训练阶段通常使用什么方法?
后训练阶段主要采用监督微调(SFT)和直接偏好优化(DPO)。SFT通过标注数据提升模型对话和指令遵循能力,而DPO则进一步优化模型输出。这些方法虽然有效,但对模型性能的提升有限。
4.现在的强化学习与之前的RLHF有什么区别?
当前的强化学习更依赖于客观的“黄金标准”奖励,例如判断任务是否完成(如代码是否正确)。这种奖励机制更可靠,允许更长时间的训练。相比之下,RLHF依赖于人类标注的偏好数据,更适合处理主观性任务。
5.后训练阶段使用的强化学习是什么类型?
后训练阶段主要使用基于策略的强化学习,如PPO。这些方法易于扩展,适合大规模训练。同时,后训练阶段的强化学习多为无模型(model-free)方法,结合一定的off-policy特性,以提高数据利用效率。
6.post-training通常有哪些算法?
当前主流的后训练方法包括监督微调、基于人类反馈的强化学习(RLHF)、直接偏好优化(DPO)、专家迭代(EI)以及它们的变体(例如:RLAIF、PPO、ORPO、)。然而,后训练方法在LLM部署之前增加了一个相当复杂的过程。
7.不以RLHF这种方式进行post-traing对齐,还有啥方法?
直接回答:可以使用Best-of-N策略来实现,即对于每个提示生成N个响应,并根据评估响应适用性的奖励模型选择最佳响应。该方法既易于理解又易于实现,且几乎不需要超参数:响应数量N是唯一的超参数,可以在推理时动态调整。相比RLHF或DPO等后训练技术相对比较简单,它避免了潜在复杂的微调步骤,从而方便了预训练或指令微调语言模型的部署。
8.文本类回答问题也适合用强化学习进行后训练?
文本类回答问题的后训练通常依赖于基于人类反馈的强化学习(RLHF),因为文本质量的评估往往带有主观性。然而,如果能够开发出复杂的评估机制,直接优化文本生成也是可能的。
9.强化学习是否提高了训练成本和对GPU的需求?
强化学习并未显著降低训练成本,反而可能增加对GPU的需求。这是因为强化学习需要生成和验证大量样本,导致计算成本上升。例如,在数学题生成中,模型需要生成答案并验证其正确性,这一过程被称为“rollout”。
10.什么是推理扩展定律?
推理扩展定律表明,延长模型的推理时间可以显著提升其性能。模型通过更长时间的思考和自我修正,能够生成更准确的答案。然而,这种提升需要根据任务类型进行权衡。
11.说一下Long-COT和Short-COT以及Long2Short?
Long-COT指模型在推理过程中使用非常长的输出,而Short-COT则尝试将输出压缩到更短的长度,同时保持正确性。Long2Short的目标是在保证正确性的前提下,优化模型的推理效率,避免不必要的冗余。
12.如何将模型从长推理优化为短推理?
实现Long2Short的方法包括:
-
模型合并:将长推理模型和短推理模型合并,得到中等长度的输出。
-
长度惩罚:在强化学习中引入长度惩罚,平衡推理长度和准确率。
-
最短数据筛选:从长模型的正确输出中筛选最短的推理路径作为训练数据。
-
直接偏好优化:通过强化学习直接优化短推理过程。
13.通过强化学习提升推理能力是否比单纯增加模型参数更有效?
强化学习可以通过优化推理过程提升模型性能,而不仅仅是依赖模型规模的扩大。小模型通过增加推理长度也能接近大模型的性能,这表明推理优化是一种有效的替代方案。
14.解释长上下文扩展?
长上下文扩展是指将模型的上下文窗口扩展到更长的长度(如128k),以提升性能。为了提高训练效率,可以采用部分展开(partial rollouts)和分段生成的方法,避免从头生成带来的高成本。此外,还可以通过提前检测重复内容来优化生成过程。
15.说一下你在训练RL中的一些有趣的现象
在生成过程中,模型可能会表现出类似人类思考的行为,例如在输出中出现“等一下”、“让我再反思一下”等词汇,甚至在生成答案时表现出“信心十足”的状态。这些现象表明模型在推理过程中可能模拟了人类的思考过程。
16.强化学习的基本概念解释一下?
强化学习(Reinforcement Learning, RL)是机器学习的一个子领域,旨在通过智能体与环境的互动,学习一种最优的行为模式,以实现累积奖励的最大化。其核心在于通过试错和反馈机制,找到每个情境下的最佳决策路径。强化学习的优化目标是通过策略选择最大化累积奖励。具体而言,智能体需要找到一个最优策略 pi,使其在各个状态下的累积回报达到最大值。这一过程可以通过价值函数(Value Function)或动作价值函数(Q函数)来形式化描述。
17.LLM中的RL怎么理解?
如下图
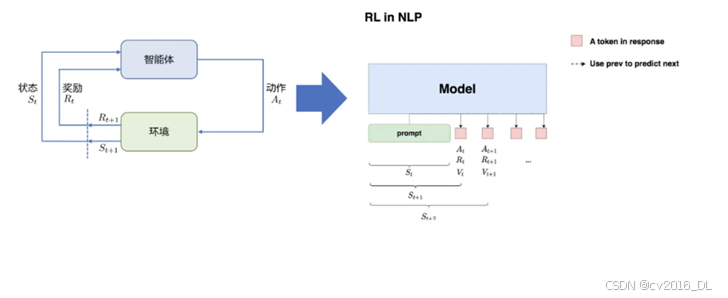
将强化学习与大语言模型的结合理解如下:
-
状态(State, S)
-
定义:状态是输入的prompt(提示或问题),即用户提供的文本输入。
-
作用:状态是智能体(LLM)需要处理的信息,决定了其下一步的决策(生成响应)。
-
动作(Action, A)
-
定义:动作是LLM的输出response(响应),即模型生成的下一个token(或一段文本)。
-
作用:动作是模型在当前状态下做出的决策,决定了生成内容的质量和方向。
-
奖励(Reward, R)
-
定义:奖励是根据prompt + response的组合,由奖励模型(Reward Model, RM)给出的评分。
-
作用:奖励信号用于衡量生成内容的质量,指导模型调整策略以生成更好的内容。
-
整体目标
-
目标:给定一个prompt,通过调整策略(policy)来生成符合人类偏好的response。
-
人类偏好:通过奖励模型(RM)的偏序信号(preference signal)来体现,即模型需要学习如何生成人类认为“更好”的内容。
18.通过 RL 探索LLM训练有哪些优势?
将强化学习整合到 LLM 的训练流程中的一个显著好处是其固有的增强泛化能力和处理分布外场景的能力。
-
广泛探索输出空间:
与在固定目标响应集上训练模型的监督微调不同,RL 强调探索。在训练过程中,模型通过采样和策略梯度更新接触到广泛的输出。这种探索使模型能够学习到可能响应的整个分布——而不仅仅是单一的“正确”答案。通过遇到多条轨迹,模型了解了什么是高奖励序列,什么是次优序列。 -
学习相对优势:
RL 方法为每条轨迹计算一个优势估计,这本质上是一个相对衡量,比较一个序列比平均结果好多少。这种相对比较帮助模型更有效地在序列的不同部分分配信用。即使基础模型最初产生了一个平庸的回应,RL 阶段的探索也可以发现产生更高奖励的替代轨迹。这些发现随后得到强化,提高了策略的整体质量。 -
对新输入的鲁棒性:
当模型仅通过监督学习进行训练时,它可能会对训练数据过拟合。相比之下,RL 中固有的探索意味着模型会定期接触到各种输入和输出。这种接触使它能够构建语言及其细微差别的丰富表示。因此,模型更有能力处理分布外的情况,并泛化到新的、未见过的提示。它不仅知道“最佳”轨迹,还知道周围可能回应的范围。 -
通过探索改进:
通常是在探索阶段,模型发现了比监督数据集中看到的更好的轨迹。即使 SFT 阶段提供了强大的基线,RL 也可以通过探索替代方案并从奖励的相对差异中学习来进一步优化模型的策略。这种持续的优化过程最终导致性能和鲁棒性的提升。
本质上,将 RL 整合到 LLM 训练中使模型能够超越简单地模仿人类策划的例子。它学习了一个更全面的输出空间视图,捕捉了高奖励轨迹以及不太优轨迹的结构。这种更丰富的理解促进了更好的泛化、更强的适应性和对新输入的更稳健响应。
19.强化学习包含哪些关键要素?
强化学习问题通常被建模为一个马尔可夫决策过程(Markov Decision Process, MDP),包含以下关键要素:
-
状态(State, S):智能体所处的环境状态,可以是游戏画面的一帧或机器人传感器的数据。
-
动作(Action, A):智能体在特定状态下可以执行的操作。
-
状态转移(Transition Dynamics, P):从当前状态 ( s ) 执行动作 ( a ) 后,转移到下一个状态 ( s' ) 的概率。
-
奖励(Reward, R):智能体在每个时刻获得的即时回报,反映了动作在当前状态下的优劣。
-
折扣因子(Discount Factor, γ):用于平衡当前奖励与未来奖励的重要性,取值范围通常为 ( (0, 1] )。
20.强化学习的两个关键特征?
首先,它依赖于持续的试错过程来发现最优行为;其次,它必须处理延迟回报的问题。这使得RL与监督学习在评价模型的方式上有显著不同:
-
监督学习:模型根据已知的正确答案获得即时反馈,学习过程直接针对减少预测误差。
-
强化学习:智能体通过与环境的互动来评估其行为,只有通过累积奖励的评估,才能确定策略的有效性。换句话说,监督学习使用已知的正确答案指导学习,而强化学习则让智能体通过不断的尝试和观察反馈,基于累积奖励调整策略,逐步找到最优解。
21.马尔可夫过程有哪些性质?
马尔可夫性质表明,一个系统的未来状态仅取决于其当前状态和采取的行动,而与之前的历史状态无关。这意味着我们可以通过当前状态来完全描述环境。
22.经典RL算法的分类说一下?
强化学习算法可以根据不同的标准进行分类,主要以下几种分类方式:
-
基于模型的(Model-Based) 和 无模型的(Model-Free):
-
基于模型的:这类算法依赖于对环境的模型来进行决策。它们通常使用动态规划或树搜索等方法。给定模型的例子包括AlphaGo/AlphaZero、I2A、World Model和MuZero。
-
无模型的:这类算法不依赖于环境模型,而是直接从与环境的交互中学习。它们进一步分为基于价值的、基于策略的和基于梯度的算法。
-
-
基于价值的(Value-Based) 和 基于策略的(Policy-Based):
-
基于价值的:这类算法通过学习状态的价值函数或动作价值函数来进行决策。包括在线策略(如Sarsa)和离线策略(如Q-Learning、DQN、Double DQN、Dueling DQN)。
-
基于策略的:这类算法直接学习一个策略函数,该函数映射状态到动作。包括无梯度的(如进化策略、DDPG、SAC)和基于梯度的(如Policy Gradient、TRPO/PPO、ACKTR)。
-
-
在线策略(On-Policy) 和 离线策略(Off-Policy):
-
在线策略:这些算法使用当前策略生成的数据来更新策略。例子包括Sarsa。
-
离线策略:这些算法可以使用其他策略生成的数据来更新当前策略。例子包括Q-Learning、DQN等。
-
-
交叉熵方法(Entropy Methods):
-
这类方法通过最大化策略的熵来鼓励探索,例子包括QT-Opt。
-
-
赌博机(Bandit) 和 梯度赌博机方法(Gradient Bandit Methods):
-
赌博机:这类问题通常涉及在不确定性下做出决策,没有状态或动作的概念。
-
梯度赌博机方法:这类算法使用梯度信息来优化决策,例子包括Policy Gradient、TRPO/PPO、ACKTR。
-
23.优势函数与值函数、动作值函数的关系是什么?
优势函数(A)与值函数(V)和动作值函数(Q)之间的关系是:优势函数是 Q 函数和 V 函数的差值。
具体区别如下:
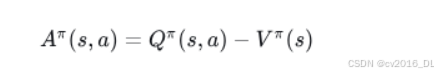
-
值函数(V):衡量一个状态的价值,反映了智能体在该状态下根据当前策略所能期望获得的总回报。
-
动作值函数(Q):衡量在某个状态下采取某个动作后,智能体所能期望获得的总回报。
-
优势函数(A):用于评估某个动作相对于平均策略的回报增益,是一个动作对比的度量。
24.估计值函数的三种常见方法有哪些?
在强化学习中,估计值函数是关键步骤,常见的三种方法包括:
-
蒙特卡洛方法(MC):通过完整的轨迹采样来估计值函数。
-
时间差分方法(TD):利用部分轨迹信息进行估计。
-
广义优势估计(GAE):结合了蒙特卡洛和时间差分方法的优点,通过折中偏差和方差来提高估计的稳定性和效率。
25.从偏差角度总结下估计值函数的三种方法?
1.MC方法
-
高方差:由于依赖完整的Episode回报,更新值可能受到随机因素的较大影响。
-
无偏性:直接使用实际累积回报进行更新,确保了长期的准确性。
-
2.TD方法
-
低方差:利用每一步的即时奖励进行更新,减少了因随机性导致的波动。
-
高偏差:依赖当前估计值进行更新,容易引入偏差,尤其是初始估计不准确时。
-
3.GAE方法
-
折中性:通过调整参数 ( \lambda ),GAE方法可以在偏差和方差之间灵活权衡。
-
平衡性:当 ( \lambda ) 接近0时,更接近TD方法,具有低方差;当 ( \lambda ) 接近1时,更接近MC方法,具有无偏性。
总结
-
MC方法适合奖励信号密集且环境随机性较小的场景。
-
TD方法适合需要快速更新且对实时性要求较高的场景。
-
GAE方法则是一种更通用的解决方案,适用于需要在偏差和方差之间灵活权衡的场景。
26.蒙特卡洛方法的优缺点是什么?
优点:
-
无需模型假设,直接基于实际回报进行学习。
-
长期来看是无偏的,因为直接利用实际累积奖励,确保了期望值的准确性。
缺点:
-
方差较大:由于仅依赖每个回合的最终回报,估计值可能波动较大。
-
当奖励信号稀疏或变化频繁时,估计的方差会进一步增大。
27.时间差分方法的优缺点是什么?
优点
-
方差小:TD方法基于每一步的即时奖励进行更新,不依赖于完整的Episode回报,因此可以在更短的时间内完成估计,方差较小。
-
支持在线学习:TD方法不需要等待完整的Episode结束即可进行学习,适合实时更新和在线调整。
缺点
-
偏差大:TD方法使用估计值而非真实回报进行更新,容易引入偏差。特别是它依赖当前的估计值来更新后续的值,如果初始估计有偏差,后续更新也会继承这种偏差。
28.广义优势估计(GAE)是什么?
广义优势估计(GAE)是一种折中方法,结合了蒙特卡洛(MC)和时间差分(TD)方法的优点。它通过引入超参数 ( \lambda )(类似于TD中的折扣因子),在计算优势函数时利用TD方法的部分信息,而不是完全依赖于真实的回报。GAE通过对TD误差进行加权平均来估计优势函数,从而减少单步TD误差带来的偏差,并控制方差的大小。计算公式如下:
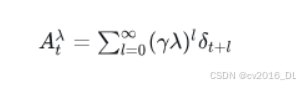
29.广义优势估计(GAE)的优缺点是什么?
优点:
-
在方差和偏差之间取得了更好的平衡,通过调整 ( \lambda ) 参数,可以灵活控制两者之间的权衡。
缺点:
-
相比纯粹的TD或MC方法,GAE需要更多的计算资源,因为它需要在每一步计算加权的TD误差。
30.强化学习中的on-policy和off-policy有什么区别?
在强化学习中,on-policy和off-policy的主要区别在于数据采样的策略是否与学习的策略一致:
-
On-policy:
-
数据采样策略与正在学习的策略相同。
-
智能体的行为策略与目标策略一致。
-
智能体在环境中的行为完全符合要学习的策略。
-
-
Off-policy:
-
数据采样策略可以与学习的目标策略不同。
-
可以用一种行为策略与环境交互,收集的数据用于学习另一种目标策略。
-
常见做法是使用经验回放池(Replay Buffer),允许历史数据被重复利用,而不必完全按照当前策略采样。
-
31.为什么要区分on-policy和off-policy?
-
策略分布一致性:
-
强化学习的目标是学习最优策略或评估某条策略的价值。如果数据来自与目标策略不同的分布,则需要额外的技术(如重要性采样)来确保学习的正确性。
-
-
数据效率:
-
On-policy方法通常“采样-训练-丢弃”,数据无法重复利用;而off-policy方法可以通过经验回放等方式重复利用数据,提高数据效率。
-
-
安全性与可控性:
-
在某些场景中,需要在策略稳定前保证系统的安全性。off-policy方法可以通过保守的行为策略收集数据,同时学习更激进的目标策略。
-
32.说一下on-policy和off-policy的代表性算法?
在线策略(On-Policy)代表算法:
-
PPO(Proximal Policy Optimization)
-
A2C/A3C(Advantage Actor-Critic)
离线策略(Off-Policy)代表算法:
-
Q-Learning
-
DQN(Deep Q-Network)
-
SAC(Soft Actor-Critic)
-
TD3(Twin Delayed Deep Deterministic Policy Gradient)
33.说一下on-policy和off-policy的优缺点?
On-policy
-
优点: 可以严格保证策略分布和数据分布一致,使得收敛性更易分析。
-
缺点: 数据利用率低,一旦策略更新,旧数据就难以重复使用,因为它们不再代表当前策略。
Off-policy
-
优点: 可以重复使用历史数据,样本效率更高。
可以从人类示教数据或其他智能体的轨迹中学习。 -
缺点: 策略与数据分布不一致带来的复杂性,可能更难保证收敛。
更新过程中更容易出现分布偏移(Distribution Shift)问题。
34.强化学习中的online和offline有什么区别?
在线强化学习(Online Reinforcement Learning)和离线强化学习(Offline Reinforcement Learning)是强化学习领域的两种不同学习范式,它们的主要区别在于如何使用经验数据(即智能体与环境交互产生的状态、动作、奖励序列)来训练模型。
35.on/off-policy和online/offline的区别是什么?
-
不同维度:
-
On/off-policy解决的问题是“采样策略”与“目标策略”的一致程度。
-
Online/offline解决的问题是“是否可以持续交互收集新数据”。
-
-
常见组合:
-
离线强化学习基本一定是off-policy,但在线强化学习可以既有on-policy,也可以有off-policy。
-
36.重要性采样的基本原理是什么?
重要性采样是一种统计方法,用于在目标分布 ( p ) 与采样分布 ( q ) 不一致的情况下,调整采样结果的权重,使得从 ( q ) 中采样的数据可以用于估计 ( p ) 的期望。
37.重要性采样的作用是什么?
重要性采样允许我们使用与目标分布不同的采样分布,从而:
-
提高采样效率,尤其在较难采样的情况下;
-
在强化学习中,它允许我们基于旧策略生成的经验数据来优化新策略,而无需重新采样环境数据。
38.REINFORCE和PPO的区别和联系是什么?
1.更新机制
-
REINFORCE:
-
在整个轨迹(episode)完成后,使用这次采样得到的数据进行一次性更新。
-
仅依赖单次采样的数据来进行学习。
-
-
PPO:
-
可以重复利用同一批采样数据进行多次更新。
-
通过截断(clipping)或KL散度(Kullback-Leibler divergence)惩罚来限制每次更新的幅度。
-
2.稳定性与效率
-
REINFORCE:
-
算法实现简单,但存在高方差和低效率的问题。
-
由于仅使用单次采样的数据,估计可能不稳定,导致学习效率较低。
-
-
PPO:
-
通过限制策略更新的幅度,显著提高了算法的稳定性和收敛速度。
-
在保证收敛性和稳定性的同时,能够更充分地利用采样数据。
-
3.应用场景
-
REINFORCE:
-
常被视为最基础的策略梯度方法,适合用于讲解强化学习的原理。
-
由于其简单性,常被用作教学示例,但在实际应用中可能不是最优选择。
-
-
PPO:
-
在实践中更常见,因为它在保持收敛性和稳定性的同时,能够更高效地利用数据。
-
适用于需要高效利用数据和稳定训练的复杂强化学习任务。
-
总结
REINFORCE和PPO都是强化学习中重要的策略梯度方法,但它们在更新机制、稳定性和效率方面存在差异。REINFORCE作为一种基础方法,适合用于教学和原理讲解;而PPO则因其在实践中的优越性能,更常用于实际应用。选择合适的方法取决于具体的任务需求和应用场景。
38.介绍下DPO中的BT算法模型?
Bradley-Terry模型是一种用于分析成对比较数据的统计学方法,旨在评估多个项目之间偏好的相对可能性。
对于两个实体 i和 j,该模型计算实体 i 相较于实体 j 被优先选择的概率如下:
P(i>j) = exp(b1)/(exp(b1)+exp(b1))
在这个公式中:
-
b1和 b2 分别代表实体 i 和j 的隐性评分。
-
模型的基本假定是,选择的偏好概率完全基于这些隐性评分,并且这些评分遵循逻辑斯蒂分布。
39.BT模型的优缺点?
-
优点:
简单直观,易于理解和实现。
可以处理成对比较数据,适用于许多实际应用场景。 -
缺点:
假设所有比较都是独立的,这在实际中可能不总是成立。 对于能力相近的对象,模型的预测可能不够准确。
40.Reward Hacking是什么意思?
在强化学习中,由于奖励函数设置不合理,导致智能体只关注累积奖励,而没有朝着预想的目标优化,这种现象被称为Reward Hacking。
41.RLHF的整体流程是什么?
RLHF(基于人类反馈的强化学习)主要分为两个步骤:
-
奖励模型训练:通过人类标注的偏好数据训练奖励模型,使其能够评估模型输出的质量。
-
近端策略优化(PPO):利用奖励模型提供的奖励信号,对语言模型进行微调,优化其生成策略,使其更符合人类偏好。
42.RLHF中有哪些数据集?
RLHF中涉及三种数据集:
-
偏好数据集:用于训练奖励模型。
-
提示数据集:在PPO流程中用于训练语言模型。
-
评估数据集:用于评估RLHF的效果。
43.PPO中的四个模型及其作用是什么?
PPO涉及四个模型的协同训练和推理:
-
策略模型(Policy Model):生成模型的输出,是RLHF训练的最终目标模型。在PPO训练中更新梯度。
-
奖励模型(Reward Model):输出奖励分数,评估生成内容的质量。在PPO训练中不更新梯度。
-
评论模型(Critic Model):预测生成内容的价值,帮助选择最优行为。在PPO训练中更新梯度。
-
参考模型(Reference Model):提供一个备份模型,防止策略更新过于激进。在PPO训练中不更新梯度。
44.为什么需要训练奖励模型?
在强化学习中,直接使用人类标注的反馈数据来微调模型是低效的,因为人类很难为每次优化迭代提供足够的反馈。因此,训练一个奖励模型(RM)是一种更高效的方法,它可以通过模拟人类的评估过程,为模型训练提供持续的奖励信号。RM决定了智能体如何从与环境的交互中学习并优化策略,以实现预定目标。
45.奖励模型是怎么训练的?
奖励模型(RM)的训练流程包括:
-
收集偏好数据:使用初始模型生成多个回答,让人类标注者进行比较或打分,获取偏好数据。
-
对偶对比训练:奖励模型输出一个标量评分,通过对比不同回答的评分来训练模型。
-
模型结构:通常在预训练语言模型的基础上添加一个“Reward Head”,用于对文本输出打分。
-
使用场景:在强化学习阶段,奖励模型为生成的回答打分,作为奖励信号优化策略模型。
46.PPO的流程是什么?
PPO的实施流程包括:
-
环境采样:策略模型生成一系列输出,奖励模型对这些输出进行打分。
-
优势估计:利用评论模型预测生成输出的未来累积奖励,并通过广义优势估计(GAE)算法估计优势函数。
-
优化调整:根据优势函数优化策略模型,同时利用参考模型保持策略更新的稳定性。
47.Critic Model和Reward Model的区别是什么?
在RLHF中:
-
Reward Model:通过人类标注数据独立训练,输出反映人类偏好的奖励分数,用于评估生成内容的质量。
-
Critic Model:与策略模型同步更新,动态估算生成过程的价值或优势,帮助策略模型优化。前者提供外部评估信号,后者用于内部学习预测长期回报。
48.Rollout是什么意思?
“Rollout”是强化学习中的一个术语,表示从某个初始状态开始,按照当前策略逐步生成一个完整的行为序列(也称为一次实验或episode)。这一过程类似于将一张纸缓缓展开,把从当前策略得到的决策序列“铺”出来,以便后续评估整个序列的表现(如计算奖励、优势等),为策略优化提供样本数据。在RLHF-PPO中,“rollout”指的是利用当前策略模型在给定输入下生成一系列输出,并对这些输出进行评估的过程。
49.解释下对齐税(Alignment Tax)?
在利用强化学习进行人类反馈(RLHF)微调大型语言模型(LLM)时,虽然可以提升模型对人类指令的遵循度,但这种微调过程往往会带来一些副作用,比如导致模型输出的多样性和自然流畅性降低,这种现象有时被称为“对齐成本”(alignment tax)。在现实世界的应用中,模型的分布外泛化能力(即模型处理未见过的数据的能力)非常重要,而输出多样性则关系到模型能否生成内容丰富、风格多变的文本。
根据文献的研究结果,与监督式微调(SFT)相比,RLHF在处理新的、未知的输入时展现出更好的泛化能力,特别是在训练数据和测试数据分布不一致时。但是,研究也发现RLHF在多个评价标准下都显著降低了输出的多样性。这表明目前的LLM微调技术在提高泛化能力和保持输出多样性之间需要做出权衡。
换句话说,虽然RLHF微调可以增强模型对人类反馈的适应性,但这可能会以牺牲模型生成多样化文本的能力为代价。这一发现提示我们在实际应用中需要仔细考虑微调的目标和期望的模型行为,以找到最佳的平衡点。
参考论文:Understanding the effects of rlhf on llm generalisation and diversity
50.PPO的痛点是什么?
PPO在算法和工程实现上存在以下痛点:
-
算法痛点:调参困难,不容易训练出好的结果。
-
工程实现痛点:涉及多阶段的数据加载(如prompt和rollout、训练),actor模型的自回归生成过程,以及多个模型的推理和训练。
51.介绍下DPO算法的原理?
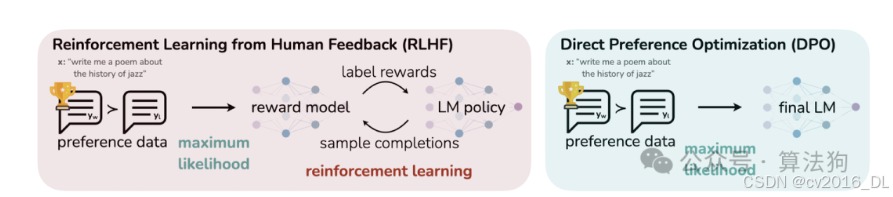
DPO的核心机制:通过提升受青睐样本的对数似然和降低不受青睐样本的对数似然来实现。它利用动态加权策略,防止了仅依赖概率比目标时可能出现的模型性能下降问题。
在优化人类偏好方面,DPO不采用强化学习方法。传统的RLHF算法一般首先训练一个奖励模型来匹配提示和人类偏好的响应对数据集,然后利用强化学习来寻找能够最大化该奖励模型的策略。与此不同,DPO直接针对简单的分类目标进行优化,以找到最能满足偏好的策略,通过拟合一个隐式奖励模型,其最优策略可以通过闭式解直接获得。
51.DPO和SFT有什么相同点和不同点?
DPO和SFT是两种优化大型语言模型的方法,目的都是提升文本生成质量,以更好地满足人类偏好。以下是它们之间的异同:
共同点:
-
两者都通过调整模型参数来优化输出,使其符合目标或偏好。
-
都利用外部数据来引导模型的优化过程,DPO用偏好数据,SFT用标注数据。
不同点:
-
数据类型与处理方式:
-
DPO直接使用偏好数据优化,偏好数据体现为样本对比,无需构建奖励模型。它通过用户偏好直接优化策略,让模型学习受欢迎的输出。
-
SFT依赖标注的输入-输出对,输出是理想响应或文本。这类似于监督学习,通过正确答案调整模型以减少误差。
-
-
优化目标与过程:
-
DPO关注在偏好数据下优化策略表现,通过对比学习直接优化策略,省去奖励函数建模。
-
SFT目标是使输出匹配标签数据,通常通过最大化似然或最小化交叉熵损失来优化,是直接的监督学习。
-
-
复杂度与灵活性:
-
DPO在处理复杂或非结构化偏好数据时可能更有优势,因为它通过比较学习,不依赖精确评分。
-
SFT在有明确答案或标准输出的任务中更有效,但在处理模糊或主观偏好时可能不如DPO灵活。
-
-
应用场景:
-
DPO适合偏好标准不易量化或可通过比较获得的场景,如艺术创作、个性化推荐。
-
SFT适合有明确正确答案的任务,如问答、翻译。
-
总之,DPO和SFT各有特点,选择哪种方法取决于任务需求、数据性质及对模型输出质量的要求。
52.DPO相比PPO有哪些改进?
在RLHF背景下,DPO(直接偏好优化)相比PPO有以下改进:
-
简化的训练流程。
-
对超参数更鲁棒。
-
提高了计算效率和效果。
-
扩展了应用范围和任务表现。
-
提高了模型解释性和对用户偏好的适应性。
-
改善了长期性能和稳定性。
53.写一下DPO算法的loss?
DPO(Direct Preference Optimization)的损失函数定义如下:
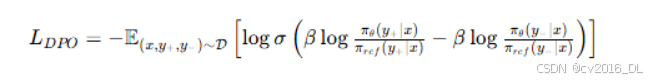
其中:
-
x 是输入的提示(prompt)。
-
y_+ 是被选中的回复(chosen response)。
-
y_- 是被拒绝的回复(rejection response)。
-
\beta 是缩放系数。。
DPO通过重参数化等效于具有隐式奖励模型的优化:
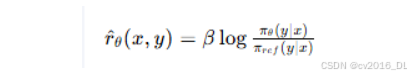
这种优化等价于在此变量更改下的奖励模型的优化。
54.能写出DPO算法的主要代码吗?
import torch.nn.functional as Fdef dpo_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, beta):"""计算直接偏好优化(Direct Preference Optimization, DPO)损失和奖励。该函数根据给定的策略模型对数概率(pi_logps)、参考模型对数概率(ref_logps)、优选完成索引(yw_idxs)、非优选完成索引(yl_idxs)以及控制KL惩罚强度的温度参数(beta),计算每对偏好的损失和奖励。参数:pi_logps (torch.Tensor): 策略模型的对数概率,形状为 (B,)。ref_logps (torch.Tensor): 参考模型的对数概率,形状为 (B,)。yw_idxs (torch.Tensor): 优选完成的索引,在 [0, B-1] 范围内,形状为 (T,)。yl_idxs (torch.Tensor): 非优选完成的索引,在 [0, B-1] 范围内,形状为 (T,)。beta (float): 控制KL惩罚强度的温度参数。返回值:losses (torch.Tensor): 每对偏好的DPO损失,形状为 (T,)。rewards (torch.Tensor): 每个样本的奖励,形状为 (B,)。每对 (yw_idxs[i], yl_idxs[i]) 表示一个偏好对的索引。函数计算策略和参考模型中优选和非优选完成的对数概率比率,然后使用逻辑函数计算DPO损失。奖励计算为策略和参考对数概率的差异,乘以温度参数beta。"""# 提取优选和非优选完成的对数概率pi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]# 计算优选和非优选完成的对数概率比率pi_logratios = pi_yw_logps - pi_yl_logpsref_logratios = ref_yw_logps - ref_yl_logps# 使用逻辑函数计算DPO损失losses = -F.logsigmoid(beta * (pi_logratios - ref_logratios))# 计算奖励为策略和参考对数概率的差异,乘以温度参数betarewards = beta * (pi_logps - ref_logps).detach()return losses, rewards55.DPO有哪些改进算法?
改进的IPO方法:由于DPO在人类偏好数据集上容易过拟合,谷歌DeepMind的研究者们提出了一种新的身份偏好优化(IPO)方法。IPO通过在DPO损失函数中加入正则项,有效防止了模型的过拟合,且无需依赖提前停止等技术即可实现模型的稳定收敛。
KTO方法:Kahneman-Tversky优化(KTO)是一种基于人类心理认知的偏好优化算法。它通过研究人类决策时的心理过程(例如注意力的分配和记忆的提取),来优化模型的输出结果。KTO的一个主要优势是它不需要成对的偏好数据,只需将样本标记为“优”或“劣”,这大大减少了数据收集的复杂性和成本。不过,如何精确模拟人类的心理认知过程,并将这些模拟结果有效应用于实际场景,仍是KTO面临的挑战。
56.说下DPO算法的优缺点?
优点:
-
直接使用人类偏好来优化。
-
不需要建立复杂的奖励模型。
-
适用于多种应用场景。
缺点:
-
可能会在小数据集上过拟合。
-
计算成本可能较高。
-
依赖高质量的偏好数据。
57.RL相比于SFT的好处有哪些?
强化学习(RL)在大型语言模型(LLM)的微调中相比有监督微调(SFT)具有一些显著的优势。以下是RL相对于SFT的具体作用和必要性:
-
整体影响的考虑
-
SFT:主要针对单个词元(token)进行反馈,目标是让模型对给定输入产生准确的输出。这种方法可能无法充分考虑到整个输出文本的上下文和整体质量。
-
RL:则针对整个输出文本进行反馈,不仅关注单个词元,而是评估整个文本的质量和效果。这种反馈方式有助于模型在保持表达多样性的同时,对文本中的微小变化保持敏感性。例如,自然语言中的一个否定词可能会完全改变句子的含义,RL可以通过奖励机制更好地捕捉这种细微差别。
2.解决幻觉问题
-
SFT:在模型不确定答案时,可能会促使模型给出一个不确定的答案,这可能导致“幻觉”(即模型生成不准确或不真实的信息)。
-
RL:可以通过设计奖励函数来解决这个问题。例如,可以设置奖励机制,使得正确答案获得高分数,放弃回答或回答“不知道”获得中等分数,而错误答案则获得负分。这样,模型在不确定时更倾向于选择不回答,从而减少幻觉的发生。
3.多轮对话的奖励累计
-
SFT:在多轮对话中,很难构建一个能够评估整个对话质量的奖励机制,因为SFT通常只关注单个回合的输出。
-
RL:则可以通过构建一个综合考虑整个对话背景和连贯性的奖励函数,来评估模型在多轮对话中的表现。这种方法可以更好地捕捉对话的整体质量和连贯性,从而提高模型在实际应用中的性能。
总结 RL在LLM微调中的必要性在于其能够提供一种更全面、更灵活的反馈机制,这有助于模型在处理复杂任务(如多轮对话、处理不确定性等)时表现出更好的性能。通过考虑整个输出文本、解决幻觉问题以及更好地处理多轮对话,RL为LLM的微调提供了一种更为有效和实用的方法。
希望这些解释能帮助你更好地理解为什么在某些情况下选择RL而不是SFT进行LLM的微调。如果你有任何进一步的问题或需要更多信息,请随时告诉我。
58.REINFORCE++的主要思想是什么?
REINFORCE++是一种增强版的REINFORCE算法,结合了PPO的关键优化技术,同时去除了对critic网络的依赖。REINFORCE++的核心目标是提高训练的简洁性和稳定性,同时降低计算开销。
59.简单说下GRPO算法?
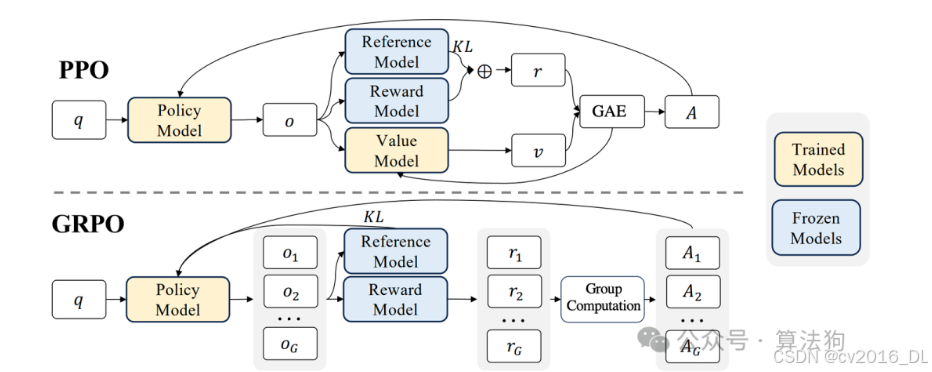
GRPO是PPO算法的改进版,并且是一种在线强化学习(online RL)方法。它用直接采样平均值的方法来取代PPO算法中使用的Critic模型,同时保留了PPO算法中的重要性采样(importance sampling)和截断(clipping)机制。在GRPO中,参考模型(Ref)和奖励模型(RM)是固定不变的,只有策略模型(Policy Model)需要被训练。
60.GRPO算法的目标函数?
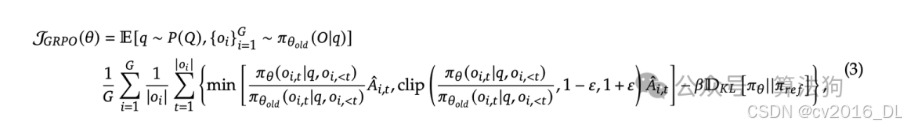
61.离散KL散度的推导过程你说一下?
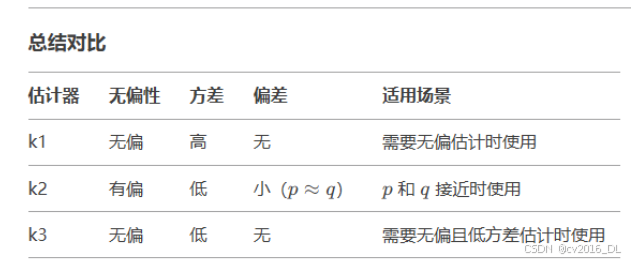
以下是 KL散度估计器 k1、k2、k3 的推导过程,包括它们的数学原理和构造思路。
1. KL散度的定义KL散度(Kullback-Leibler Divergence)的定义为:
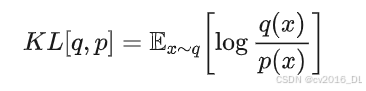

2. k1 估计器的推导原理k1 是 KL 散度的朴素蒙特卡洛估计器,直接基于 KL 散度的定义。
推导从 KL 散度的定义出发:
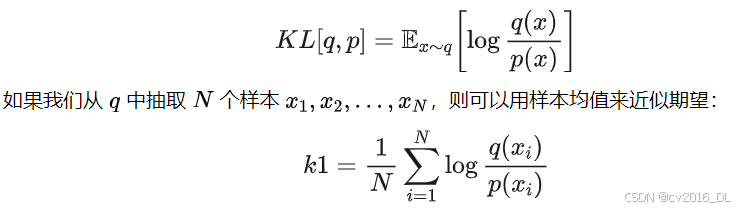
这是 k1 估计器的形式。
性质
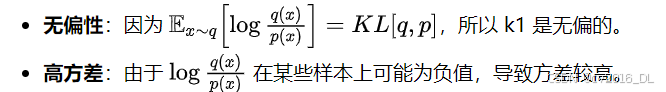
3. k2 估计器的推导原理k2 是基于二阶近似的估计器,利用了 KL 散度在 时的局部性质。
推导当 和 接近时,KL 散度可以近似为:

性质
-
低方差:k2 总是非负的,因此方差比 k1 低。
-
有偏性:k2 是 KL 散度的二阶近似,当 和 差异较大时,偏差会显著增加。
4. k3 估计器的推导原理k3 结合了 k1 和控制变量(control variate)的思想,通过引入一个修正项来降低方差,同时保持无偏性。
推导

5. 总结推导
-
k1:直接基于 KL 散度的定义,使用蒙特卡洛方法估计期望。
-
k2:利用 KL 散度在 时的二阶近似,构造一个低方差但有偏的估计器。
-
k3:通过控制变量法,构造一个无偏且低方差的估计器。
数学细节

通过以上推导,我们可以清晰地理解 k1、k2、k3 的构造原理及其优缺点。
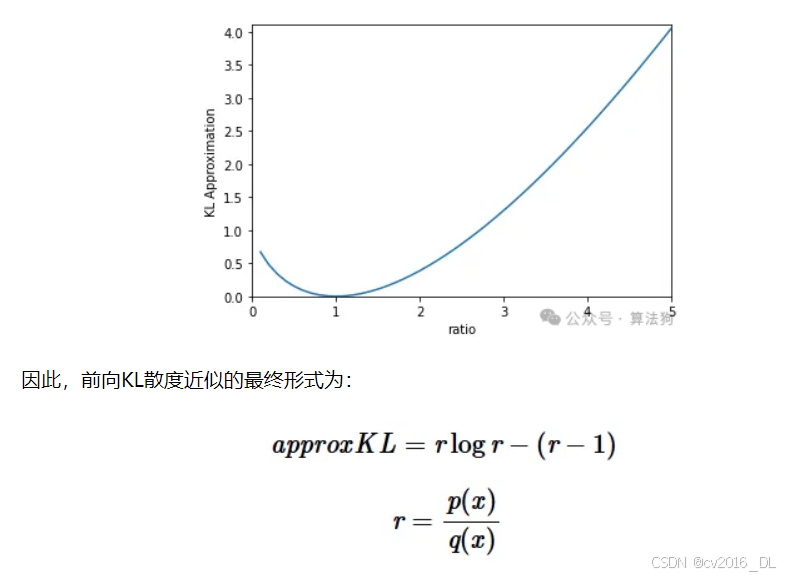
62.近似KL散度的计算
在本文中,我将讨论KL散度的样本近似方法。我会同时介绍前向KL散度和反向KL散度哈
为什么要进行近似?
-
没有解析解:KL散度的完整形式可能没有解析解。例如,高斯混合分布就是这种情况。
-
计算复杂度高:计算完整的KL散度通常需要对整个分布空间求和。使用不需要这样做的近似方法是有用的,因为它可能会更快。
近似的标准

直观上,近似应该与被近似的原始指标具有相似的行为。我们可以通过以下两种方式衡量这种相似性:
-
偏差:理想情况下,近似应该是无偏的,即近似的期望值应该等于原始指标。
-
方差:一个无偏的近似如果方差为0(即确定性的),将完全等于原始指标!当然,这是不现实的,但理想情况下方差应该尽可能低,从而增加获得接近原始指标值的可能性。
前向KL散度的近似
首先,我们回顾一下完整的解析形式:
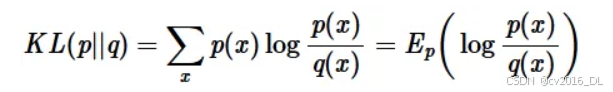
首先,我们考虑偏差的情况。我们希望:
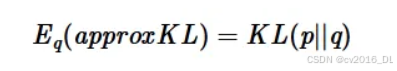
其中approxKL是我们想要得到的近似值。下面是一个解决方案:
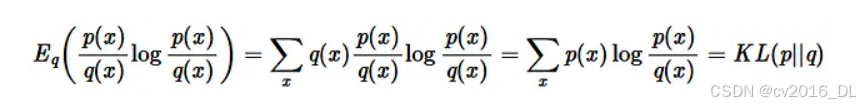 因此:
因此:
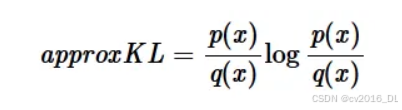
但这个近似的方差仍然很高,因为它可能取负值,而实际的KL散度不能。一种改进方法是添加一个期望值为0且与上述原始近似负相关的项。我们提出以下解决方案:
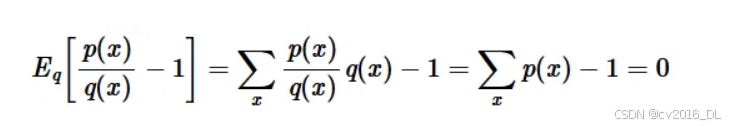

反向KL散度的近似
我们可以按照与前向KL散度相同的步骤来得到反向KL散度的近似值!
首先,我们回顾一下完整的解析形式:
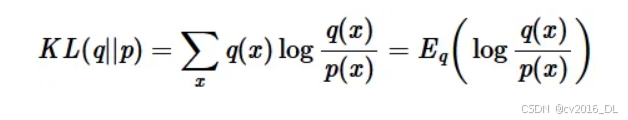
同样,我们首先需要获得一个简单的无偏近似;以下是一个解决方案:
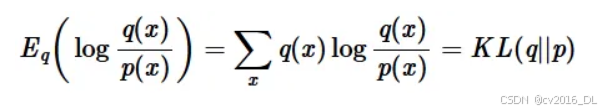
因此:
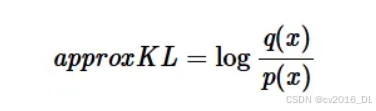
这与前向KL散度的无偏近似存在完全相同的问题:它可以取负值,从而导致方差很大。我们可以使用与上次相同的项来尝试抵消这种情况:
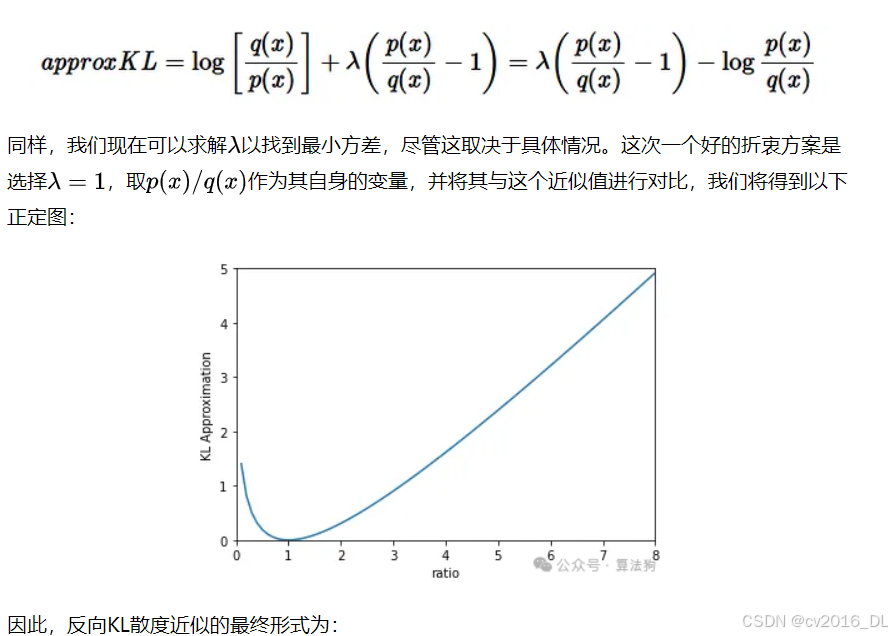
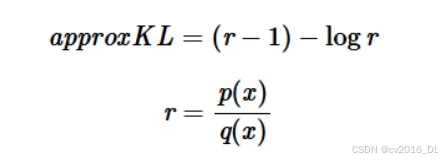
63.离散token的KL散度在ppo中怎么计算
我们都知道,在PPO算法中,更新Actor参数的时候,是需要算KL散度的,也就是计算actor输出的probs和参考模型的probs的概率分布之间的差异,我们希望差异越小越好。那么两个离散部分的KL散度是怎么计算的的,我们看openRLHF中的源码,如下:

64.离散token的KL散度在ppo中怎么计算
我们都知道,在PPO算法中,更新Actor参数的时候,是需要算KL散度的,也就是计算actor输出的probs和参考模型的probs的概率分布之间的差异,我们希望差异越小越好。那么两个离散部分的KL散度是怎么计算的的,我们看openRLHF中的源码,如下:

优点
-
无偏性:k1 是 KL 散度的无偏估计器,即 E[k1]=KL[q,p]。
-
简单直观:直接反映了 KL 散度的定义。
缺点
-
高方差:由于log(p/q) 在某些样本上可能为负值(尽管 KL 散度本身是非负的),导致估计器的方差较高。
-
不稳定性:当p(x)q(x)) 接近零时,log操作会变得非常大,导致估计不稳定。
K2
-
k2 估计器基于二阶近似,公式为:
-
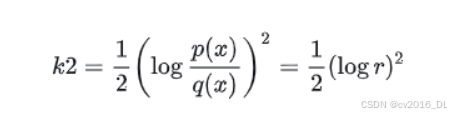
它通过平方对数比率来估计 KL 散度。
优点
-
低方差:k2 总是非负的,因此方差比 k1 低。
-
对分布接近时表现良好:当 p 和 q接近时,k2 的偏差非常小,因为它是 KL 散度的二阶近似。
缺点
-
有偏性:k2 是一个有偏估计器,尤其是在 p和 q 差异较大时,偏差会显著增加。
-
不适用于大差异分布:当p和 q差异较大时,k2 的偏差会导致估计不准确。
K3
-
k3 估计器结合了 k1 和控制变量(control variate)的思想,公式为:计算公式如下:
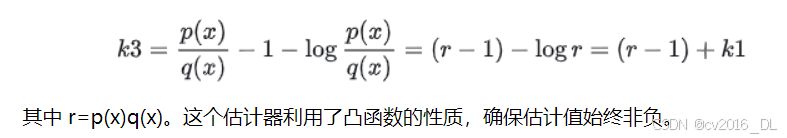
它通过平方对数比率来估计 KL 散度。
优点
-
低方差:k2 总是非负的,因此方差比 k1 低。
-
对分布接近时表现良好:当 p 和 q接近时,k2 的偏差非常小,因为它是 KL 散度的二阶近似。
缺点
-
有偏性:k2 是一个有偏估计器,尤其是在 p和 q 差异较大时,偏差会显著增加。
-
不适用于大差异分布:当p和 q差异较大时,k2 的偏差会导致估计不准确。
-
K3 k3 估计器结合了 k1 和控制变量(control variate)的思想,公式为:计算公式如下:
怎么用
-
如果 p 和 q 非常接近,且允许一定的偏差,可以使用 k2,因为它具有低方差。
-
如果需要无偏估计,且 p 和 q 差异较大,建议使用 k3,因为它兼具无偏性和低方差。
-
k1 适用于需要简单无偏估计的场景,但需要注意其高方差问题。
65.OPEN-RLHF中的PPO算法通过哪种方式计算KL散度的
目前来看,在open-RLHF中,计算KL散度的方式是通过k1的这种近似来做的,之前在我们的文章中也说到有3种近似的计算方式,这里就直接说k1这种近似的做法,那么其实现起来也很简答的,如下:
假设我们得到的log概率分布为log_probs和log_probs_base,分别表示actor和referencer模型的输出的概率分布,那么整个使用k1来近似计算KL散度的代码如下:
log_ratio = (log_probs.float() - log_probs_base.float()*mask
没了,就这么简单
66.为何大模型普遍训练1-2个epoch
大模型(如 GPT、BERT 等)通常只训练 1-2 个 epoch,这是出于以下几个核心原因:
-
数据量大,信息冗余
-
计算成本高,不经济
-
泛化能力优先于训练精度
-
随机采样、多任务训练等提升多样性
-
早停机制避免过拟合
详细解如下:
1. 数据量极大,不需要多轮遍历
-
数据规模巨大:大模型的训练数据通常是互联网规模的数据,动辄达到 TB 级别,遍历完整数据集 1 次(即 1 个 epoch)已经足够让模型学到足够多的信息。
-
数据冗余性高:大数据集本身信息量丰富,很多数据之间存在重复或高度相似的内容,多次遍历对模型的增益效果有限。
理论依据:
在大数据集下,随机梯度下降(SGD)及其变种(如 Adam)在一次 epoch 内通常能捕捉到数据分布的主导模式。再多遍历反而会导致 过拟合。
2. 训练成本过高,计算资源限制
-
模型参数庞大:大模型(如 GPT-3,175B 参数)训练一次 epoch 需要消耗极其巨大的计算资源,再进行多次 epoch 会成倍增加计算成本。
-
时间限制:即便使用最先进的 GPU/TPU 集群,训练大模型 1 个 epoch 都需要耗费数周甚至更长时间,多次遍历数据的时间成本非常高。
平衡点:
在模型效果和计算资源之间做平衡,1-2 个 epoch 的训练已经能达到一个合理的性能水平,继续增加 epoch 收益递减。
3. 过拟合风险与泛化能力考虑
-
过拟合风险增加:数据规模大时,1-2 个 epoch 已经足够学习数据分布的主要模式。多轮遍历容易使模型过拟合,尤其是模型规模巨大的情况下。
-
目标是泛化能力:大语言模型的目标是提升 泛化能力,即使面对新任务或数据也能做出合理的推断。多次遍历相同数据反而可能导致模型“记忆”数据,而不是提炼通用模式。
启发自早期研究:
在 ImageNet 等计算机视觉任务中,也观察到随着 epoch 增加,模型性能在训练集上提升,但泛化能力却不一定增强,甚至下降。
4. 随机采样 + 大批量数据等效多次 epoch
-
随机采样策略:大模型的训练过程中使用 随机批量(mini-batch)训练,每次从数据集中采样不同的子集进行更新,相当于对整个数据集进行了多次随机的遍历。
-
数据增强 + 多任务训练:结合多任务目标、数据增强和动态 Masking 等手段,即使只训练 1-2 个 epoch,也能起到类似多轮训练的效果。
变相增加数据多样性:
这些策略有效地提升了数据的多样性,从而弥补了少轮遍历带来的潜在不足。
5. 早停机制与过早饱和现象
-
早停(Early Stopping)机制:大模型通常采用早停策略,当验证集的损失不再明显下降时,就停止训练,避免不必要的计算浪费。
-
学习效率高:大模型由于参数量巨大,对于大规模数据的学习效率非常高,早期阶段就能捕捉到数据的主导特征。
理论基础:
现代优化方法(如 Adam、Adafactor)能在较少 epoch 内迅速收敛到较优的解。
6. 预训练 + 微调机制
-
预训练只需 1-2 个 epoch:大模型的预训练通常只进行 1-2 个 epoch,因为目标是学习通用表示,并不需要完全拟合数据。
-
微调阶段更敏感:在特定任务上的微调可能只需要更少的 epoch 来进行适配。
Transfer Learning 逻辑:
微调阶段的数据通常比预训练数据少得多,更适合多轮遍历来提升效果。
相关论文
-
GPT-3: Language Models are Few-Shot Learners (2020)在论文中说“We trained for a total of 300 billion tokens over 1 epoch with a batch size of 3.2 million tokens.”
-
T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (2020)在论文中说“We observe that increasing the number of pre-training epochs beyond 1 did not significantly improve downstream task performance.”
-
Scaling Laws for Neural Language Models (2020)在论文中说“For any given compute budget, the optimal performance is achieved by training for a single epoch over a sufficiently large dataset, rather than training for multiple epochs over a smaller dataset.”
-
RoBERTa: A Robustly Optimized BERT Pretraining Approach (2019)在论文中说“We trained for 1 epoch over 160GB of text with larger batch sizes, showing that increasing the amount of data was more effective than increasing the number of training epochs.”
简单总结 现在预训练的数据量都很大,搞那么多epoch没啥用,反而容易过拟合,且效率低下,使用少量epoch学习到数据变化的模式有助于提升泛化性,且那么多的数据预训练后足够保证foundation models有较好的输出能力,后续在特定领域搞的话就sft
67.为什么RLHF中,PPO需要Critic模型而不是直接使用RewardModel
这两个模型,一个是预测奖励值,也就reward,一个是预测value,其中
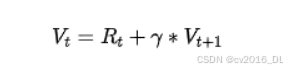
模型结构
其中reward的代码如下

其中critic的结构如下

两个模型在定义的时候参数基本是一样的,但是在forward的时候就有区分了,我们先看reward模型的forward
last_hidden_states = outputs["last_hidden_state"]
values = getattr(self, self.value_head_prefix)(last_hidden_states).squeeze(-1)
reward = values.gather(dim=1, index=eos_indices).squeeze(1)
首先取出来last_hidden_states,然后使用上面定义的一个Linear层进行转换,然后gather取eos对应位置的值。
那对于critic模型呢,我们看其forward函数如下
values = getattr(self, self.value_head_prefix)(last_hidden_states).squeeze(-1)
if self.normalize_reward:
values = (values - self.mean) / self.std
action_values = values[:, -num_actions:]
前面的计算和reward虽然有点像,但是这里取得是action后面的值,其可不就是一个值了,而是一个长度为num_action的vector.
内在原因
引入Critic模型的核心目的在于充当一个价值评估器,对状态或状态动作对的价值进行估计,而且是估计状态或状态动作对的长期价值,也就是状态值函数或动作值函数,进而辅助策略的更新与优化过程。它能够学习并预测在当前状态下采取不同动作所获得的累积奖励情况,从而为策略的改进提供方向指引
奖励模型虽然能够为每个状态或状态动作对提供即时的奖励信号,但它无法直接给出价值估计。即时奖励信号仅能反映当前动作的短期反馈情况,而无法涵盖长期时间尺度上的价值信息。
68.为何大模型非RLHF不可
监督微调(SFT, Supervised Fine-Tuning)和基于人类反馈的强化学习(RLHF, Reinforcement Learning from Human Feedback)是大语言模型(LLM)训练流程中的两个关键阶段。虽然SFT能初步对齐模型与人类意图,但RLHF是进一步提升模型输出质量、安全性和可控性的必要步骤。
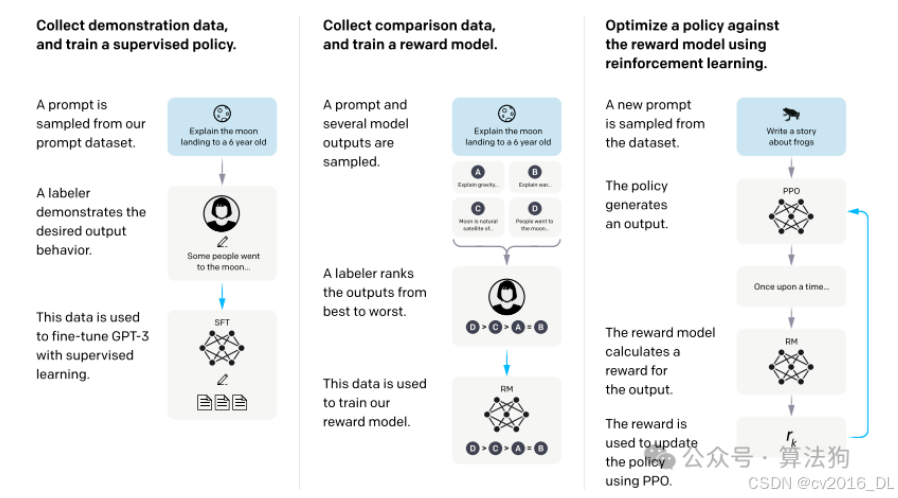
首先呢,SFT操作存在一下问题:
-
SFT主要使用人工标注的数据进行监督训练,但数据量有限且固定,且模型容易过拟合;
-
SFT的主要思路还是模仿标注数据,在面对开放问题时难以有很好的表现;
-
缺乏对好坏的区分 SFT模型可能同时学会正确回答和错误回答,但无法主动避免后者。
-
人类偏好往往是多维度的(如事实准确性 vs 流畅性,创意性 vs 安全性),SFT难以通过单一损失函数捕捉这些权衡。
因此就需要RLHF来对齐人类偏好数据了,其中RLHF通过引入人类对模型输出的偏好反馈(如排序或评分),让模型学习更符合人类价值观的行为:
-
通过人类对多个输出的对比(如A比B更好),RLHF能学习隐式的、多维度的评价标准(例如:减少有害内容、提高信息密度)。例如:对同一问题,人类可能偏好简短准确的回答而非冗长重复的回答,RLHF能捕捉这种偏好。
-
RLHF通过强化学习(如PPO算法)持续调整模型,使其在“探索-利用”中找到更优输出,而非简单模仿SFT数据。 例如:模型学会主动避免低质量输出(如胡言乱语、政治不正确等)。
整体上总结如下:SFT是“模仿”,RLHF是“优化”:
-
SFT让模型学会“如何回答”,RLHF让模型学会“如何回答得更好”。
-
二者结合是大模型对齐人类意图的黄金标准(如ChatGPT、Claude等均采用此流程)。
其次,RLHF也验证了有效性,如下所示:
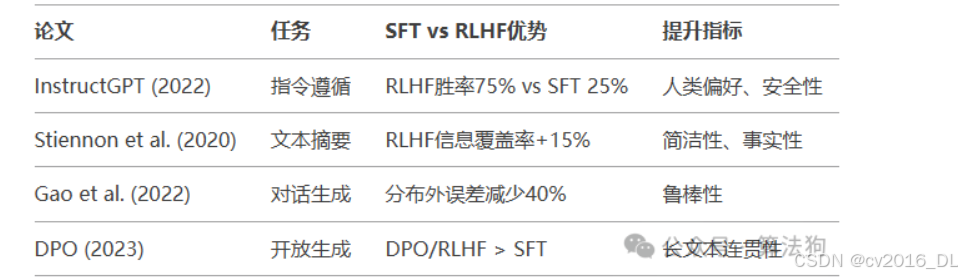
可以看到使用RLHF后模型的效果有很大的提升,也证明了其必要性。
69.大模型开始训练初期的Loss大概是多少
回答:在大模型(如GPT、LLaMA等)的初始化训练阶段,初始损失值(loss)通常接近理论上的“随机猜测”损失,具体数值取决于模型架构、词表大小和损失函数类型。
若使用交叉熵损失(Cross-Entropy Loss),模型参数初始化后,对每个token的预测接近均匀分布。假设词表大小为 ( V ),初始损失的理论值为:
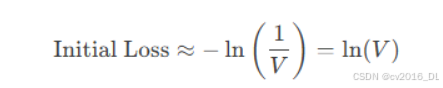
如:词表大小 V = 50,000 → 初始损失约 10.82(因为 ln(50,000) = 10.82 。 实际中可能略低(因参数初始化并非完全均匀)。
GPT-3、LLaMA等模型的训练日志中,初始损失通常接近理论值,但可能因以下因素略有差异:
-
参数初始化方式(如正态分布、Xavier初始化)。
-
输入数据分布(如长尾词频)。
-
损失计算细节(如是否屏蔽padding tokens)。
例如:
-
GPT-3(词表50,257)的初始损失约 10.5~11.0。
-
较小模型(如GPT-2)可能观察到 6~7(词表较小,约40,000)。
影响因素
-
词表大小:词表越大,初始损失越高(因为ln(V)增大)。
-
初始化方法:某些方法(如残差连接后的缩放)可能略微降低初始损失。
-
数据预处理:对输入数据的归一化或分词方式会影响初始输出分布。
下面写一个代码来验证一下
import torch
import torch.nn.functional as Fvocab_size = 50000
logits = torch.randn(1, vocab_size) # 模拟随机初始化输出
target = torch.randint(0, vocab_size, (1,)) # 随机目标token
loss = F.cross_entropy(logits, target)
print(loss.item()) # 输出应接近 ln(50000) ≈ 10.8270.PPO算法中的actor和critic学习率为啥不一样?
在研究RLHF(Reinforcement Learning from Human Feedback)源码时,我注意到一个设置,起初一直不太明白其原因。经过查阅资料和整理,现总结如下:
在强化学习领域,尤其是采用Actor-Critic算法时,通常会将Actor(策略网络)和Critic(价值网络)的学习率设置为不同的数值,这种差异是由它们在算法中所承担的不同角色以及训练过程中的动态特性所决定的。以下是具体分析:
1. 任务差异导致敏感性不同
-
Actor(策略网络)
其主要职责是直接输出动作(或动作的概率分布),从而直接决定智能体的行为表现。-
策略更新较为敏感:Actor的参数发生小幅变化,就可能使动作分布产生显著的改变。因此,为了防止策略出现剧烈震荡甚至崩溃,需要为其设置较低的学习率(例如
5e-7)。 -
若Actor的学习率过高,很容易导致策略快速陷入局部最优,甚至出现策略退化的情况。
-
-
Critic(价值网络)
它的作用是估计状态或状态-动作的价值(如V值或Q值),为Actor提供梯度方向的指导。-
价值函数更新相对稳定:Critic的目标是拟合一个标量值(而非直接控制动作),所以对参数变化的鲁棒性更强。因此,可以为其设置较大学习率(例如
9e-6),以加快其收敛速度。 -
如果Critic的学习率过低,那么它可能无法及时提供准确的梯度信号,进而拖慢Actor的训练进程。
-
2. 梯度幅度存在差异
-
Actor的梯度通常是基于策略梯度定理计算得出的(例如REINFORCE算法中的梯度,或者PPO算法中的近似梯度),其幅度会受到回报(或优势函数)方差的较大影响,往往较小且不够稳定。
-
Critic的梯度则是来源于价值函数的均方误差(MSE),其梯度幅度通常较大且相对稳定。
-
学习率需与梯度幅度相匹配:鉴于Critic的梯度较大,需要较高的学习率来实现快速收敛;而Actor的梯度较小,为了防止出现过度调整的情况,需要较低的学习率。
3. 算法设计的经验规律
-
常见算法的默认设置:在许多强化学习算法的论文和实际实现中(例如OpenAI的PPO算法),Critic的学习率通常比Actor的学习率高 1~2个数量级。例如:
-
Actor学习率设置为
3e-4,Critic学习率设置为1e-3(这是一种常见的初始设置)。 -
你所采用的设置(
5e-7vs9e-6)也符合这一规律,只是学习率的绝对值相对较小(这可能是因为针对的是更复杂的任务或者更大的模型)。
-
-
更新速度的平衡:Critic需要快速收敛,以便为Actor提供稳定的价值估计;而Actor则需要谨慎地进行更新,以避免策略出现退化。
4. 具体场景下的影响
-
任务复杂度:在奖励较为稀疏或者状态空间维度较高的任务中,Critic可能需要更高的学习率,以便能够快速地学习到价值函数。
-
网络架构:如果Critic网络的深度或宽度大于Actor网络,可能需要对学习率进行调整,以补偿梯度传播过程中的差异。
-
探索与利用的平衡:Actor的低学习率有助于稳定地进行探索,而Critic的高学习率则可以加速利用过程。
学习率调整方法
-
监控训练曲线:
-
如果观察到Actor的损失值出现剧烈震荡,那么应该考虑降低其学习率。
-
如果Critic的损失值下降速度过慢,可以适当提高其学习率。
-
-
保持比例关系:一般来说,Critic的学习率应约为Actor学习率的 10~100倍。
-
采用自动化方法:可以使用自适应优化器(如Adam)或者学习率调度器(如LR Scheduler)来动态地调整学习率。
总结你的学习率设置(5e-7 vs 9e-6)是合理的,主要基于以下几点原因:
-
Actor需要谨慎地进行更新,以确保策略的稳定性;而Critic需要快速收敛。
-
两者的梯度幅度以及任务敏感性存在差异。
-
这种设置符合算法设计的经验性规律。
如果在训练过程中发现系统不稳定,可以尝试缩小两者学习率的差距(例如将Actor学习率调整为 1e-6,Critic学习率调整为 5e-6),但要确保Critic的学习率仍然显著高于Actor。
71.你想过为什么交叉熵log是以e为底而不是2为底
之前可能大家太忙了,平时也没有想到一些基本的运算,那么在大型语言模型(LLM)的训练中,交叉熵损失函数的对数计算通常使用自然对数(以 e 为底,即 ln ),而非以 2 为底的对数。以下是关键点解析:
-
数学一致性
-
交叉熵的原始定义基于自然对数
-
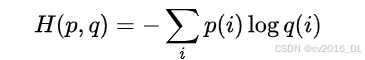


72.为什么计算重要性参数用log相减后再exp而不是直接除
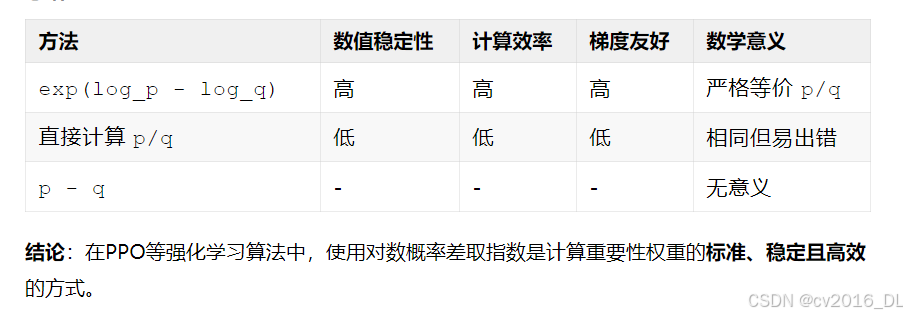
在强化学习(如PPO)中,使用 torch.exp(token_log_probs - old_log_probs) 计算重要性权重,而不是直接使用概率值(probs / old_probs),原因如下:
1. 数值稳定性
-
概率值(probs)可能非常小:
在语言模型中,词表通常很大(如50k+ token),每个token的概率可能极小(如1e-5)。直接计算probs / old_probs会导致数值下溢(接近0)或溢出(分母接近0时无穷大)。 -
对数概率(log_probs)更稳定:
通过log_probs - old_log_probs并在最后取指数,等价于exp(log(p) - log(q)) = p/q,但避免了中间过程的数值问题。
例子:
-
若
p = 1e-5,q = 1e-6,直接计算p/q = 10。 -
但
log(p) = -11.51,log(q) = -13.82,则exp(-11.51 - (-13.82)) = exp(2.31) ≈ 10,结果相同但更稳定。
2. 计算效率
-
深度学习框架的优化:
log_softmax和log_prob是PyTorch/TensorFlow中的原生操作,直接输出对数概率,比先计算概率再取对数更高效(避免重复计算)。 -
避免冗余转换:
模型最后一层通常输出logits,直接计算log_softmax比先算softmax再log更高效。
3. 梯度计算
-
对数概率的梯度更友好:
在反向传播时,对数概率的梯度计算(如log_prob.backward())比概率的梯度更数值稳定,尤其是概率接近0时。 -
概率的梯度可能爆炸:
若probs接近0,其梯度1/probs会变得极大,导致训练不稳定。
4. 数学一致性
-
对数空间的操作是标准做法:
概率的乘法在对数空间变为加法(log(p*q) = log(p) + log(q)),这在序列生成(如逐token采样)中非常关键。 -
KL散度等指标依赖对数概率:
许多RLHF相关指标(如KL惩罚)直接使用对数概率计算,保持一致性。
5. 为什么不能直接用 probs - old_probs?
-
减法无概率意义:
probs - old_probs是两个概率的差值,无法表示重要性权重(需比值p/q)。 -
不满足重要性采样的数学定义:
重要性采样要求权重是概率密度比(即p/q),而非差值。
代码示例对比
# 正确做法(稳定且高效)
log_ratio = token_log_probs - old_log_probs
ratio = torch.exp(log_ratio) # 等价于 (probs / old_probs)# 错误做法(数值不稳定)
probs = torch.softmax(logits, dim=-1)
old_probs = torch.softmax(old_logits, dim=-1)
ratio = probs / old_probs # 可能溢出或下溢总结
73.model.generate如何强制让结果等长
回答如下: 强制忽略 eos_token_id 并固定长度(不推荐自然性会下降):
outputs = model.generate(
...,
eos_token_id=None, # 禁用结束符
max_new_tokens=50, # 固定生成 exactly 50 token
early_stopping=False
)
其实,在 model.generate() 中,生成的输出 默认会自动填充(padding)到相同的长度,以确保返回的张量是一个规整的矩阵(batch_size × sequence_length)。但实际有效内容(非填充部分)的长度可能不同,具体取决于生成过程是否遇到 eos_token_id 或其他终止条件。
-
其它:
-
自动填充对齐长度
-
无论生成的句子实际长度如何,
generate()会通过pad_token_id将所有输出填充到 当前 batch 中最长序列的长度(或max_length如果指定)。 -
例如:如果 batch 中一个句子生成了 10 个 token,另一个生成了 15 个 token,则第一个句子会被填充 5 个
pad_token_id。
-
-
实际内容长度可能不同
-
生成过程中,如果某个序列提前遇到
eos_token_id,其有效内容会终止,但依然会被填充到最大长度。 -
可通过
attention_mask区分有效 token 和填充部分(attention_mask=1为有效,=0为填充)。
-
-
控制对齐行为的参数
-
pad_token_id:必须提供,否则无法填充。 -
max_length:如果设置,所有序列会被填充或截断到该长度。 -
attention_mask:在生成时用于忽略输入部分的填充,但输出仍会统一填充。
-
-
来个代码:
-
outputs = model.generate(
prompt_ids,
attention_mask=prompt_mask,
max_new_tokens=50, # 最大生成长度
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
# 输出的形状是 (batch_size, max_length_in_batch)
print(outputs.shape)
# 检查实际长度(排除填充部分)
real_lengths = (outputs != tokenizer.pad_token_id).sum(dim=-1)
print(real_lengths) # 各句子的实际 token 数可能不同
74.PPO算法到底是on-policy还是off-policy
PPO(Proximal Policy Optimization)本质上是 on-policy 算法,但通过一些技巧(如重要性采样和经验回放)部分借鉴了 off-policy 的思想,使其在实践中有一定的灵活性。以下是详细分析:
核心结论
-
PPO 的原始设计是 on-policy:因为它要求使用当前策略(current policy)与环境交互收集的数据进行更新,且数据不能重复使用(传统 on-policy 的特点)。
-
通过重要性采样(Importance Sampling)引入了 off-policy 的特性:允许用旧策略(old policy)的数据进行多次梯度更新,但会通过裁剪(clipping)或惩罚(KL penalty)限制更新幅度,避免偏离原始数据分布太远。
因此,PPO 可以看作 “大部分 on-policy,小部分 off-policy” 的混合方法。
关键概念解析
(1) On-policy 的特点
-
数据必须来自当前策略:每次策略更新后,旧数据立即失效,需重新采样(如原始 TRPO、REINFORCE)。
-
优点:理论收敛性好,数据分布与当前策略一致。
-
缺点:样本效率低(大量数据仅用一次)。
(2) Off-policy 的特点
-
可使用历史策略的数据(如 DQN、SAC)。
-
优点:样本效率高,支持经验回放(replay buffer)。
-
缺点:需处理分布偏移(distribution shift),通常需重要性采样或约束更新。
PPO 的混合特性PPO 通过以下设计平衡了 on-policy 和 off-policy 的特性:
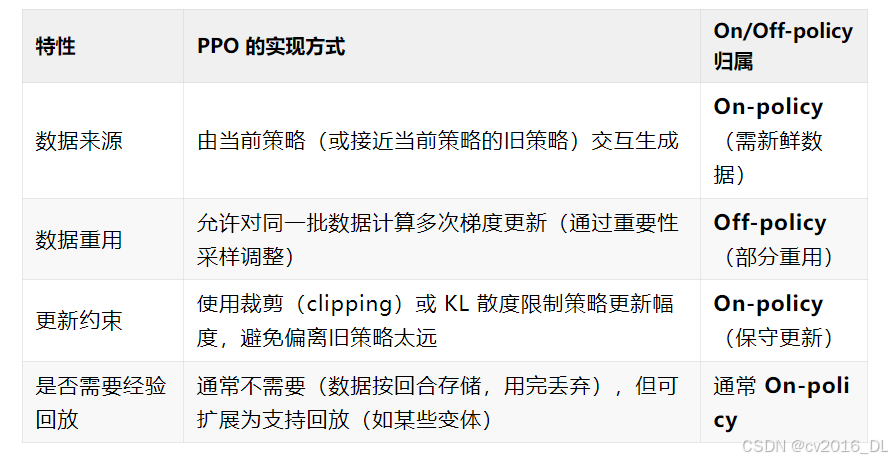
75.为什么说 PPO 主要是 On-policy?
-
数据时效性要求高:PPO 虽然允许少量数据重用(如 3-10 次梯度更新),但长期依赖旧数据会导致性能下降(需重新采样)。
-
更新约束严格:裁剪或 KL 惩罚本质是强制策略保持接近数据收集时的分布(类似 on-policy 的保守性)。
-
对比典型 Off-policy 算法(如 SAC、DQN):
-
PPO 不能直接使用任意历史数据(如 replay buffer 中的旧数据)。
-
SAC/DQN 可完全解耦数据收集和策略更新。
-
总结
76.PPO算法中新旧策略的关系是什么?
在PPO(Proximal Policy Optimization)中,新策略(当前策略) 和 旧策略(行为策略) 的关系是通过交替执行数据收集与策略更新来实现的,具体流程如下:
1. 数据收集阶段(旧策略生成数据)
-
旧策略(Behavior Policy):


简单回答 PPO通过交替执行数据收集(旧策略)和策略优化(新策略),利用重要性采样和裁剪机制,在保持On-Policy稳定性的同时,实现了有限的数据重用。这一设计是其高效性和鲁棒性的核心。
77.PPO中完全重用旧数据会有哪些问题?理论分析下
在强化学习(尤其是PPO这类策略梯度方法)中,完全重用旧数据会导致训练不稳定甚至失败,核心原因在于策略分布偏移(Policy Distribution Shift)和重要性权重方差爆炸(Importance Weight Variance Explosion)。下面展开详细分析:

3. 方差爆炸的后果
(1) 梯度更新不稳定
-
少数高权重样本主导梯度方向,其他样本被忽视,模型陷入局部最优。
-
极端权重导致梯度值爆炸(如从正常0.1突变为50),引发数值溢出或参数剧烈波动。
(2) 策略崩溃(Policy Collapse)
-
新策略可能过度优化某些高权重动作,忽视全局探索,最终退化(如重复执行单一动作)。
-
经典现象:在机器人控制中,策略突然“抽搐”;在对话生成中,输出重复无意义的句子
78.如何解决PPO算法中方差大和训练策略不稳定的现象?
简单回答:重要性权重裁剪和KL散度来约束
下面是详细解答
为避免上述问题,PPO通过以下方法约束策略更新:


79.解释一下PPO算法重要性采样的原理
PPO(Proximal Policy Optimization)算法中重要性采样(Importance Sampling)的核心原理是利用旧策略的数据来估计新策略的期望回报,从而避免每次策略更新后都需要重新采样数据。其是一种在概率分布不同时估计期望值的方法。在强化学习中:

80.从偏差角度总结下估计值函数的三种方法
-
MC方法
-
高方差:由于依赖完整的Episode回报,更新值可能受到随机因素的较大影响。
-
无偏性:直接使用实际累积回报进行更新,确保了长期的准确性。
-
TD方法
-
低方差:利用每一步的即时奖励进行更新,减少了因随机性导致的波动。
-
高偏差:依赖当前估计值进行更新,容易引入偏差,尤其是初始估计不准确时。

总结
-
MC方法适合奖励信号密集且环境随机性较小的场景。
-
TD方法适合需要快速更新且对实时性要求较高的场景。
-
GAE方法则是一种更通用的解决方案,适用于需要在偏差和方差之间灵活权衡的场景。
81.解释下GRPO的基本原理?
当然可以,以下是对原表述的重新组织,以保持原意但用不同的字面表达:
GRPO的基本原理是通过在组内进行归一化处理来替代PPO中的价值评估模型,以此减少计算资源的需求。具体操作步骤如下:

82.DPO属于off-policy还是on-policy呢?
DPO属于一种off-policy算法,其训练所用的pair数据并非必须来源于ref policy或sft policy。它的一大优点是无需对模型进行采样及标注,可直接利用现有的数据集开展训练,从而节省了采样和标注环节的成本。不过,它的缺点在于效果难以确保,当模型自身能力与发布的pair数据不匹配时,问题尤为突出。而PPO是on-policy算法,通常情况下整体效果要比DPO更胜一筹。
83.DPO算法第0步的loss是什么?


84.PPO中使用reward存在哪些问题?
在PPO(Proximal Policy Optimization)算法中使用奖励模型(Reward Model)时,可能会遇到以下典型问题,这些问题可能影响策略优化的效果和稳定性:
问题
-
奖励模型的偏差(Bias):如果奖励模型的训练数据分布与实际策略生成的数据分布不一致,奖励模型可能无法准确评估新策略生成的样本,导致偏差。比如在文本生成任务中,模型可能生成符合奖励模型偏好但语义不通的文本。
-
奖励稀疏性与信用分配问题:当奖励信号稀疏或延迟时(如仅在任务完成时给予奖励),奖励模型可能难以提供细粒度的反馈,导致信用分配困难。
-
奖励欺骗(Reward Hacking):策略通过“欺骗”奖励模型获得高奖励,而非真正完成任务。这是RLHF中的常见问题。比如机器人可能找到绕过奖励计算规则的方式(如反复触发高奖励动作但无实际意义)。
-
奖励模型的非平稳性:在在线学习或迭代训练中,策略分布不断变化,导致奖励模型的评估标准失效(分布漂移)。最显然可以看到而得是策略优化过程中出现剧烈波动或崩溃。
-
奖励尺度问题:奖励模型的输出范围不稳定(如过大或过小),影响PPO的梯度更新。比如策略更新步长不合理,导致训练不稳定。
-
多目标冲突:当奖励模型需要平衡多个目标(如效率、安全性)时,可能难以合理分配权重。这样策略过度优化某个子目标而忽略其他。
-
训练-测试环境差异:奖励模型在训练环境中表现良好,但在真实环境中失效(Sim2Real问题)。
优化方向
-
奖励模型的正则化:防止过拟合。
-
动态更新奖励模型:适应策略分布变化。
-
多模型集成:减少单一模型的偏差。
-
人工干预:定期验证策略行为并调整奖励。
通过系统性地分析这些问题,可以更好地设计奖励模型和调整PPO的训练流程,从而提高策略的鲁棒性和性能。
85.RL中on/off line以及on/off policy的区别和联系
可能说到每个具体的概念大家都能回答出来,但是一下子这么多概念比较起来的话,可能你一下子真的回答不出来。
那么,来个灵魂3问...
是不是认为“Online=On-policy,Offline=Off-policy”。 是不是认为“Offline RL只能做Off-policy”。
是不是认为“Off-policy一定优于On-policy”。
带着问题,我们来分析下这个面试题哈...
在强化学习(Reinforcement Learning, RL)中,Online vs Offline 和 On-policy vs Off-policy 是两组不同的分类维度,分别关注数据收集方式和策略更新方式。以下是它们的核心区别与联系:
**1. Online vs Offline(1) Online(在线学习)
-
定义:智能体实时与环境交互,边收集数据边更新策略。
-
特点:
-
数据通过当前策略(或探索策略)动态生成。
-
需要与环境持续交互(例如游戏、机器人控制)。
-
典型算法:DQN、PPO(在线版本)、A3C。
-
-
优势:适应动态环境,数据分布与当前策略一致。
-
挑战:交互成本高,可能存在探索-利用权衡问题。
(2) Offline(离线学习)
-
定义:智能体使用预先收集的静态数据集(不与环境交互)进行策略学习。
-
特点:
-
数据来自历史记录或其他策略(如专家演示)。
-
适用于高风险或高成本场景(如医疗、自动驾驶)。
-
典型算法:BCQ、CQL、TD3-BC。
-
-
优势:安全、低成本,可直接利用现有数据。
-
挑战:数据分布偏移(Distribution Shift),需处理策略与数据分布的不匹配。
2. On-policy vs Off-policy(1) On-policy(同策略)
-
定义:使用当前策略生成的数据来更新该策略。
-
特点:
-
数据必须由当前策略的最新版本生成。
-
策略更新后,旧数据立即失效。
-
典型算法:SARSA、TRPO、PPO(严格来说属于on-policy)。
-
-
优势:数据与当前策略一致,理论收敛性较强。
-
挑战:数据利用率低,需频繁重新采样。
(2) Off-policy(异策略)
-
定义:使用其他策略(如旧策略、探索策略)生成的数据来更新目标策略。
-
特点:
-
支持经验回放(Replay Buffer),可复用历史数据。
-
数据与当前策略可以无关。
-
典型算法:Q-learning、DDPG、SAC。
-
-
优势:数据利用率高,适合稀疏奖励场景。
-
挑战:可能引入偏差(例如Q-learning的过估计问题)。
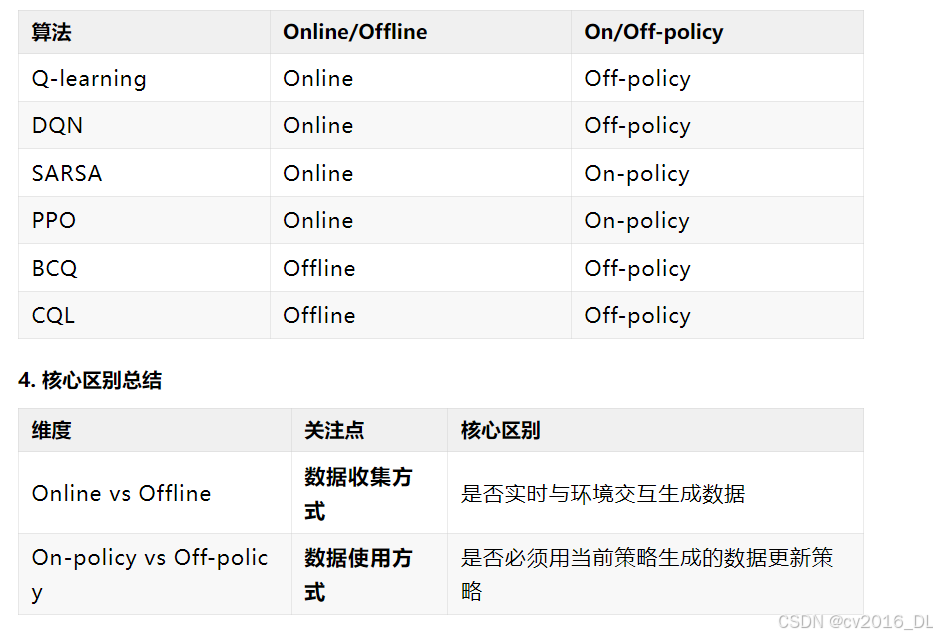
3. 两组概念的关系与组合(1) 交叉组合的可能性
-
Online + On-policy:
实时交互并仅用当前策略的数据更新(如PPO、A3C)。 -
Online + Off-policy:
实时交互但用历史数据更新(如DQN使用经验回放)。 -
Offline + Off-policy:
最常见组合,使用静态数据集更新策略(如BCQ、CQL)。 -
Offline + On-policy:
理论上可能(例如用静态数据中的当前策略旧版本数据更新),但实际中几乎不存在,因为离线数据通常非当前策略生成。
(2) 典型算法分类
86.如何看待一大堆算法号称性能超越PPO这一现象?
首先,PPO(Proximal Policy Optimization)是强化学习中的经典算法,特别是在与RLHF(基于人类反馈的强化学习)结合时,用于微调大语言模型(LLM)。但PPO存在一些问题,比如训练不稳定、计算成本高、需要同时维护多个模型(策略模型、价值模型、参考模型)等。因此,研究者们提出了各种替代算法,试图解决这些问题,并声称在性能、效率或稳定性上有所提升。
接下来需要逐个了解这些替代算法:
-
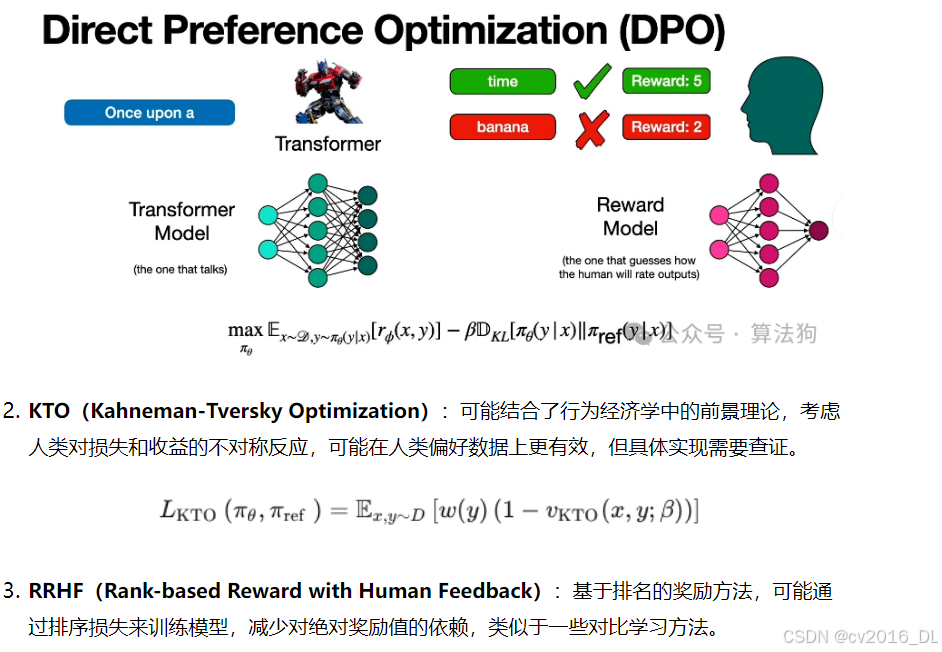
DPO(Direct Preference Optimization):直接利用偏好数据优化策略,绕过显式的奖励建模。DPO通过将奖励函数隐式地融入策略优化中,减少了训练复杂性。这可能避免了奖励模型的偏差问题,同时简化了训练流程。

对其性能超越PPO的可信度分析:
(1) 理论合理性
-
DPO、ORPO等算法通过数学推导证明了与PPO目标的等价性或改进,理论上具备潜力。
-
部分方法(如KTO)引入心理学理论,可能更贴合人类偏好特性。
(2) 实验证据
-
多数论文在特定任务(如对话生成、文本摘要)上报告了更高的胜率或更低的数据需求。需注意:实验通常在小规模模型(如1B参数)上进行,结论是否适用于大模型(如100B+)尚待验证。
-
评估指标(如人工评分、自动指标)可能存在偏差,需关注跨数据集的泛化性。
(3) 工程实践
-
PPO的成熟实现(如TRL库)经过大量优化,而新算法的开源支持较少,实际效果可能因实现细节差异而波动。
-
新方法可能简化训练流程,但引入新的超参数(如对比温度系数)需调优。
conclusion, RLHF的核心挑战包括高质量人类偏好数据的获取、奖励模型的泛化能力、策略优化的稳定性等。替代算法可能在某个环节改进,但未必全面解决所有问题。例如,DPO虽然不需要奖励模型,但对偏好数据的质量和分布可能更敏感。
87.分析一下RLHF的替代算法的局限性
这里就说了几个替代算法(DPO、KTO、RRHF、SLIC等)的局限与挑战哈,没有说的很全,主要从4个方面来说的。
1. 数据依赖:偏好数据的质量与噪声敏感性问题
(1) 核心问题
-
依赖高质量偏好数据:DPO、RRHF等算法通过直接优化人类偏好数据(如A/B对比标注)来训练模型,但:
-
标注成本高:需要大量人工标注的偏好对(如ChatGPT训练依赖数万小时的标注)。
-
噪声放大效应:标注不一致(如不同标注者对同一回答的偏好冲突)会导致模型学习到错误信号。
-
数据分布偏差:若偏好数据仅覆盖特定领域(如客服对话),模型在其他场景(如创意写作)可能表现不佳。
-
(2) 典型案例
-
DPO的脆弱性:
在《Direct Preference Optimization》论文中,作者发现当偏好数据中存在30%的噪声标签时,DPO的性能会下降15%以上,而PPO因依赖奖励模型的平滑性,下降幅度更小(约8%)。 -
RRHF的排序偏差:
若排序标注中高频回答总是被优先选择(如短文本更受标注者青睐),模型会偏向生成短文本,忽视信息量。
(3) 解决方案方向
-
数据增强:通过合成数据(如LLM生成伪偏好对)扩充数据集(参见《Self-Rewarding Language Models》)。
-
鲁棒性训练:引入噪声感知损失函数(如《Robust DPO》中的噪声加权机制)。
-
主动学习:优先标注模型不确定的样本(如ReMax的策略)。
2. 任务特异性:算法与任务场景的匹配局限
(1) 生成任务 vs 决策任务
-
生成任务(如文本、图像):
SLIC、RRHF等算法通过对比学习或排序损失优化生成多样性,但:-
不适用于序列决策:如机器人控制需要连续动作空间,而SLIC的离散排序机制难以直接迁移。
-
缺乏长期奖励建模:生成任务关注单步输出质量,而决策任务需考虑多步累积奖励(如AlphaGo的棋局胜负)。
-
(2) 典型案例
-
SLIC在文本摘要的局限性:
SLIC(《Sequence Likelihood Calibration》)在文本摘要任务中表现优异,但在Atari游戏(如Pong)中因无法处理帧间状态依赖,性能不及PPO。 -
KTO的心理学假设局限:
KTO基于人类损失厌恶设计,在对话生成中有效,但在股票交易等非情感决策任务中可能失效。
(3) 解决方案方向
-
任务适配改造:如将RRHF的排序机制与Q-learning结合,用于离散动作空间(参见《RankRL》)。
-
混合架构:生成任务算法(如DPO)与决策算法(如SAC)分阶段协作。
3. 理论普适性:数学基础与假设的局限性
(1) 理论缺口
-
DPO的等价性假设:
DPO通过数学变换将RLHF问题转化为分类问题,但其推导依赖奖励模型与策略共享架构的假设,若两者结构差异大(如奖励模型为CNN,策略为Transformer),理论保证失效。 -
KTO的行为经济学简化:
Kahneman-Tversky理论在人类实验中成立,但模型对“损失”的定义(如文本流畅度下降)未必符合心理学原义。
(2) 典型案例
-
ORPO的几率比假设:
ORPO假设偏好对的几率比稳定,实际中标注者可能因疲劳导致偏好尺度漂移(如后期标注更严格)。 -
CQL的保守性过强:
离线RL算法CQL在理论上有保守性保证,但实践中可能因过度悲观抑制有效策略探索(参见《On the Utility of Model Learning in Offline RL》)。
(3) 解决方案方向
-
理论扩展:如《Theoretical Analysis of DPO》中放松共享架构假设。
-
实证验证:通过大规模实验检验理论假设的鲁棒性(如不同数据分布下的ORPO表现)。
4. 生态支持:工具链与社区资源的差距
(1) 工程化瓶颈
-
PPO的成熟生态:
-
框架支持:Stable Baselines3、RLlib等库提供高效实现。
-
硬件优化:支持分布式训练(如NVIDIA的RLGPU)。
-
调试工具:W&B、TensorBoard的集成。
-
-
新算法的短板:
-
DPO等算法依赖研究者自实现代码,缺乏GPU优化(如FlashAttention兼容性)。
-
超参数调优指南不足(如ORPO的odds ratio阈值如何设置)。
-
(2) 典型案例
-
DPO的复现差异:
不同团队实现的DPO在相同任务上性能波动可达10%(源自《DPO Revisited》中的消融实验),主要因采样策略或梯度裁剪的细节差异。 -
硬件适配问题:
RRHF需维护多个生成序列的排序,在低显存设备(如消费级GPU)上易溢出。
(3) 解决方案方向
-
标准化库建设:如Hugging Face的
TRL(Transformer Reinforcement Learning)逐步集成DPO。 -
社区协作:通过开源竞赛(如NeurIPS的RLHF Challenge)推动算法工程化。
总结
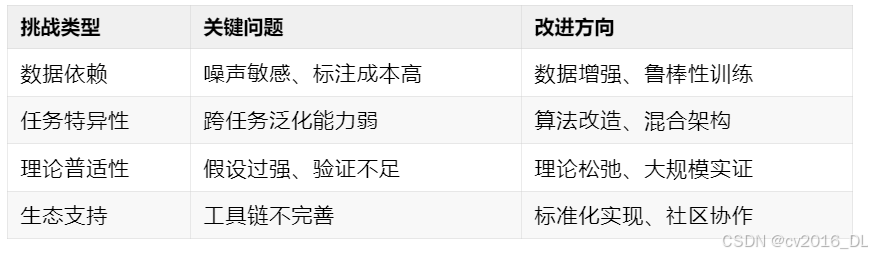
这些所谓的超越PPO的未来需在理论严谨性、任务通用性和工程可用性三者间寻求平衡,而非单纯追求“超越PPO”的指标。
88.如何保证请解释下同一Prompt在LLM中多次计算得到一样的结果?
-
静态Padding:在预处理时统一所有prompt的长度(如按数据集最大长度padding),避免动态变化。
具体做法:
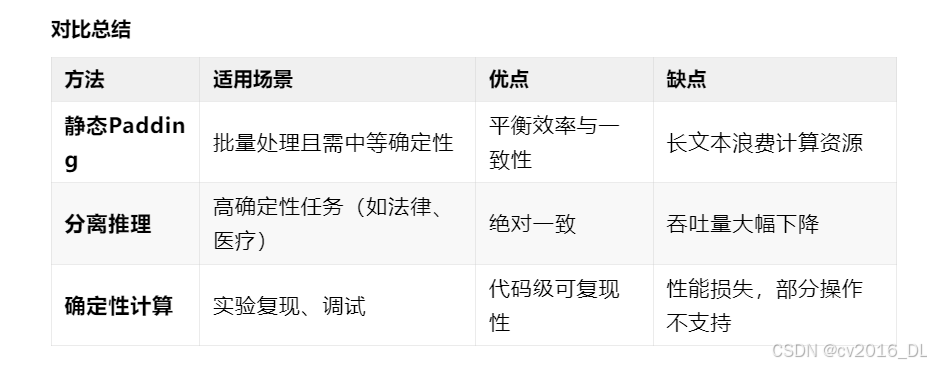
-
预处理阶段统一所有prompt长度:
-
统计训练集或任务中最大prompt长度(如20个token)。
-
对所有输入prompt强制填充或截断至固定长度20。
-
# 示例:PyTorch实现静态padding from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b") max_length = 20 # 预设固定长度 def preprocess(prompt): inputs = tokenizer(prompt, padding="max_length", max_length=max_length, truncation=True, return_tensors="pt") return inputs -
效果:
-
同一prompt在所有batch中输入完全一致,消除padding差异。
-
输出稳定性显著提升,但可能牺牲效率(短文本被过度填充)。
-
-
分离推理:对确定性要求高的任务,避免batch推理,改用单条prompt单独处理。
-
具体做法:
- 放弃batch推理,改用逐条处理:
# 示例:单条推理模式 model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b") def generate_one_by_one(prompts): outputs = [] for prompt in prompts: inputs = tokenizer(prompt, return_tensors="pt") output = model.generate(**inputs, max_new_tokens=50) outputs.append(tokenizer.decode(output[0])) return outputs -
效果:
-
彻底消除batch间干扰,保证100%确定性。
-
代价:推理速度下降(无法利用GPU并行能力),适合高确定性低吞吐场景。
-
-
确定性计算:启用框架级的确定性模式(如PyTorch的
torch.use_deterministic_algorithms(True)),但可能降低性能。 -
具体做法:
- 启用PyTorch/TensorFlow的确定性模式:
# PyTorch设置 import torch torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False torch.use_deterministic_algorithms(True) # TensorFlow设置 import tensorflow as tf tf.config.experimental.enable_op_determinism() -
对比总结
- 限制并行计算:
import os os.environ["CUBLAS_WORKSPACE_CONFIG"] = ":4096:8" # 限制CUDA工作空间 -
效果:
-
性能下降10%-30%(禁用硬件优化)。
-
部分操作(如
nn.LSTM)可能不支持确定性模式。
-
保证同一设备上多次运行结果完全一致。
-
代价:
-
-
]
-
推荐选择:
-
优先尝试静态Padding,若仍不一致则叠加确定性计算。
-
对关键任务(如合同生成),直接使用分离推理。
89.请解释下同一Prompt在Batch Inference为什么会得到不一样的结果?
简要回答:在LLM(如LLaMA2)的批量(batch)推理过程中,即使同一个prompt被复制多次,其输出仍可能不一致。这主要是由于动态padding机制和深度Transformer模型对极小数值的累积效应导致的。
具体原因可以分解如下,懂得就直接划过1. Batch Processing 与动态Padding的影响在批量推理时,不同prompt的长度可能不同,因此需要padding(填充)以使所有输入达到同一长度(通常取batch中最长prompt的长度)。例如:
-
Prompt A:
"What is AI?"(token数:3) -
Prompt B:
"Explain artificial intelligence in detail"(token数:6)
如果这两个prompt在同一个batch里,较短的Prompt A会被padding到长度6:
"What is AI? [PAD] [PAD] [PAD]"
但如果Prompt A单独在一个batch里,可能不需要padding(或padding更少)。
关键问题:
-
同一个prompt在不同batch里可能padding数量不同,导致输入的实际内容(prompt + padding)不一致。
2. Transformer如何处理Padding?在标准的Transformer架构中,padding部分会被mask掉,通常通过以下方式:
-
Attention Mask:在计算注意力权重时,padding位置的
Q^T K会被设置为一个极小的值(如-2^32 + 1或-1e9),使得softmax后这些位置的权重接近0:
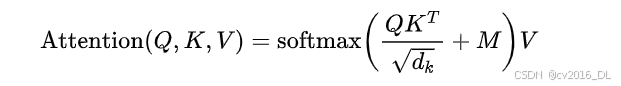
其中,M是mask矩阵,padding位置设为 -∞(或极小值)。
2.理论上:padding部分应该对最终输出无影响,因为它们的attention权重趋近于0。
尽管padding的attention权重理论上应该为0,但在极深的大模型(如LLaMA2)中,数值误差的累积可能导致padding仍然对输出产生微小影响。原因包括:
(1) Softmax的数值稳定性问题
-
在softmax计算中,即使某些logits被mask成极小值(如
-1e9),但由于浮点运算的有限精度(如FP16/FP32),这些值在指数计算后仍可能产生非零但极小的权重(如1e-20)。 -
在极深的Transformer(如65层)中,这些微小的数值可能逐层累积,最终影响模型的输出分布。
(2) 残差连接(Residual Connections)的放大效应
-
Transformer依赖残差连接(
x + Attention(x)),即使padding的attention贡献极小,但经过数十层的叠加后,这些微小差异可能被放大。 -
类似现象在梯度计算中也会出现(如vanishing/exploding gradients),但在前向推理中,数值误差的累积仍然可能影响最终logits。
(3) 采样策略(如Greedy Decoding)的敏感性
-
即使padding只导致logits的微小变化,但如果两个token的logits原本非常接近(如
p(token1)=0.501, p(token2)=0.499),这种微小扰动可能改变greedy decoding的选择。
90.DPO训练过程中,training positive和 negative的概率同时下降的原因?
在 DPO(Direct Preference Optimization)的训练过程中,training positive(优选样本)和 negative(劣选样本)的概率同时下降,看似矛盾的现象实际上是由其优化目标和策略约束共同导致的。

