网站建设 分析荆州seo推广
强化学习算法
(一)动态规划方法——策略迭代算法(PI)和值迭代算法(VI)
(二)Model-Free类方法——蒙特卡洛算法(MC)和时序差分算法(TD)
(三)基于动作值的算法——Sarsa算法与Q-Learning算法
(四)深度强化学习时代的到来——DQN算法
(五)最主流的算法框架——AC算法(AC、A2C、A3C、SAC)
(六)应用最广泛的算法——PPO算法与TRPO算法
(七)更高级的算法——DDPG算法与TD3算法
(八)待续
文章目录
- 强化学习算法
- 前言
- 一、Sarsa算法
- 1. 核心思想
- 2. 代码实战
- 二、Q-Learning算法
- 1. 核心思想
- 2. 代码实战
- 三、强化学习算法的分类与小总结
- 1. 强化学习算法的分类
- 2. 强化学习算法宏观角度的内在联系(个人理解,可能不正确)
前言
上一章学习了蒙特卡洛算法(MC)和时序差分算法(TD),目前较为主流的算法大多利用TD思想,比如本章将要介绍的Sarsa算法和Q-Learning算法。因此在TD算法的基础上,我们可以很容易的掌握这两种算法。
一、Sarsa算法
1. 核心思想
Sarsa算法的名字很有趣,它是由“状态-动作-奖励-下一状态-下一动作”的英文首字母缩写组成,Sarsa算法的名字也指出了该算法的核心公式的
Q ( s t , a t ) ← Q ( s t , a t ) + α [ R t + 1 + γ Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ] Q(s_t,a_t)←Q(s_t,a_t)+α[R_{t+1}+γQ(s_{t+1},a_{t+1})-Q(s_t,a_t)] Q(st,at)←Q(st,at)+α[Rt+1+γQ(st+1,at+1)−Q(st,at)]从公式可以看出,除 α α α和 γ γ γ两个常数外,公式中的参数是由 ( s t , a t , r t + 1 , s t + 1 , a t + 1 ) (s_t,a_t,r_{t+1},s_{t+1},a_{t+1}) (st,at,rt+1,st+1,at+1)组成,此外,如果还记得上一章的TD算法,就会发现把TD公式中的 R R R全部替换为 Q Q Q就得到了Sarsa算法,下面是TD算法的更新公式:
V ( s t ) ← V ( s t ) + α [ R t + 1 + γ V ( s t + 1 ) − V ( s t ) ] V(s_t)←V(s_t)+α[R_{t+1}+γV(s_{t+1})-V(s_t)] V(st)←V(st)+α[Rt+1+γV(st+1)−V(st)]TD算法本质是用单步奖励 R t + 1 R_{t+1} Rt+1和下一状态价值 V ( s t + 1 ) V(s_{t+1}) V(st+1)的估计来更新当前状态价值 V ( s t ) V(s_t) V(st),而Sarsa算法是用当前策略选择的下一动作 a t + 1 a_{t+1} at+1对应的动作价值 Q ( s t + 1 , a t + 1 ) Q(s_{t+1},a_{t+1}) Q(st+1,at+1)来更新当前的 Q ( s t , a t ) Q(s_t,a_t) Q(st,at)。
2. 代码实战
import numpy as np
import matplotlib.pyplot as plt# 复用之前的网格世界定义
GRID_SIZE = 4
STATES = GRID_SIZE * GRID_SIZE
ACTIONS = 4 # 上(0)、右(1)、下(2)、左(3)
GOAL = (3, 3)
OBSTACLE = (1, 1)
ACTION_DELTA = [(-1, 0), (0, 1), (1, 0), (0, -1)]def build_model():"""构建网格世界的环境模型(状态转移矩阵P和奖励函数R)"""P = np.zeros((STATES, ACTIONS, STATES))R = np.full((STATES, ACTIONS), -1.0) # 默认每步奖励-1for s in range(STATES):x, y = s // GRID_SIZE, s % GRID_SIZEif (x, y) == GOAL:continue # 终点无动作for a in range(ACTIONS):dx, dy = ACTION_DELTA[a]x_next = x + dxy_next = y + dy# 检查边界和障碍物if x_next < 0 or x_next >= GRID_SIZE or y_next < 0 or y_next >= GRID_SIZE:x_next, y_next = x, yif (x_next, y_next) == OBSTACLE:x_next, y_next = x, ys_next = x_next * GRID_SIZE + y_nextP[s, a, s_next] = 1.0 # 确定性转移# 到达终点的奖励为0if (x_next, y_next) == GOAL:R[s, a] = 0.0return P, Rdef sarsa_learning(P, R, gamma=0.9, epsilon=0.1, alpha=0.1, episodes=10000):"""SARSA算法实现"""Q = np.zeros((STATES, ACTIONS)) # 初始化动作值函数policy = np.random.randint(0, ACTIONS, size=STATES) # 初始随机策略for _ in range(episodes):s = 0 # 起点 (0,0)x, y = s // GRID_SIZE, s % GRID_SIZEif (x, y) == GOAL:continue# 选择初始动作(ε-贪婪策略)if np.random.rand() < epsilon:a = np.random.randint(0, ACTIONS)else:a = policy[s]while True:# 执行动作,获得下一状态和奖励s_next = np.argmax(P[s, a]) # 确定性转移reward = R[s, a]# 终止条件判断x_next, y_next = s_next // GRID_SIZE, s_next % GRID_SIZEif (x_next, y_next) == GOAL:# 终点无下一步动作,Q(s',a')=0Q[s, a] += alpha * (reward + gamma * 0 - Q[s, a])break# 选择下一动作(ε-贪婪策略)if np.random.rand() < epsilon:a_next = np.random.randint(0, ACTIONS)else:a_next = policy[s_next]# SARSA更新公式:Q(s,a) ← Q(s,a) + α [R + γ Q(s',a') - Q(s,a)]Q[s, a] += alpha * (reward + gamma * Q[s_next, a_next] - Q[s, a])# 策略改进(贪婪策略)policy[s] = np.argmax(Q[s])# 转移到下一步s, a = s_next, a_nextreturn Q, policydef plot_value(Q, title):V = np.max(Q, axis=1) # 从Q表提取状态价值plt.figure(figsize=(8, 6))grid = V.reshape((GRID_SIZE, GRID_SIZE))# 绘制网格和状态值plt.imshow(grid, cmap='viridis', origin='upper')plt.colorbar()plt.title(title)# 标注特殊状态for i in range(GRID_SIZE):for j in range(GRID_SIZE):if (i, j) == GOAL:plt.text(j, i, 'GOAL', ha='center', va='center', color='white')elif (i, j) == OBSTACLE:plt.text(j, i, 'BLOCK', ha='center', va='center', color='white')else:plt.text(j, i, f'{V[i * GRID_SIZE + j]:.1f}', ha='center', va='center', color='white')plt.xticks([])plt.yticks([])value_img_path = "fig/3.1.png"plt.savefig(value_img_path)plt.show()plt.close()# 复用之前的可视化函数
def plot_policy(policy, title):plt.figure(figsize=(8, 6))action_symbol = ['↑', '→', '↓', '←']for i in range(GRID_SIZE):for j in range(GRID_SIZE):s = i * GRID_SIZE + jif (i, j) in [GOAL, OBSTACLE]:plt.text(j, i, 'GOAL' if (i, j) == GOAL else 'BLOCK', ha='center', va='center')else:plt.text(j, i, action_symbol[policy[s]], ha='center', va='center', fontsize=20)plt.xlim(-0.5, GRID_SIZE - 0.5)plt.ylim(-0.5, GRID_SIZE - 0.5)plt.gca().invert_yaxis()plt.title(title)plt.grid(True)value_img_path = "fig/3.2.png"plt.savefig(value_img_path)plt.show()plt.close()if __name__ == '__main__':P, R = build_model()# 运行Sarsa算法V_td0, policy_td0 = sarsa_learning(P, R, gamma=0.9, alpha=0.1, epsilon=0.1, episodes=10000)plot_value(V_td0, "Sarsa - Optimal State Values")plot_policy(policy_td0, "Sarsa - Optimal Policy")运行结果:
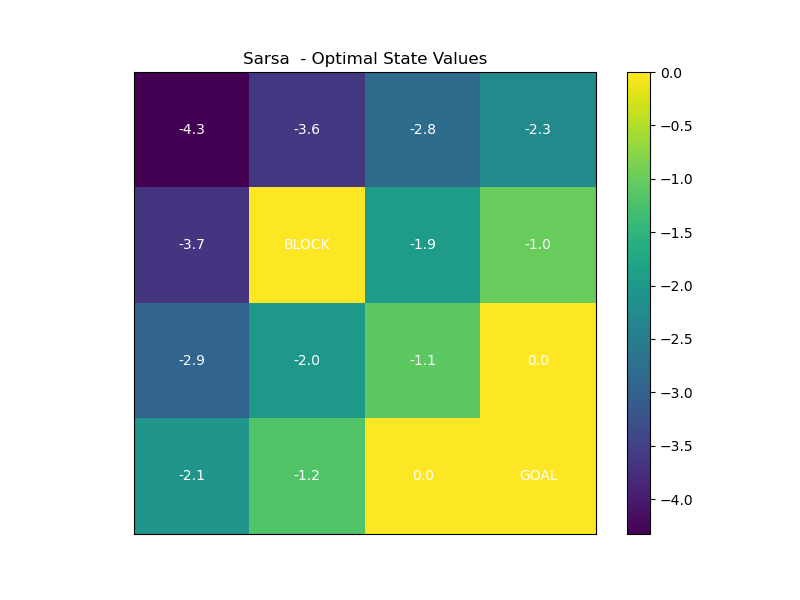
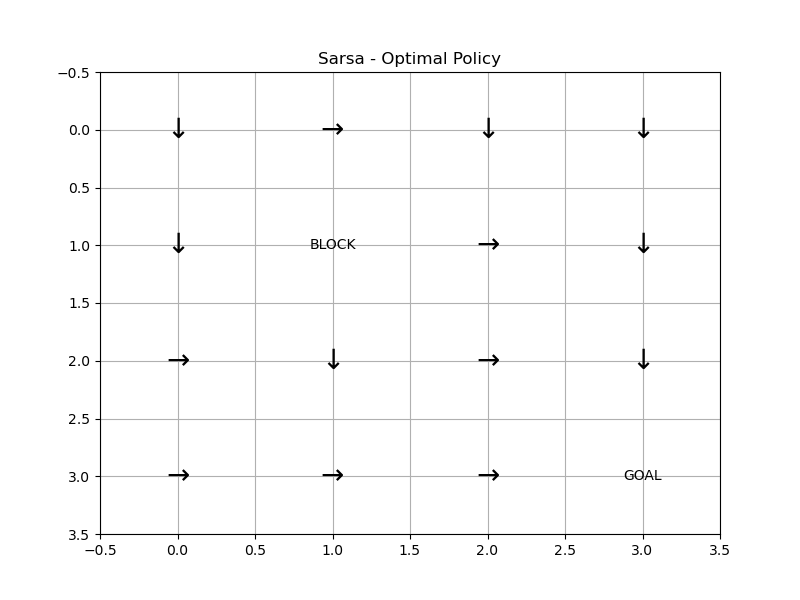
二、Q-Learning算法
1. 核心思想
Q-Learning算法的思想非常简单粗暴且有效。Sarsa算法在更新当前状态-价值对的Q值时,是选取下一状态的实际动作价值;Q-Learning算法是直接选取下一状态的最优动作价值更新当前状态-价值对Q值,其核心公式如下:
Q ( s t , a t ) ← Q ( s t , a t ) + α [ R t + 1 + γ max a Q ( s t + 1 , a t + 1 ) − Q ( s t , a t ) ] Q(s_t,a_t)←Q(s_t,a_t)+α[R_{t+1}+γ\max_{a}Q(s_{t+1},a_{t+1})-Q(s_t,a_t)] Q(st,at)←Q(st,at)+α[Rt+1+γamaxQ(st+1,at+1)−Q(st,at)]
2. 代码实战
import numpy as np
import matplotlib.pyplot as plt# 复用之前的网格世界定义(完全一致)
GRID_SIZE = 4
STATES = GRID_SIZE * GRID_SIZE
ACTIONS = 4 # 上(0)、右(1)、下(2)、左(3)
GOAL = (3, 3)
OBSTACLE = (1, 1)
ACTION_DELTA = [(-1, 0), (0, 1), (1, 0), (0, -1)]def build_model():"""(与之前代码完全一致)"""P = np.zeros((STATES, ACTIONS, STATES))R = np.full((STATES, ACTIONS), -1.0) # 默认每步奖励-1for s in range(STATES):x, y = s // GRID_SIZE, s % GRID_SIZEif (x, y) == GOAL:continue # 终点无动作for a in range(ACTIONS):dx, dy = ACTION_DELTA[a]x_next = x + dxy_next = y + dy# 检查边界和障碍物if x_next < 0 or x_next >= GRID_SIZE or y_next < 0 or y_next >= GRID_SIZE:x_next, y_next = x, yif (x_next, y_next) == OBSTACLE:x_next, y_next = x, ys_next = x_next * GRID_SIZE + y_nextP[s, a, s_next] = 1.0 # 确定性转移# 到达终点的奖励为0if (x_next, y_next) == GOAL:R[s, a] = 0.0return P, Rdef q_learning(P, R, gamma=0.9, epsilon=0.1, alpha=0.1, episodes=10000):"""Q-Learning算法实现"""Q = np.zeros((STATES, ACTIONS)) # 初始化动作值函数policy = np.random.randint(0, ACTIONS, size=STATES) # 初始随机策略for _ in range(episodes):s = 0 # 起点 (0,0)x, y = s // GRID_SIZE, s % GRID_SIZEif (x, y) == GOAL:continuewhile True:# ε-贪婪策略选择动作if np.random.rand() < epsilon:a = np.random.randint(0, ACTIONS)else:a = policy[s]# 执行动作,获得下一状态和奖励s_next = np.argmax(P[s, a]) # 确定性转移reward = R[s, a]# 终止条件判断x_next, y_next = s_next // GRID_SIZE, s_next % GRID_SIZEif (x_next, y_next) == GOAL:# 终点无下一步动作,max(Q(s',a'))=0# Q-Learning更新公式:Q(s,a) ← Q(s,a) + α [R + γ * max(Q(s')) - Q(s,a)]Q[s, a] += alpha * (reward + gamma * 0 - Q[s, a])break# Q-Learning核心更新公式(使用max(Q(s_next, a_next)))max_q_next = np.max(Q[s_next]) # 下一状态的最大Q值Q[s, a] += alpha * (reward + gamma * max_q_next - Q[s, a])# 策略改进(贪婪策略)policy[s] = np.argmax(Q[s])# 转移到下一状态s = s_nextreturn Q, policy# 完全复用之前的可视化函数
def plot_value(Q, title):"""可视化状态价值(取每个状态的最大Q值)"""V = np.max(Q, axis=1)plt.figure(figsize=(8, 6))grid = V.reshape((GRID_SIZE, GRID_SIZE))plt.imshow(grid, cmap='viridis', origin='upper')plt.colorbar()plt.title(title)# 标注特殊状态for i in range(GRID_SIZE):for j in range(GRID_SIZE):s = i * GRID_SIZE + jif (i, j) == GOAL:plt.text(j, i, 'GOAL', ha='center', va='center', color='white')elif (i, j) == OBSTACLE:plt.text(j, i, 'BLOCK', ha='center', va='center', color='white')else:plt.text(j, i, f'{V[s]:.1f}', ha='center', va='center', color='white')plt.xticks([])plt.yticks([])value_img_path = "fig/3.3.png"plt.savefig(value_img_path)plt.show()plt.close()def plot_policy(policy, title):"""(与之前代码完全一致)"""plt.figure(figsize=(8, 6))action_symbol = ['↑', '→', '↓', '←']for i in range(GRID_SIZE):for j in range(GRID_SIZE):s = i * GRID_SIZE + jif (i, j) in [GOAL, OBSTACLE]:plt.text(j, i, 'GOAL' if (i, j) == GOAL else 'BLOCK', ha='center', va='center')else:plt.text(j, i, action_symbol[policy[s]], ha='center', va='center', fontsize=20)plt.xlim(-0.5, GRID_SIZE - 0.5)plt.ylim(-0.5, GRID_SIZE - 0.5)plt.gca().invert_yaxis()plt.title(title)plt.grid(True)value_img_path = "fig/3.4.png"plt.savefig(value_img_path)plt.show()plt.close()if __name__ == '__main__':P, R = build_model()# 运行Q-Learning算法Q_ql, policy_ql = q_learning(P, R, gamma=0.9, alpha=0.1, epsilon=0.1, episodes=10000)plot_value(Q_ql, "Q-Learning - State Values")plot_policy(policy_ql, "Q-Learning - Learned Policy")
运行结果:
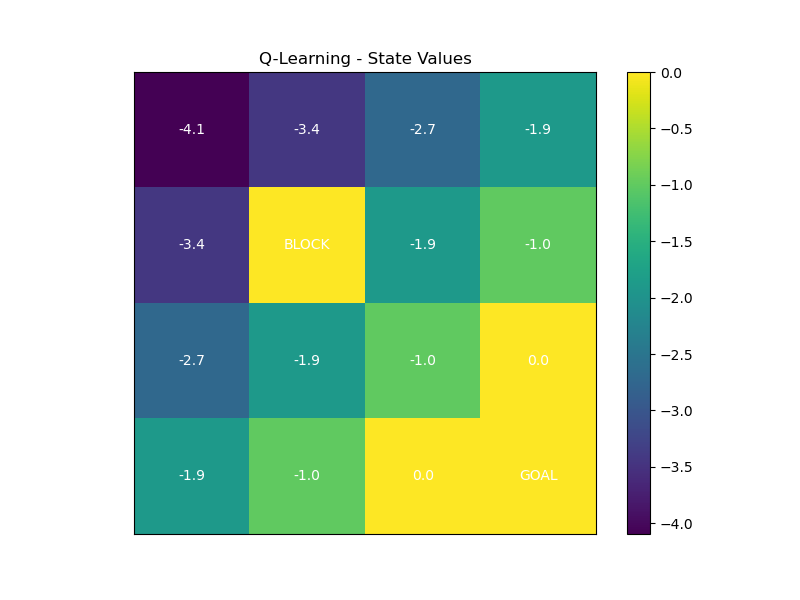
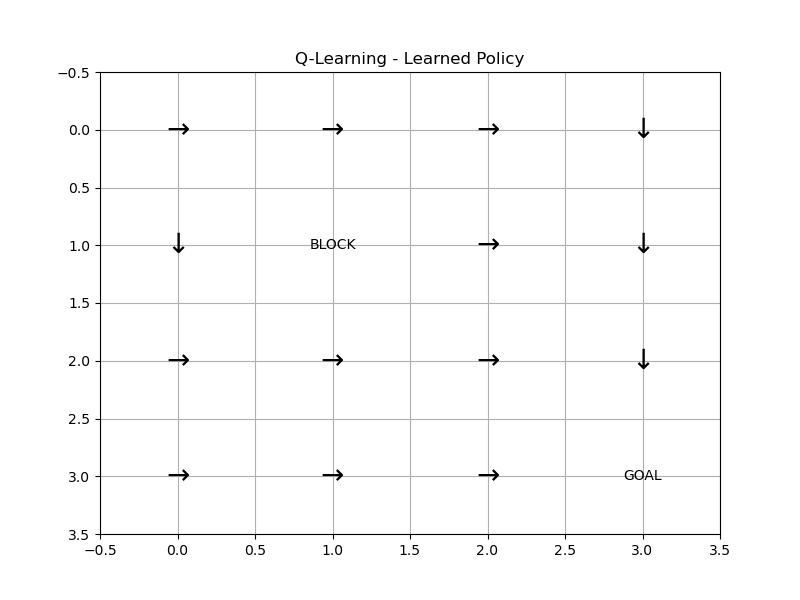
三、强化学习算法的分类与小总结
至此,已经学习了策略迭代算法(PI)、值迭代算法(VI)、蒙特卡洛算法(MC)、时序差分算法(TD)、Sarsa算法和Q-Learning算法六种算法,此时我们心中应该有疑问——这些算法有没有什么内在联系?或者区别?这里根据常见的一些强化学习分类方法并结合自己的理解回顾一下这些算法,帮助大家理解。
1. 强化学习算法的分类
主流的强化学习算法分类方式有三种:有模型(Model-based)和无模型(Model-free)、On-policy和Off-policy、基于值(Value-based)和基于策略(Policy-based)。目前我们接触到的均为基于值的算法,在后续学习到策略梯度算法才会引入基于策略的这一大类算法,此处暂不讨论。
- 有模型(Model-based)和无模型(Model-free)分类方式
有模型:依赖环境动态(状态转移概率和奖励函数),如动态规划算法(PI和VI)。
无模型:仅通过与环境交互的经验学习,如蒙特卡洛和时序差分,而Sarsa和Q-Learning属于TD算法的一种,因此也属于无模型算法。 - On-policy和Off-policy的分类方式
这种分类方式的标准为:用于测试的行为策略与目标策略是否为一致,该分类方式仅针对Model-free类算法。
On-policy:目标策略(目标策略)与行为策略一致(如Sarsa)。
Off-policy:目标策略与行为策略分离(如Q-Learning)。
而动态规划方法是基于模型计算,并为使用行为策略与环境交互,因此不适用这种分类方式。
下表总结了六种算法的分类
| 算法 | 有/无模型 | On/Off-policy | 基于值/策略 | 备注 |
|---|---|---|---|---|
| 策略迭代(PI) | 有模型 | 不适用 | 基于值 | 动态规划,需要环境模型。 |
| 值迭代(PI) | 有模型 | 不适用 | 基于值 | 动态规划,直接逼近最优值函数。 |
| 蒙特卡洛(MC) | 无模型 | On-Policy | 基于值 | 通过完整轨迹更新值函数。 |
| 时序差分(PI) | 无模型 | 依具体算法而定 | 基于值 | 单步更新,如TD(0)通常为On-policy。 |
| Sarsa | 无模型 | On-Policy | 基于值 | 使用当前策略选择动作。 |
| Q-Learning | 无模型 | Off-policy | 基于值 | 行为策略与目标策略分离(如ε-greedy)。 |
2. 强化学习算法宏观角度的内在联系(个人理解,可能不正确)
突如其来的一股奇思妙想,问了问某些东西,不知道它说的对不对,这里记录一下,后面再思考正确性。
问:Sarsa的过程有点像策略迭代算法先进行策略评估,再进行策略改进?,Q-Learning的off-policy形式很像值迭代算法直接利用贝尔曼最优方程求解最优策略,而Q-Learning的on-policy形式又和策略迭代算法很像,不知道这样类比对吗?或者我可以推广为on-policy算法和策略迭代算法类似,而off-policy算法和值迭代算法相似吗?
答:你的类比有一定的道理,但需要结合算法细节和理论框架进一步澄清。我们可以从以下几个方面来分析:
- Sarsa与策略迭代的类比
策略迭代分为两个阶段:
策略评估:计算当前策略下的值函数(通过贝尔曼期望方程)。
策略改进:基于当前值函数贪心地更新策略(例如选择最大化动作价值的动作)。
Sarsa是典型的 on-policy TD算法,与策略迭代的
联系:
策略评估:Sarsa在更新时使用当前策略生成的动作 a (即遵循ε-greedy策略),相当于对当前策略的价值进行估计。
策略改进:通过不断更新Q值,隐式地改进策略(例如ε-greedy策略会逐渐趋向最优策略)。
区别:
策略迭代需要完全收敛的策略评估(多次迭代),而Sarsa是单步更新(类似于截断的策略评估)。
Sarsa是无模型的,而策略迭代通常假设已知环境模型。
- Q-Learning与值迭代的类比
值迭代直接通过贝尔曼最优方程更新值函数:其目标是直接找到最优值函数,无需显式的策略改进步骤。
Q-Learning是典型的 off-policy TD算法,与值迭代的
联系:
Q-Learning直接通过最大化下一状态的Q值(即贝尔曼最优方程)更新当前Q值,这与值迭代的“一步最优性”思想一致。
两者都绕过显式的策略评估,直接逼近最优策略。
区别:
值迭代需要已知环境模型(动态规划),而Q-Learning是无模型的。
Q-Learning的更新是增量式的,而值迭代通常需要多次扫描所有状态。 - On-policy与Off-policy的广义类比
On-policy算法(如Sarsa):
策略评估和策略改进使用相同的行为策略。
类似于策略迭代的“逐步优化”过程,即先评估当前策略,再改进它。
Off-policy算法(如Q-Learning):
策略评估和策略改进使用不同的策略(例如行为策略是ε-greedy,目标策略是greedy)。
类似于值迭代的“一步最优”思想,直接通过最大化动作价值逼近最优策略。
推广的可能性:
可以认为,On-policy方法更贴近策略迭代(逐步优化当前策略),而Off-policy方法更贴近值迭代(直接优化目标策略)。
但需注意:这种类比是启发式的,实际算法在理论和实现上有差异(例如是否依赖模型、是否显式维护策略)。
- 结论是否正确?
正确性:
你的类比在直觉层面是合理的,尤其是从“渐进优化”与“直接最优”的角度来看。
On-policy方法(如Sarsa)和策略迭代都强调对当前策略的评估和改进;Off-policy方法(如Q-Learning)和值迭代都绕过当前策略,直接逼近最优策略。
需要澄清的细节:
策略迭代 vs 值迭代:策略迭代需要显式的策略改进步骤,而值迭代将策略改进隐式地嵌入到值函数更新中。类似地,Sarsa需要显式地跟踪策略(通过动作选择),而Q-Learning隐式地通过最大化Q值改进策略。
模型依赖:策略迭代和值迭代通常是基于模型的(动态规划),而TD学习(Sarsa/Q-Learning)是无模型的。
- 更严谨的理论框架
广义策略迭代(GPI):
无论是策略迭代、值迭代,还是TD学习(Sarsa/Q-Learning),都可以统一到GPI框架中。
GPI的核心思想是策略评估和策略改进交替进行,但不同算法在具体实现时有差异:
策略迭代:完全策略评估 → 完全策略改进。
值迭代:单步策略评估(截断) → 隐式策略改进。
TD学习(Sarsa/Q-Learning):单步策略评估(通过采样) → 隐式策略改进。
On-policy/Off-policy与GPI的关系:
On-policy方法(如Sarsa)更符合GPI的“交替优化”思想。
Off-policy方法(如Q-Learning)可以看作是GPI的一种变体,其中策略改进通过目标策略(而非行为策略)完成。 - 总结
你的类比在直觉上是成立的,且可以推广为:
On-policy方法(如Sarsa)与策略迭代类似,强调对当前策略的评估和改进。
Off-policy方法(如Q-Learning)与值迭代类似,直接通过贝尔曼最优方程逼近最优策略。
但需注意两者在模型依赖性(有无模型)、更新方式(单步/多步)等方面的差异。这种类比有助于理解算法背后的思想,但在严格的理论框架下,它们属于不同的类别(动态规划 vs 强化学习)。