个人备案的网站 做企业站百度一下你知道主页官网
文章目录
- 一、生成数据集
- 二、数据导入
- 1. Csv/Excel数据集方式导入
- 1.1 新建文件夹
- 1.2 新建数据集
- 2. 数据库表方式导入
- 2.1 把图书数据集导入MySQL
- 2.2 连接数据库
- 2.3 新建数据集
一、生成数据集
该 Python 脚本通过 Faker 库和自定义函数,能够生成涵盖图书 ID、书名、作者等 10 个核心字段的 50000 条图书数据,其中类别覆盖 15 个图书领域,出版社来自 15 家主流机构,价格、评分等数据均符合实际分布,采用标准 ISBN-13 编码规则生成 ISBN,最终将数据以 CSV/EXCEL 文件格式输出,为 FineBI 的数据分析与可视化提供优质数据源。
import csv
import randomfrom faker import Faker
from openpyxl import Workbook
from openpyxl.styles import Font
from openpyxl.utils import get_column_letter# 创建Faker实例,用于生成随机数据
fake = Faker('zh_CN')# 预设数据
CATEGORIES = ['文学', '历史', '哲学', '科学', '技术', '经济', '管理', '心理学', '社会学', '艺术', '医学', '教育','计算机', '外语', '工具书']
PUBLISHERS = ['人民文学出版社', '商务印书馆', '三联书店', '中信出版社', '机械工业出版社', '电子工业出版社','清华大学出版社', '北京大学出版社', '中国人民大学出版社', '科学出版社', '化学工业出版社','人民教育出版社', '上海译文出版社', '新星出版社', '广西师范大学出版社']def generate_isbn():"""生成随机ISBN-13"""prefix = '978'base = ''.join([str(random.randint(0, 9)) for _ in range(9)])checksum = str((10 - (sum(int(base[i]) * (3 if i % 2 else 1) for i in range(9)) + int(prefix) * 1) % 10) % 10)return f"{prefix}-{base}-{checksum}"def generate_book_data(num_books=100):"""生成图书数据"""books = []for i in range(1, num_books + 1):# 图书IDbook_id = f"BK{i:05d}"# 书名title = fake.sentence(nb_words=3, variable_nb_words=True).rstrip('.')# 作者(1-3位)author_count = random.randint(1, 3)authors = ', '.join([fake.name() for _ in range(author_count)])# 出版社publisher = random.choice(PUBLISHERS)# 出版年份(2000-2023)year = random.randint(2000, 2023)# 类别category = random.choice(CATEGORIES)# ISBNisbn = generate_isbn()# 价格(20-200元)price = round(random.uniform(20, 200), 2)# 评分(2.0-5.0)rating = round(random.uniform(2.0, 5.0), 1)# 评分人数(10-10000)rating_count = random.randint(10, 10000)# 添加到图书列表books.append({'图书ID': book_id,'书名': title,'作者': authors,'出版社': publisher,'出版年份': year,'类别': category,'ISBN': isbn,'价格': price,'评分': rating,'评分人数': rating_count})return booksdef save_to_csv(books, filename='books.csv'):"""将图书数据保存为CSV文件"""try:with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile:fieldnames = ['图书ID', '书名', '作者', '出版社', '出版年份', '类别', 'ISBN', '价格', '评分', '评分人数']writer = csv.DictWriter(csvfile, fieldnames=fieldnames)# 写入表头writer.writeheader()# 写入数据for book in books:writer.writerow(book)print(f"成功生成 {filename} 文件!")except Exception as e:print(f"生成CSV文件时出错:{e}")def save_to_excel(books, filename='books.xlsx'):"""将图书数据保存为Excel文件"""try:# 创建工作簿和活动工作表wb = Workbook()ws = wb.activews.title = "图书数据"# 定义表头fieldnames = ['图书ID', '书名', '作者', '出版社', '出版年份', '类别', 'ISBN', '价格', '评分', '评分人数']# 写入表头并设置字体加粗for col_idx, fieldname in enumerate(fieldnames, 1):cell = ws.cell(row=1, column=col_idx)cell.value = fieldnamecell.font = Font(bold=True)# 写入数据for row_idx, book in enumerate(books, 2): # 从第2行开始for col_idx, fieldname in enumerate(fieldnames, 1):ws.cell(row=row_idx, column=col_idx).value = book.get(fieldname)# 自动调整列宽以适应内容for column in ws.columns:max_length = 0column_letter = get_column_letter(column[0].column)for cell in column:try:if len(str(cell.value)) > max_length:max_length = len(str(cell.value))except:passadjusted_width = (max_length + 2)ws.column_dimensions[column_letter].width = adjusted_width# 保存工作簿wb.save(filename)print(f"成功生成 {filename} 文件!")except Exception as e:print(f"生成Excel文件时出错:{e}")if __name__ == "__main__":# 生成50000条图书数据books = generate_book_data(50000)# 保存为CSV文件save_to_csv(books)# 保存为Excel文件save_to_excel(books)
生成的数据集部分数据如下图所示。

二、数据导入
在 FineBI 数据分析平台中,支持通过以下三种标准化方式实现数据导入,满足不同场景下的数据接入需求:
1. 数据库表直连导入
通过数据库驱动直连主流关系型数据库(如 MySQL、SQL Server、PostgreSQL 等),可直接读取数据库表中的结构化数据。该方式支持实时数据同步,适用于需要基于数据库原始表进行分析的场景,可确保数据与源系统的一致性。
2. SQL 数据集定制导入
利用自定义 SQL 查询语句从数据库中提取特定数据,支持复杂的多表关联、条件筛选、聚合计算等操作。该方式灵活性高,可按需定制分析所需的数据集结构,尤其适合需要对原始数据进行预处理或跨表整合的场景。
3. Csv/Excel 文件数据集导入
支持直接上传本地 Csv 或 Excel 格式文件(如前文生成的图书数据文件),系统会自动识别文件中的字段结构与数据类型。该方式操作简便,适合非技术用户快速导入离线数据,或用于小规模数据集的临时分析。
1. Csv/Excel数据集方式导入
1.1 新建文件夹
新建一个名为图书的文件夹,用于保存导入的数据。

1.2 新建数据集
选择新建Excel数据集,步骤如下图所示。

选择生成的Csv/Excel数据集,并上传Excel数据集,步骤如下图所示。

数据集上传成功后,点击确定,步骤如下图所示。

之后就可以在图书目录下看到上传后的数据集,如下图所示。

2. 数据库表方式导入
2.1 把图书数据集导入MySQL
此处为了方便演示,先在MySQL中创建books数据库,然后把图书数据集导入到MySQL的books数据库中。
在MySQL中创建books数据库,如下图所示。

在books数据库中,右击表,点击导入向导,选择导入类型为CSV文件,如下图所示。

选择生成的books.csv图书数据集,如下图所示。

点击下一步,如下图所示。

点击下一步,如下图所示。

点击下一步,如下图所示。

点击下一步,如下图所示。

点击下一步,如下图所示。

点击开始,如下图所示。

导入完成后点击关闭,如下图所示。

导入后的数据如下图所示。

2.2 连接数据库
在管理系统中找到数据连接管理,点击新建数据连接,在显示的页面中找到MySQL并点击,步骤如下图所示。

在显示的页面中输入数据库的相关信息,测试连接显示成功后,点击保存,如下图所示。
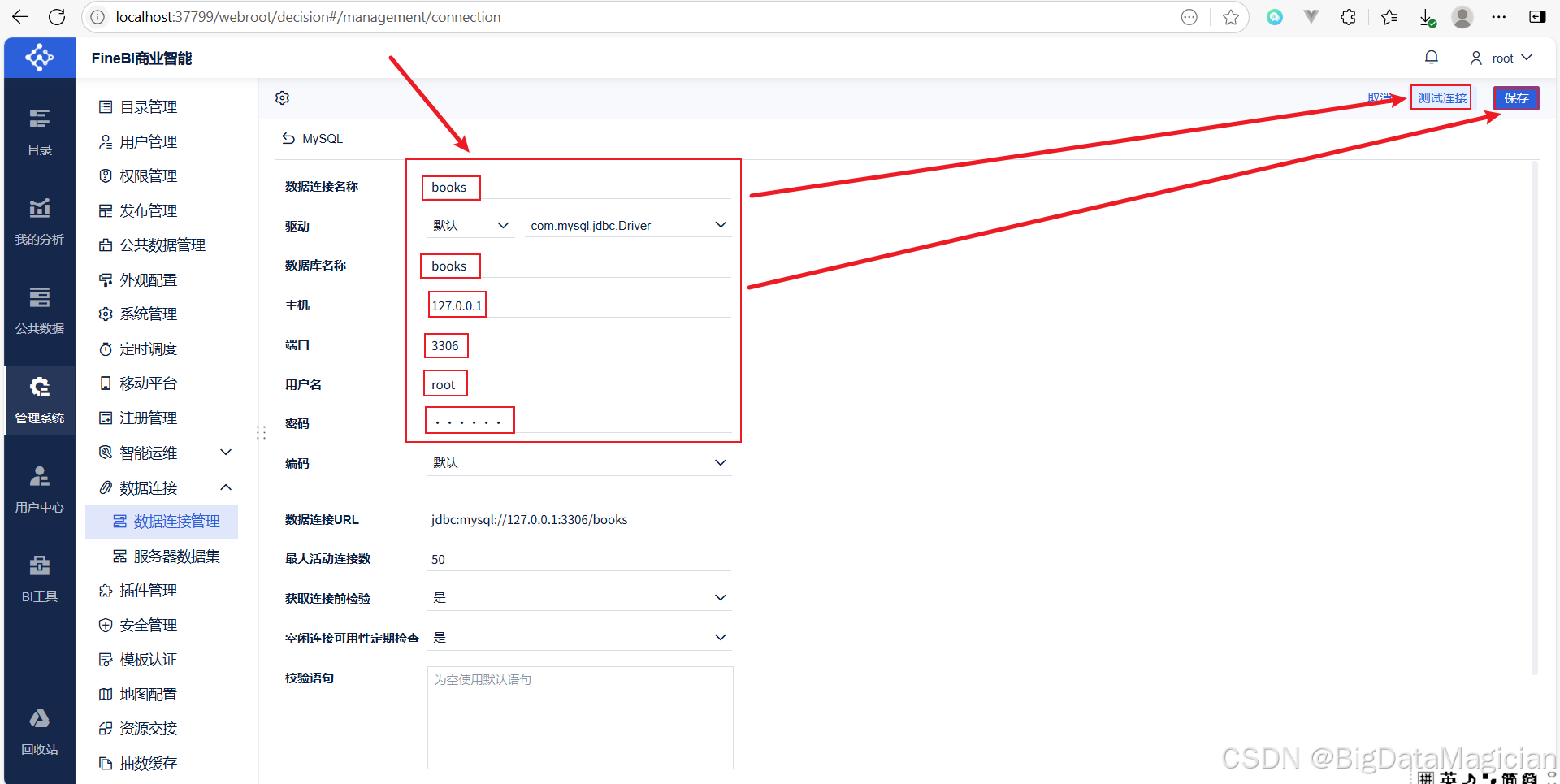
保存成功后,在显示的页面中可以看到books数据库的相关信息,如下图所示。

2.3 新建数据集
点击图书目录,点击新建数据集,选择数据库表方式,选择名称为books的数据连接,选择books数据库,然后点击确定,步骤如下图所示。

数据导入成功后,需要点击更新来更新数据,更新并显示后的数据如下图所示。
