网站推广现状贵阳网站优化公司
目录
过期淘汰策略
常见 linux 命令
过期字典
过期策略
内存淘汰策略
最大内存
不进行内存淘汰策略
进行内存淘汰策略
在设置了过期时间的数据中进行淘汰
在所有数据中进行淘汰
常见 linux 命令
LRU 算法和 LFU 算法
总结
力扣 手搓 LRU
资料来源
过期淘汰策略
redis 设置了键值对的过期时间
而到了对应的时间 redis 会使用机制对键值对进行删除
这就是 redis 的过期淘汰策略
常见 linux 命令
生成某个键并且设置过期时间
set <key> <value> ex <n> 秒
set <key> <value> px <n> 毫秒设置键的过期时间
expire <key> <n> 多少秒后过期
pexpire <key> <n> 多少毫秒后过期反悔命令
persist key1过期字典
过期字典里保存了 redis 里所有的键值对的过期时间
过期字典的数据结构类似于哈希表
key 是键的名称
value 是过期时间
当我们查询 key 的时候 我们首先会判断其是否在过期字典里面
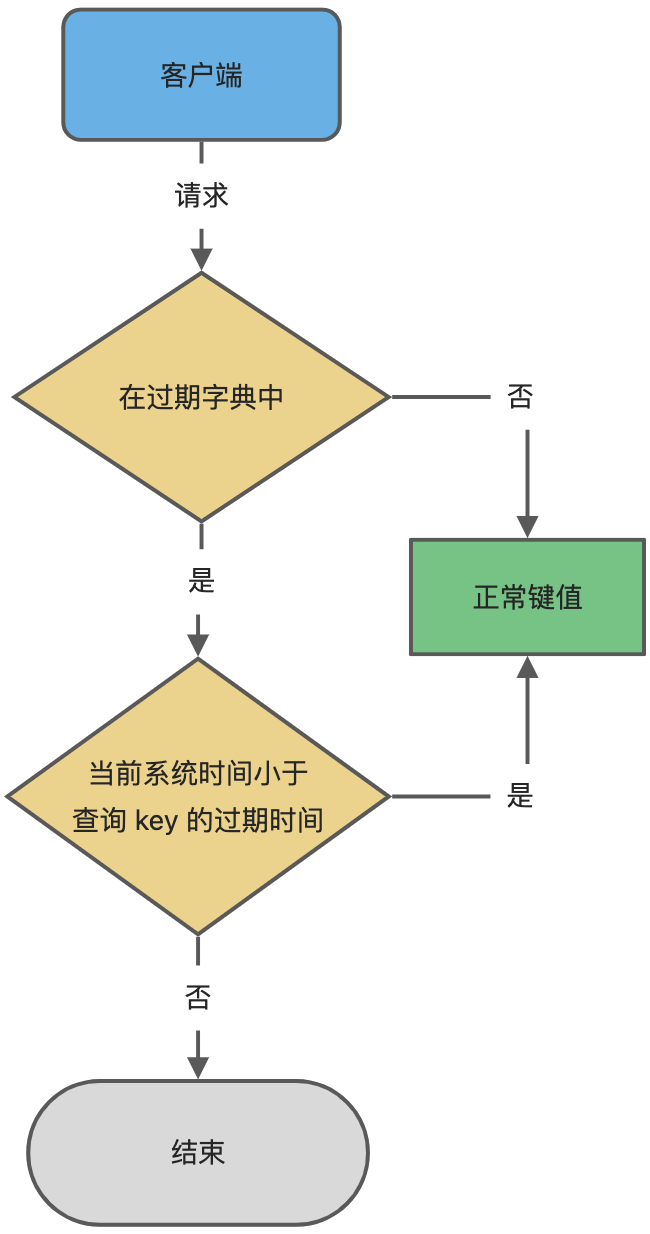
过期策略
- 定时删除
根据过期时间 到了指定时间后删除 key
锐评:过于占用 cpu
- 惰性删除
使用 key 的时候 看 key 是否过期 过期则删除
锐评:过于占用内存
- 定期删除
每隔一段时间 拿出一堆 key 出来 (20 个) 判断其是否过期
锐评:不稳定
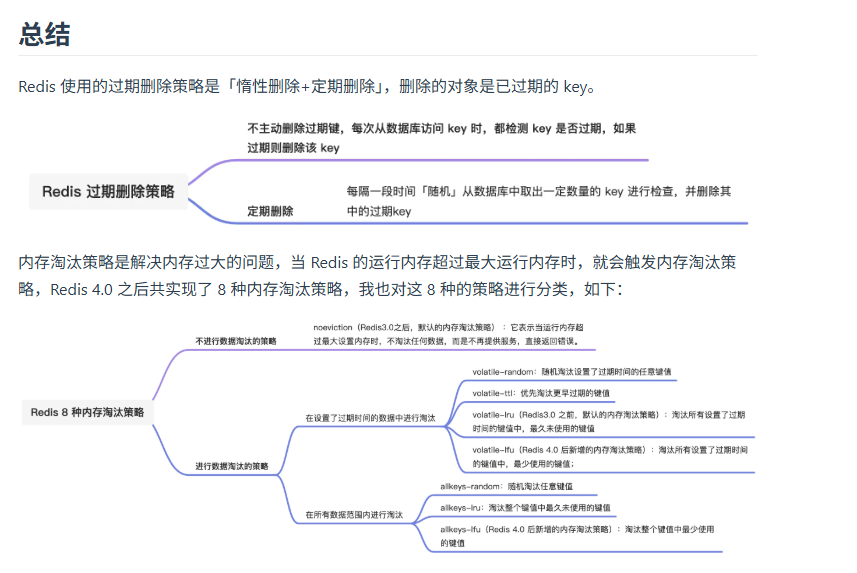
redis 采用的是 惰性删除+定期删除搭配的方式
内存淘汰策略
redis 的内存达到一定的数值 会触发内存淘汰策略
最大内存
在 redis.conf 配置文件里面
maxmemory <bytes>这个默认值在 64 位机器里是 0 表示为无上限
在 32 位机器里是 3G
不进行内存淘汰策略
超过内存的话
任何 key 都会被报告为无法写入
但是单纯的查询和查询还是可以实现的
进行内存淘汰策略
在设置了过期时间的数据中进行淘汰
- random
随机淘汰设置了过期时间的任意键值
- ttl
优先淘汰更早过期的键值
- lru
淘汰所有设置了过期时间的键值中,最久未使用的
- lfu
淘汰所有设置了过期时间的键值中,最少使用的
在所有数据中进行淘汰
- random
随机淘汰任意键值
- lru
淘汰最久未使用的键值
- lfu
淘汰最少使用的键值
常见 linux 命令
命令设置 重启即可
config set maxmemory-policy <策略>配置文件修改
maxmemory-policy <策略>maxmemory-policy <策略>LRU 算法和 LFU 算法
传统的 LRU 算法是基于链表这种数据结构的
最近使用的元素都会被提到链表头部
而最久未使用的数据很显然就在链表的尾部
我们每次只需要去掉链表尾部的元素即可
但是这种传统的做法有两个弊端
- 链表带来空间开销
- 链表频繁操作 , 性能消耗大
Redis 并没有采用原始的 LRU 算法
而是在 redis 对象的属性中加一条额外的属性 记录最后一次访问时间
Redis 进行内存淘汰的时候 随机取样 然后淘汰最久没有使用的那一个
LRU 算法可能会存在内存污染的问题
就是存在大量只读取一次的数据后 这些数据会一直存在 并且每次随机淘汰的时候都可能被拿出来
LFU 算法是为了解决 LRU 算法带来的问题
LRU 是淘汰最久未使用 LFU 是淘汰最少使用
LRU 是根据最后一次访问时间来淘汰数据
LFU 是根据数据的所有访问次数来 淘汰数据
这些 我没怎么看懂 好像也看懂了 看不懂他那个算法是怎么计算的
大概就是先将 redis 对象头的 24bits 的 lru 字段
分成两段 ldt 和 logc
ldt 记录访问时间戳
logc 记录访问频率 随时间推迟衰减
当访问 key 的时候
先按照上次访问时间距离当前时间的时长,先对 logc 进行衰减
然后按照一定概率增加 logc 的数值

实际上 我记得 配置里有两个项
可以手动配置 LFU 淘汰策略中的 logc 的增长速度和衰减速度
原文

总结
力扣 手搓 LRU
146. LRU 缓存
import java.util.HashMap;
import java.util.Map;public class Main {public static void main(String[] args) {// 测试用例 1: 基本 get 和 put 操作System.out.println("测试用例 1:");LRUCache cache1 = new LRUCache(2);cache1.put(1, 1);cache1.put(2, 2);System.out.println(cache1.get(1)); // 返回 1cache1.put(3, 3); // 该操作会使得关键字 2 作废System.out.println(cache1.get(2)); // 返回 -1 (未找到)cache1.put(4, 4); // 该操作会使得关键字 1 作废System.out.println(cache1.get(1)); // 返回 -1 (未找到)System.out.println(cache1.get(3)); // 返回 3System.out.println(cache1.get(4)); // 返回 4// 测试用例 2: 更新已有键的值System.out.println("\n测试用例 2:");LRUCache cache2 = new LRUCache(2);cache2.put(1, 1);cache2.put(2, 2);cache2.put(1, 10); // 更新 key=1 的值System.out.println(cache2.get(1)); // 返回 10System.out.println(cache2.get(2)); // 返回 2// 测试用例 3: 容量为 1 的缓存System.out.println("\n测试用例 3:");LRUCache cache3 = new LRUCache(1);cache3.put(1, 1);System.out.println(cache3.get(1)); // 返回 1cache3.put(2, 2); // 替换 key=1 的项System.out.println(cache3.get(1)); // 返回 -1System.out.println(cache3.get(2)); // 返回 2// 测试用例 4: 访问不存在的键System.out.println("\n测试用例 4:");LRUCache cache4 = new LRUCache(2);System.out.println(cache4.get(1)); // 返回 -1// 测试用例 5: 连续访问使最近最少使用的项被淘汰System.out.println("\n测试用例 5:");LRUCache cache5 = new LRUCache(3);cache5.put(1, 1);cache5.put(2, 2);cache5.put(3, 3);cache5.get(1); // 使 1 变为最近使用cache5.put(4, 4); // 淘汰 key=2System.out.println(cache5.get(2)); // 返回 -1}
}class LRUCache{// 双向链表节点class DLinkedNode{int key,value;DLinkedNode prev,next;public DLinkedNode() {}public DLinkedNode(int key,int value){this.key=key;this.value=value;}}// mapprivate Map<Integer,DLinkedNode>cache=new HashMap<>();// 当前大小private int size;// 当前容量private int capacity;// 头结点 尾巴节点private DLinkedNode head , tail;// 初始化LRU缓存public LRUCache(int capacity) {this.size = 0;this.capacity = capacity;// 使用伪头部和伪尾部节点head = new DLinkedNode();tail = new DLinkedNode();head.next = tail;tail.prev = head;}// 获取key 再业务中类似于使用keypublic int get(int key) {DLinkedNode node = cache.get(key);if (node == null) {return -1;}// 如果 key 存在,先通过哈希表定位,再移到头部moveToHead(node);return node.value;}// 放入key-valuepublic void put(int key, int value) {DLinkedNode node = cache.get(key);if (node == null) {// 如果 key 不存在,创建一个新的节点DLinkedNode newNode = new DLinkedNode(key, value);// 添加进哈希表cache.put(key, newNode);// 添加至双向链表的头部addToHead(newNode);++size;if (size > capacity) {// 如果超出容量,删除双向链表的尾部节点DLinkedNode tail = removeTail();// 删除哈希表中对应的项cache.remove(tail.key);--size;}}else {// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部node.value = value;moveToHead(node);}}// 将节点添加到尾部private void addToHead(DLinkedNode node) {node.prev = head;node.next = head.next;head.next.prev = node;head.next = node;}// 移除某个节点private void removeNode(DLinkedNode node) {node.prev.next = node.next;node.next.prev = node.prev;}// 将某个节点提到链表的head 是在get()和put()操作后执行private void moveToHead(DLinkedNode node) {removeNode(node);addToHead(node);}// 移除尾部节点private DLinkedNode removeTail() {DLinkedNode res = tail.prev;removeNode(res);return res;}
}资料来源
Redis 过期删除策略和内存淘汰策略有什么区别? | 小林coding