百度提交入口网站网址全国人大常委会委员长
几种常见的激活函数解析
- 激活函数的用处
- 常见激活函数
- Sigmoid
- 图像
- 函数
- 导数
- 优点
- 缺点
- 应用场景
- Tanh
- 图像
- 函数
- 导数
- 优点
- 缺点
- relu
- 图像
- 函数
- 导数
- 优点
- 缺点
- LeaklyRelu
- 图像
- 函数
- 导数
- 优点
- 缺点
- PRelu
- 图像
- 函数
- 导数
- 优点
- 缺点
- swish
- 图像
- 函数
- 导数
- 优点
- 缺点
激活函数的用处
在研究激活函数之前,首先要把激活函数的用处说明白,公式化的说出激活函数的作用,如下:
- 引入非线性的行为
作用:激活函数能够为神经网络引入非线性,使其能够学习和逼近复杂的非线性关系。
纯粹的多层线性层堆叠,在不引入激活函数的情况下,其本质基本等同于单层线性层,这也导致了多层线性层无法解决非线性问题,例如一个很经典的问题,异或问题,但是在引入激活函数后,神经网络就可以轻松地解决这个问题。如果想了解激活函数和多层线性层解决异或问题,可以看pytroch 使用神经网络来拟合异或操作
- 模拟神经元的兴奋和抑制
作用:激活函数可以模拟生物神经元的兴奋和抑制特性,决定神经元是否被激活。
例如sigmoid函数,可以根据输入x的值将其映射到 0 - 1之间,当输入值较小时,输出值接近0,表示神经元未被激活;当输入值较大时,输出值接近1,表示神经元被激活。这种特性使得神经网络能够模拟生物神经元的行为,从而更好地进行信息处理和传递。
- 用于分类和回归任务
作用:在神经网络的输出层,激活函数可以根据任务的需要对输出进行特定的变换,以适应分类或回归任务的要求
在二分类问题中,输出层可以使用Sigmoid函数,其输出值在0到1之间,表示样本属于某一类的概率。在多分类问题中,输出层可以使用softmax函数,将多个神经元的输出转换为一个概率分布,表示样本属于不同类别的概率
简而言之,我认为激活函数,就是目前神经网络对神经元的模拟,从而获得比纯粹线性层堆叠更好的效果。
常见激活函数
Sigmoid
图像
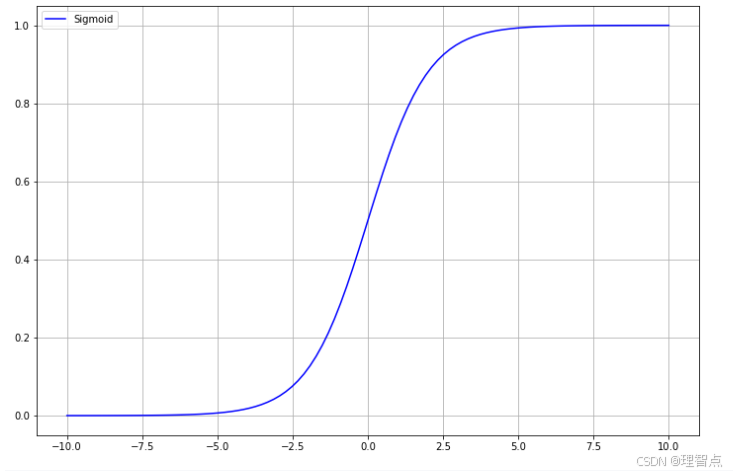
函数
f ( x ) = 1 1 + e − x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1
导数
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x) =f(x)(1 - f(x)) f′(x)=f(x)(1−f(x))
证明 sigmoid函数求导-只要四步
优点
平滑可导:Sigmoid函数是平滑的且处处可导,便于使用梯度下降等优化算法进行参数更新。
输出范围固定:能将输入值压缩到(0,1)区间,适用于需要概率输出的场景,如二分类问题。
缺点
梯度消失问题:在输入值较大或较小时,函数的导数接近于0,导致反向传播时梯度信息逐渐消失,影响深层网络的训练。
计算复杂度高:涉及指数运算,相比一些简单的激活函数(如ReLU),计算成本较高。
非零中心化输出:输出范围在(0,1),不是以0为中心,可能导致在反向传播中梯度更新效率低下。
应用场景
二分类问题:如垃圾邮件分类、医学诊断中的疾病预测等,输出层使用Sigmoid函数将输出转换为概率。
RNN中的门控机制:在循环神经网络(RNN)的变体如LSTM中,Sigmoid函数用于控制门的开启程度,决定信息的流动。
Tanh
图像
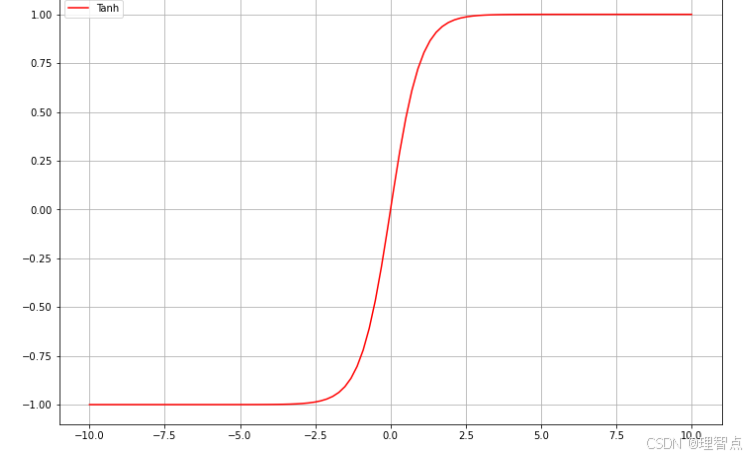
函数
f ( x ) = e x − e − x e x + e − x f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} f(x)=ex+e−xex−e−x
或者
f ( x ) = 2 S i g m o i d ( 2 x ) − 1 f(x) = 2 Sigmoid(2x) - 1 f(x)=2Sigmoid(2x)−1
导数
f ′ ( x ) = 1 − t a n h 2 ( x ) f'(x) =1 - tanh^2(x) f′(x)=1−tanh2(x)
证明 激活函数tanh(x)求导
优点
平滑可导:Tanh函数是平滑的且处处可导,便于使用梯度下降等优化算法进行参数更新。
输出范围固定:能将输入值压缩到(-1, 1)区间,有助于归一化神经网络的输出。
缺点
梯度消失问题:在输入值较大或较小时,函数的导数接近于0,导致反向传播时梯度信息逐渐消失,影响深层网络的训练。
计算复杂度高:涉及指数运算,相比一些简单的激活函数(如ReLU),计算成本较高。
relu
图像
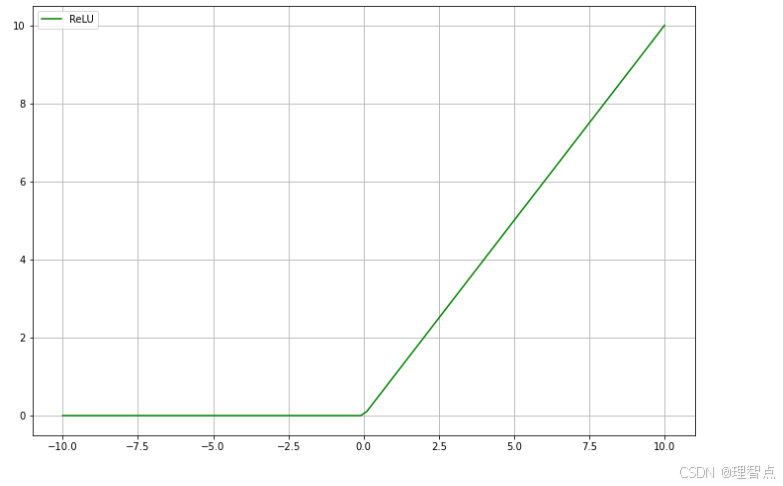
函数
f ( x ) = M A X ( 0 , x ) f(x)=MAX(0,x) f(x)=MAX(0,x)
导数
f ( x ) = { 1 x>0 0 x<=0 f(x)= \begin{cases} 1& \text{x>0}\\ 0& \text{x<=0} \end{cases} f(x)={10x>0x<=0
优点
计算简单高效:ReLU的计算非常简单,只需要进行一次阈值判断和可能的取零操作,相比Sigmoid和Tanh等函数大大减少了计算成本,尤其在大型神经网络中能显著提高训练和推理速度。
缓解梯度消失问题:在反向传播过程中,当输入x>0时,ReLU的梯度为1,不会像Sigmoid和Tanh那样出现梯度逐渐缩小的情况,从而有助于深层网络的训练。
稀疏激活带来的优势:稀疏激活不仅可以减少计算量,还能使模型更专注于重要的特征,提高对数据的表达能力和泛化性能。
缺点
神经元死亡问题:当输入x长期为负时,ReLU的输出恒为0,梯度也为0,导致这些神经元在训练过程中无法更新权重,永久失去作用,降低了模型的有效容量。
非零中心化输出:ReLU的输出范围是[0, +∞),不是以0为中心,这可能会导致在反向传播中梯度更新的方向出现偏差,影响训练效率。
对输入噪声敏感:由于ReLU在正区间是线性的,对于输入中的噪声和异常值可能会直接传递,影响模型的稳定性和鲁棒性。
LeaklyRelu
图像
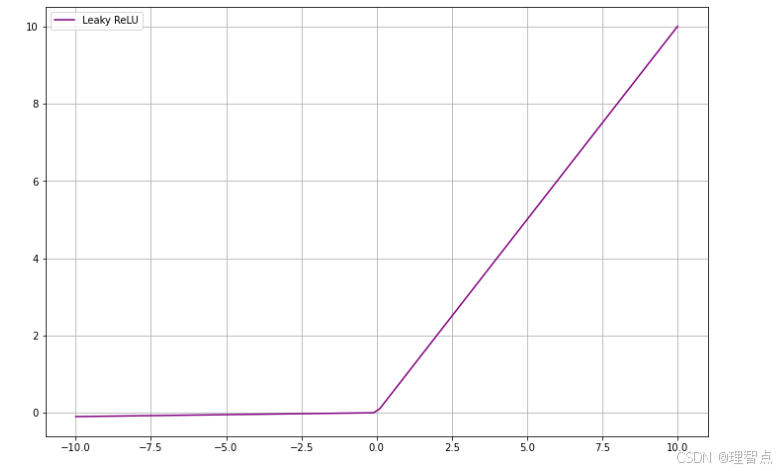
函数
f ( x ) = M a x ( α x , x ) , α 一般取 0.01 f(x) = Max(\alpha x,x) ,\alpha 一般取0.01 f(x)=Max(αx,x),α一般取0.01
导数
f ( x ) = { 1 x>0 α x<=0 f(x)= \begin{cases} 1& \text{x>0}\\ \alpha & \text{x<=0} \end{cases} f(x)={1αx>0x<=0
优点
解决神经元死亡问题:Leaky ReLU通过在负值区域赋予一个小的斜率,使得即使输入为负,神经元也能被激活,从而避免了ReLU函数中可能出现的神经元死亡问题。
保持ReLU的优点:Leaky ReLU保留了ReLU函数计算简单、收敛速度快等优点,同时通过引入负区间的小斜率,进一步提高了模型的稳定性和学习能力。
零中心化输出:Leaky ReLU的输出范围是(−∞,+∞),在一定程度上接近零中心化,有助于梯度的传播。
缺点
结果不一致:由于在正负区间应用了不同的函数形式,Leaky ReLU无法为正负输入值提供一致的关系预测,这可能会影响模型的稳定性和泛化能力。
参数选择敏感:Leaky ReLU中的斜率参数α需要仔细调整。如果α设置过大,函数可能过于线性;如果设置过小,则可能无法有效解决神经元死亡问题。
计算复杂度略高:相比传统的ReLU函数,Leaky ReLU在负区间需要进行额外的乘法运算,计算成本略有增加。
PRelu
图像
函数
f ( x ) = M a x ( α x , x ) , α 由学习中得来 f(x) = Max(\alpha x,x) ,\alpha 由学习中得来 f(x)=Max(αx,x),α由学习中得来
导数
f ( x ) = { 1 x>0 α x<=0 f(x)= \begin{cases} 1& \text{x>0}\\ \alpha & \text{x<=0} \end{cases} f(x)={1αx>0x<=0
优点
自适应学习:PReLU的斜率参数α是通过反向传播学习得到的,可以根据数据自动调整,以达到最优的激活效果。
避免神经元死亡:通过在负值区域赋予一个可学习的斜率,PReLU避免了ReLU函数中可能出现的神经元死亡问题。
性能潜力:在某些任务中,PReLU可以获得比ReLU和Leaky ReLU更好的性能。
缺点
增加模型复杂度:引入额外的可学习参数α,增加了模型的复杂度。
可能过拟合:在某些情况下,特别是在小数据集上,PReLU可能导致过拟合。
swish
图像

函数
f ( x ) = x ⋅ S i g m o i d ( x ) = x 1 + e − x f(x) = x\cdot Sigmoid(x) = \frac{x}{1 + e^{-x}} f(x)=x⋅Sigmoid(x)=1+e−xx
导数
f ( x ) = S i g m o i d ( x ) + x ⋅ S i g m o i d ( x ) ∗ ( 1 − s i g m o i d ( x ) ) f(x) = Sigmoid(x) + x \cdot Sigmoid(x) * (1 - sigmoid(x)) f(x)=Sigmoid(x)+x⋅Sigmoid(x)∗(1−sigmoid(x))
优点
性能提升:在深度模型中,Swish函数通常比ReLU表现更好,特别是在图像分类等任务中。
平滑性:Swish函数是平滑的,这有助于梯度的传播和优化过程。
自门控特性:Swish函数通过自身作为门控来调节输出,这使得它能够更好地处理复杂的输入信号。
缺点
计算复杂度高:Swish函数涉及指数运算和除法运算,相比ReLU等简单激活函数,计算成本较高。
非单调性可能带来的问题:Swish函数的非单调性可能导致在某些情况下优化过程变得复杂。