免费域名的网站seo搜索引擎实战详解
本项目代码在个人github链接:https://github.com/KLWU07/Machine-learning-Project-practice/tree/main
处理流程
- 1.导入波士顿房价数据集并进行预处理。
- 2.使用 GradientBoostingRegressor 模型进行回归分析。
- 3.通过交叉验证评估模型的性能,计算 MAE、MSE、MBE、RMSE 和 R^2 分数。
- 4.使用 matplotlib 绘制训练集和测试集的真实值与预测值的折线图和散点图,直观展示模型的预测效果。
九种回归算法
| 英文名称 (代码调用) | 中文名称 | 说明 |
|---|---|---|
LinearRegression | 线性回归 | 最简单的回归算法,假设目标变量与特征之间存在线性关系。适用于线性可分的数据集。 |
ElasticNet | 弹性网络回归 | 结合了 L1 和 L2 正则化,是 Lasso 和 Ridge 的结合。适用于特征数量较多且存在多重共线性的数据集。 |
Lasso | Lasso 回归 | 使用 L1 正则化,可以进行特征选择,使一些特征的系数为零。适用于特征数量较多且需要稀疏解的数据集。 |
Ridge | 岭回归 | 使用 L2 正则化,可以处理多重共线性问题。适用于特征数量较多且存在多重共线性的数据集。 |
DecisionTreeRegressor | 决策树回归器 | 基于决策树的回归算法,可以处理非线性关系。适用于特征数量较少且数据分布不均匀的数据集。 |
KNeighborsRegressor | K 近邻回归器 | 基于 K 近邻的回归算法,预测目标值是其最近邻点的平均值。适用于数据点分布较为均匀的数据集。 |
SVR | 支持向量回归器 | 基于支持向量机的回归算法,可以处理非线性关系。适用于特征数量较多且数据分布复杂的数据集。 |
GradientBoostingRegressor | 梯度提升回归器 | 基于梯度提升的回归算法,通过组合多个弱学习器来提高预测性能。适用于特征数量较多且数据分布复杂的数据集。 |
ExtraTreesRegressor | 额外树回归器 | 基于随机森林的回归算法,通过组合多个决策树来提高预测性能。适用于特征数量较多且数据分布复杂的数据集。 |
一、数据集介绍
波士顿房价数据集是机器学习领域中经典的回归分析数据集,用于房价预测,监督学习中的回归问题,目标是通过多个特征预测波士顿地区的房屋中位数价格(MEDV)。共 506 条样本(观测值),每条样本对应一个波士顿城镇的统计数据。典型的单变量回归任务,目标是通过 13 个特征预测MEDV。数据集字段(特征)说明如下
| 序号 | 特征名称 | 名称中文 | 说明 |
|---|---|---|---|
| 1 | CRIM | 人均犯罪率 | 城镇每千人犯罪次数 |
| 2 | ZN | 住宅用地比例 | 25,000 平方英尺以上住宅用地比例(规划限制,非住宅用地比例) |
| 3 | INDUS | 非零售商业用地比例 | 城镇非零售商业用地比例(商业活动密度) |
| 4 | CHAS | 查尔斯河虚拟变量 | 1 = 邻近河流,0 = 不邻近 |
| 5 | NOX | 氮氧化物浓度 | ppm,空气质量指标 |
| 6 | RM | 平均房间数 | 每套住宅的平均房间数 |
| 7 | AGE | 房龄较老房屋占比 | 1940 年前建成的自住房屋比例 |
| 8 | DIS | 就业中心加权距离 | 到波士顿 5 个就业中心的加权距离(通勤便利性) |
| 9 | RAD | 辐射状公路可达性指数 | 交通便利程度,指数越高表示越容易到达高速公路 |
| 10 | TAX | 房产税税率 | 每 1 万美元房产的年税额 |
| 11 | PRTATIO | 师生比 | 城镇师生比(教育资源指标) |
| 12 | B | 黑人比例计算值 | 公式:B = 1000(Bk - 0.63)^2,其中Bk为黑人比例 |
| 13 | LSTAT | 低收入人群比例 | %,社会经济地位指标 |
| 14 | MEDV | 房屋中位数价格 | 单位:千美元,目标变量 |
1.各特征分布情况
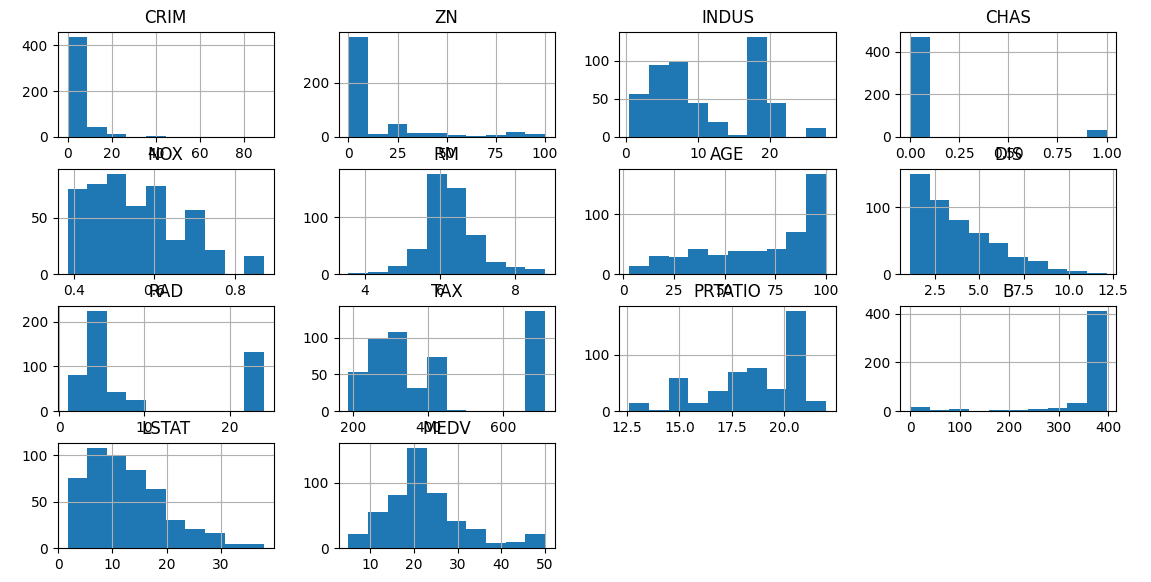
二、算法评估
尝试了数据标准化没有很大提升。
1.九种回归算法RMSE 和 R^2 比较
图中的蓝色柱子表示 RMSE,红色柱子表示 R^2 分数。通过这个图,可以直观地比较不同模型的性能。

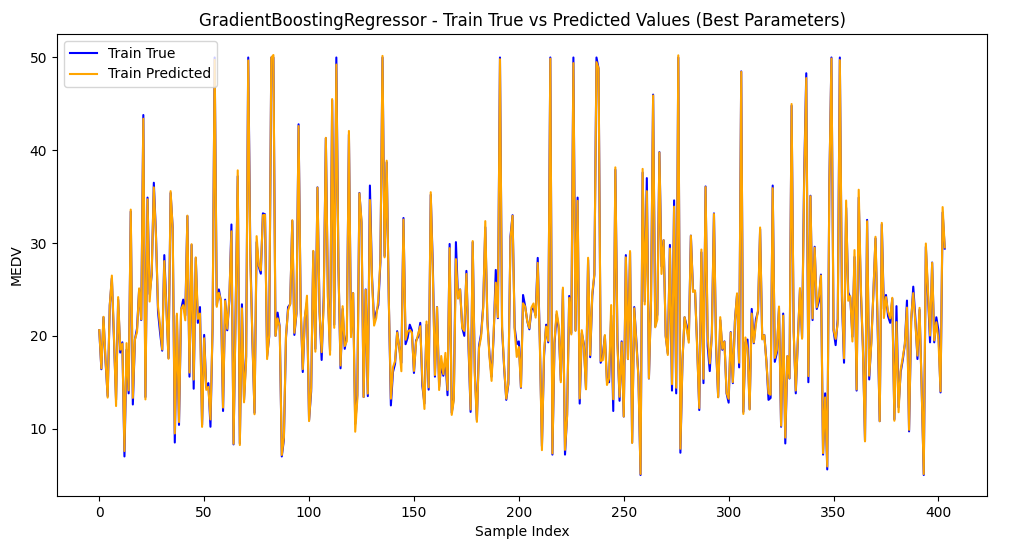
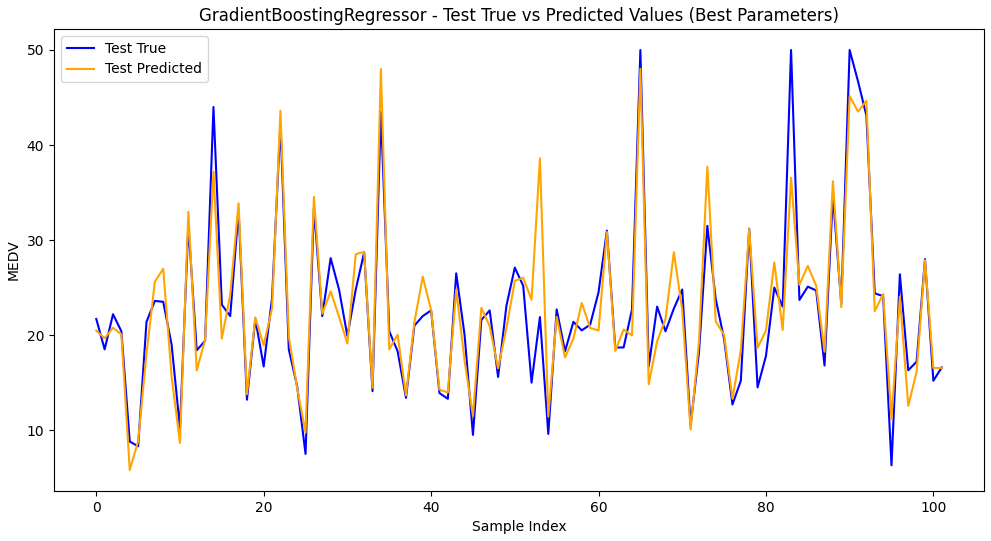
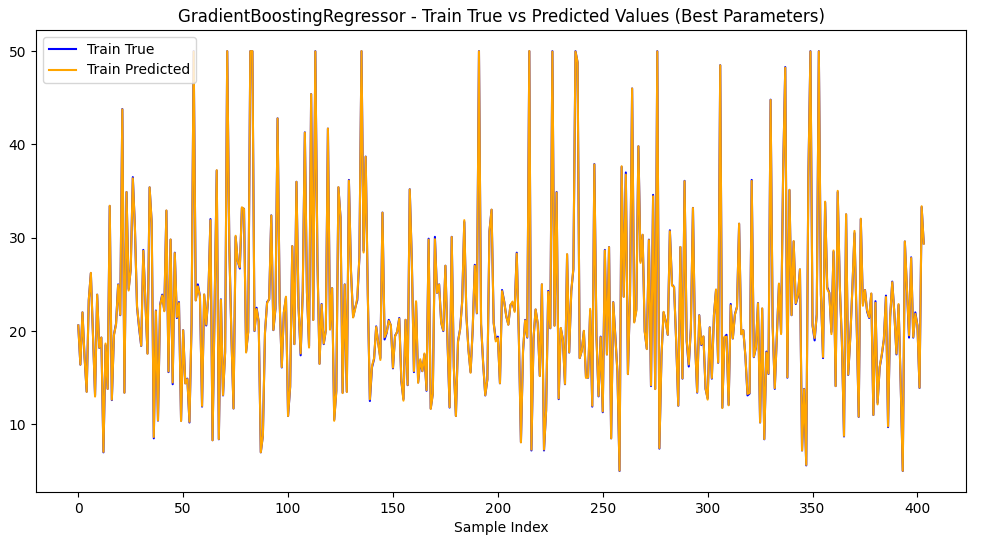
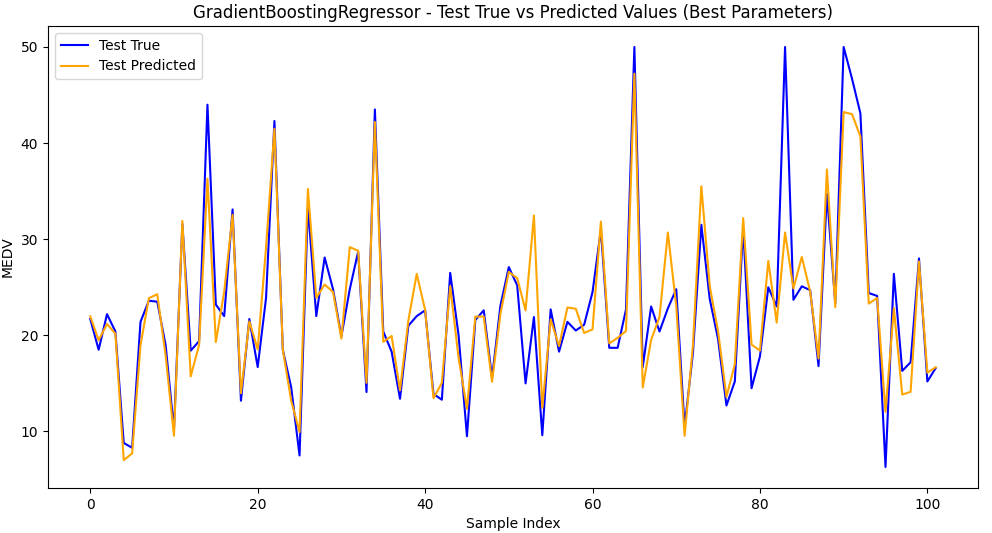
2.训练集和测试集预测值和真实值可视化
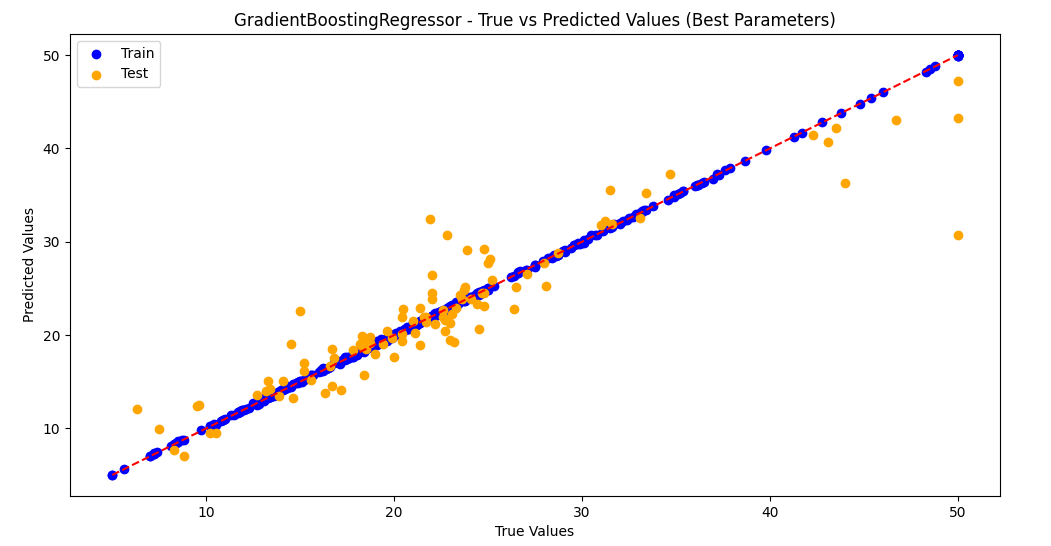
梯度提升回归树模型GradientBoostingRegressor和随机搜索最佳参数,均方根误差RMSE为2.725 (0.540),决定系数R2为 0.903 (0.035)。
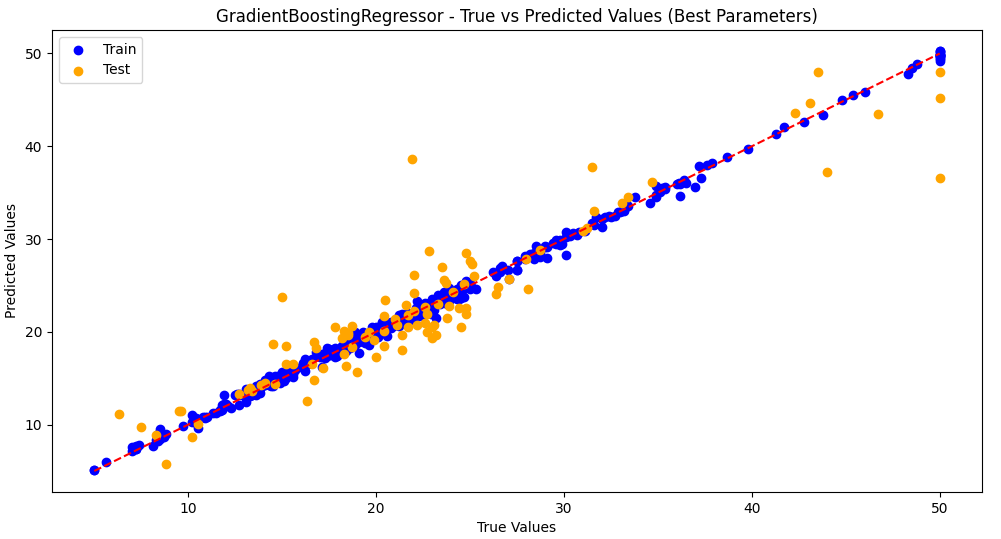
3.训练集和测试集预测值和真实值散点图
Best parameters: {'learning_rate': 0.12829684257109286, 'max_depth': 5, 'max_features': 'log2', 'min_samples_leaf': 3, 'min_samples_split': 5, 'n_estimators': 122, 'random_state': 42}
Best cross-validation score: -7.715896901281501
MAE: -1.943 (0.285)
MSE: -7.716 (3.060)
MBE: 0.008 (0.223)
RMSE: 2.725 (0.540)
R2: 0.903 (0.035)
4.特征重要性
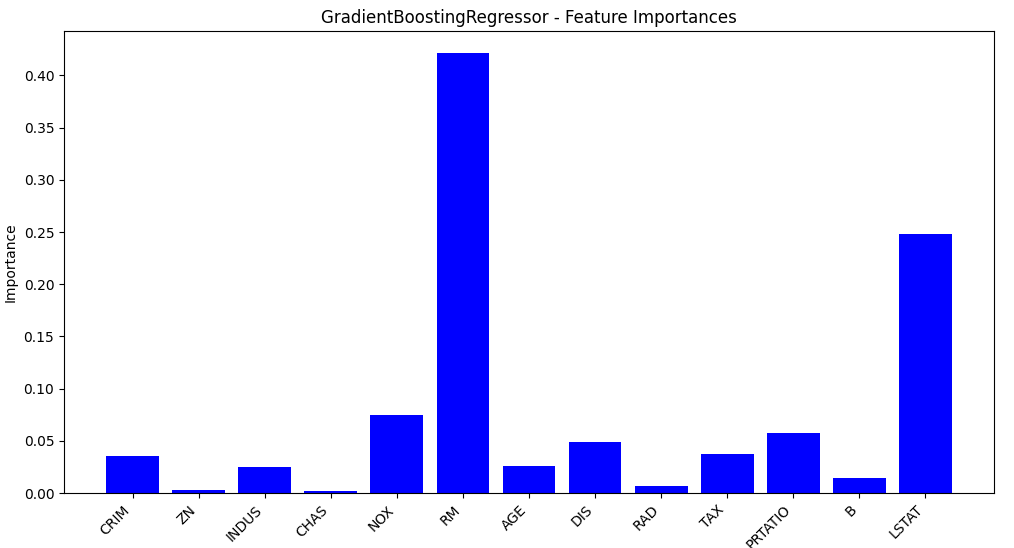
5.加入主成分分析PCA降维
评估结果不好,不适合使用降维方法。(pca = PCA
n_components=3 # 降维到 3 个主成分
X_pca = pca.fit_transform(X))
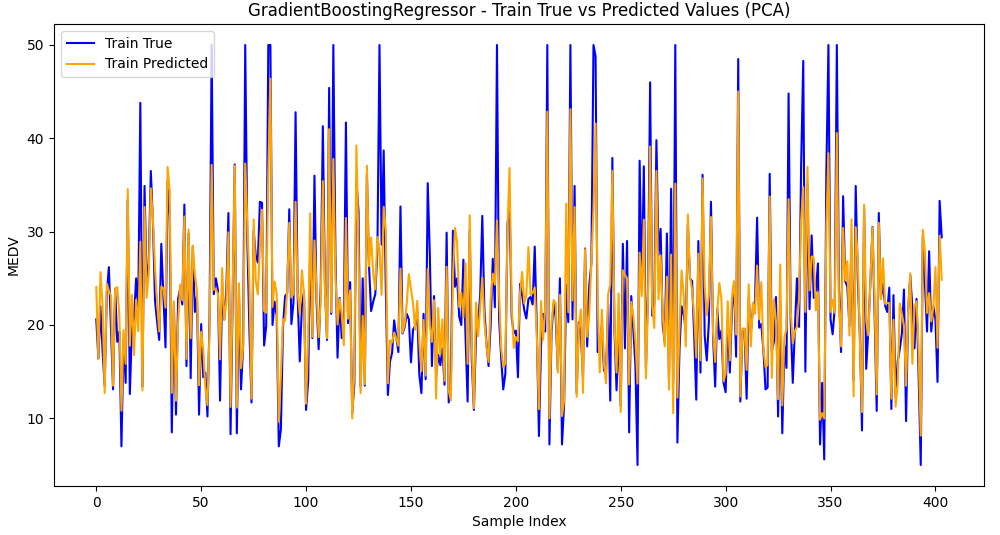
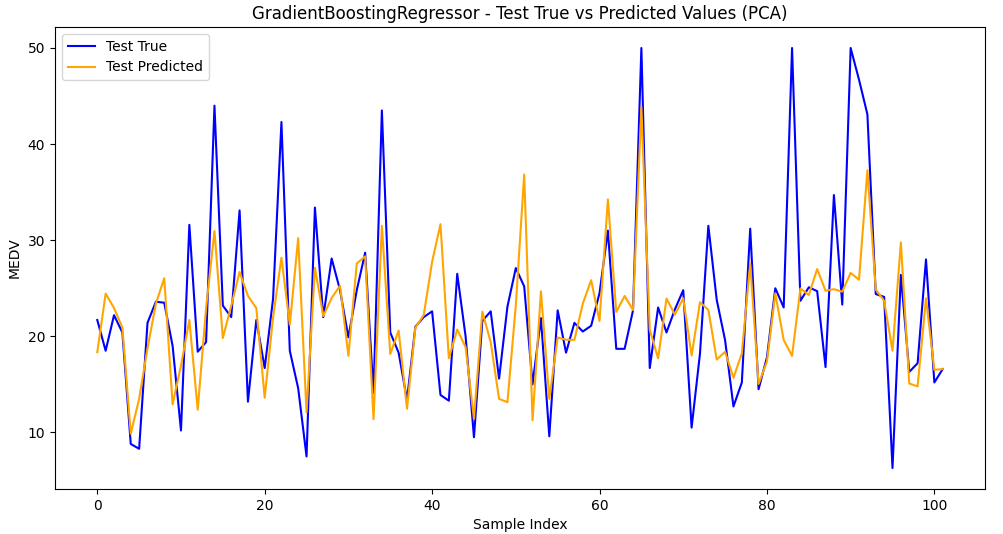
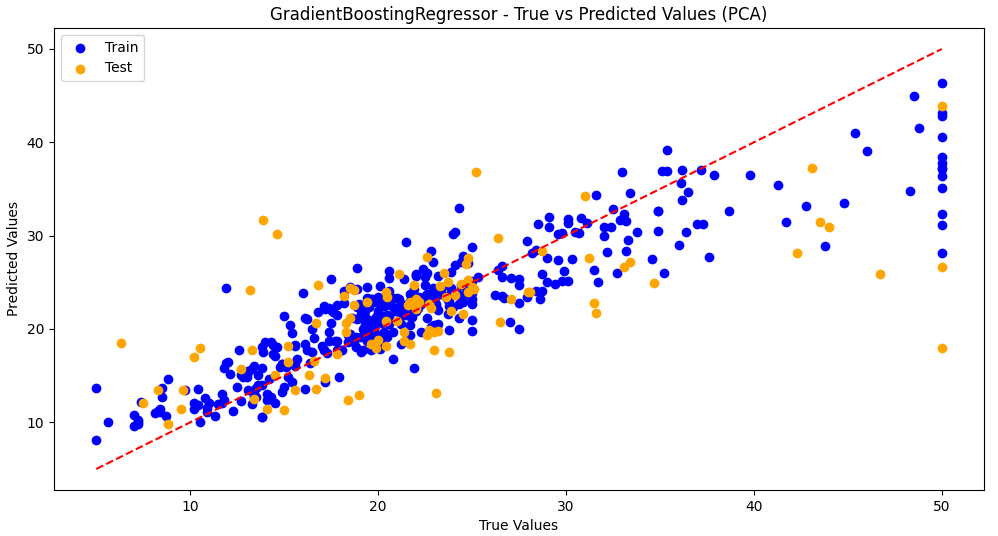
Model: GradientBoostingRegressor
MAE: -4.632 (0.564)
MSE: -48.134 (15.559)
MBE: -0.023 (0.886)
RMSE: 6.845 (1.202)
R2: 0.413 (0.152)
6.网格搜索(Grid Search)最佳参数组合
Best parameters: {'learning_rate': 0.1, 'max_depth': 6, 'max_features': 'sqrt', 'n_estimators': 160, 'random_state': 7}
Best cross-validation score: -8.265665640433037
MAE: -1.951 (0.287)
MSE: -8.266 (3.460)
MBE: -0.011 (0.315)
RMSE: 2.813 (0.595)
R2: 0.897 (0.039)
7.随机搜索(Random Search)
在前参数范围基础上寻找更好一点参数。结果在最前面1
三、完整代码
from pandas import read_csv
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LinearRegression, ElasticNet, Lasso, Ridge
from sklearn.tree import DecisionTreeRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.svm import SVR
from sklearn.ensemble import GradientBoostingRegressor, ExtraTreesRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt# 导入数据
filename = 'housing.csv'
names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS','RAD', 'TAX', 'PRTATIO', 'B', 'LSTAT', 'MEDV']
data = read_csv(filename, names=names, delim_whitespace=True)# 将数据分为输入数据和输出结果
array = data.values
X = array[:, 0:13] # 输入特征
Y = array[:, 13] # 输出目标变量# 设置交叉验证参数
n_splits = 10
seed = 7
kfold = KFold(n_splits=n_splits, shuffle=True, random_state=seed)# 定义多个回归模型
models = {'LinearRegression': LinearRegression(),'ElasticNet': ElasticNet(),'Lasso': Lasso(),'Ridge': Ridge(),'DecisionTreeRegressor': DecisionTreeRegressor(),'KNeighborsRegressor': KNeighborsRegressor(),'SVR': SVR(),'GradientBoostingRegressor': GradientBoostingRegressor(),'ExtraTreesRegressor': ExtraTreesRegressor()
}# 定义评分标准
scoring = ['neg_mean_absolute_error', 'neg_mean_squared_error', 'r2']# 定义自定义评分函数
def mean_bias_error(y_true, y_pred):return np.mean(y_pred - y_true)def root_mean_squared_error(y_true, y_pred):return np.sqrt(mean_squared_error(y_true, y_pred))# 评估每个模型
model_names = []
rmse_scores = []
r2_scores = []for name, model in models.items():print(f"Model: {name}")# 计算MAEresult_mae = cross_val_score(model, X, Y, cv=kfold, scoring=scoring[0])print('MAE: %.3f (%.3f)' % (result_mae.mean(), result_mae.std()))# 计算MSEresult_mse = cross_val_score(model, X, Y, cv=kfold, scoring=scoring[1])print('MSE: %.3f (%.3f)' % (result_mse.mean(), result_mse.std()))# 计算R^2result_r2 = cross_val_score(model, X, Y, cv=kfold, scoring=scoring[2])print('R2: %.3f (%.3f)' % (result_r2.mean(), result_r2.std()))# 计算MBE和RMSEmbe_scores = []rmse_scores_temp = []for train_index, test_index in kfold.split(X):X_train, X_test = X[train_index], X[test_index]Y_train, Y_test = Y[train_index], Y[test_index]model.fit(X_train, Y_train)Y_pred = model.predict(X_test)mbe_scores.append(mean_bias_error(Y_test, Y_pred))rmse_scores_temp.append(root_mean_squared_error(Y_test, Y_pred))print('MBE: %.3f (%.3f)' % (np.mean(mbe_scores), np.std(mbe_scores)))print('RMSE: %.3f (%.3f)' % (np.mean(rmse_scores_temp), np.std(rmse_scores_temp)))print("-" * 50)# 保存模型名称、RMSE 和 R^2 分数model_names.append(name)rmse_scores.append(np.mean(rmse_scores_temp))r2_scores.append(np.mean(result_r2))# 绘制柱状图
fig, ax1 = plt.subplots(figsize=(12, 8))# 设置柱状图的位置
bar_width = 0.35
index = np.arange(len(model_names))# 绘制 RMSE 柱状图
ax1.bar(index, rmse_scores, bar_width, label='RMSE', color='tab:blue')
ax1.set_xlabel('Model')
ax1.set_ylabel('RMSE', color='tab:blue')
ax1.tick_params(axis='y', labelcolor='tab:blue')# 创建第二个坐标轴
ax2 = ax1.twinx()# 绘制 R^2 柱状图
ax2.bar(index + bar_width, r2_scores, bar_width, label='R^2', color='tab:red')
ax2.set_ylabel('R^2', color='tab:red')
ax2.tick_params(axis='y', labelcolor='tab:red')# 添加标题和标签
ax1.set_title('Comparison of RMSE and R^2 for Different Models')
ax1.set_xticks(index + bar_width / 2)
ax1.set_xticklabels(model_names, rotation=45, ha='right')
ax1.legend(loc='upper left')
ax2.legend(loc='upper right')plt.tight_layout()
plt.show()