企业网络服务合肥seo公司
Paper:https://arxiv.org/abs/2505.14059
Source code: https://github.com/bytedance/Dolphin
作者机构:字节跳动
背景
业务场景
企业数据大多数都以文本、图片、扫描件、电子表格、在线文档、邮件等文档的形式存在,例如:PDF文档(论文、财报等)、发票、收据等等,难以流通和处理,大量有价值的信息都被锁定在非结构化的文档中,无法充分发挥出数据价值,此外不同类型的文档包含的内容,以及内容展示形式也千差万别,这为非结构数据结构化进程增加了更多的不确定性和挑战。
相关工作
当前主流的文档解析主要是两个大的方向,
- Integration-based Document Parsing,这种解决方案整合了多个特有的模型于整个处理的pipeline中,例如:通过版面分析去识别表格,公式等,然后再使用对应的模型做相关的处理,主要的缺陷是:在系统复杂性、跨模型协调和对复杂文档布局的理解有限。
- Autoregressive Document Parsing,这种方案利用视觉语言模型通过自回归解码直接生成结构化的结果。其分为两种类型:
- General VLMs,这些模型受益于对不同视觉数据的大规模预训练,表现出强大的零样本能力。然而,它们在处理效率、专门的元素识别和布局结构保存方面经常面临挑战,特别是在处理具有复杂布局的长文档时。
- Expert VLMs,这些模型是专门为文档解析或理解任务设计和训练的。Dolphin就是这种类型。
方法论
该模型的处理范围是两阶段文档图像解析,如下图:
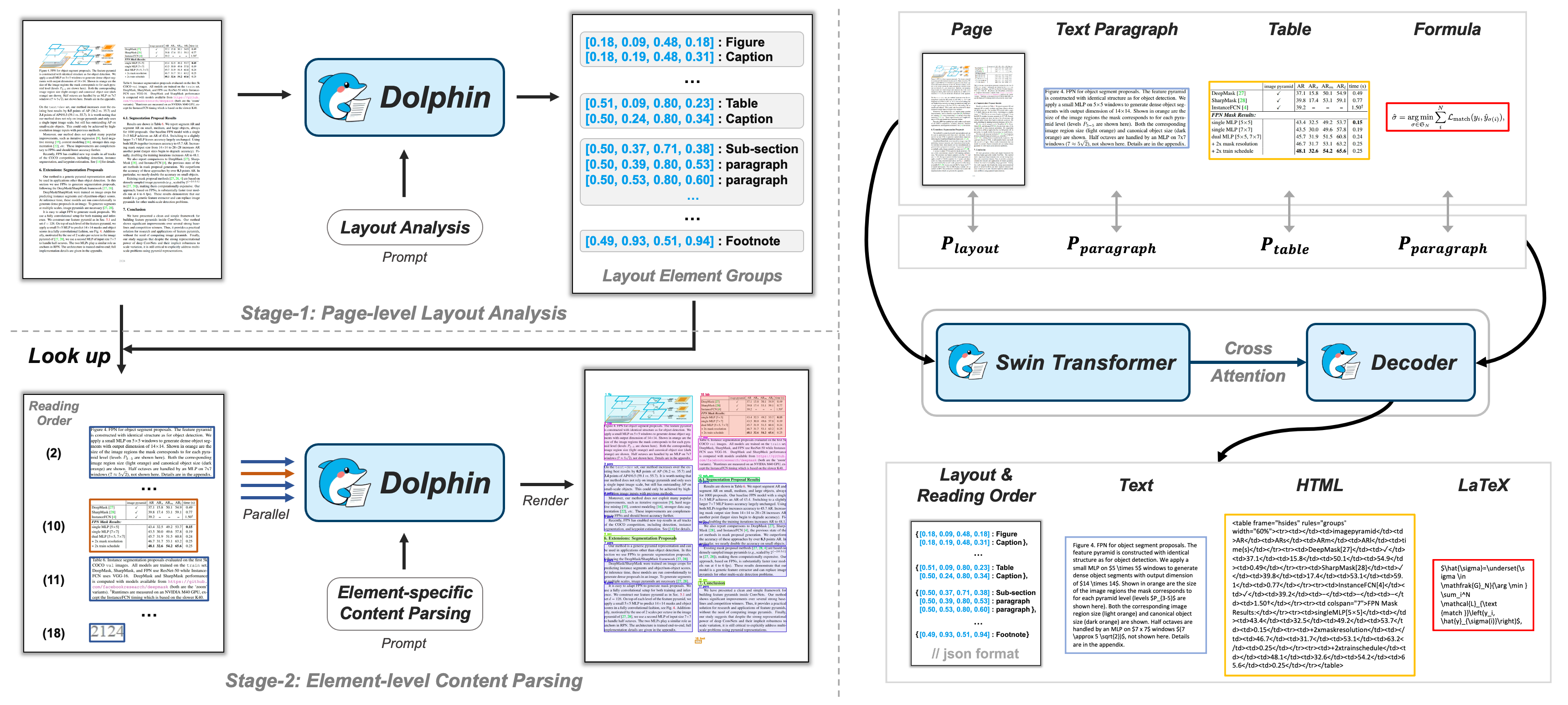
推理样例:

总得来说:主要分为两个阶段,在给定处理的文档图片后,首先(第一阶段)做page级的处理,采用的是版面分析的思想但与之不同的是其获取的是具有阅读顺序的各种类型元素结果,然后(第二阶段)做元素级的处理,并行地使用特定元素类型的prompt进行提取,由于已经得到了第一阶段的阅读顺序以及位置信息(bbox)就很容易将第二阶段的结果进行整合了。
可见思路是比较清晰的,那么需要探索的是这两个阶段的效果是否符合预期,或者是work的比较good。
Page-level layout analysis
页面级别的版面分析是如何做的?
对于输入的图片,作者使用的是Swin Transformer作为整个模型的视觉编码器。注:输入图像会被调整大小并填充到固定的 H × W,保留其纵横比以避免文本失真。
版面分析结果的生成。使用版面分析的prompt,然后解码器输出目标结果。这里会涉及视觉特征和文本特征之间的对齐。作者使用的是mBart作为解码器。最后输出的就结果就是Bounding box + element type。
附录中给出里支持的元素种类,如下:

Element-level Content Parsing
元素级别的内容分析又是如何做的呢?
结合各元素的类型使用各自的prompt并行地处理(这里很显然会带来更多资源的消耗,小心OOM)。使用的是各自bbox截取出当前类型的图片。
附录中也给出了对应元素类型的prompt,如下:

对应表格图片,模型的结果是html形式的。段落中如果包含公式,输出的结果是使用LaTeX进行表示的。
效果比对
Dolphin模型参数量在322M,并不是很大,相比于其他VLMs在体积上优势很大(就是快)。文中使用的评判指标是ED(edit distances)和FPS(frames per second)。也分别在页面级和元素级分别做了比较。
页面级的对比如下:
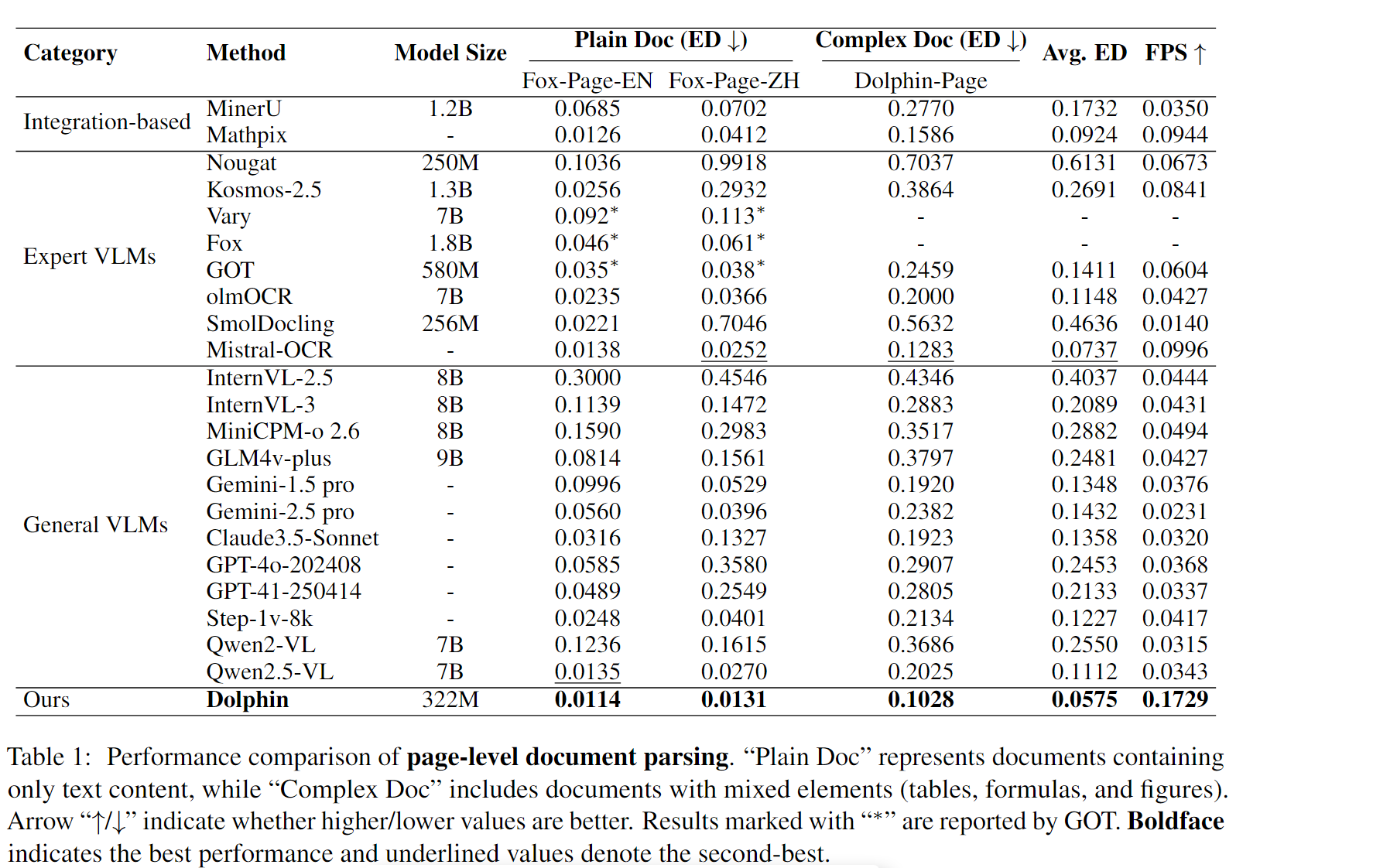
元素级的对比如下:
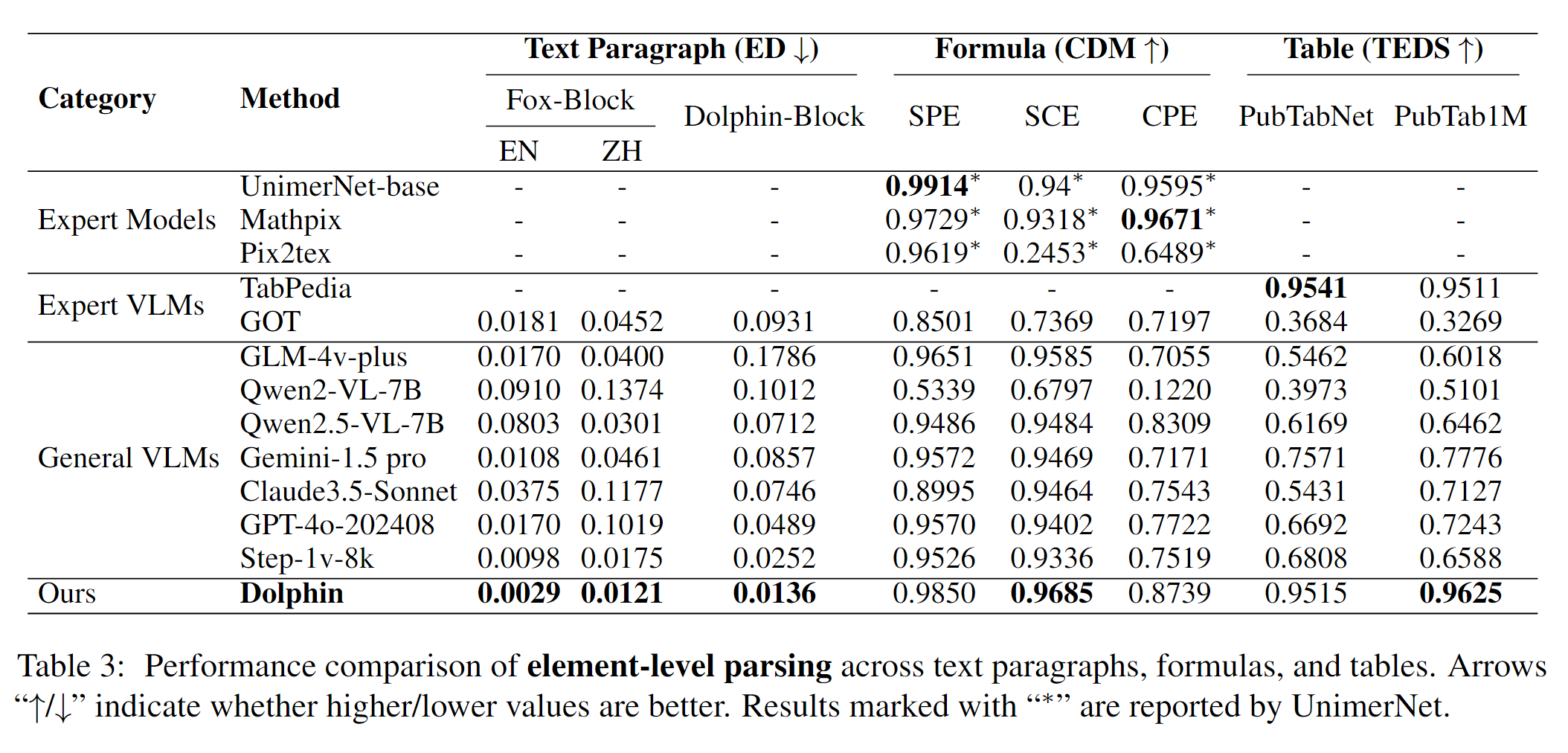
从罗列的指标上来看,在相关的测试数据指标是不错的。根据工作经验来说,在具体业务中最好还是需要做进一步测试和实验。
好了,模型的推理到此结束。下面该看看如何训这个模型的,也就是(1)如何构建训练预料;(2)如何提高小模型的指令跟随能力。
模型训练
训练数据
收集了超过3kw覆盖page-level,element-level的样本。可参见如下表格:
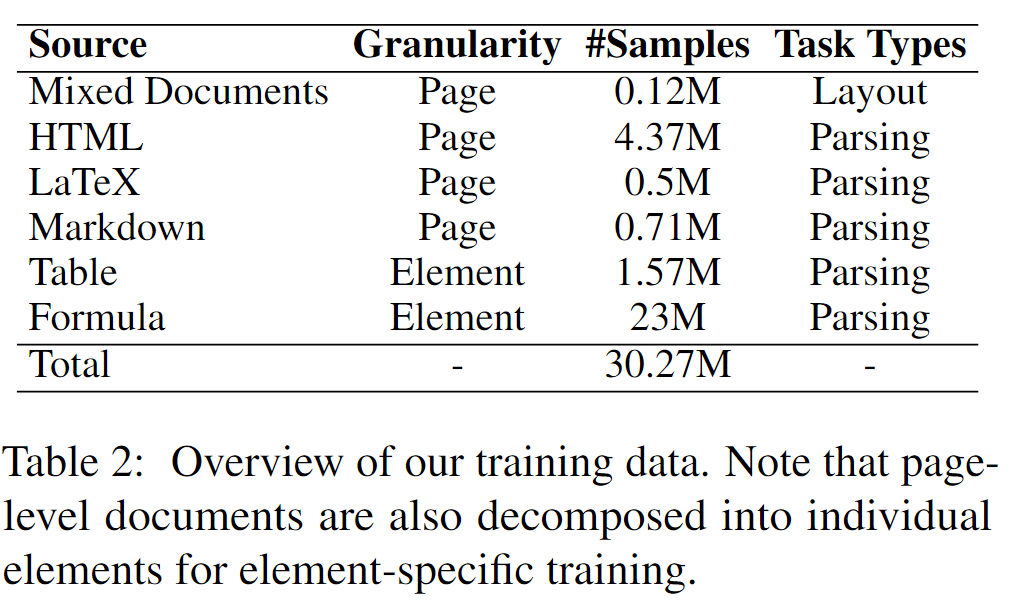
其在Mixed Documents中进行了具有阅读顺序的版面分析标注,即有元素类型、bbox以及阅读顺序。其它的数据主要是用于构建元素级别的提取训练语料。更多训练数据形式可参见原论文。
实验
模型层面:
- 视觉encoder使用的是Swin Transformer,window size:7, hierarchical structure([2, 2, 14, 2] encoder layers with [4, 8, 16, 32] attention heads),tips: 常见的通用VLM的视觉编码器通常使用的是基于vit的处理,后面对比一下其与Swin Transformer的差异;
- decoder使用的是mBart,包含了10个hidden dimension的Transformer layer;
- 使用Donut的预训练权重进行初始化。
训练:
- 优化器AdamW;
- Learning rate 5e-5 cosine decay schedule;
- 机器:40张A100;
- 2 epochs with a batch size of 16 per device (gradient accumulation)
- 训练Loss:cross-entripy loss。
其他:
- 图片进行归一化操作,将图片保留纵横比(aspect ratio),将最长的边放大或缩小到896个pixels,然后进一步padding以达到896x896 pixels 的尺寸。
总结
从文中可以看出,尽管Dolphin表现出了出色的性能,但仍有一些限制需要进一步改进。首先,Dolphin主要支持标准水平文本布局,对于垂直文本如古代手稿等的支持有限。其次,虽然Dolphin能够有效地处理中英双语文档,但其多语言能力仍需扩展。此外,虽然Dolphin通过并行元素解析实现了效率提升,但在文本行和表格单元格的并行处理方面仍有优化空间。最后,Dolphin的手写识别能力还需要进一步增强。
此外,由于文档的多样性和复杂性,还需要在工业界进行考验。项目也提供了在线试用的地址:http://115.190.42.15:8888/dolphin/。
对于类似的端到端的文档智能多模态模型还有如:GOT、SmolDocling等专门处理文档的多模态(大)语言模型。这些模型和方法为端到端的文档智能智能提供了很多解决思路,为后续的发展奠定了基础,但个人试用起来,感觉整体效果还需有进一步提升。