有什么好的网站可以接单子做竞价排名
目录
前言
一,HTTP协议
1,认识URL
2,urlencode和urldecode
3,HTTP协议请求与响应格式
二,myhttp服务器端代码的编写
HTTP请求报文示例
HTTP应答报文示例
代码编写
网络通信模块
处理请求和发送应答模块
结果展示
完整代码
main.cc 文件
http.hpp文件
makefile
相关测试网页(html形式)
前言
虽然说,应用层协议是需要我们程序猿自己定的。但是实际上,已经有大佬们定义了一些现成的,非常好用的应用层协议,供我们直接使用 。HTTP(超文本传输协议 )就是其中之一。
在互联网世界中,HTTP(HyperText Transfer Protocol,超文本传输协议)是一个至关重要的协议。它定义了客户端(如浏览器)与服务器之间如何进行通信,以交换或传输超文本(如HTML)。
一,HTTP协议
HTTP协议是客户端与服务器之间通信的基础。客户端通过HTTP协议向服务器发送请求,服务器收到请求后处理并返回响应。
1,认识URL
URL是Uniform Resource Location的缩写,译为“统一资源定位符”。
我们平时所说的网址,就是URL,例如:

- 开始部分https:表示我们获取资源采用的协议,这里的https起始是对http协议的一种加密,这里我们看作是http。
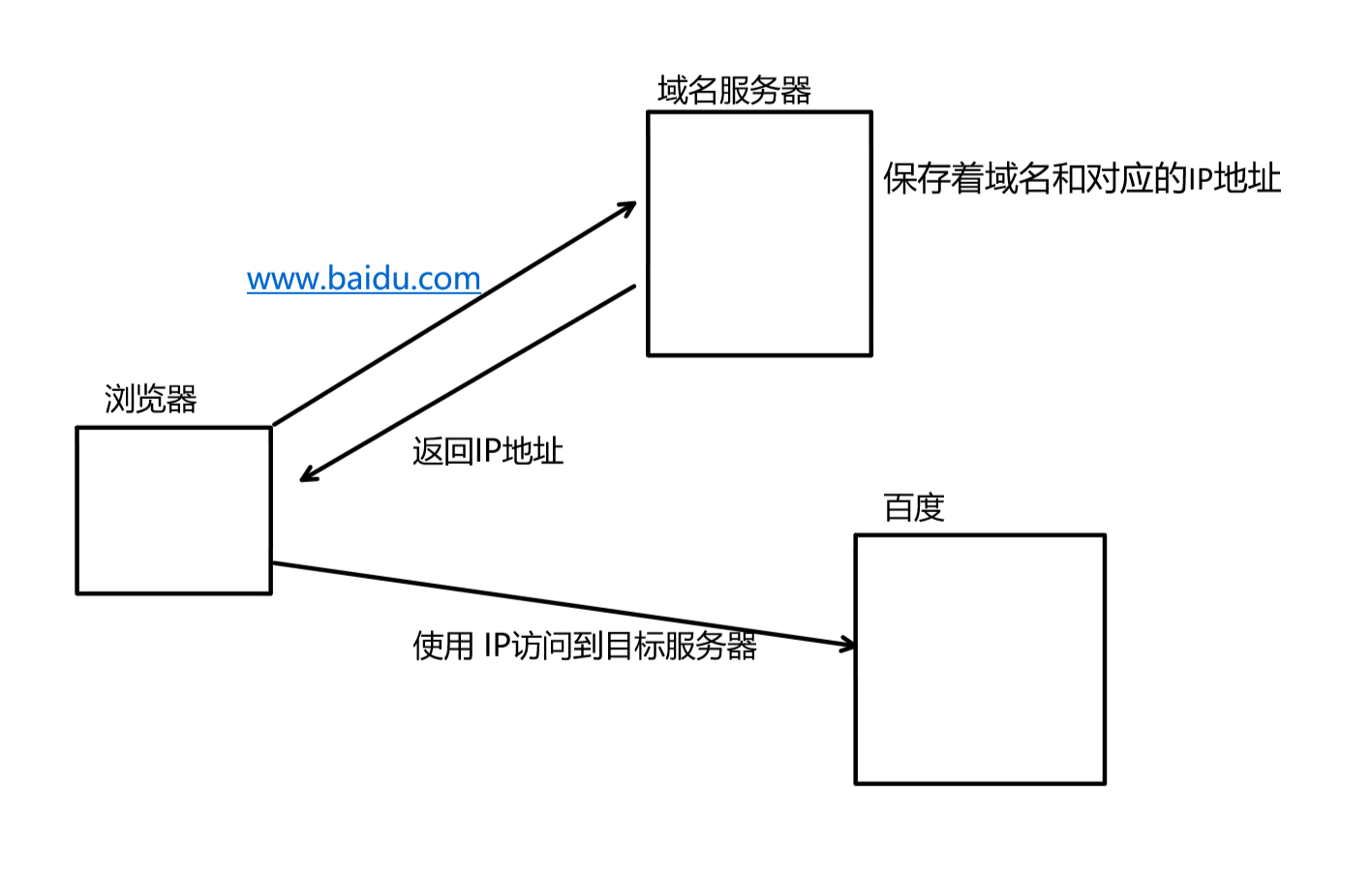
- news.qq.com:这一部分表示域名,通过域名 可以找到要访问服务器的IP地址。如何找到呢?
- 域名服务器是网络中的基础设施建设,内部保存着域名和对应的IP地址,当时使用浏览器访问百度时,浏览器内部一般内置了域名服务器的IP地址,比如8.8.8.8。通过域名服务器获取到IP地址,这个过程叫做DNS。最后进行对目标服务器的访问。
- 但是,要访问目标服务器,需要知道IP地址+端口号,IP地址可以通过域名 获取到,但是端口号呢?其实,对于这些成熟的协议,端口号是固定的。https对应的端口号是443,http对应的端口号是80,ssh对应的端口号是22。
- 而域名之后的剩余部分,/ch/tech:是我们要访问的资源路径。可以发现,其中"/",就是linux下的路径分割符,所以该部分就代表linux系统下的一个特定路径。
- 而我们上网的行为分为两种,一个是从远端拿下来数据,另一个是将数据上传到远端,这其实就是IO。而我们想从远端拿下来数据时,就是获取资源,这些资源在哪呢?就在linux服务器内部,特定路径下的一个文件。
- 通过这条URL,域名可以找到IP(具有唯一性),而路径,目标机器上特定 路径下的一个文件(也具有唯一性),所以通过URL可以定位到全网内特定的一个文件。
2,urlencode和urldecode
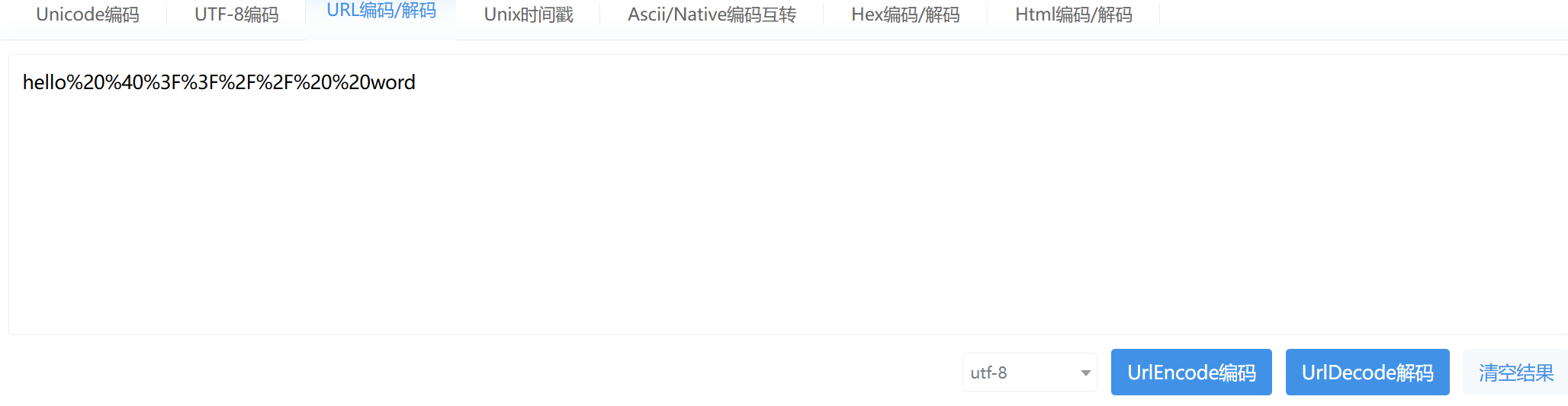
像?/:这样的字符,已经被当作特殊字符理解了。因此这些字符不能随意出现。如果出现了这些特殊意义的字符,需要客户端(一般是浏览器)对这些特殊字符进行编码(encode)。服务器自己需要进行解码decode。示例:
hello @??// word编码后的结果是:
解码后的结果是:
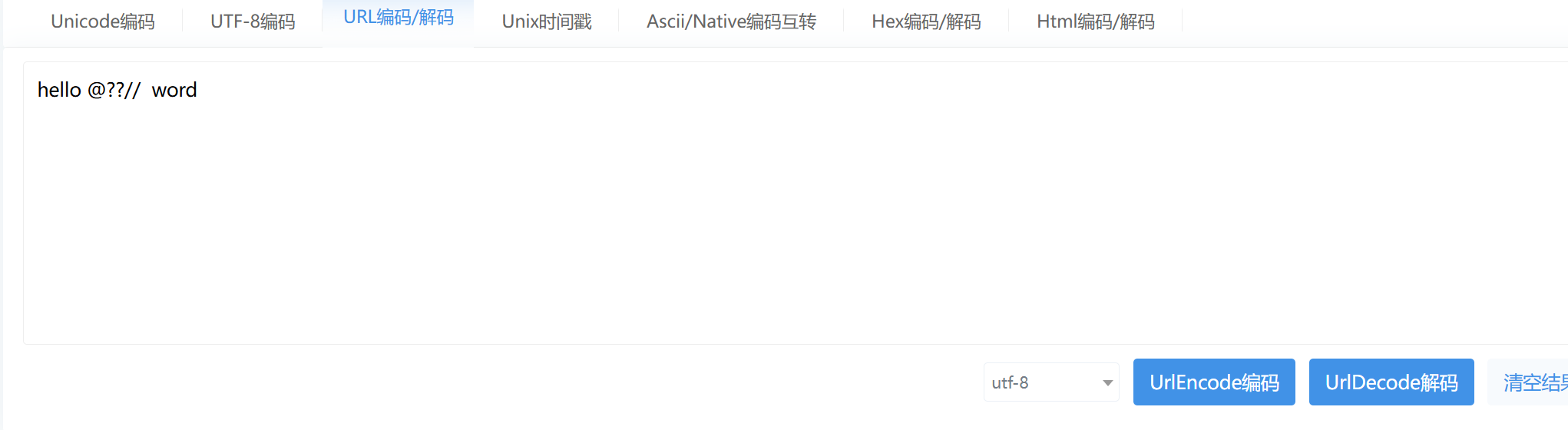
工具: UrlEncode编码/UrlDecode解码 - 站长工具
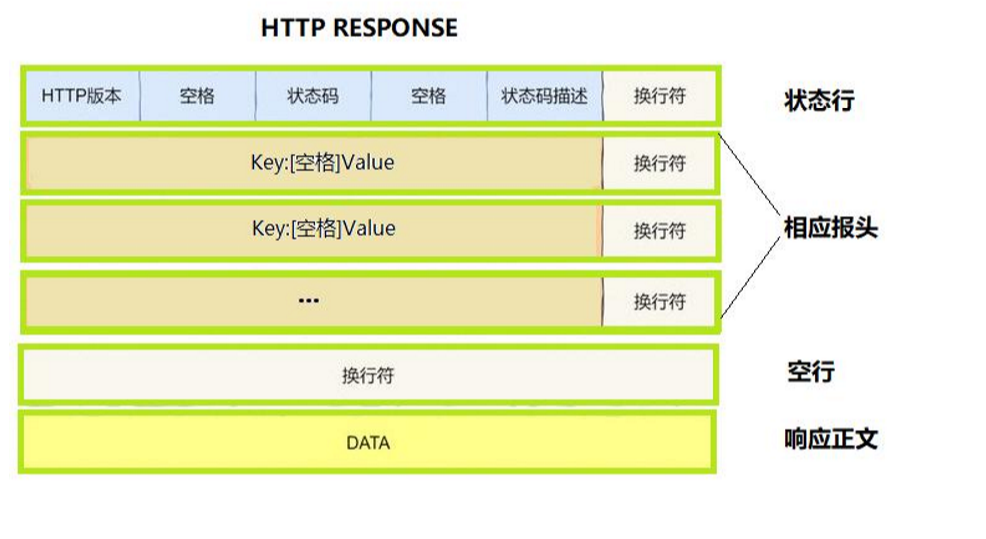
3,HTTP协议请求与响应格式
HTTP底层使用的是tcp协议。
HTTP请求(request)
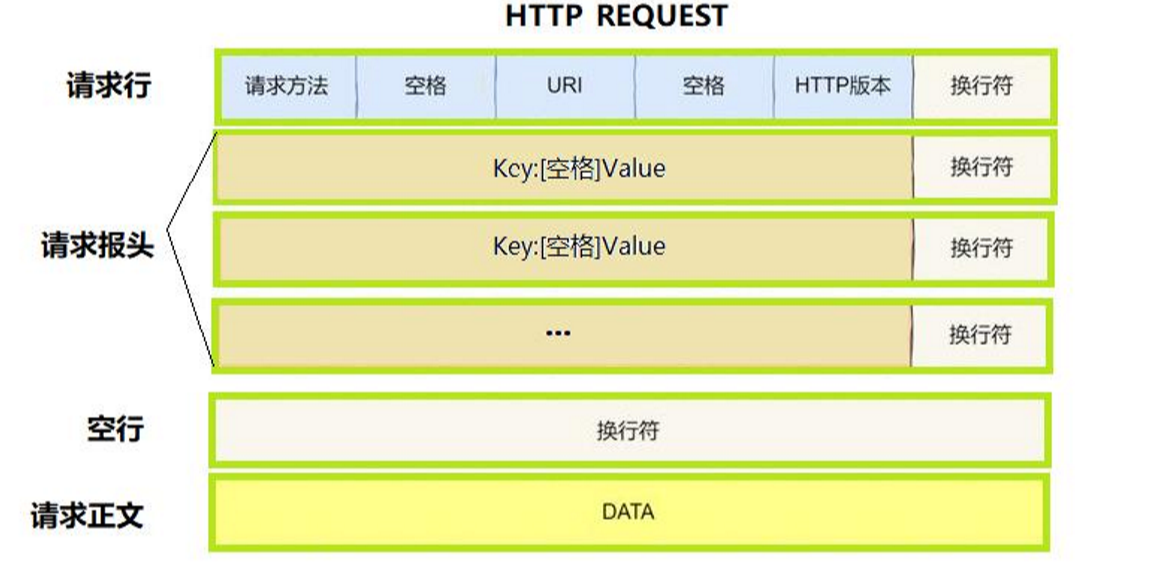
首行:【方法】+【url】+【版本号】
Header:请求的属性,以冒号分割的键值对。每组属性之间使用\r\n分割,遇到空行表示Header结束。
DATA:空行后面的内容都是DATA。DATA允许为空。
HTTP响应格式(response),与请求格式类似。
二,myhttp服务器端代码的编写
HTTP请求报文示例
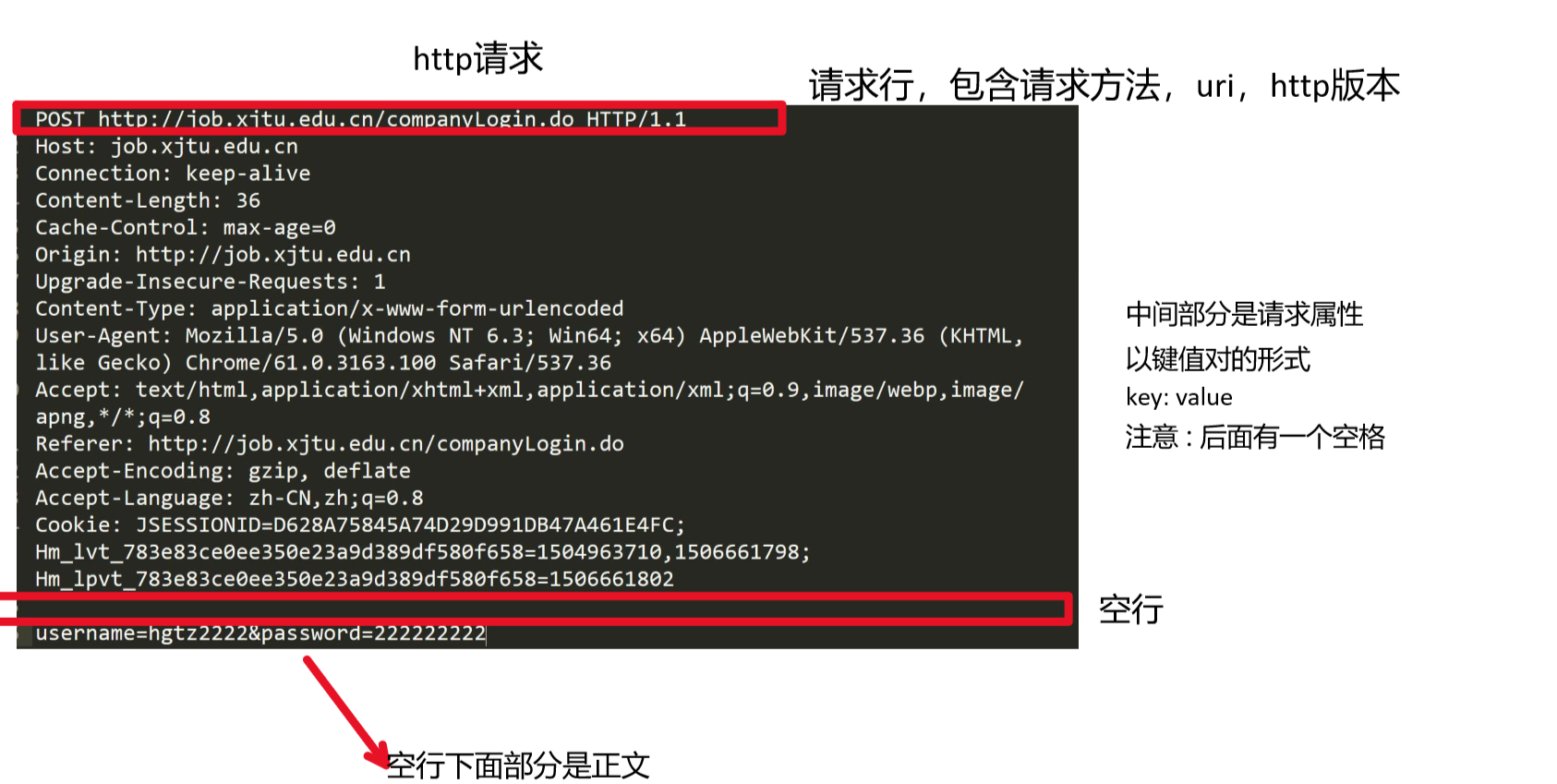
- 这里的uri是统一资源定位符,它的作用是,可以唯一的标识资源,并允许用户通过特定的协议与资源进行交互。而前面提到的url,是统一资源标识符,url是uri的一种形式。
- 在上面的内容中提到过,url统一资源标识符,也就是网址。它的域名之后的内容,其实是特定linux机器上的特定路径的一个文件,我们使用 url(网址)的时候,其实就是访问目标主机上特定路径下的一个文件。
- 在这里,请求行中的uri,也代表要访问的路径 。
- 需要注意的是,在uri中 ,"/"不是指linux下的根目录,而是web根目录。什么是web根目录?就是和当前项目在同一级的一个目录,其内部可能包含网址,图片,视频等等各种资源,所以我们实际访问的其实是是web根目录下的资源。
将整个请求看作是一个大的字符串,中间使用\r\n,或者使用一些空格,空行分割。
编写代码时的想法:
- 为了表示这个大字符串,我们可以定义一个Request请求类来管理。
- 类中的成员就包含请求行的三个属性,用三个字符串表示即可。中间部分是以键值对的形式,所以可以使用unordered_map来存储,还有一个空行,和正文部分,使用string即可。
- 当我们的服务器端收到这个请求报文时,就需要对这个大字符串进行反序列化,填充类中的成员。也就是将这个大的字符串,转化为结构化数据。
HTTP应答报文示例
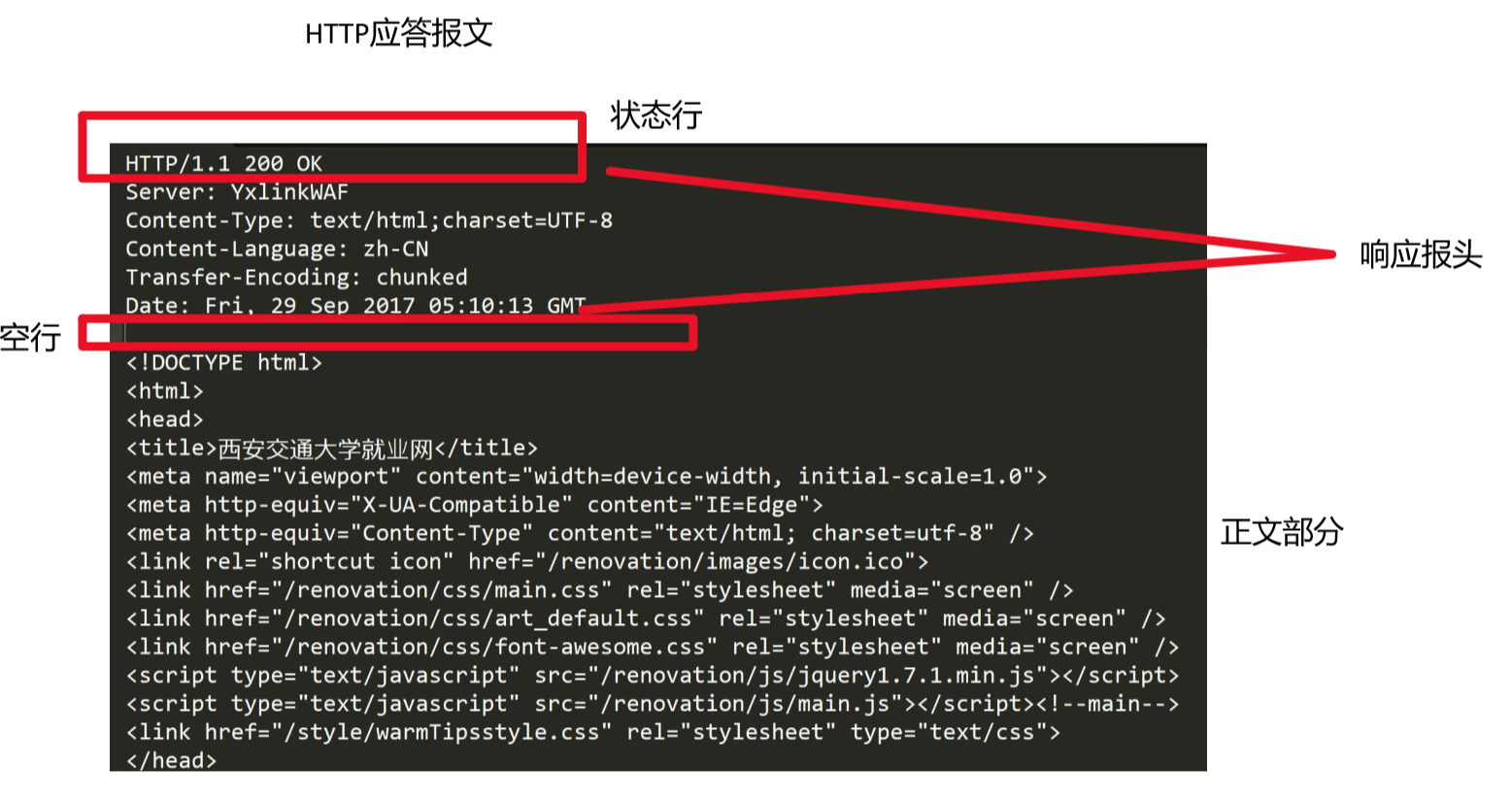
和请求报文结构类似。
- 同样我们定义一个response应答类,和request类似。从上图可以看出,其实正文部分,就是一个html,是我们要返回给客户端的一个网页。也就是客户端想要访问的资源。
- 将来我们的response类中一定会包含一个string _text。表示正文部分。我们拖过客户端发来的请求报文,可以知道客户端想要访问是么资源,可以查看uri。如果我们将资源硬编码到代码中,那么就只可以访问一个文件。比如将html文件,当成一个大字符串,_text存储这个大字符串。那么我们在发送应答的时候,返回的就永远是这一个资源,所以不能将资源硬编码到代码中。
- 我们可以根据客户端发来的请求,提取uri,找到要访问的资源。然后以打开该文件,再读取文件中的内容即可。
- 最后发送 给客户端,需要我们将类中的成员序列化成一个大的字符串。也就是将结构化数据,转化为大的字符串。
代码编写
- 现在我们大概了解了HTTP协议的请求格式和应答格式。接下来使用浏览器作为客户端,发送请求,接受应答。我们自己编写一个myhttp服务器,对客户端发来的HTTP请求做解析,然后返回给客户端应答。
- HTTP协议是基于tcp的。
- 在这里使用多进程的方式,父进程不停的获取连接,子进程不断处理连接。
首先是网络通信部分代码:
核心逻辑:
- 服务端
- 创建套接字 → 绑定地址 → 监听连接 → 接受请求 → 读取数据 → 回传数据。
网络通信模块
const int gbacklog = 8;
int main(int argc, char *argv[])
{// 1,创建套接字int listenfd = socket(AF_INET, SOCK_STREAM, 0);if (listenfd < 0){std::cerr << "创建监听套接字失败" << std::endl;exit(1);}// 从命令行参数中获取端口号uint16_t port = std::stoi(argv[1]);// 填写sockaddr_in结构体,注意主机序列转化为网络字节序struct sockaddr_in addr;int addrlen = sizeof(addr);addr.sin_family = AF_INET;addr.sin_port = htons(port);addr.sin_addr.s_addr = INADDR_ANY;// 2,绑定端口号和ip地址int n = bind(listenfd, (struct sockaddr *)&addr, sizeof(addr));if (n < 0){std::cerr << "绑定失败" << std::endl;exit(2);}// 3,开始监听int s = listen(listenfd, gbacklog);if (s < 0){std::cerr << "监听失败" << std::endl;exit(3);}// 4,获取连接,处理连接while (true){int sockfd = accept(listenfd, (struct sockaddr *)&addr, (socklen_t *)&addrlen);if (n < 0){std::cerr << "获取连接失败" << std::endl;continue; // 继续获取}// 创建子进程处理请求pid_t id = fork();if (id == 0){// 子进程// 关闭不需要的文件描述符close(listenfd);if (fork() > 0)exit(0); // 子进程退出// 孙子进程 处理请求handle_request(sockfd);// 孙子进程退出exit(0);}else if (id > 0){// 父进程// 关闭不需要的文件描述符close(sockfd);pid_t rid=::waitpid(id,nullptr,0);(void)rid;}else{std::cerr << "创建子进程失败" << std::endl;}}return 0;
}至此实现了网络通信的功能。 通过回调函数处理客户端(浏览器)发送过来的请求。
处理请求和发送应答模块
- 接下来就是子进程处理请求。
- 现在实现requet类和response类,其中request需要实现反序列化,将大字符串变成一个结构化数据。而response需要实现序列化,将序列化数据转化为结构化数据。
- 需要注意的是,我们在给客户端发送应答报文的时候,必须要发送状态行(也就是报文的第一行),它包含了HTTP版本,状态码和状态码描述,这些是必须返回给客户端的,而其他的内容 可以不发。
通过回调方法处理请求,发送应答
// 定义一个回调方法,处理请求
void handle_request(int sockfd)
{char buffer[BUFFER_SIZE];// 读取请求报文ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1,0);if (n > 0){buffer[n] = 0;//for debug//std::cout<<buffer<<std::endl;Request req;// 将读取到的字符串反序列为请求对象req.Deserilaze(buffer);// 构建应答报文Response resp;//获取客户端想要访问的资源文件resp.SetTargetFile(req.GetUri());//for debug//std::cout<<"##############################"<<std::endl;//std::cout<<req.GetUri()<<std::endl;//std::cout<<"##############################"<<std::endl;// 将目标文件内容填写到正问部分resp.SetText();resp._version = "HTTP/1.1";resp._code = 200; // successresp._desc = "OK";// 反序列化std::string resp_str = resp.Serilaze();// 发送应答报文send(sockfd, resp_str.c_str(), resp_str.size(),0);}
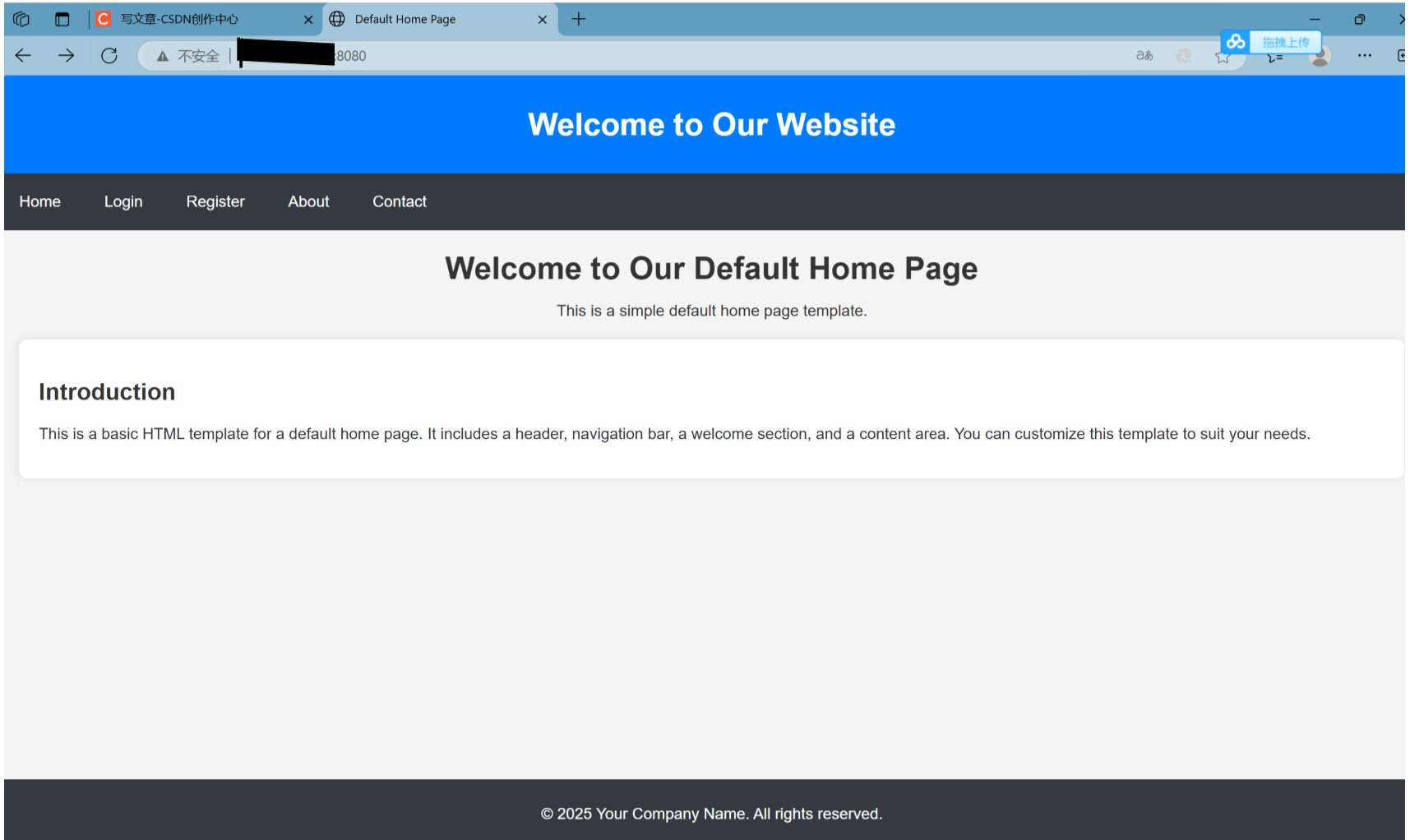
}结果展示
之后通过浏览器访问我们的http服务,所获得的网页。
完整代码
main.cc 文件
// 服务器端
// 基于HTTP协议
#include "http.hpp"
#include <sys/wait.h>// 缓冲区大小
#define BUFFER_SIZE 4096// 定义一个回调方法,处理请求
void handle_request(int sockfd)
{char buffer[BUFFER_SIZE];// 读取请求报文ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1,0);if (n > 0){buffer[n] = 0;//for debug//std::cout<<buffer<<std::endl;Request req;// 将读取到的字符串反序列为请求对象req.Deserilaze(buffer);// 构建应答报文Response resp;//获取客户端想要访问的资源文件resp.SetTargetFile(req.GetUri());//for debug//std::cout<<"##############################"<<std::endl;//std::cout<<req.GetUri()<<std::endl;//std::cout<<"##############################"<<std::endl;// 将目标文件内容填写到正问部分resp.SetText();resp._version = "HTTP/1.1";resp._code = 200; // successresp._desc = "OK";// 反序列化std::string resp_str = resp.Serilaze();// 发送应答报文send(sockfd, resp_str.c_str(), resp_str.size(),0);}
}
const int gbacklog = 8;
int main(int argc, char *argv[])
{// 1,创建套接字int listenfd = socket(AF_INET, SOCK_STREAM, 0);if (listenfd < 0){std::cerr << "创建监听套接字失败" << std::endl;exit(1);}// 从命令行参数中获取端口号uint16_t port = std::stoi(argv[1]);// 填写sockaddr_in结构体,注意主机序列转化为网络字节序struct sockaddr_in addr;int addrlen = sizeof(addr);addr.sin_family = AF_INET;addr.sin_port = htons(port);addr.sin_addr.s_addr = INADDR_ANY;// 2,绑定端口号和ip地址int n = bind(listenfd, (struct sockaddr *)&addr, sizeof(addr));if (n < 0){std::cerr << "绑定失败" << std::endl;exit(2);}// 3,开始监听int s = listen(listenfd, gbacklog);if (s < 0){std::cerr << "监听失败" << std::endl;exit(3);}// 4,获取连接,处理连接while (true){int sockfd = accept(listenfd, (struct sockaddr *)&addr, (socklen_t *)&addrlen);if (n < 0){std::cerr << "获取连接失败" << std::endl;continue; // 继续获取}// 创建子进程处理请求pid_t id = fork();if (id == 0){// 子进程// 关闭不需要的文件描述符close(listenfd);if (fork() > 0)exit(0); // 子进程退出// 孙子进程 处理请求handle_request(sockfd);// 孙子进程退出exit(0);}else if (id > 0){// 父进程// 关闭不需要的文件描述符close(sockfd);pid_t rid=::waitpid(id,nullptr,0);(void)rid;}else{std::cerr << "创建子进程失败" << std::endl;}}return 0;
}http.hpp文件
#pragma once
#include <iostream>
#include <string>
#include <sys/types.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include <unistd.h>
#include <unordered_map>
#include <sstream>
#include <fstream>const std::string gspace = " ";
const std::string glinespace = "\r\n";
const std::string glinesep = ": ";
// web根目录
const std::string webroot = "./wwwroot";
// 默认访问的首页
const std::string homepage = "index.html";// http协议
// 包含请求和应答
// 请求
class Request
{
public:Request(){}~Request(){}// 反序列化接口bool Deserilaze(std::string bigstr){std::string reqline;// 读取第一行,第一行的末尾是"\r\n"// 所以在字符串中找到"\r\n"的位置,截取前面部分即可auto pos = bigstr.find(glinespace);if (pos == std::string::npos)return false; // 不包含完整的请求// 获取到第一行的内容reqline = bigstr.substr(0, pos);// 将第一行进行反序列化std::stringstream ss(reqline);ss >> _method >> _uri >> _version;if (_uri == "/") // 表示要访问的资源就是web根目录下的首页_uri = webroot + _uri + homepage;else_uri = webroot + _uri; // 表示要访问特定路径下的资源// 删除第一行bigstr.erase(0, pos + glinespace.size());return true;}std::string GetUri(){return _uri;}private:std::string _method; // 请求方法std::string _uri; // uristd::string _version; // http版本// 请求报头std::unordered_map<std::string, std::string> _headers;// 空行std::string _blankline;// 正文std::string _text;
};// 应答
class Response
{
public:Response():_blankline(glinespace){}~Response(){}// 序列化std::string Serilaze(){// 状态行std::string status_line = _version + gspace + std::to_string(_code) + gspace + _desc + glinespace;// 响应报头std::string resp_header;for (auto &header : _headers){std::string line = header.first + glinesep + header.second + glinespace;resp_header += line;}return status_line + resp_header + _blankline + _text;}// 设置想要访问的资源文件void SetTargetFile(const std::string file){_targetfile = file;}//将目标文件填写入正文部分void SetText(){std::ifstream in(_targetfile);if(!in.is_open()){return ;}std::string line;while(std::getline(in,line)){_text+=line;}in.close();}public:std::string _version; // http版本int _code; // 退出码std::string _desc; // 描述退出码的退出信息// 应答报头std::unordered_map<std::string, std::string> _headers;// 空行std::string _blankline;// 正文std::string _text;// 文件,用来填充正文std::string _targetfile;
};makefile
myhttp:main.ccg++ -o $@ $^ -std=c++17
.PHONY:clean
clean:rm -f myhttp相关测试网页(html形式)
index.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Default Home Page</title><style>body {font-family: Arial, sans-serif;margin: 0;padding: 0;background-color: #f4f4f4;color: #333;}header {background-color: #007bff;color: #fff;padding: 10px 20px;text-align: center;}nav {background-color: #343a40;padding: 10px 0;}nav a {color: #fff;text-decoration: none;padding: 10px 20px;display: inline-block;}nav a:hover {background-color: #5a6268;}.container {padding: 20px;}.welcome {text-align: center;margin-bottom: 20px;}.welcome h1 {margin: 0;}.content {background-color: #fff;padding: 20px;border-radius: 8px;box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);}footer {background-color: #343a40;color: #fff;text-align: center;padding: 10px 0;position: fixed;width: 100%;bottom: 0;}</style>
</head>
<body><header><h1>Welcome to Our Website</h1></header><nav><a href="#">Home</a><a href="Login.html">Login</a> <!-- 跳转到登录页面 --><a href="Register.html">Register</a> <!-- 跳转到注册页面 --><a href="#">About</a><a href="#">Contact</a></nav><div class="container"><div class="welcome"><h1>Welcome to Our Default Home Page</h1><p>This is a simple default home page template.</p></div><div class="content"><h2>Introduction</h2><p>This is a basic HTML template for a default home page. It includes a header, navigation bar, a welcome section, and a content area. You can customize this template to suit your needs.</p></div></div><footer><p>© 2025 Your Company Name. All rights reserved.</p></footer>
</body>
</html>Login.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Login Page</title><style>body {font-family: Arial, sans-serif;background-color: #f4f4f4;display: flex;justify-content: center;align-items: center;height: 100vh;margin: 0;}.login-container {background-color: #fff;padding: 20px;border-radius: 8px;box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);width: 300px;text-align: center;}.login-container h2 {margin-bottom: 20px;}.form-group {margin-bottom: 15px;}.form-group label {display: block;margin-bottom: 5px;text-align: left;}.form-group input {width: 100%;padding: 10px;border: 1px solid #ccc;border-radius: 4px;}.form-group input[type="submit"] {background-color: #007bff;color: #fff;border: none;cursor: pointer;}.form-group input[type="submit"]:hover {background-color: #0056b3;}</style>
</head>
<body><div class="login-container"><h2>Login</h2><form action="/login" method="post"><div class="form-group"><label for="username">Username</label><input type="text" id="username" name="username" required></div><div class="form-group"><label for="password">Password</label><input type="password" id="password" name="password" required></div><div class="form-group"><input type="submit" value="Login"></div></form></div>
</body>
</html>Register.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Register Page</title><style>body {font-family: Arial, sans-serif;background-color: #f4f4f4;display: flex;justify-content: center;align-items: center;height: 100vh;margin: 0;}.register-container {background-color: #fff;padding: 20px;border-radius: 8px;box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);width: 350px;text-align: center;}.register-container h2 {margin-bottom: 20px;}.form-group {margin-bottom: 15px;}.form-group label {display: block;margin-bottom: 5px;text-align: left;}.form-group input {width: 100%;padding: 10px;border: 1px solid #ccc;border-radius: 4px;}.form-group input[type="submit"] {background-color: #28a745;color: #fff;border: none;cursor: pointer;}.form-group input[type="submit"]:hover {background-color: #218838;}</style>
</head>
<body><div class="register-container"><h2>Register</h2><form action="/register" method="post"><div class="form-group"><label for="username">Username</label><input type="text" id="username" name="username" required></div><div class="form-group"><label for="email">Email</label><input type="email" id="email" name="email" required></div><div class="form-group"><label for="password">Password</label><input type="password" id="password" name="password" required></div><div class="form-group"><label for="confirm-password">Confirm Password</label><input type="password" id="confirm-password" name="confirm-password" required></div><div class="form-group"><input type="submit" value="Register"></div></form></div>
</body>
</html>