网站搭建策略与方法是什么宁波seo外包快速推广
【测试一下性能】
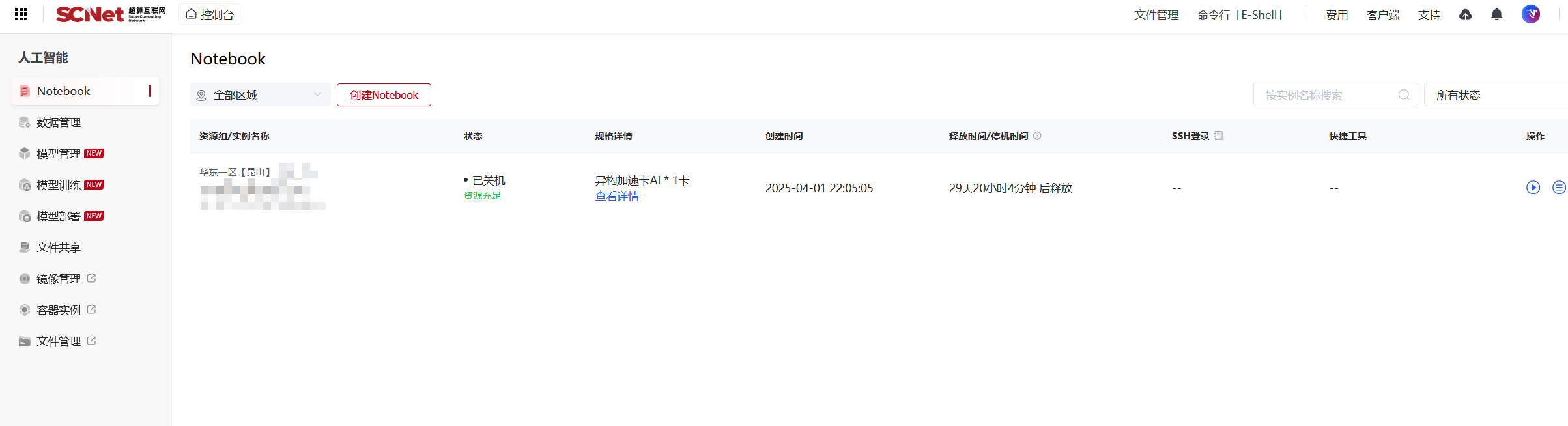
图像测试
在超算互联网里已经有相应的测试环境了,多配置几张卡,进入下载好模型,可以测试,目前根据测试代码测了图像的理解。
代码
代码如下:
# TODO: 导入相关依赖
b_env_ready = True
try:# 系统内置依赖import reimport osimport sysimport subprocessimport argparseimport ioimport timeimport loggingimport warningsfrom transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessorfrom qwen_vl_utils import process_vision_info# 获取根日志记录器并设置日志级别为 ERRORlogger = logging.getLogger()logger.setLevel(logging.ERROR)# 忽略所有警告warnings.filterwarnings("ignore")warnings.filterwarnings('ignore', category=UserWarning, message='1Torch was not compiled.*')warnings.filterwarnings('ignore', category=UserWarning, message='Using a slow image processor*')import ipywidgets as widgetsfrom IPython.display import display, HTML, Imagefrom PIL import Image as PILImagefrom datetime import datetime# 模型依赖from PIL import Imageimport requestsimport torch# from diffusers.utils import load_image
except ModuleNotFoundError as e:missing_module = str(e).split("'")[1]print(f"\033[31m模块未找到错误: 没有名为 '{missing_module}' 的模块\033[0m")print("\033[31m请确保执行第一步依赖模块安装后再运行应用:\033[0m")print("\033[31m如仍有模块缺失错误,请在Notebook中新建单元格执行以下命令安装缺少的模块:\033[0m")print(f"\033[32mpip install {missing_module}\033[0m")print(f"\033[31m将为您自动安装缺失的模块...\033[0m")# Optionally, you could automatically install the modulesubprocess.check_call([sys.executable, "-m", "pip", "install", missing_module])print(f"\033[32m'{missing_module}'模块安装命令执行完成...\033[0m")b_env_ready = Falsetry:if b_env_ready == False:# 退出执行raise SystemExit(f"已尝试安装 '{missing_module}' 模块,请重启Notebook内核,再执行此步骤")
except SystemExit as e:print(e)sys.exit()# 环境变量设置
os.environ["TOKENIZERS_PARALLELISM"] = "false"# ************************************************
# 代码实现部分
# ************************************************print(f"\033[32m环境依赖导入完成...\033[0m\n")g_input_img_url = ""
g_input_text = ""# 创建文件上传小部件
upload = widgets.FileUpload(description='选择本地图片',accept='image/*', # 接受所有图片文件multiple=False # 禁止多文件上传
)# 创建文本输入框
text_box = widgets.Text(placeholder='请输入提示词',disabled=True # 初始时禁用文本框
)# 创建按钮小部件
upload_button = widgets.Button(description='上传图片',disabled=True, # 初始时禁用button_style='primary'
)
process_button = widgets.Button(description='执行推理任务',disabled=True, # 初始时禁用按钮button_style='success'
)# 创建输出小部件
output = widgets.Output()# 定义文件上传事件处理函数
def on_upload_change(change):global g_input_img_url# 检查是否有文件上传if upload.value:# 当有文件上传时,启用上传按钮upload_button.disabled = Falsecheck_all_inputs() # 检查是否满足执行推理任务的条件else:# 没有文件上传时,禁用上传按钮upload_button.disabled = True# 定义上传按钮点击事件处理函数
def on_upload_button_click(b):global g_input_img_urlwith output:output.clear_output() # 清空之前的输出if upload.value == "":print(f"请先选择需要上传的图片!")returnuploaded_file = upload.value[0]file_name = uploaded_file['name']content = uploaded_file['content']# 将字节内容转换为PIL图像image = PILImage.open(io.BytesIO(content))# 指定保存的文件名,以png格式保存timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")input_filename = f"input_{file_name}_{timestamp}.png"image.save(input_filename, format='PNG')g_input_img_url = input_filenameprint(f"\033[32m已将您上传图片{file_name}保存为{input_filename},请输入提示词后点击'执行推理任务'\033[0m\n")text_box.disabled = False# 启用处理按钮check_all_inputs()# 设置文本框的事件处理程序
def on_text_change(change):global g_input_textg_input_text = change['new']check_all_inputs() # 检查是否满足执行推理任务的条件# 定义处理按钮点击事件处理函数
def on_process_button_click(b):global g_input_img_url, g_input_textwith output:output.clear_output() # 清空之前的输出if g_input_img_url and g_input_text:upload.disabled = True#upload_button.disabled = Truetext_box.disabled = Trueprocess_button.disabled = True# 执行推理任务run_model(g_input_img_url, g_input_text, "") upload.disabled = Falsetext_box.value = ""else:print("请确保已经上传图片并输入文字。")# 检查所有输入是否满足条件
def check_all_inputs():if g_input_img_url and g_input_text:process_button.disabled = Falseelse:process_button.disabled = True# 设置小部件的事件处理程序
upload.observe(on_upload_change, names='value')upload_button.on_click(on_upload_button_click)text_box.observe(on_text_change, names='value')process_button.on_click(on_process_button_click)# TODO: 模型和pipe建立
model_id = "./"global pipedef load_model(torch_dtype, device):global pipenum_gpus = torch.cuda.device_count()if num_gpus < 2:print("\033[31m该模型推理运行至少需要 2 张异构加速卡卡,当前只检测到 {} 张。请重新选择创建实例。\033[0m".format(num_gpus))sys.exit()# 释放显存torch.cuda.empty_cache()print(f"\033[31m本模型较大,加载耗时约3-5分钟,请耐心等待...\033[0m")# 加载模型try:print(f"正在以{torch_dtype}类型加载模型...")print(f"开始加载{model_id}模型...")# 使用 AutoProcessor 和模型加载model = Qwen2_5_VLForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")min_pixels = 256 * 28 * 28max_pixels = 1280 * 28 * 28processor = AutoProcessor.from_pretrained(model_id, min_pixels=min_pixels, max_pixels=max_pixels)# processor = AutoProcessor.from_pretrained(model_id)pipe = processor, model # 保存处理器和模型# 这里可以添加更多显存信息和模型状态输出print(f"模型加载完成...")# return processor, modelgpu_memory_allocated = torch.cuda.memory_allocated(device) print(f"\033[32m模型{model_id}加载完成,显存占用: {gpu_memory_allocated / 1024 ** 3:.2f} GB,剩余显存:{(g_gpu_memory - gpu_memory_allocated) / (1024 ** 3):.2f} GB\033[0m\n")print(f"\033[32m模型加载完成...\033[0m\n")print(f"\033[31m请按照以下步骤体验本模型:\033[0m")print(f"\033[31m1.点击'选择本地图片'按钮,选择需要输入的图片\033[0m")print(f"\033[31m2.点击'上传图片'按钮,将您选择的本地图片上传\033[0m")print(f"\033[31m3.将提示词输入在提示词输入框\033[0m")print(f"\033[31m4.点击'执行推理任务'按钮执行\033[0m\n")# 显示文件上传小部件、按钮、文本框和输出display(upload)display(upload_button)display(text_box)display(process_button)display(output)except torch.cuda.OutOfMemoryError as e:print(f"\033[31m显存不足,无法继续运行模型,请重启内核释放显存...\033[0m")print(f"\033[31m错误信息: \033[0m")print(f"{str(e)}\n")# 释放显存torch.cuda.empty_cache()return Falsedef run_model(image_url, prompt, negative_prompt):global pipeprocessor, model = pipe # 获取处理器和模型try:input_image = Image.open(image_url).convert("RGB")messages = [{"role": "user","content": [{"type": "image","image": input_image ,},{"type": "text", "text": prompt},],}]# 生成图片 print(f"正在加载图像...")print(f"您输入的图片为:")display(input_image)print(f"您输入的提示词为:{prompt}")text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)image_inputs, video_inputs = process_vision_info(messages)inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt",)inputs = inputs.to("cuda")# 将图片和文本准备好inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True,return_dict=True, return_tensors="pt").to(model.device, dtype=torch.bfloat16)generated_ids = model.generate(**inputs, max_new_tokens=1280)generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False) print(output_text)# # 生成输出# with torch.no_grad():# output = model.generate(**inputs, max_new_tokens=1024)# # 解码输出# decoded_output = processor.batch_decode(# output, # skip_special_tokens=True# )filtered_text = re.sub(r'user\n.*?\nmodel', '', output_text[0], flags=re.DOTALL)print(filtered_text)timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")print(f"\n\033[31m如需再次体验,请重新上传图片,输入提示词,点击'执行推理任务'按钮执行...\033[0m\n")except torch.cuda.OutOfMemoryError as e:print(f"\033[31m显存不足,无法继续运行模型,请重启内核释放显存...\033[0m")print(f"\033[31m错误信息: \033[0m")print(f"{str(e)}\n")# 释放显存torch.cuda.empty_cache()return False# 检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():for i in range(torch.cuda.device_count()):props = torch.cuda.get_device_properties(i)g_gpu_memory = props.total_memoryprint(f"GPU{i}显存为: {props.total_memory / (1024 ** 3):.2f} GB")
else:print(f"未检测到GPU卡,模型将被加载至CPU,推理所需时间较长")# 加载模型并执行推理
prompt = ""
negative_prompt = ""
image_url = ""parser = argparse.ArgumentParser(description="模型推理提示词参数")
parser.add_argument("image", type=str, nargs='?', default="", help='请输入模型推理输入图片参数')
parser.add_argument("prompt", type=str, nargs='?', default="", help='请输入模型推理提示词参数')
args = parser.parse_args()image_url = args.image
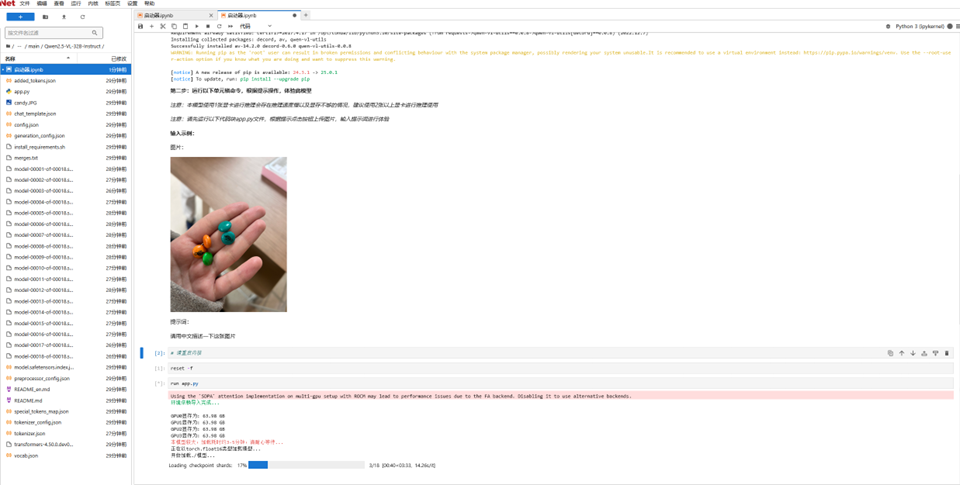
prompt = args.promptload_model(torch.float16, device)运行效果
视频推理
代码
视频推理没有现成的代码,但是参考了一下:
【工程开发】Qwen2.5-VL-32B-Instruct 微调(一)-CSDN博客
需要改一下模型加载的代码,最终代码如下:
import os
import sys
import torch
import argparse
from PIL import Image
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
import logging
import warnings
# 在类初始化时添加版本检查
from packaging import version
import qwen_vl_utils# if version.parse(qwen_vl_utils.__version__) < version.parse("0.2.0"):
# raise ImportError("需要 qwen_vl_utils >= 0.2.0,当前版本: " + qwen_vl_utils.__version__)# 禁用不必要的日志和警告
logging.getLogger().setLevel(logging.ERROR)
warnings.filterwarnings("ignore")class VideoInferenceSystem:def __init__(self, model_name="/root/private_data/SothisAI/model/Aihub/Qwen2.5-VL-32B-Instruct/main/Qwen2.5-VL-32B-Instruct"):self.device = "cuda" if torch.cuda.is_available() else "cpu"self.model = Noneself.processor = Noneself.load_model(model_name)def load_model(self, model_name):"""加载模型和处理器,使用代码片段1的配置"""print("正在加载模型和处理器...")# 显存优化配置min_pixels = 256 * 28 * 28max_pixels = 1280 * 28 * 28try:# 加载模型(禁用特殊注意力机制)self.model = Qwen2_5_VLForConditionalGeneration.from_pretrained(model_name,local_files_only=True,torch_dtype=torch.bfloat16,device_map="auto",attn_implementation="flash_attention_2" # 关键修改)# 加载处理器(启用快速模式)self.processor = AutoProcessor.from_pretrained(model_name,local_files_only=True,use_fast=True # 关键修改)print(f"成功加载 {model_name} 模型")except Exception as e:print(f"模型加载失败: {str(e)}")sys.exit(1)def process_video(self, video_path, prompt, fps=1.0):"""处理视频推理"""# try:# 构建消息结构(兼容本地文件和URL)messages = [{"role": "user","content": [{"type": "video","video": f"file://{os.path.abspath(video_path)}","max_pixels": 360 * 420,"fps": fps},{"type": "text", "text": prompt}]}]text=self.processor.apply_chat_template(messages,tokenize=False, add_generation_prompt=True)image_inputs, video_inputs = process_vision_info(messages)inputs = self.processor(text=[text],images=image_inputs,videos=video_inputs,fps=fps,padding=True,return_tensors="pt")inputs = inputs.to("cuda")# 推理generated_ids = self.model.generate(**inputs, max_new_tokens=128)generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]output_text = self.processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)return output_text# except Exception as e:# print(f"推理错误: {str(e)}")# return Noneif __name__ == "__main__":parser = argparse.ArgumentParser(description="视频推理系统")parser.add_argument("--video", type=str, required=True, help="输入视频路径")parser.add_argument("--prompt", type=str, required=True, help="推理提示词")parser.add_argument("--fps", type=float, default=1.0, help="视频采样率")args = parser.parse_args()# 初始化系统vis = VideoInferenceSystem()# 执行推理result = vis.process_video(args.video, args.prompt) print("\n=== 推理结果 ===")print(result)
运行效果

加载模型和推理花费的时间特别长,是因为显卡的问题?