什么网站合适做流量怎么进行网络推广
1. 预训练的通俗理解:AI的“高考集训”
我们可以将预训练(Pre-training) 形象地理解为大模型AI的“高考集训”。就像学霸在高考前需要刷五年高考三年模拟一样,大模型在正式诞生前,也要经历一场声势浩大的“题海战术”。
这个“题海战术”的核心就是将海量的文本、图片、视频等数据“喂”给AI。通过这种大规模的数据投喂,AI会进行自监督学习,疯狂地吸收知识,自主挖掘数据中的内在规律和模式。最终,通过这个过程,AI才能炼成能写诗、能看病、会作画的全能大脑。

2. 预训练的技术定义:构建基础认知能力
从技术角度来看,预训练是指在AI模型应用于特定任务之前,先利用海量无标注数据,让模型自主挖掘语言、视觉、逻辑等方面的通用规律,从而构建其基础认知能力的训练过程。
通过从大规模未标记数据中学习通用特征和先验知识,预训练能够显著减少模型对标记数据的依赖。这不仅能够加速模型在有限数据集上的训练过程,还能在很大程度上优化模型的性能,使其在后续的下游任务中表现更出色。
预训练的核心逻辑与关键操作
预训练过程并非简单的数据堆砌,其背后包含了一系列精妙的核心逻辑和技术操作。
1. 数据投喂:构建AI的“知识库”
高质量、多样化、大规模的数据集是预训练的基石。
- 海量数据抓取与投喂:
- 文本数据: 包括书籍、网页、论文、对话记录、代码、新闻文章等。例如,GPT-3的训练数据包含了Common Crawl、WebText2、Books1、Books2、Wikipedia等海量语料。
- 图像数据: 带有
alt标签的图片(用于图像描述)、视频帧、图像-文本对等。例如,CLIP模型就通过大量的图像-文本对进行预训练。 - 结构化数据: 如知识图谱、表格数据等,用于增强模型的逻辑推理和事实性知识。
- 数据清洗与过滤: 在数据投喂前,必须进行严格的清洗和过滤,以确保数据质量。这包括剔除乱码、重复内容、低质量内容、以及涉及黄赌毒等不合规内容。数据质量直接影响模型的学习效果和泛化能力。
- Tokenizer分词: 对于文本数据,需要通过Tokenizer(分词器) 将原始文本切分成AI能够理解的“单词积木”,即Token。Token可以是单词、子词或字符,其目的是将连续的文本转化为离散的数值表示。
- 关键操作: 构建一个量级在50k-100k的词表(Vocabulary)。例如,像
"深度"和"学习"这样的词汇可能会被分别编码,而"深度学习"这个短语则可能被作为一个独立的Token进行编码,从而更好地捕捉语义信息。常用的分词算法包括BPE (Byte Pair Encoding)、WordPiece和SentencePiece。
- 关键操作: 构建一个量级在50k-100k的词表(Vocabulary)。例如,像
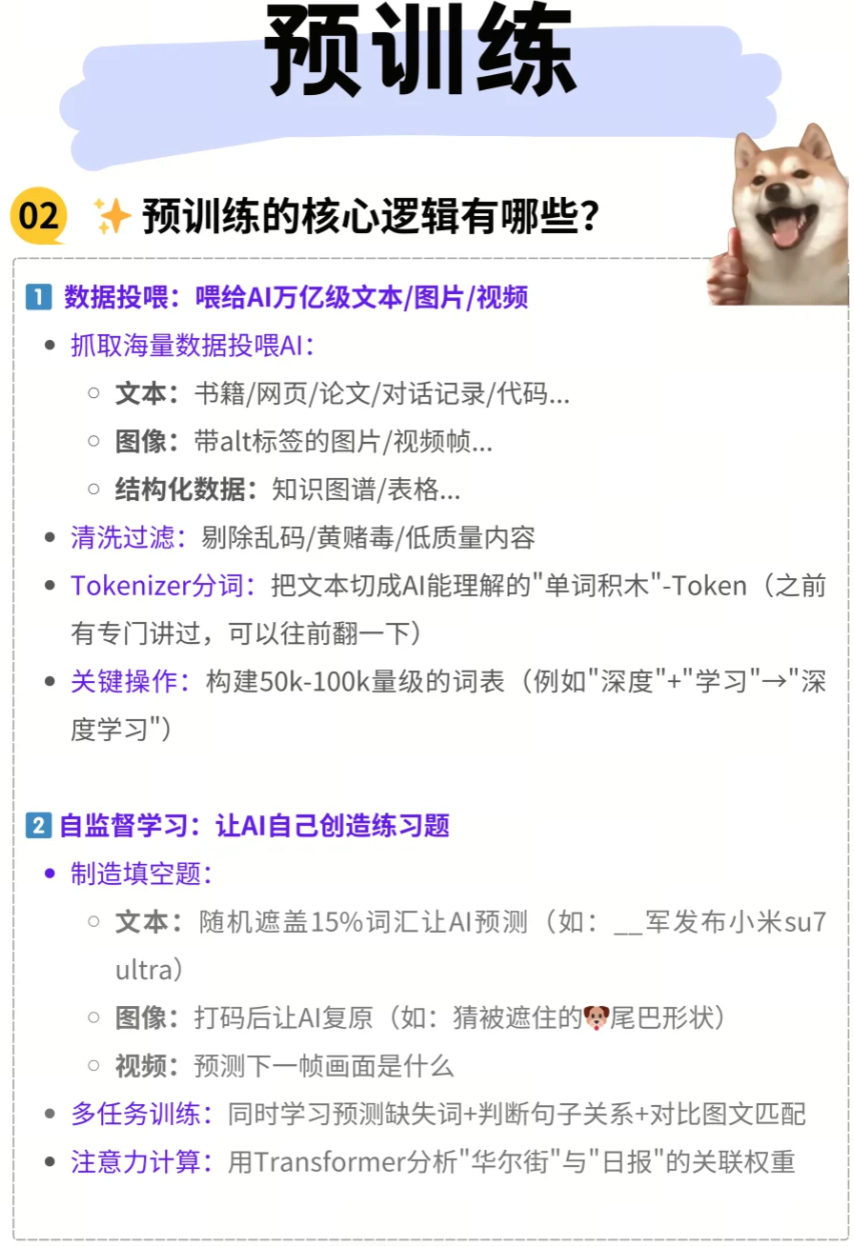
2. 自监督学习:让AI“自己创造练习题”
自监督学习(Self-supervised Learning) 是预训练的核心机制,它允许模型在没有人工标注的情况下,从大规模数据中学习有用的表示。
- 制造“填空题”: 模型通过预测数据中缺失的部分来学习。
- 文本领域(如BERT的MLM任务): 随机遮盖文本中15%的词汇(Token),然后让AI预测被遮盖的词。例如,在句子
"__军发布小米su7 ultra"中,模型需要预测出"小"字。这种机制迫使模型理解上下文语境和词汇间的关系。 - 图像领域(如MAE): 随机遮盖图像的部分区域(打码),然后让AI复原被遮盖的像素或特征。例如,
"猜被遮住的🐶尾巴形状",模型需要根据未被遮盖的部分推断出尾巴的形态。 - 视频领域: 预测视频的下一帧画面是什么,或预测被遮盖的帧内容。这有助于模型学习时序信息和运动模式。
- 文本领域(如BERT的MLM任务): 随机遮盖文本中15%的词汇(Token),然后让AI预测被遮盖的词。例如,在句子
- 多任务训练: 为了让模型学习更全面的能力,预训练通常会包含多个自监督任务。
- 文本: 除了预测缺失词,还可能包含下一句预测(NSP) 任务,即判断两个句子之间是否存在前后关系。
- 图像与文本: 学习图文匹配,让模型判断图像和文本描述是否匹配,从而理解多模态信息。
- 注意力计算(Transformer): 在预训练过程中,Transformer 架构的自注意力机制(Self-Attention) 至关重要。它允许模型在处理序列数据时,动态地计算不同部分之间的关联权重。例如,在分析
"华尔街日报"时,模型能够计算"华尔街"和"日报"这两个词之间的关联权重,从而理解其作为一个整体的特定含义。
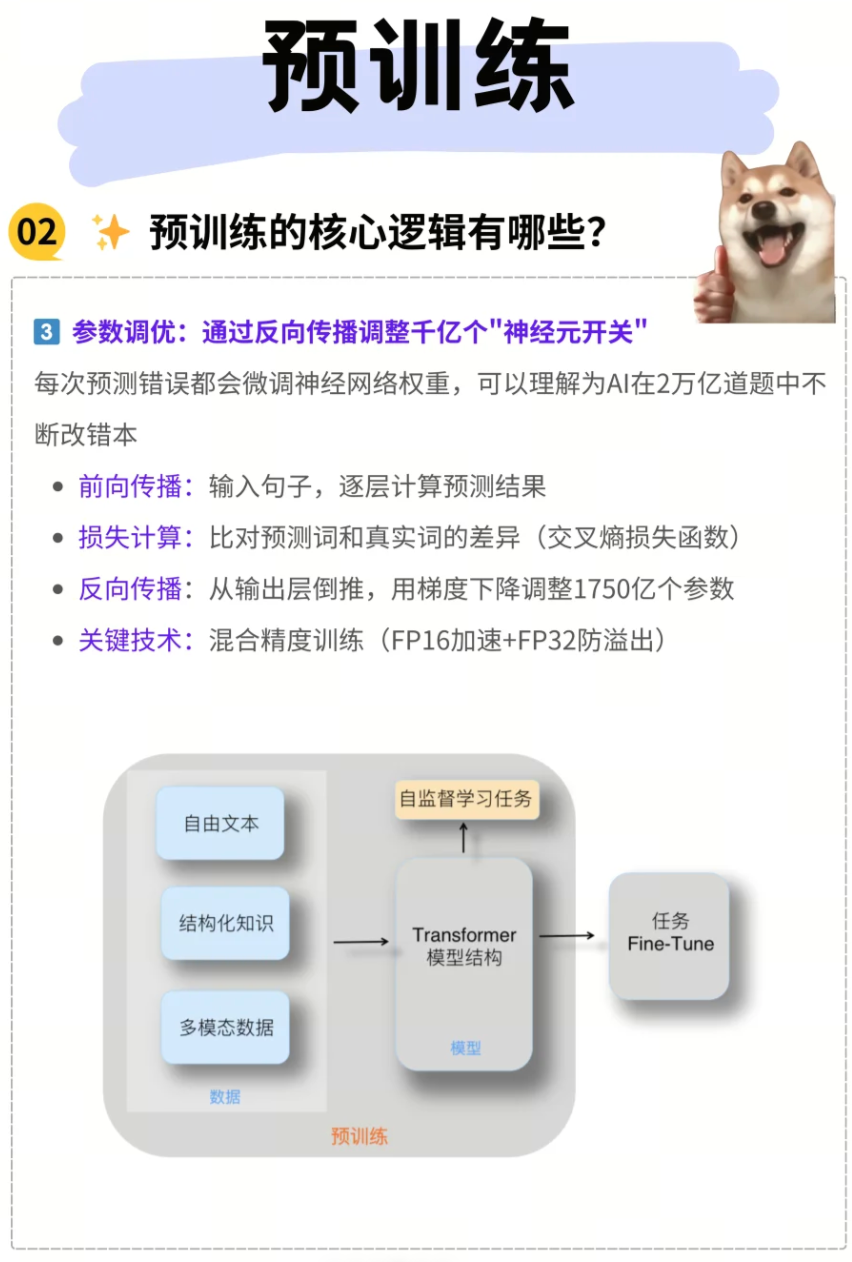
3. 参数调优:微调千亿个“神经元开关”
反向传播(Backpropagation) 和梯度下降(Gradient Descent) 是模型优化的核心算法。
- 误差纠正与权重调整: 每次模型进行预测后,都会将预测结果与真实值进行比较,计算出损失(Loss)。这个损失值通过反向传播算法,用于微调神经网络中数千亿个参数(权重)。
- AI的“改错本”: 可以把这个过程理解为AI在面对数万亿道题目时,不断地批改自己的“错题本”。每当预测错误时,模型就会根据错误程度和方向,对内部的“神经元开关”(即参数)进行细微调整,以期在下一次预测中做得更好。这个迭代优化的过程,使得模型能够逐步收敛,并学到更精确的特征表示。
相关推荐
-
2025大模型技术架构揭秘:GPT-4、Gemini、文心等九大模型核心技术对比与实战选型指南-CSDN博客
-
💡大模型中转API推荐
-
✨中转使用教程
技术交流:欢迎在评论区共同探讨!更多内容可查看本专栏文章,有用的话记得点赞收藏噜!
