网站建设技术网站电脑培训学校哪家最好
CUDA C编程笔记
- 第五章 共享内存和常量内存
- 5.3 减少全局内存访问
- 5.3.2 使用展开的并行规约
- 思路
- reduceSmemUnroll4(全局内存)具体代码:
- 运行结果
- 意外发现书上全局加载事务和全局存储事务和ncu中这两个值相同
待解决的问题:意外发现书上全局加载事务和全局存储事务和ncu中这两个值相同,是否有直接相关???
第五章 共享内存和常量内存
5.3 减少全局内存访问
使用共享内存的主要原因之一是要缓存片上的数据,来减少核函数中全局内存访问的次数。
第三章介绍了用全局内存的并行规约核函数,并解释了下面2个问题:
①如何重新安排数据访问模式来避免线程束分化
②如何展开循环来保证有足够的操作使指令和内存带宽饱和
本节重新使用并行规约核函数,但是这里用共享内存作为缓存来减少全局内存的访问。【并行规约+共享内存】
5.3.2 使用展开的并行规约
前面的核函数用一个线程块处理一个数据块。继续优化用第三章的思想,一次运行多个IO操作,展开线程块来提高核函数性能。
这里展开了4个线程块,即每个线程处理4个数据块的数据。
这样做的优势是:
①提高全局内存的吞吐量,因为每个线程进行了更多的并行IO。
②全局内存存储事务减少了1/4
③整体内核性能提升
思路
先重新计算全局输入数据的偏移值。
//全局索引,一次处理4个输入数据块unsigned int idx = blockIdx.x * blockDim.x * 4 + threadIdx.x;//这里乘4
再一次性处理4个元素,每个线程读取4个数据,把这个4个数据的和放到局部变量tmpSum中,用tmpSum来初始化共享内存,而非从全局内存初始化共享内存。
//边界条件检查if(idx < n)//在范围内的相邻块大小的元素都加起来,最多可以一次处理4个块{int a1, a2, a3, a4;a1 = a2 = a3 = a4 = 0;a1 = g_idata[idx];if(idx + blockDim.x < n) a2 = g_idata[idx + blockDim.x];if(idx + 2 * blockDim.x < n) a3 = g_idata[idx + 2 * blockDim.x];if(idx + 3 * blockDim.x < n) a4 = g_idata[idx + 3 * blockDim.x];tmpSum = a1 + a2 + a3 + a4;}
reduceSmemUnroll4(全局内存)具体代码:
//reduceSmemUnroll4
__global__ void reduceSmemUnroll(int *g_idata, int *g_odata, unsigned int n){//静态共享数组__shared__ int smem[DIM];//设置线程IDunsigned int tid = threadIdx.x;//全局索引,一次处理4个输入数据块unsigned int idx = blockIdx.x * blockDim.x * 4 + threadIdx.x;//这里乘4//展开4个块int tmpSum = 0;//【】//边界条件检查if(idx < n)//在范围内的相邻块大小的元素都加起来,最多可以一次处理4个块{int a1, a2, a3, a4;a1 = a2 = a3 = a4 = 0;a1 = g_idata[idx];if(idx + blockDim.x < n) a2 = g_idata[idx + blockDim.x];if(idx + 2 * blockDim.x < n) a3 = g_idata[idx + 2 * blockDim.x];if(idx + 3 * blockDim.x < n) a4 = g_idata[idx + 3 * blockDim.x];tmpSum = a1 + a2 + a3 + a4;}smem[tid] = tmpSum;__syncthreads();//在共享内存中就地规约if(blockDim.x >= 1024 && tid < 512) smem[tid] += smem[tid + 512];__syncthreads();if(blockDim.x >= 512 && tid < 256) smem[tid] += smem[tid + 256];__syncthreads();if(blockDim.x >= 256 && tid < 128) smem[tid] += smem[tid + 128];__syncthreads();if(blockDim.x >= 128 && tid < 64) smem[tid] += smem[tid + 64];__syncthreads();//展开warpif(tid < 32){volatile int *vsmem = smem;vsmem[tid] += vsmem[tid + 32];vsmem[tid] += vsmem[tid + 16];vsmem[tid] += vsmem[tid + 8];vsmem[tid] += vsmem[tid + 4];vsmem[tid] += vsmem[tid + 2];vsmem[tid] += vsmem[tid + 1];}//把结果写回全局内存if(tid == 0) g_odata[blockIdx.x] = smem[0];
}
对应的主函数调用核函数也要修改,网格除4。
这里只能给grid.x/4,不能给block/4。
如果block/4,假设原来block大小为256,调用时block/4=64,blockDim.x=64,共享内存仍分配256个空间,只有前64个有值,后面的都是未定义的有问题的值。并且归约也会崩溃,索引也有问题。
//3、reduceSmemUnroll4cudaMemcpy(d_idata, h_idata, bytes, cudaMemcpyHostToDevice);reduceSmemUnroll<<<grid.x / 4, block>>>(d_idata, d_odata, size);//这里要除4,因为一个线程块处理四个数据块,需要的线程块减为原来的1/4cudaMemcpy(h_odata, d_odata, grid.x / 4 * sizeof(int), cudaMemcpyDeviceToHost);gpu_sum = 0;for(int i = 0; i < grid.x / 4; i++) gpu_sum += h_odata[i];printf("reduceSmemUnroll4: %d <<<grid %d block %d>>>\n", gpu_sum, grid.x / 4,block.x);
运行结果
[6/8] Executing 'cuda_gpu_kern_sum' stats reportTime (%) Total Time (ns) Instances Avg (ns) Med (ns) Min (ns) Max (ns) StdDev (ns) Name -------- --------------- --------- --------- --------- -------- -------- ----------- --------------------------------------------50.4 238,789 1 238,789.0 238,789.0 238,789 238,789 0.0 reduceGmem(int *, int *, unsigned int) 32.5 154,051 1 154,051.0 154,051.0 154,051 154,051 0.0 reduceSmem(int *, int *, unsigned int) 17.2 81,377 1 81,377.0 81,377.0 81,377 81,377 0.0 reduceSmemUnroll(int *, int *, unsigned int)
意外发现书上全局加载事务和全局存储事务和ncu中这两个值相同
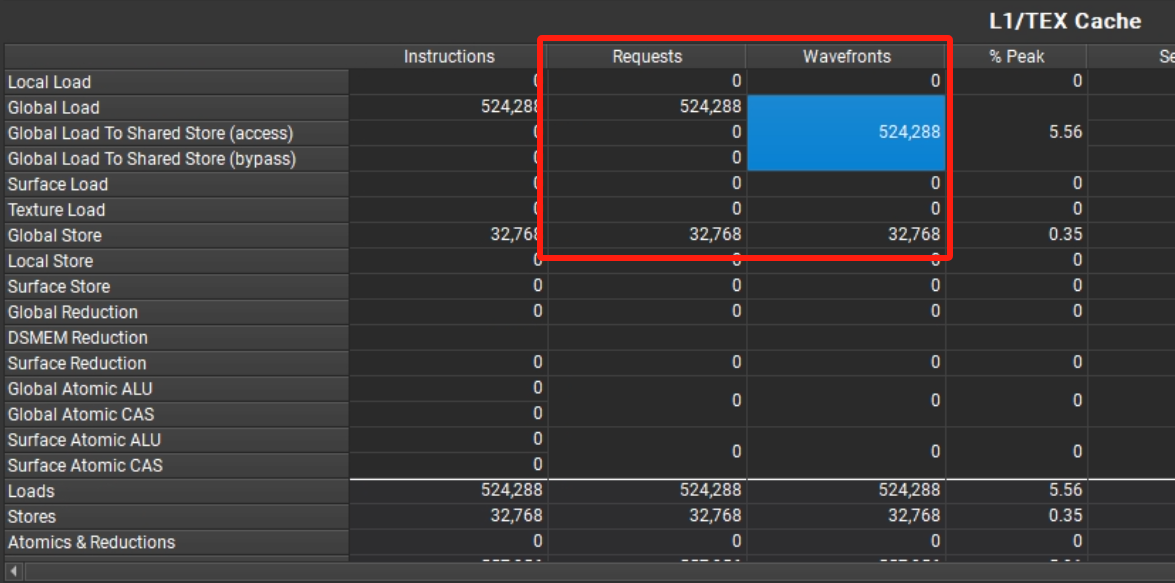
存储事务:与reduceSmem相比,reduceSmemUnroll4存储事务数量减少为1/4,加载事务数量不变。
全局内存吞吐量:
加载吞吐量增加,因为大量同时加载请求。
存储吞吐量下降,较少的存储请求让总线饱和。