二级域名做网站好不好杭州网站推广公司
构建并评价聚类模型
- 构建并评价聚类模型
- 一、数据读取与准备(代码6 - 6部分)
- 结果
- 代码解析
- 二、Kmeans聚类(代码6 - 6部分)
- 结果
- 代码解析
- 三、数据降维可视化(代码6 - 6部分)
- 结果
- 代码解析
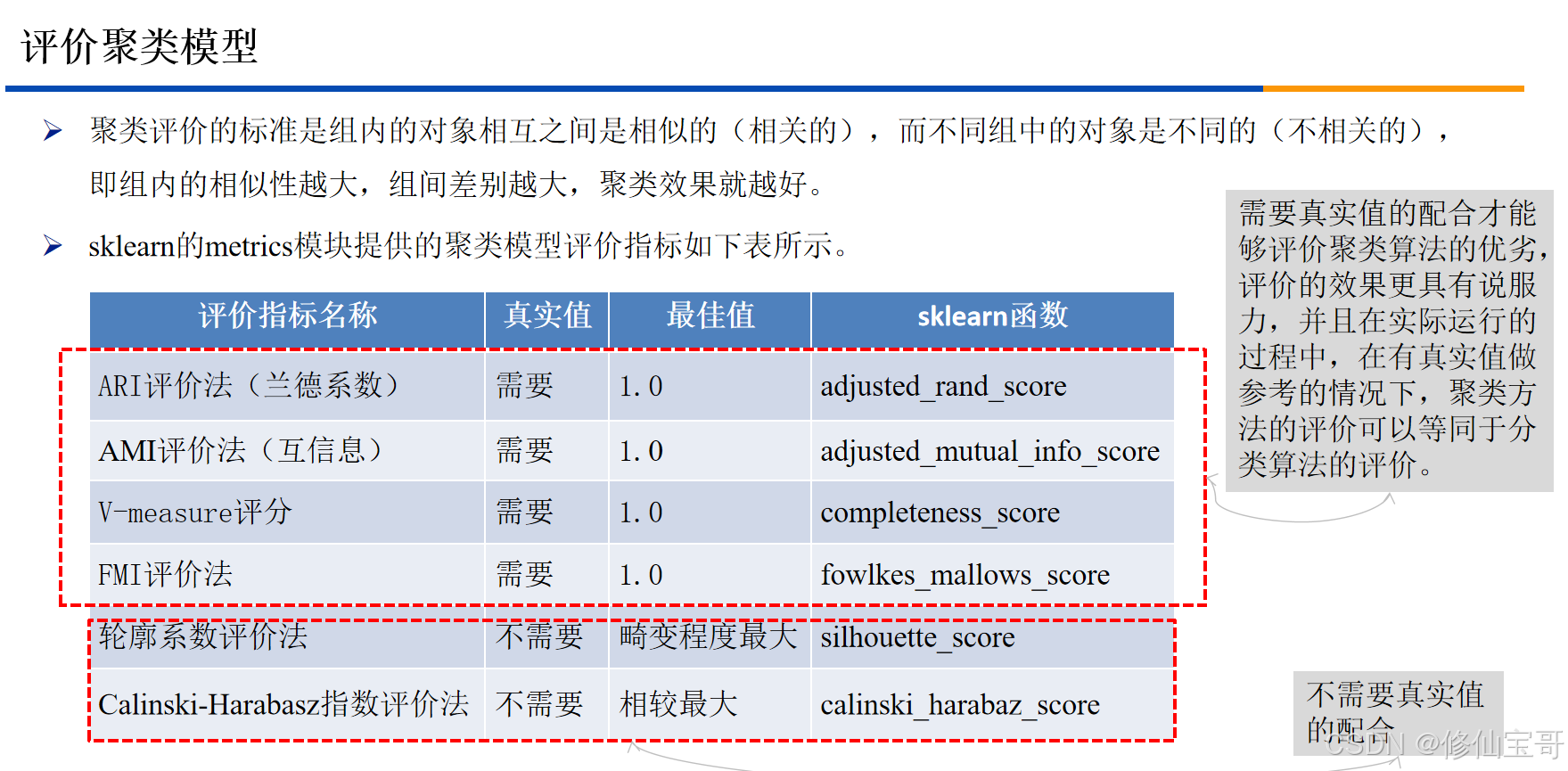
- 四、FMI评价(代码6 - 7部分)
- 结果
- 代码解析
- 五、轮廓系数评价(代码6 - 8部分)
- 结果
- 代码解析
- 六、calinski_harabaz指数评价(代码6 - 9部分)
- 结果
- 代码解析
- 总结
构建并评价聚类模型
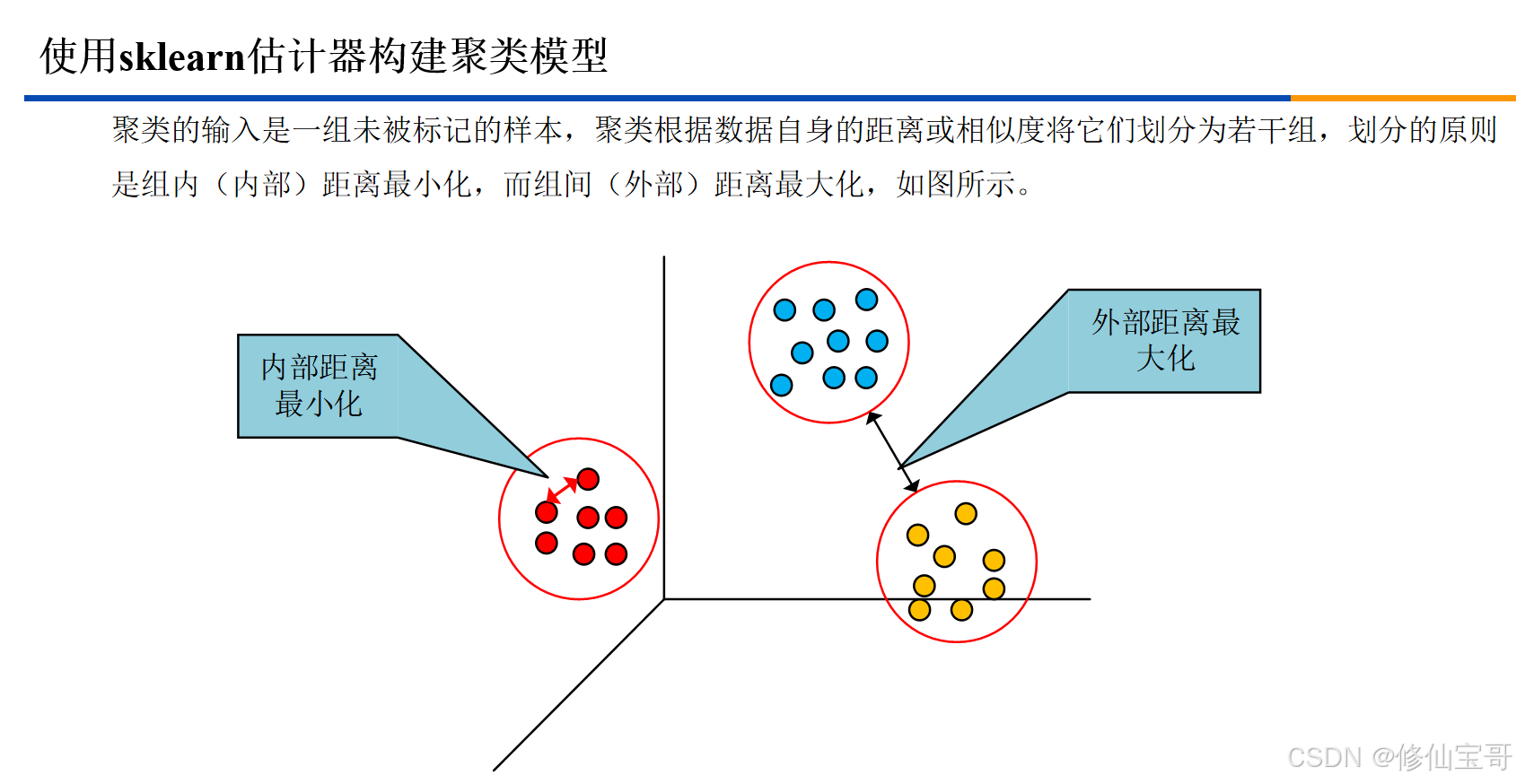
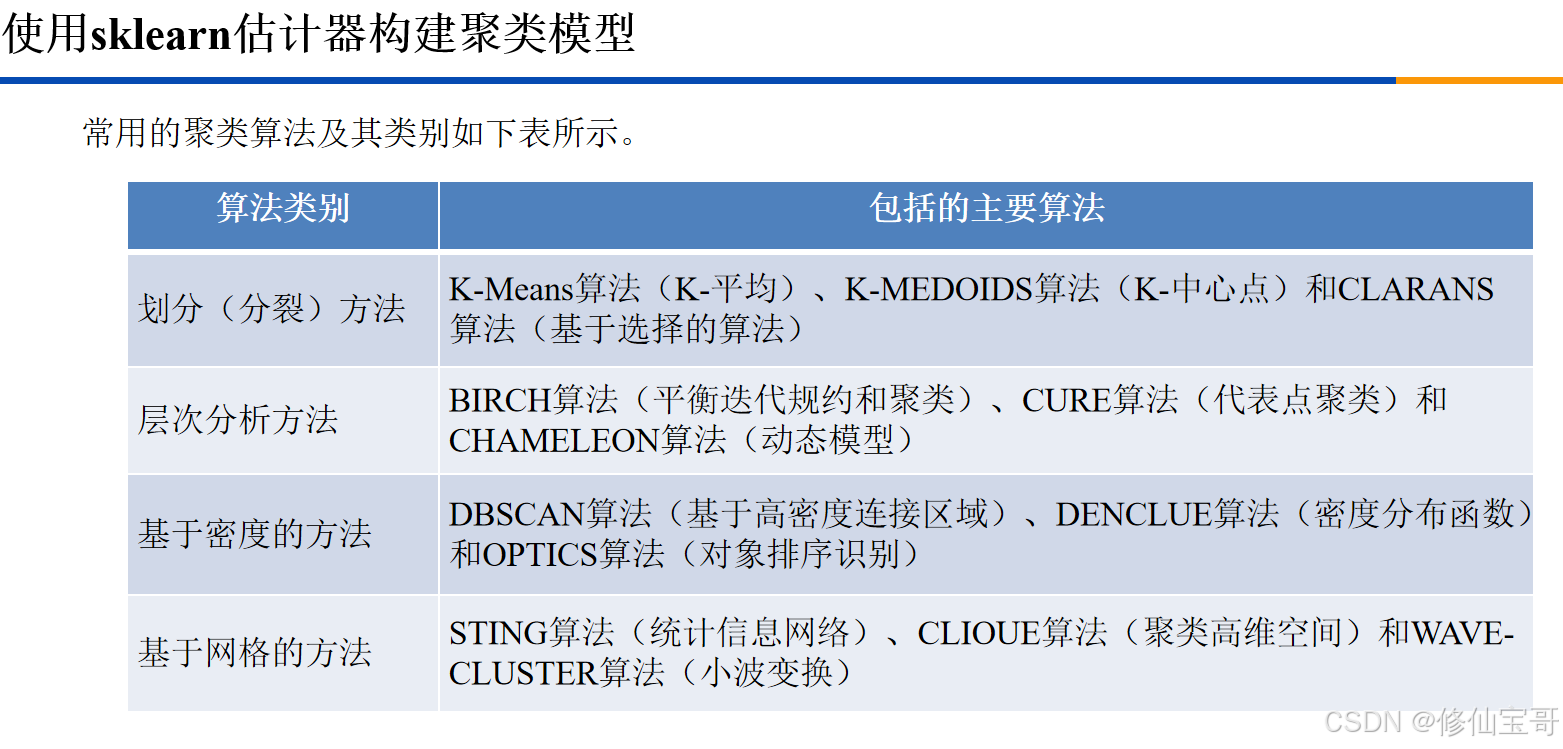
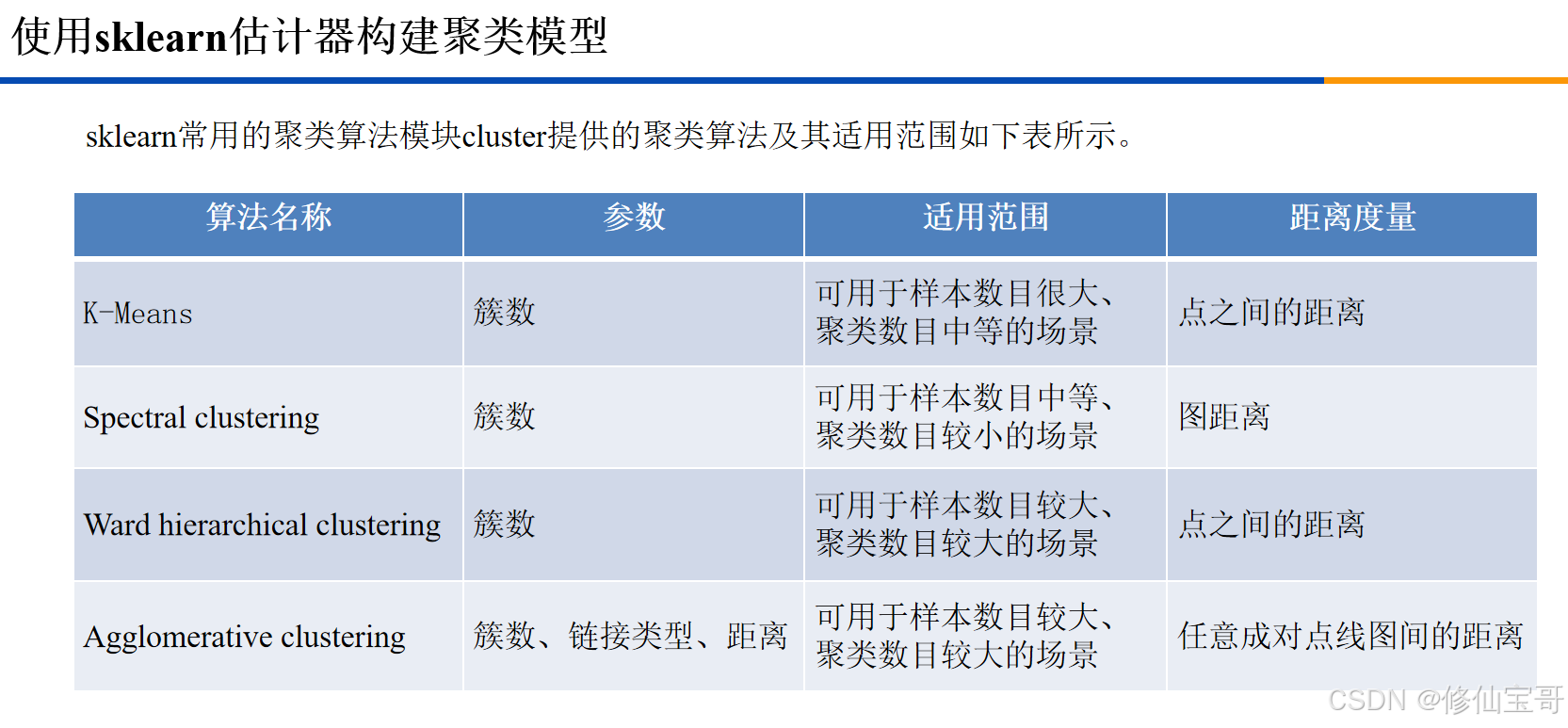


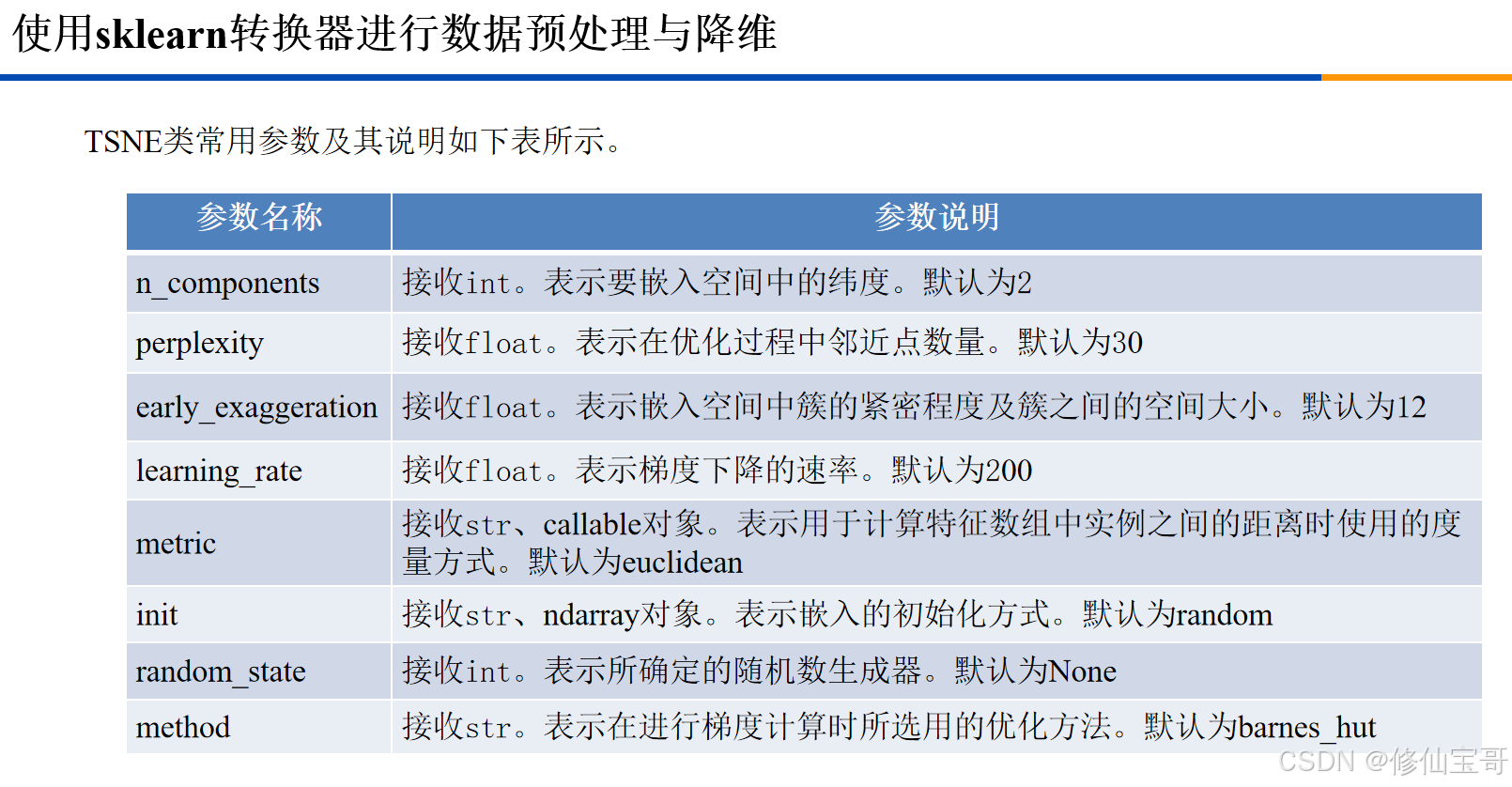
本文主要介绍了如何使用Python构建聚类模型,并对聚类结果进行评价。以下是整体的思维导图:
一、数据读取与准备(代码6 - 6部分)
# 代码6-6
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
# 读取数据集
customer = pd.read_csv('./customer.csv', encoding='gbk')
customer_data = customer.iloc[:, :-1]
customer_target = customer.iloc[:, -1]
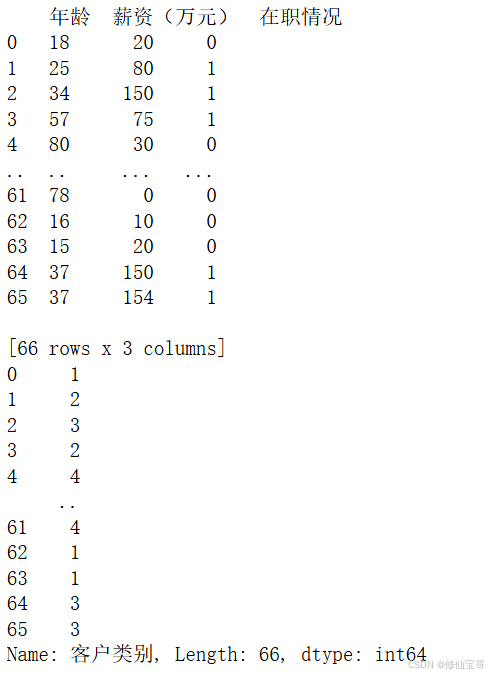
print(customer_data)
print(customer_target)
结果
代码解析
pd.read_csv('./customer.csv', encoding='gbk'):使用pandas库的read_csv方法读取customer.csv文件,指定编码为gbk。customer.iloc[:, :-1]:选取除最后一列之外的所有列作为特征数据。customer.iloc[:, -1]:选取最后一列作为目标数据。
二、Kmeans聚类(代码6 - 6部分)
# Kmeans聚类
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=4, random_state=6).fit(customer_data)
结果

代码解析
KMeans:sklearn库中的Kmeans聚类算法类。n_clusters=4:指定聚类的数量为4。random_state=6:设置随机种子,保证结果的可重复性。.fit(customer_data):使用特征数据进行模型训练。
三、数据降维可视化(代码6 - 6部分)
# 使用TSNE进行数据降维,降成两维
tsne = TSNE(n_components=2, init='random',random_state=2). fit(customer_data)
df = pd.DataFrame(tsne.embedding_) # 将原始数据转换为DataFrame
df['labels'] = kmeans.labels_ # 将聚类结果存储进df数据表
# 提取不同标签的数据
df1 = df[df['labels'] == 0]
df2 = df[df['labels'] == 1]
df3 = df[df['labels'] == 2]
df4 = df[df['labels'] == 3]
# 绘制图形
fig = plt.figure(figsize=(9, 6)) # 设定空白画布,并制定大小
# 用不同的颜色表示不同数据
plt.plot(df1[0], df1[1], 'bo', df2[0], df2[1], 'r*', df3[0], df3[1], 'gD', df4[0], df4[1], 'kD')
plt.savefig('./聚类结果.jpg', dpi=1080)
plt.show() # 显示图片
结果
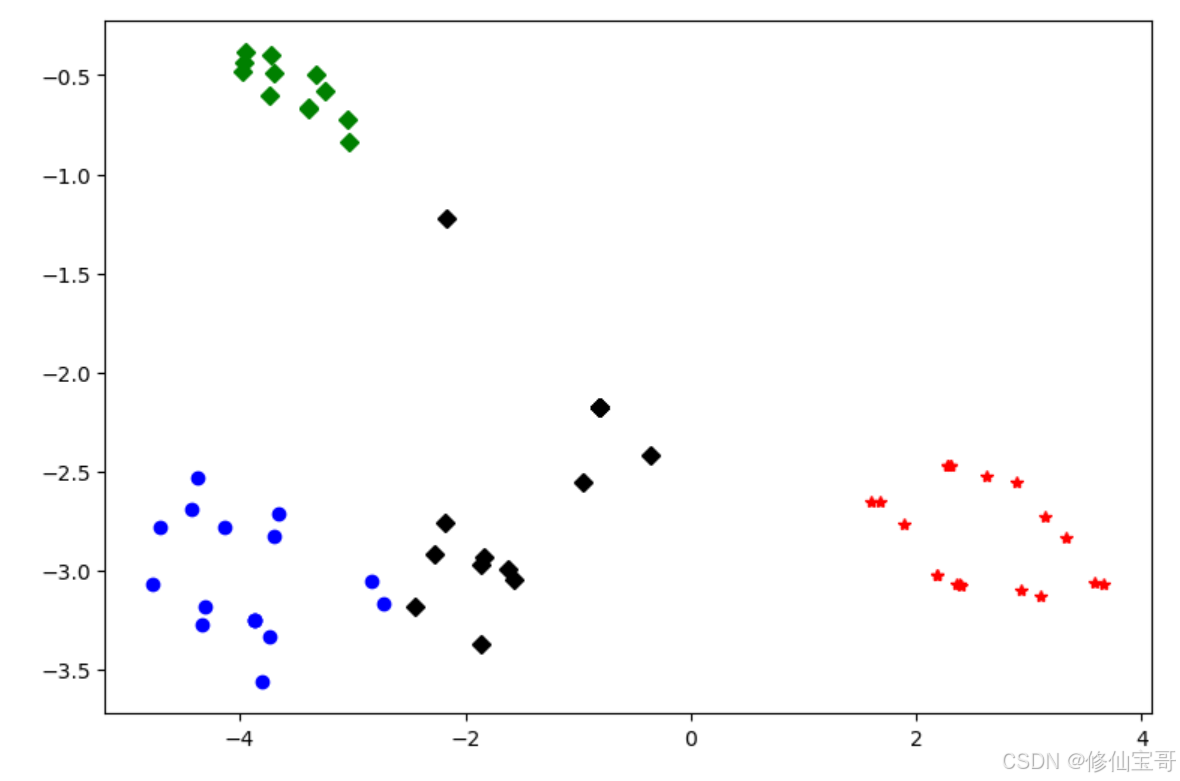
代码解析
TSNE:sklearn库中的t - 分布随机邻域嵌入算法,用于数据降维。n_components=2:指定降维后的维度为2。init='random':初始化方式为随机。random_state=2:设置随机种子。pd.DataFrame(tsne.embedding_):将降维后的数据转换为DataFrame格式。df['labels'] = kmeans.labels_:将聚类结果添加到DataFrame中。plt.plot:使用matplotlib库绘制散点图,不同的符号和颜色表示不同的聚类。plt.savefig:保存绘制的图形。plt.show:显示图形。
四、FMI评价(代码6 - 7部分)
# 代码6-7
from sklearn.metrics import fowlkes_mallows_score
from sklearn.cluster import KMeans # 确保导入KMeansfor i in range(1, 7):# 构建并训练模型,显式设置n_init=10kmeans = KMeans(n_clusters=i, random_state=6, n_init=10).fit(customer_data)score = fowlkes_mallows_score(customer_target, kmeans.labels_)print('customer数据聚%d类FMI评价分值为:%f' % (i, score))
结果

代码解析
fowlkes_mallows_score:sklearn库中的Fowlkes - Mallows指数,用于评价聚类结果与真实标签的相似性。for i in range(1, 7):循环尝试不同的聚类数,从1到6。KMeans(n_clusters=i, random_state=6).fit(customer_data):使用不同的聚类数构建并训练Kmeans模型。fowlkes_mallows_score(customer_target, kmeans.labels_):计算FMI得分。
五、轮廓系数评价(代码6 - 8部分)
# 代码6-8
import matplotlib.pyplot as plt # 补充导入matplotlib.pyplot
from sklearn.metrics import silhouette_score
from sklearn.cluster import KMeans # 补充导入KMeanssilhouettteScore = []
for i in range(2, 10):# 构建并训练模型,显式设置n_init=10以消除警告kmeans = KMeans(n_clusters=i, random_state=6, n_init=10).fit(customer_data)score = silhouette_score(customer_data, kmeans.labels_)silhouettteScore.append(score)plt.figure(figsize=(10, 6))
plt.plot(range(2, 10), silhouettteScore, linewidth=1.5, linestyle='-')
plt.savefig('./轮廓系数.jpg', dpi=1080)
plt.show()
结果
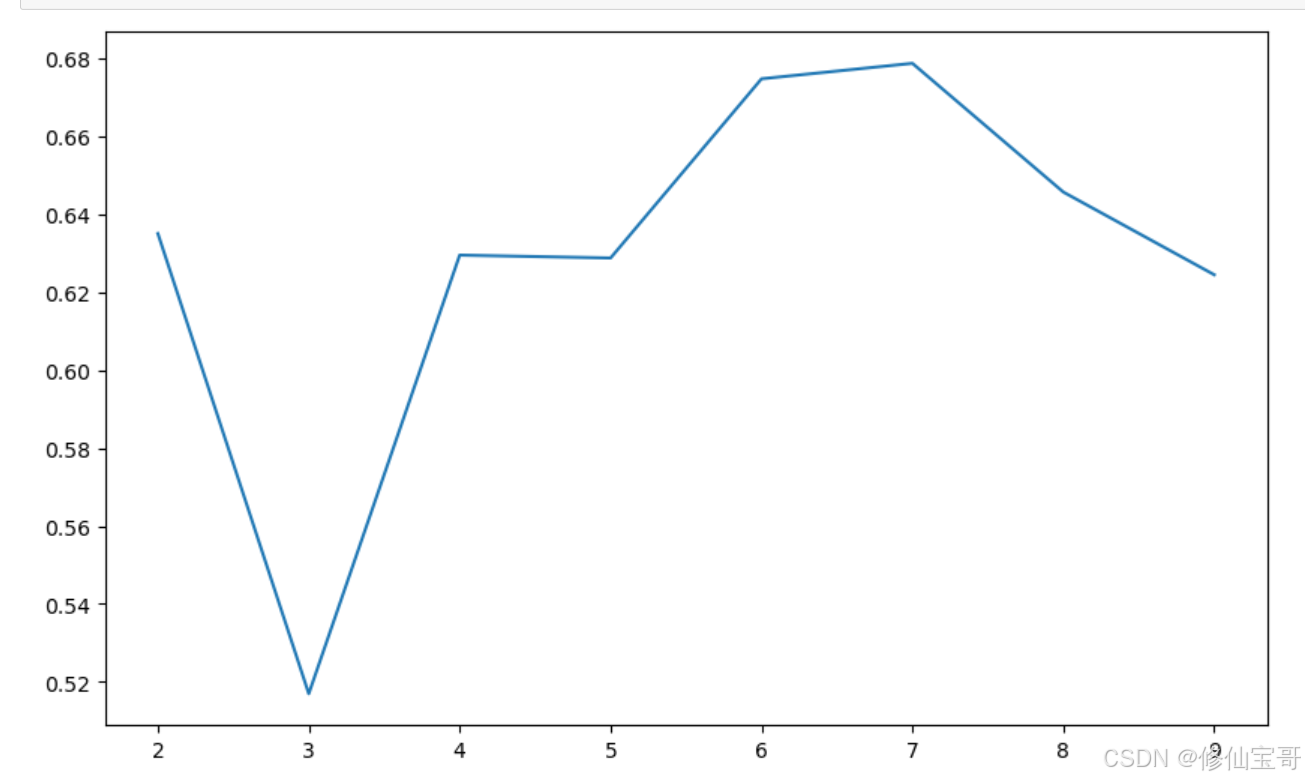
代码解析
silhouette_score:sklearn库中的轮廓系数,用于评价聚类的紧密程度和分离程度。for i in range(2, 10):循环尝试不同的聚类数,从2到9。KMeans(n_clusters=i, random_state=6).fit(customer_data):使用不同的聚类数构建并训练Kmeans模型。silhouette_score(customer_data, kmeans.labels_):计算轮廓系数得分。plt.plot:绘制轮廓系数随聚类数变化的曲线。
六、calinski_harabaz指数评价(代码6 - 9部分)
# 代码6-9
from sklearn.metrics import calinski_harabasz_score
from sklearn.cluster import KMeans # 补充导入(若未导入会报错,这里假设是遗漏)for i in range(2, 5):# 构建并训练模型,显式设置 n_init=10 以消除警告kmeans = KMeans(n_clusters=i, random_state=2, n_init=10).fit(customer_data)score = calinski_harabasz_score(customer_data, kmeans.labels_)print('customer数据聚%d类calinski_harabaz指数为:%f' % (i, score))
结果

代码解析
calinski_harabasz_score:sklearn库中的Calinski - Harabasz指数,用于评价聚类的紧凑性和分离性。for i in range(2, 5):循环尝试不同的聚类数,从2到4。KMeans(n_clusters=i, random_state=2).fit(customer_data):使用不同的聚类数构建并训练Kmeans模型。calinski_harabasz_score(customer_data, kmeans.labels_):计算Calinski - Harabasz指数得分。
总结
通过本文的学习,读者可以掌握以下知识与技能:
- 使用
pandas库读取CSV文件。 - 使用
sklearn库的Kmeans算法进行聚类分析。 - 使用
TSNE算法对高维数据进行降维并可视化。 - 使用FMI、轮廓系数和Calinski - Harabasz指数对聚类结果进行评价。
这些技能可以帮助读者在实际项目中更好地处理聚类问题,选择合适的聚类数,提高聚类的效果。