电子政务网站建设方案项目推广渠道有哪些
本节代码实现了一个多头注意力机制(Multi-Head Attention)模块,它是Transformer架构中的核心组件之一。
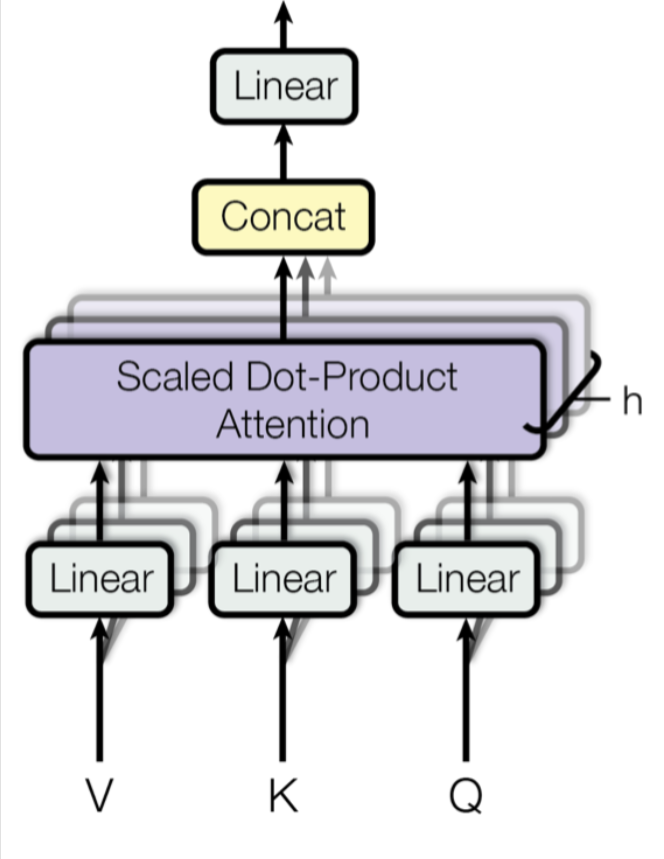
⭐关于多头自注意力机制的数学原理请见文章:
Transformer - 多头自注意力机制复现-CSDN博客
本节要求理解原理后手敲实现多头注意力机制
1. 初始化部分
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_project = nn.Linear(d_model, d_model)self.k_project = nn.Linear(d_model, d_model)self.v_project = nn.Linear(d_model, d_model)self.o_project = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)-
d_model:模型的维度,表示输入的特征维度。 -
num_heads:注意力头的数量。多头注意力机制将输入分成多个不同的“头”,每个头学习不同的特征,最后再将这些特征合并起来。 -
d_k:每个头的维度,计算公式为d_model // num_heads。例如,如果d_model=512,num_heads=8,则每个头的维度为512 // 8 = 64。 -
q_project、k_project、v_project:这三个线性层分别用于将输入x投影到查询(Query)、键(Key)和值(Value)空间。投影后的维度仍然是d_model。 -
o_project:输出投影层,将多头注意力的结果再次投影到d_model维度。 -
dropout:用于防止过拟合的Dropout层。
2. 前向传播部分
def forward(self, x, attn_mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.k_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.v_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)-
输入
x:形状为(batch_size, seq_len, d_model),其中seq_len是序列长度。 -
投影操作:
-
使用
q_project、k_project、v_project将输入x分别投影到查询(Q)、键(K)和值(V)空间。 -
投影后的张量形状为
(batch_size, seq_len, d_model)。
-
-
多头拆分:
-
使用
.view(batch_size, seq_len, self.num_heads, self.d_k)将投影后的张量拆分成多个头,形状变为(batch_size, seq_len, num_heads, d_k)。 -
使用
.transpose(1, 2)将头的维度提到前面,形状变为(batch_size, num_heads, seq_len, d_k)。
-
atten_scores = Q @ K.transpose(2, 3) / math.sqrt(self.d_k)-
计算注意力分数:
-
使用矩阵乘法
@计算Q和K的点积,K.transpose(2, 3)将K的形状变为(batch_size, num_heads, d_k, seq_len)。 -
点积结果的形状为
(batch_size, num_heads, seq_len, seq_len),表示每个位置之间的注意力分数。 -
除以
math.sqrt(self.d_k)是为了防止点积结果过大,导致梯度消失或爆炸。
-
if attn_mask is not None:attn_mask = attn_mask.unsqueeze(1)atten_scores = atten_scores.masked_fill(attn_mask == 0, -1e9)-
注意力掩码(关于掩码的具体实现将在下一篇文章进行讲解):
-
如果提供了注意力掩码
attn_mask,则使用unsqueeze(1)将掩码的形状扩展为(batch_size, 1, seq_len, seq_len)。 -
使用
masked_fill将掩码为0的位置的注意力分数设置为一个非常小的值(如-1e9),这样在softmax计算时,这些位置的注意力权重会接近0。
-
atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ V-
归一化注意力分数:
-
使用
torch.softmax对注意力分数进行归一化,形状仍为(batch_size, num_heads, seq_len, seq_len)。
-
-
计算加权和:
-
使用矩阵乘法
@将归一化后的注意力分数与V相乘,得到每个头的加权和,形状为(batch_size, num_heads, seq_len, d_k)。
-
out = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)out = self.o_project(out)return self.dropout(out)-
合并多头结果:
-
使用
.transpose(1, 2)将头的维度放回原来的位置,形状变为(batch_size, seq_len, num_heads, d_k)。 -
使用
.contiguous().view(batch_size, seq_len, d_model)将多头结果合并成一个张量,形状为(batch_size, seq_len, d_model)。
-
-
输出投影:
-
使用
o_project将合并后的结果再次投影到d_model维度。
-
-
Dropout:
-
使用
dropout层对输出进行Dropout操作,防止过拟合。
-
需复现完整代码
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads, dropout):super().__init__()self.num_heads = num_headsself.d_k = d_model // num_headsself.q_project = nn.Linear(d_model, d_model)self.k_project = nn.Linear(d_model, d_model)self.v_project = nn.Linear(d_model, d_model)self.o_project = nn.Linear(d_model, d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, attn_mask=None):batch_size, seq_len, d_model = x.shapeQ = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)K = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)V = self.q_project(x).view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)atten_scores = Q @ K.transpose(2, 3) / math.sqrt(self.d_k)if attn_mask is not None:attn_mask = attn_mask.unsqueeze(1)atten_scores = atten_scores.masked_fill(attn_mask == 0, -1e9)atten_scores = torch.softmax(atten_scores, dim=-1)out = atten_scores @ Vout = out.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)out = self.o_project(out)return self.dropout(out)