网站为什么要备案电子商务营销的概念
前言
从这个模型开始,我的数据集主阵地就将从装甲板转移到手语视频数据集,模型开始变得更加复杂,数据集当然也要更复杂啦,我将记录在这个过程中遇到的问题和解决后续。
数据读取
由于是视频数据集,我采取的方法是将每一帧读取进来,灰度处理成单通道(个人认为彩色并没有什么信息,同时也是减少通道数量),再将前几帧数据集堆叠成多通道,实现对于视频的处理。
import cv2
import os
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
import random
import torch
import time
import warnings
# warnings.filterwarnings("ignore")
root='/home/chen/Dataset/NMFs-CSL/jpg_video'
labels=os.listdir(root)[:10]
labels

videos_path=[]
for label in labels:for filename in os.listdir(os.path.join(root,label)):if not filename.endswith(".mp4"):videos_path.append(os.path.join(root,label,filename))
videos_path
def train_test_split(data_path,train=0.8):train_data_path=[]test_data_path=[]num_len=len(data_path)indices=list(range(num_len))random.seed(0)random.shuffle(indices)train_num=int(num_len*train)for i in indices[:train_num]:train_data_path.append(data_path[i])for i in indices[train_num:]:test_data_path.append(data_path[i])return train_data_path,test_data_path
train_data_path,test_data_path=train_test_split(videos_path)
len(train_data_path),len(test_data_path)
堆叠多帧成多通道
def stack_frames(frames, num_frames):"""将多个连续帧堆叠成一个高维输入。Args:frames: 帧序列 (list of tensors)num_frames: 堆叠的帧数Returns:stacked_frame: 堆叠后的高维输入"""stacked_frame = torch.cat(frames[:num_frames], dim=0) # 堆叠成一个高维输入
# print(stacked_frame.shape)return stacked_frame
train_data=[]
test_data=[]
train_label=[]
test_label=[]
frames_len=4
for video in train_data_path:frames=[]for i in os.listdir(video):frame=cv2.cvtColor(cv2.resize(cv2.imread(os.path.join(video,i)),(224,224)),cv2.COLOR_BGR2GRAY)frame=torch.tensor(frame,dtype=torch.float32)frame=frame.unsqueeze(0)normalize = transforms.Normalize(mean=[0.5], std=[0.5])frame=normalize(frame)frames.append(frame)print(len(frames))train_label.append(video.split('/')[6])train_data.append(stack_frames(frames,frames_len))
for video in test_data_path:frames=[]for i in os.listdir(video):frame=cv2.cvtColor(cv2.resize(cv2.imread(os.path.join(video,i)),(224,224)),cv2.COLOR_BGR2GRAY)frame=torch.tensor(frame,dtype=torch.float32)frame=frame.unsqueeze(0)normalize = transforms.Normalize(mean=[0.5], std=[0.5])frame=normalize(frame)frames.append(frame)
# select=len(frames)//2test_label.append(video.split('/')[6])test_data.append(stack_frames(frames,frames_len))
train_labels = [labels.index(item) for item in train_label if item in labels]
test_labels = [labels.index(item) for item in test_label if item in labels]
train_labels,test_labels

batch_size=16
class MyDatasets(Dataset):def __init__(self,data,labels,size=None):self.data=dataself.labels=labelsself.size=sizeself.end_time=time.time()def __len__(self):return len(self.data)def __getitem__(self,index):img=self.data[index]label=torch.tensor(self.labels[index],dtype=torch.long)
# print(img.shape)
# print(time.time()-self.end_time)return img,label
def load_data(train_data,train_labels,test_data,test_labels,batch_size,size=None):train=MyDatasets(train_data,train_labels)test=MyDatasets(test_data,test_labels)return DataLoader(train,batch_size,shuffle=True,num_workers=8),DataLoader(test,batch_size,shuffle=True,num_workers=8)
train_iter,test_iter=load_data(train_data,train_labels,test_data,test_labels,batch_size)
for x,y in train_iter:print(x.shape)break
模型
import torch.nn as nn
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device

也是todesk了一台有显卡的电脑,速度嘎嘎快。虽然但是第一次cuda,遇到好几个报错,什么模型在cuda上,数据没放cuda上,还有结果acc什么的要matplotlib要放在cpu上。
# 输入图像为224*224*64
net=nn.Sequential(
nn.Conv2d(frames_len,96,kernel_size=11,stride=4,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(96,256,kernel_size=5,padding=2),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(256,384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(384,384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(384,256,kernel_size=3,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Flatten(),
nn.Linear(6400,4096),nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096,4096),
nn.Dropout(p=0.5),
nn.Linear(4096,len(labels))).to(device)
def init_weight(m):if type(m)==nn.Linear or type(m)==nn.Conv2d:nn.init.xavier_uniform_(m.weight)
net.apply(init_weight)

loss_fn=nn.CrossEntropyLoss()
optimer=torch.optim.SGD(net.parameters(),lr=0.0001)#0.001会导致loss为nan
# 初始化最小测试损失
best_test_loss = float('inf')
best_model_path = './models/AlexNet1.pt'
调参了这么些个模型最大体会就是轮次调大一点,那样就只需要调小轮次再训练,而不是一直调大,并且很多时候跑多轮了才会发现一些关键问题,不要看开始不行就停下来!!看完结果再决定。
epochs_num=300
train_len=len(train_iter.dataset)
all_acc=[]
all_loss=[]
test_all_acc=[]
shape=None
for epoch in range(epochs_num):acc=0loss=0for x,y in train_iter:x=x.to(device)y=y.to(device)hat_y=net(x)l=loss_fn(hat_y,y)loss+=loptimer.zero_grad()l.backward()optimer.step()acc+=(hat_y.argmax(1)==y).sum()all_acc.append((acc/train_len).cpu().numpy())all_loss.append(loss.detach().cpu().numpy())
# print(all_loss)test_acc=0test_loss=0test_len=len(test_iter.dataset)with torch.no_grad():for x,y in test_iter:x=x.to(device)y=y.to(device)shape=x.shapehat_y=net(x)test_loss+=loss_fn(hat_y,y)test_acc+=(hat_y.argmax(1)==y).sum()test_all_acc.append((test_acc/test_len).cpu().numpy())print(f'{epoch}的test的acc{test_acc/test_len}')# 保存测试损失最小的模型if test_loss < best_test_loss:best_test_loss = test_loss
# torch.save(net, best_model_path)dummy_input = torch.randn(shape)
# torch.onnx.export(net, dummy_input, "./models/LeNet6.onnx", opset_version=11)print(f'Saved better model with Test Loss: {best_test_loss:.4f}')

可视化
import matplotlib.pyplot as plt
损失函数可视化
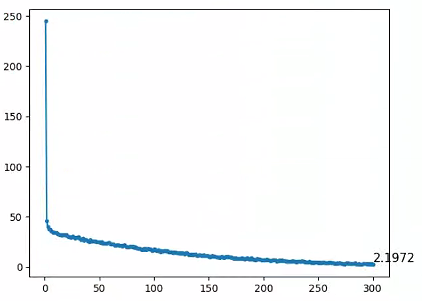
plt.plot(range(1,epochs_num+1),all_loss,'.-',label='train_loss')
plt.text(epochs_num, all_loss[-1], f'{all_loss[-1]:.4f}', fontsize=12, verticalalignment='bottom')
准确率可视化
plt.plot(range(1,epochs_num+1),all_acc,'-',label='train_acc')
plt.text(epochs_num, all_acc[-1], f'{all_acc[-1]:.4f}', fontsize=12, verticalalignment='bottom')
plt.plot(range(1,epochs_num+1),test_all_acc,'-.',label='test_acc')
plt.legend()

看上去似乎效果还可以,实际上我认为完全没有学习我想要它学习的内容。
bug
1.正确率一直很低且相同
解决方法:我查看了整体思路,实在没有头绪,打印了train的loss,惊然发现loss为nan,于是默默将学习率调到很低,终于acc开始有了变化。
2.loss下降,但train和test正确率疯狂在震荡且无提升
解决方法:由于准确率在随机的那个值附近徘徊,判断是没有学习到东西,调高学习率之后,train的acc疯狂上升,test的acc轻微上升。
3.train的acc很高,但test的acc很低
解决方法:发现在调低batch和帧数之后,train疯狂上升到98%,test也有所上升,结论模型根本没有在识别视频手语,而是在做图片的分类,我个人感觉是对于这个模型本身就不存在时序性导致的。
总结
后面学的一些模型可能在这个数据集上效果还是不会好吧,先拿这个数据集做练习着,看train的acc就知道我模型应该没写错哈哈,还是有在拟合图片的。