做网站需要看的书上海今天发生的重大新闻
Transformer网络是一种革命性的深度学习架构,由Vaswani等人在2017年的论文《Attention is All You Need》中提出。它彻底改变了自然语言处理(NLP)领域,并成为BERT、GPT等现代模型的核心。
一、核心思想
- 完全基于注意力机制:摒弃传统RNN/CNN的循环或卷积结构,完全依赖自注意力(Self-Attention)捕捉序列内全局依赖。
- 并行计算优势:所有位置的Token可同时处理,显著提升训练效率。
二、核心组件
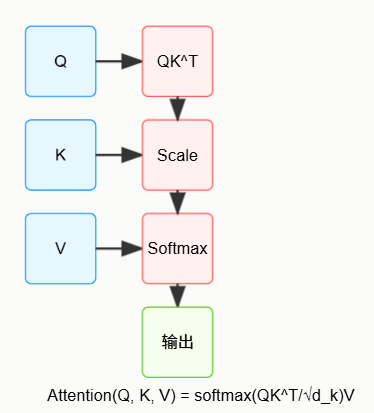
1. 自注意力机制(Self-Attention)
-
输入表示:每个Token被映射为三个向量:
- Query(Q):当前Token的“提问”向量。维度 d k d_k dk
- Key(K):所有Token的“标识”向量。维度 d k d_k dk
- Value(V):实际携带信息的向量。维度 d v d_v dv
-
计算步骤:
- 计算注意力分数: Score = Q ⋅ K T d k \text{Score} = Q \cdot \frac{K^T}{\sqrt{d_k}} Score=Q⋅dkKT(缩放点积)当Score过大或过小时,Softmax的梯度都会趋近0,通过缩放因子 1 d k \frac{1}{\sqrt{d_k}} dk1将Softmax的输入值被限制在合理范围内,避免进入饱和区(梯度消失)。
- 应用Softmax归一化为概率分布。
- 加权求和Value向量: Output = Softmax ( Score ) ⋅ V \text{Output} = \text{Softmax}(\text{Score}) \cdot V Output=Softmax(Score)⋅V
-
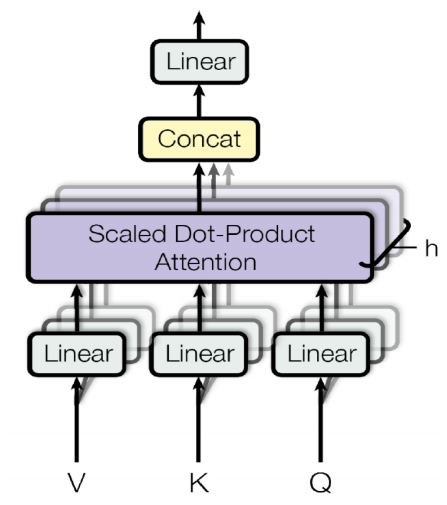
多头注意力(Multi-Head):
单一注意力头可能无法捕捉到所有重要的信息子空间。- 将查询、键、值分别线性投影到 h个不同的子空间,得到 h个头。
- 对每个头独立进行缩放点积注意力计算。
- 将 h个头的输出拼接起来,再通过一个线性变换进行融合。
2. 位置编码(Positional Encoding)
- 问题:自注意力本身无顺序信息。
- 解决方案:为输入添加位置编码向量,使用正弦/余弦函数或可学习参数:
P E ( p o s , 2 i ) = sin ( p o s / 10000 2 i / d ) PE_{(pos, 2i)} = \sin(pos / 10000^{2i/d}) PE(pos,2i)=sin(pos/100002i/d)
P E ( p o s , 2 i + 1 ) = cos ( p o s / 10000 2 i / d ) \quad PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i/d}) PE(pos,2i+1)=cos(pos/100002i/d)
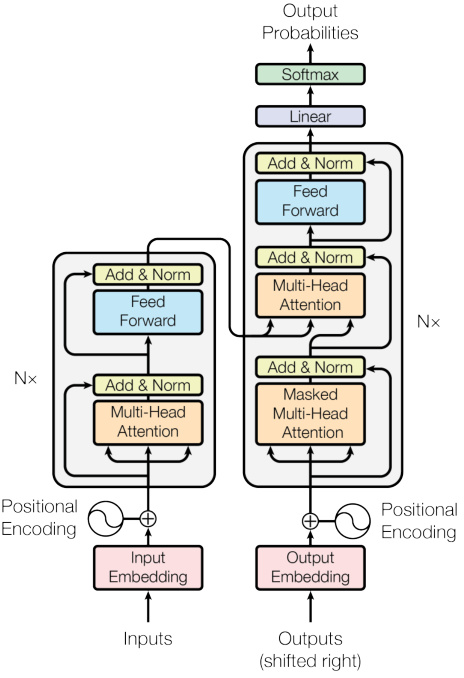
3. 编码器与解码器结构
-
编码器(Encoder):
- 包含多层,每层有:
- 多头自注意力
- 前馈网络(FFN): 两个全连接层(通常含ReLU激活)
- 层间有:残差连接 & 层归一化(LayerNorm)
- 包含多层,每层有:
-
解码器(Decoder):
- 比编码器多一个“掩码多头自注意力”层。
- 掩码自注意力:保持自回归性,防止解码时看到未来Token(通过掩码矩阵实现)。即文本生成是按顺序生成的,防止文本顺序错乱。
三、关键优势
- 并行性:所有Token同时处理,训练速度远超RNN。
- 长距离依赖:自注意力直接关联任意两个位置,缓解RNN的梯度消失问题。
- 可扩展性:通过堆叠层数轻松增大模型规模(如GPT-3有1750亿参数)。
四、流程示例(以翻译任务为例)
- 输入处理:源语言序列添加位置编码后输入编码器。
- 编码器输出:生成富含上下文信息的隐藏表示。
- 解码器工作:
- 自回归生成目标序列(如逐词生成译文)。
- 每一步用掩码自注意力确保仅依赖已生成部分。
- 多头自注意力关联源与目标序列。
五、应用与变体
- 仅编码器:BERT(文本分类、实体识别)。
- 仅解码器:GPT系列(文本生成)。
- 编码器-解码器:T5、BART(翻译、摘要)。
六、局限性
- 计算复杂度:自注意力的 O ( n 2 ) O(n^2) O(n2) 复杂度限制长序列处理(如段落级文本)。
- 改进方向:稀疏注意力(如Longformer)、分块处理(如Reformer)。
七、代码示例(简化版自注意力)
import torch
import torch.nn.functional as Fdef self_attention(Q, K, V):d_k = Q.size(-1)scores = torch.matmul(Q, K.transpose(-2, -1)) / (d_k ** 0.5)attn_weights = F.softmax(scores, dim=-1)output = torch.matmul(attn_weights, V)return output# 示例输入:batch_size=1, seq_len=3, embedding_dim=4
Q = torch.randn(1, 3, 4)
K = torch.randn(1, 3, 4)
V = torch.randn(1, 3, 4)
print(self_attention(Q, K, V).shape) # 输出形状: [1, 3, 4]
Transformer通过其创新的架构设计,成为现代深度学习的基石。理解其核心机制是掌握NLP前沿技术的关键。