天元建设集团有限公司文件免费seo课程
我发现我纠结于这个问题好几年了,在再次改版之前回顾一下:
1 Python 全栈系列22 - 分布式消息管理 celery
这个是2020-09的,当时准备开写,没有完成。里面有引用几个帖子
使用Celery踩过的坑
这个帖子说了启动的问题,多个q,worker使用次数的问题。
celer介绍
这个相当于已经给了一个精简的使用版本

2 建模杂谈系列36- celery + rabbiqmq进行分布式计算
这个是2020-10,只写了一些基本的想法
1 执行的任务是I/O问题还是计算问题。如果是IO并行,那么一个cpu也可以(协程)。
2 如果任务是类似矩阵计算之类的,那么单核利用已经达到最高。(如果是for的话其实本身可以考虑用矩阵提升)
3 如果任务的网络结构是比较扁平(而非纵深)的,那么适合分布执行。
3 建模杂谈系列38- 基于celery、rabbitmq、redis和asyncio的分布并行处理(概述)
2020-10的晚些时候,我终于发了第一篇帖子
当时是考虑用celery worker直接做计算负载;现在看来定位不太合适。不同的任务所需要的环境不同,最后的情况是逻辑跟着容器走。
4 建模杂谈系列39- celery + redis的单机异步并行
2020-10 试着用celery的worker进行etl类的工作,用pandas处理。其实这种计算密集的任务,用celery的意义不大,只是调度而已。如果真的计算量大,其实可以起任何一个容器,共同消耗任务队列就可以了。(或者说更具弹性,不需要考虑其他因素,只是队列)
5 Python 全栈系列48 - celery + flask 异步调用任务
2020-11 还是讨论了把逻辑放到task里,然后还额外设计了冗余分发的策略。也讨论了使用rabbitmq作为消息队列。
总结到这里,我也蛮奇怪celery和 rabbitmq是我拿起又放下好几次的工具,问题到底在哪里?
首先,在部署方式上总是把celery作为本地服务部署(systemd)
其次,希望celery做通用的计算任务
最后,rabbitmq总是作为简单队列被使用(高级功能没有真正发挥作用)
是不是可以得出这样的结论:celery不要直接在宿主机上,不要期待它能做通用任务。而rabbitmq的真正使用场景并不是这个(简单任务队列)。
6 Python 全栈系列194 Flask+Celery魔改版:准实时请求
2022-10 这是过了2年,然后我又想起来用Celery了,这时候结合了Flask。应该说,这时候的形态有点成熟了,和最新的设计想法在某方面很相似。
- 1 微服务传入请求。发布任务时不是直接通过celery,而是通过Flask。
- 2 伪实时请求。背后使用异步服务,而让前端感知为实时服务。
从现在的视角来看,当时的很多地方还是不够好,没用起来是正常的。
7 Python 全栈系列243 S2S flask_celery
2024-5 只是又过了快2年,继续在尝试。当时这个概念Stream To Stream,到当前版本是打算采用的,不过此时队列换成了Kafka。Kafka的特性可以让件事成功,这算是工具的问题了。
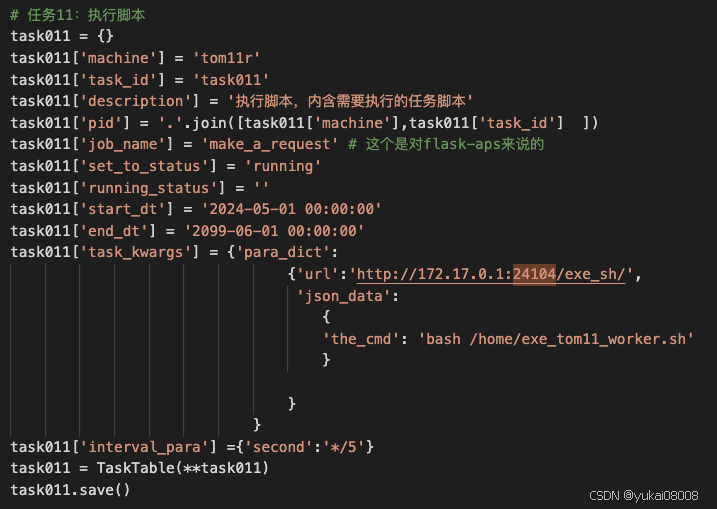
卖糕的,我觉得这个celery是现在还在运行的。任务还不少。这种参数化的执行是我现在也希望这么定义的。
任务通过ORM存在Mongo中,这个可以替换成我新的AMalchemy对象。
在找到项目文件夹了,写的非常完整,当时定义了三类任务:
- 1 s2s: 从stream到stream
- 2 s2ch: 从stream到clickhouse
- 3 exe_sh:执行脚本
当时只用了一个server.py文件就完成了,还非常精简。
因为是systemd执行的,我真的没发现…
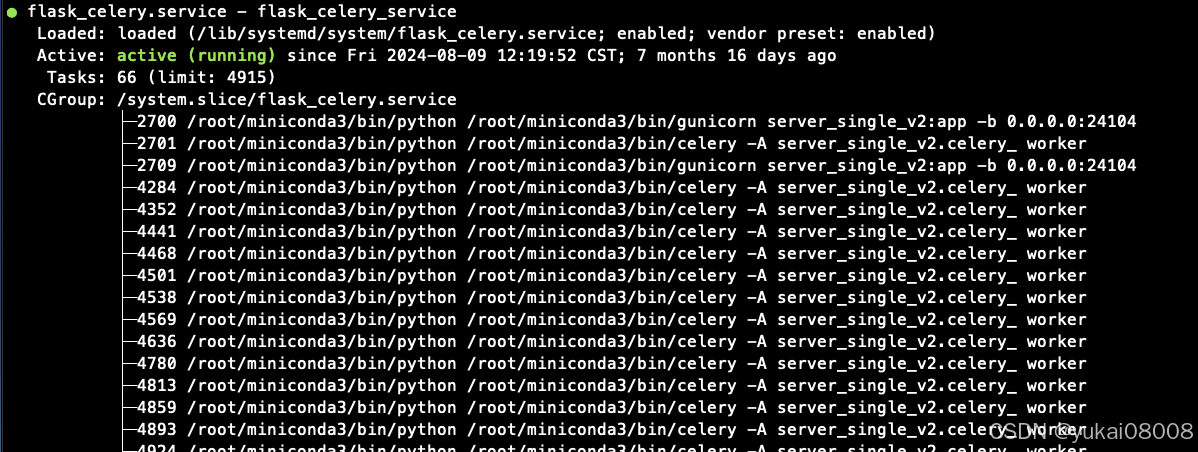
所以,除了一些特别特别基础的服务,真的不要systemd,会忘记…
另外,当时这个项目应该被打断了,去干了一些别的占用精力的项目,所以也没有继续去完善。然后在去年我决定再开一个fastapi框架,所以这个就被扔到一边了。不过看起来这个应该还是在稳定执行的。
8 Python 全栈系列253 再梳理flask-celery的搭建
2024-6 在上次的基础上发现了一些问题

这大概也是celery在我这里突然重要性下降的原因:大量的任务实际上是IO任务,如果都是线程同步占用就毫无意义了。这时候还是在考虑使用systemd来创建服务。
然后为啥又要搞celery?
我记得后来我有看了一些工具,airflow, prefect,发现这些工具似乎背后还是celery,那我问题就不在celery,而是我的认知可能有偏差。然后随着我对异步服务这块做了不少实践,再加上大模型的知识,我觉得似乎可以再搞一次。
这次目标非常明确:解决IO并发任务。
上面的目标就会要求:
- 1 采用异步/协程方式
- 2 方便进行定时控制
然后我也既不希望烂尾,也不希望失控(之前那个默默运行中的celery…)。
所以会采用一种微服务+ORM的方式进行。这被证明是黄金搭档,目前这种方式的服务都运行且管理良好。
最后,大约还需要一个表格状的前端来展示当前任务的状态。并能够通过按钮来进行任务状态的改变。
从应用上:
- 1 一些定期需要通过爬取或者api获得数据的程序集中运行【数据获取】
- 2 复杂任务,需要通过api调用完成,比如大模型api 【计算负载】
对于celery而言,本身不承担任何计算负载,只是完成api调用,这一定是可以做成异步的。
这样从功能上和应用上就能满足我的要求了。
新的架构
这是我最关心的基础:celery的worker可以以协程方式工作。

最后的产出是一个微服务:celery_fastapi_apscheduler_24165_24166
一个ORM:WCelery
先来细细看一下:
1 我所关心的协程模式
用--loglevel=debug 可以看到比较详细的启动信息(嗯,其实gevent的信息用info级别也有)
(base) root@a93c876766f4:/workspace# celery -A celery_app.celery_app worker --loglevel=debug --pool=gevent --concurrency=100
[2025-03-28 23:23:10,249: DEBUG/MainProcess] | Worker: Preparing bootsteps.
[2025-03-28 23:23:10,251: DEBUG/MainProcess] | Worker: Building graph...
[2025-03-28 23:23:10,251: DEBUG/MainProcess] | Worker: New boot order: {Timer, Hub, Pool, Autoscaler, Beat, StateDB, Consumer}
[2025-03-28 23:23:10,258: DEBUG/MainProcess] | Consumer: Preparing bootsteps.
[2025-03-28 23:23:10,258: DEBUG/MainProcess] | Consumer: Building graph...
[2025-03-28 23:23:10,316: DEBUG/MainProcess] | Consumer: New boot order: {Connection, Agent, Events, Mingle, Gossip, Tasks, Control, Heart, event loop}-------------- celery@a93c876766f4 v5.4.0 (opalescent)
--- ***** -----
-- ******* ---- Linux-5.15.0-60-generic-x86_64-with-glibc2.36 2025-03-28 23:23:10
- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: celery_app:0x7f1e5c928b90
- ** ---------- .> transport: redis://:**@172.17.0.1:24008/1
- ** ---------- .> results: redis://:**@172.17.0.1:24008/1
- *** --- * --- .> concurrency: 100 (gevent) <------ 这里说明用gevent启动协程了
-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)
--- ***** ------------------- [queues].> celery exchange=celery(direct) key=celery[tasks]. celery.accumulate. celery.backend_cleanup. celery.chain. celery.chord. celery.chord_unlock. celery.chunks. celery.group. celery.map. celery.starmap. celery_app.check_gevent. celery_app.process_task. celery_app.sniff_mongo_change[2025-03-28 23:23:10,397: DEBUG/MainProcess] | Worker: Starting Pool
[2025-03-28 23:23:10,397: DEBUG/MainProcess] ^-- substep ok
[2025-03-28 23:23:10,398: DEBUG/MainProcess] | Worker: Starting Consumer
[2025-03-28 23:23:10,398: DEBUG/MainProcess] | Consumer: Starting Connection
[2025-03-28 23:23:10,411: INFO/MainProcess] Connected to redis://:**@172.17.0.1:24008/1
[2025-03-28 23:23:10,412: DEBUG/MainProcess] ^-- substep ok
[2025-03-28 23:23:10,412: DEBUG/MainProcess] | Consumer: Starting Events
[2025-03-28 23:23:10,415: DEBUG/MainProcess] ^-- substep ok
[2025-03-28 23:23:10,415: DEBUG/MainProcess] | Consumer: Starting Mingle
[2025-03-28 23:23:10,416: INFO/MainProcess] mingle: searching for neighbors
[2025-03-28 23:23:11,440: INFO/MainProcess] mingle: all alone
[2025-03-28 23:23:11,440: DEBUG/MainProcess] ^-- substep ok
[2025-03-28 23:23:11,440: DEBUG/MainProcess] | Consumer: Starting Gossip
[2025-03-28 23:23:11,449: DEBUG/MainProcess] ^-- substep ok
[2025-03-28 23:23:11,449: DEBUG/MainProcess] | Consumer: Starting Tasks
[2025-03-28 23:23:11,455: DEBUG/MainProcess] ^-- substep ok
[2025-03-28 23:23:11,455: DEBUG/MainProcess] | Consumer: Starting Control
[2025-03-28 23:23:11,455: DEBUG/MainProcess] ^-- substep ok
[2025-03-28 23:23:11,455: DEBUG/MainProcess] | Consumer: Starting Heart
[2025-03-28 23:23:11,461: INFO/MainProcess] pidbox: Connected to redis://:**@172.17.0.1:24008/1.
[2025-03-28 23:23:11,463: DEBUG/MainProcess] ^-- substep ok
[2025-03-28 23:23:11,463: DEBUG/MainProcess] | Consumer: Starting event loop
[2025-03-28 23:23:11,463: INFO/MainProcess] celery@a93c876766f4 ready.
[2025-03-28 23:23:11,463: DEBUG/MainProcess] basic.qos: prefetch_count->400
# 终端1
from celery_app import check_gevent
check_gevent.delay()# 服务终端打印
[2025-03-28 23:36:24,139: WARNING/MainProcess] Running in greenlet: <Greenlet at 0x7fedb8f013a0: apply_target(<function fast_trace_task at 0x7fede5211c60>, ('celery_app.check_gevent', 'd95278c2-5324-4287-b1, {}, <bound method create_request_cls.<locals>.Request., <bound method Request.on_accepted of <Request: cel, timeout=None, timeout_callback=<bound method Request.on_timeout of <Request: cele)>
并发测试,服务开100并发,这么执行没问题
In [3]: from celery_app import process_task # 替换为你的任务...: import time...:...: def test_concurrency(n=100):...: start = time.time()...: results = [process_task.delay(f"task-{i}") for i in range(n)]...: print(f"已发送 {n} 个任务,耗时: {time.time() - start:.2f}s")...:...: # 可选:等待所有任务完成(同步阻塞)...: for r in results:...: r.get(timeout=30) # 设置超时避免卡死...: print(f"所有任务完成,总耗时: {time.time() - start:.2f}s")...:...: if __name__ == "__main__":...: test_concurrency(500) # 测试 500 并发...:
已发送 500 个任务,耗时: 0.60s
所有任务完成,总耗时: 53.98s
当服务开500并发,然后就出错了,正好单个任务的时间超过了之前设定的30s,重新改60s,问题解决。【并发大不一定有用】500和100相比,服务多了5倍,而实际的能力大约只能提升2倍。
In [7]: from celery_app import process_task # 替换为你的任务...: import time...:...: def test_concurrency(n=100):...: start = time.time()...: results = [process_task.delay(f"task-{i}") for i in range(n)]...: print(f"已发送 {n} 个任务,耗时: {time.time() - start:.2f}s")...:...: # 可选:等待所有任务完成(同步阻塞)...: for r in results:...: r.get(timeout=60) # 设置超时避免卡死...: print(f"所有任务完成,总耗时: {time.time() - start:.2f}s")...:...: if __name__ == "__main__":...: test_concurrency(500) # 测试 500 并发...:
已发送 500 个任务,耗时: 0.59s
所有任务完成,总耗时: 34.24s
然后我又试了下线程,开到100时还行,速度甚至比协程500还快;但是并发开到500就直接bbq了, 看到任务有执行,但是前端没有收到结果。

嗯,最后跑完了,没有超时,但是效果大幅降低了。看来是线程之间切换的问题。另外就是线程的确比协程要更消耗资源,占的内存更多。整体上感觉,线程不宜太多。
综上:
- 1 协程验证没问题,并发可以至少设置100
- 2 我大部分应该都是采用微服务执行复杂任务,所以一般采用协程。
- 3 当需要进行密集计算时 ,可能还是采用进程

2 部署
首先,得搞清楚Celery服务的定位。


也就是说,celery的负载主要在运行服务的位置,和调用的位置无关。
如果是在本地,可以这样统一去调用
from celery_app import process_task,sniff_mongo_changeresult = process_task.delay("test_value")
print(result.get()) # 获取任务结果result = sniff_mongo_change.delay(db_server='xxx', tier1='xxx', tier2='xxx',query_col='xxx')
print(result.get()) # 获取任务结果
我上午在想,那么直接用celery+redis是不是就够了。例如,有一个celery worker,可以动态检测任务文件夹,然后开发端就可以动态的增加各种任务,然后通过这个worker执行…
结论是No。
没有一种方案能解决所有的问题,我们应该是根据不同类型的问题选择不同的方案。这里不同类型并不是无限枚举,而是基于同步、异步这样大的MECE框架分的。
从整个数据处理流程上,数据的IO和计算显然是两块完全不同的场景。所以Celery应该专注于解决IO问题,比如说获取数据,流转数据等。在大模型时代,这块工作的重要性被提高了:一般企业不可能部署大模型,因此只能向大厂调用。此时,原本繁重的计算问题,变成了IO问题 (prompt + 数据) -> 结果。而重计算的框架,则交给ray和dask这样的计算框架。

定义一个通用的http任务:
import httpx
from httpx import Timeout
from pydantic import BaseModel
@celery_app.task(name="http_request",autoretry_for=(httpx.RequestError,),retry_kwargs={'max_retries': 3, 'countdown': 2},time_limit=200
)
def http_request(url: str, json_data: dict, timeout: float = 10.0,headers: dict = None
):"""同步HTTP POST请求:param url: 请求地址:param json_data: POST的JSON数据:param timeout: 超时时间(秒):param headers: 可选请求头"""with httpx.Client() as client:resp = client.post(url,json=json_data,timeout=Timeout(timeout),headers=headers or {"Content-Type": "application/json"})resp.raise_for_status()return resp.json()
3 几种调用方法
同步(阻塞)调用。这个比较简单,适合用来做测试。
task = http_request.delay(url=test_url,json_data={"key": "value"},timeout=5.0
)try:# 阻塞等待结果(超时时间建议大于Celery的time_limit)result = task.get(timeout=30) # 最多等待30秒print("Result:", result)
except Exception as e:print("Task failed:", str(e))
异步分为两种,第一种是for循环加asleep,这种相对简单(我现在做的伪实时服务就是这样)
import asyncio
from celery.result import AsyncResultasync def async_wait_for_task(task_id: str, timeout: int = 30):"""异步等待Celery任务完成"""result = AsyncResult(task_id)for _ in range(timeout):if result.ready():return result.resultawait asyncio.sleep(1) # 非阻塞等待raise TimeoutError(f"Task {task_id} timeout after {timeout}s")
第二种是用异步服务封装,这就是关于【FastAPI】的部分
# 示例:FastAPI路由
@app.post("/run-task")
async def run_task():task = http_request.delay(url=test_url,json_data={"key": "value"},timeout=5.0)try:result = await async_wait_for_task(task.id)return {"status": "success", "result": result}except TimeoutError as e:return {"status": "error", "message": str(e)}
另一大类则是基于事件的方式。

第一种,应该来说也是最合适在内部系统里流转的方式。事件的callback。
from celery.signals import task_success@task_success.connect(sender='http_request')
def handle_task_result(sender=None, result=None, **kwargs):"""任务完成时自动触发"""print(f"Task {sender.request.id} completed! Result: {result}")# 调用任务(无需主动等待)
http_request.delay(url=test_url, json_data={"key": "value"})
后来我试了下,发现有点不靠谱,我也懒得调,和deepseek商量了下,用webhook来替代这个动作。
修改后的celery_app服务代码如下:
import httpx
from httpx import Timeout
from pydantic import BaseModel
import time
@celery_app.task(name="celery_app.http_request",autoretry_for=(httpx.RequestError,),retry_kwargs={'max_retries': 3, 'countdown': 3},time_limit=200
)
def http_request(url: str, json_data: dict, timeout: float = 10.0,headers: dict = None,webhook_url: str = None # 新增webhook参数
):"""同步HTTP POST请求:param url: 请求地址:param json_data: POST的JSON数据:param timeout: 超时时间(秒):param headers: 可选请求头:webhook_url: 回调通知地址(可选)"""# 设置默认headersfinal_headers = {"Content-Type": "application/json"}if headers:final_headers.update(headers)try:# 1. 执行主请求with httpx.Client() as client:resp = client.post(url,json=json_data,timeout=Timeout(timeout),headers=headers or {"Content-Type": "application/json"})resp.raise_for_status()result = resp.json()# 2. 如果配置了webhook则回调if webhook_url:# 【主请求】webhook_payload = {"status": "success","task_result": result,"task_for": json_data.get("task_for", "tem"),"function": json_data.get("function", "tem"),"rec_id": json_data.get("rec_id", str(int(time.time()*1e6))),"metadata": {"source_url": url,"timestamp": get_time_str1()}}try:with httpx.Client() as client:callback_resp = client.post(webhook_url,json=webhook_payload,timeout=5.0)callback_resp.raise_for_status()except Exception as e:print(f"Webhook回调失败: {str(e)}")# 这里不建议raise,因为主请求已成功return resultexcept httpx.HTTPStatusError as e:# 处理HTTP状态码错误error_result = {"error": str(e),"status_code": e.response.status_code,"response": e.response.text}if webhook_url:# 即使主请求失败也尝试发送webhooktry:with httpx.Client() as client:client.post(webhook_url,json={"status": "error","error": error_result,"metadata": {"source_url": url,"timestamp": get_time_str1()}},timeout=5.0)except Exception:passreturn error_result
主要改进点:
-
1.错误处理更完善:
- 1 保留了resp.raise_for_status()以确保HTTP状态码正确
- 2 对主请求和webhook请求分别处理异常
-
2.headers处理更规范:
- 1 先设置默认headers再合并自定义headers
-
3.webhook逻辑优化:
- 1 即使主请求失败也会尝试发送错误通知
- 2 webhook失败不再影响主任务结果
-
4.代码结构更清晰:
- 1 使用嵌套的try-except块区分不同层级的错误
- 2 添加了更详细的注释和文档字符串
- 资源管理:
- 1 为webhook请求也使用了Client上下文管理器
调用如下:不带webhook的模式
# 获取等待
from celery_app import http_request
test_url ="https://httpbin.org/post"task = http_request.delay(**{"url": test_url,"json_data": {"key": "value"},"timeout": 5.0
})
try:# 阻塞等待结果(超时时间建议大于Celery的time_limit)result = task.get(timeout=30) # 最多等待30秒print("Result:", result)
except Exception as e:print("Task failed:", str(e))Result: {'args': {}, 'data': '{"key": "value"}', 'files': {}, 'form': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Content-Length': '16', 'Content-Type': 'application/json', 'Host': 'httpbin.org', 'User-Agent': 'python-httpx/0.27.2', 'X-Amzn-Trace-Id': 'Root=1-67e811ed-257a775a7be6f5f56666bbcc'}, 'json': {'key': 'value'}, 'origin': '45.126.120.54', 'url': 'https://httpbin.org/post'}
带webhook的模式:
webhook_url="https://your-webhook.example.com/notify"
from celery_app import http_request
test_url ="https://httpbin.org/post"
task = http_request.delay(**{"url": test_url,"json_data": {"key": "value"},"timeout": 5.0,'webhook_url':webhook_url
})
try:# 阻塞等待结果(超时时间建议大于Celery的time_limit)result = task.get(timeout=30) # 最多等待30秒print("Result:", result)
except Exception as e:print("Task failed:", str(e))Result: {'args': {}, 'data': '{"key": "value"}', 'files': {}, 'form': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Content-Length': '16', 'Content-Type': 'application/json', 'Host': 'httpbin.org', 'User-Agent': 'python-httpx/0.27.2', 'X-Amzn-Trace-Id': 'Root=1-67e8127d-4cd39ca9145a9e095d0ba9f5'}, 'json': {'key': 'value'}, 'origin': '45.126.120.54', 'url': 'https://httpbin.org/post'}
对应的服务器信息:可以看到虚拟的webhook有问题,但是不影响返回。之后我做好一个专门的微服务来处理就可以了。
[2025-03-29 23:32:14,774: WARNING/MainProcess] Webhook回调失败: [Errno -2] Name or service not known
[2025-03-29 23:32:14,853: INFO/MainProcess] Task celery_app.http_request[8a5bb464-6a7e-49e2-bd04-3a5658f8bf91] succeeded in 2.476185337989591s: {'args': {}, 'data': '{"key": "value"}', 'files': {}, 'form': {}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, br, zstd', 'Content-Length': '16', 'Content-Type': 'application/json', 'Host': 'httpbin.org', 'User-Agent': 'python-httpx/0.27.2', 'X-Amzn-Trace-Id': 'Root=1-67e8127d-4cd39ca9145a9e095d0ba9f5'}, 'json': {'key': 'value'}, 'origin': '45.126.120.54', 'url': 'https://httpbin.org/post'}
callback 和 webhook,我的理解是一样的东西,实现的机制不同。webhook出现的更晚,应该是更好一些的。callback的问题是耦合太紧了,webhook比较灵活。


还有另外两种返回的方法 SSE、WebSocket都需要借助Web服务器实现【FastAPI】。
SSE的样例
server.py 服务器端代码
from fastapi import FastAPI, Response
from fastapi.responses import StreamingResponse
from celery.result import AsyncResultapp = FastAPI()@app.post("/run-task")
async def run_task():# 提交Celery任务task = http_request.delay(url="https://api.example.com", json_data={"key": "value"})return {"task_id": task.id} # 立即返回task_id@app.get("/task-events/{task_id}")
async def stream_task_events(task_id: str):"""SSE事件流端点"""async def event_generator():result = AsyncResult(task_id)while not result.ready():# 推送等待状态yield {"event": "status","data": {"status": "pending", "task_id": task_id}}await asyncio.sleep(1) # 检查间隔# 任务完成时推送结果yield {"event": "result","data": {"status": "completed","result": result.result,"task_id": task_id}}return StreamingResponse(event_generator(),media_type="text/event-stream",headers={"Cache-Control": "no-cache"})
js 前端代码
// 1. 首先提交任务
const startTask = async () => {const res = await fetch('/run-task', {method: 'POST'});const {task_id} = await res.json();listenToTaskEvents(task_id);
};// 2. 监听SSE事件
const listenToTaskEvents = (task_id) => {const eventSource = new EventSource(`/task-events/${task_id}`);eventSource.addEventListener('status', (e) => {console.log('Status update:', JSON.parse(e.data));});eventSource.addEventListener('result', (e) => {console.log('Final result:', JSON.parse(e.data));eventSource.close(); // 关闭连接});eventSource.onerror = () => {console.error('SSE error');eventSource.close();};
};// 触发任务
startTask();
websocket方式
server.py
# 示例:FastAPI + WebSocket
@app.websocket("/task-status/{task_id}")
async def websocket_task_status(websocket: WebSocket, task_id: str):await websocket.accept()result = AsyncResult(task_id)while not result.ready():await asyncio.sleep(0.5)await websocket.send_json({"status": "completed","result": result.result})
SSE和WebSocket方式我还不那么熟,回头可以试试看。SSE看起来是Stream的方式,这个和大模型实时返回有点像,websocket主要是用了新的协议,是可以在连接中双向交互的,适合实时对话的场景。
到这里写的有点太长了,我自己也没想到。还有一部分是关于FastAPI和Celery融合起来的(可以看到,如果想通过接口使用,还是要微服务);然后再写一个ORM来进行简便控制。这篇看明天能不能写出来吧。