physon可以做网站怎样制作网站
在Oracle到GreatSQL迁移中排序规则改变引发的乱码问题分析及解决
一、引言
某老系统数据库从 Oracle 迁移至 GreatSQL 过程中,首批迁移(存储过程、表结构、基础数据)顺利完成。然而,第二批数据迁移时出现主键冲突问题:原Oracle数据库中存在主键字段A与a(忽略大小写后视为相同值),但 GreatSQL 默认排序规则 utf8mb4_0900_ai_ci 不区分大小写,导致主键冲突。
为解决此问题,将排序规则调整为 utf8mb4_0900_bin 以区分大小写。但调整后,Java程序读取中文字段时出现乱码(如“好”显示为“好”),直接影响业务功能。本文从环境兼容性、驱动版本、字符编解码机制等角度深入分析问题根源,并提供三种解决方案。
二、环境说明与问题背景
关键组件版本:
| 组件 | 版本号 | 备注 |
|---|---|---|
| 数据库 | GreatSQL 8.0.32-26 | 默认字符集utf8mb4 |
| jdk | 1.7.0_80 | 旧版本,升级成本高 |
| 驱动版本 | mysql-connector-java 5.1.46 | 官方已停止维护 |
| 字符集 | utf8mb4 | 未变动 |
| 排序规则 | utf8mb4_0900_ai_ci->utf8mb4_0900_bin | 变更后引发乱码 |
核心矛盾点
- 业务需求:需使用 utf8mb4_0900_bin 排序规则解决主键冲突。
- 环境限制:旧版 JDK 1.7 与低版本驱动(5.1.46)存在兼容性问题,无法正确解析新排序规则。
三、复现过程
1. 创建测试表并插入数据
greatsql> CREATE TABLE test.t1(id int PRIMARY KEY, cname varchar(10)) DEFAULT charset=utf8mb4 collate=utf8mb4_0900_ai_ci;
Query OK, 0 rows affected (0.02 sec)greatsql> INSERT INTO test.t1 VALUES(1, '好');
Query OK, 1 row affected (0.00 sec)
确认 Java 版本
$ javac -version
javac 1.7.0_80
$ java -version
java version "1.7.0_80"
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
编写 SimpleDBQuery.java,其内容如下:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;public class SimpleDBQuery {public static void main(String[] args) {String url = "jdbc:mysql://172.17.134.66:3301/test?characterEncoding=UTF-8&useSSL=false";String username = "bing";String password = "abc123";Connection conn = null;Statement stmt = null;ResultSet rs = null;try {Class.forName("com.mysql.jdbc.Driver");conn = DriverManager.getConnection(url, username, password);String sql = "SELECT cname FROM t1 LIMIT 1";stmt = conn.createStatement();rs = stmt.executeQuery(sql);if (rs.next()) {String value = rs.getString("cname");System.out.println(" 查询结果: " + value);}} catch (Exception e) {e.printStackTrace();} finally {try {if (rs!= null) rs.close();if (stmt!= null) stmt.close();if (conn!= null) conn.close();} catch (Exception e) {e.printStackTrace();}}}
}
2.Java程序读取数据(正常)
$ javac -cp .:mysql-connector-java-5.1.46.jar SimpleDBQuery.java
$ java -cp .:mysql-connector-java-5.1.46.jar SimpleDBQuery查询结果: 好
3.修改排序规则后复现乱码
greatsql> ALTER TABLE test.t1 CONVERT TO charset utf8mb4 COLLATE utf8mb4_0900_bin;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
再次通过 Java 程序访问数据库中的汉字,则出现乱码:
$ java -cp .:mysql-connector-java-5.1.46.jar SimpleDBQuery查询结果: 好
四、关键排查过程
1. 数据库端验证
确认表中数据无乱码,且字符集未变动,仅排序规则修改。
greatsql> SHOW CREATE TABLE test.t1 \G
*************************** 1. row ***************************Table: t1
Create Table: CREATE TABLE `t1` (`id` int NOT NULL,`cname` varchar(10) COLLATE utf8mb4_0900_bin DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin
1 row in set (0.00 sec)greatsql> SELECT * FROM test.t1;
+----+-------+
| id | cname |
+----+-------+
| 1 | 好 |
+----+-------+
1 row in set (0.01 sec)
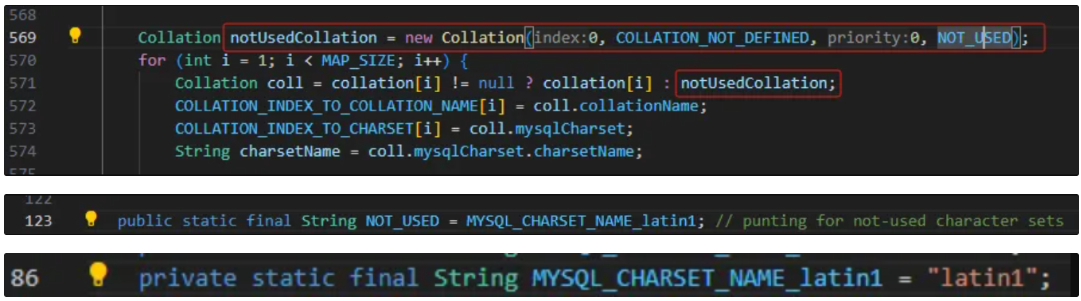
2. 驱动源码分析
查看驱动5.1.46中仅支持 utf8mb4_0900_ai_ci,未定义 utf8mb4_0900_bin。
$ grep -inr 'utf8mb4_0900_ai_ci' *
com/mysql/jdbc/CharsetMapping.java:489: collation[255] = new Collation(255, "utf8mb4_0900_ai_ci", 0, MYSQL_CHARSET_NAME_utf8mb4);
$ grep -inr 'utf8mb4_0900_bin' *
$ pwd
/opt/software/jdbc_test/mysql-connector-java-5.1.46/src
3. 解码逻辑
当驱动无法识别排序规则时,默认使用latin1解码,导致UTF-8字节流被错误解析
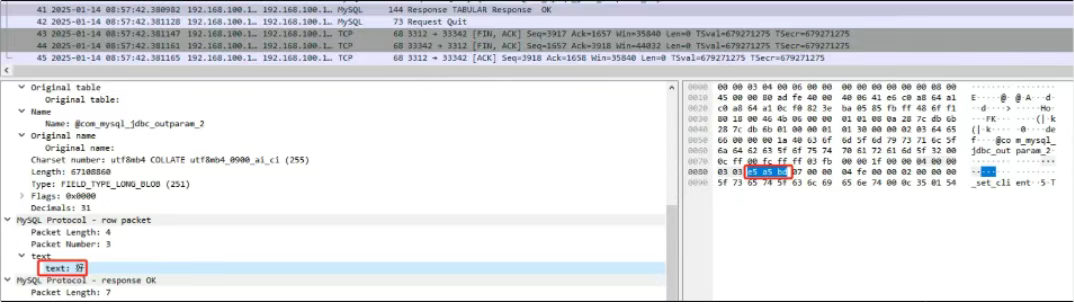
4. 网络抓包验证
通过抓包,对比确认不论是 utf8mb4_0900_ai_ci,还是 utf8mb4_0900_bin,返回的十六进制数据均为 e5 a5 bd
5. 解析抓包内容验证
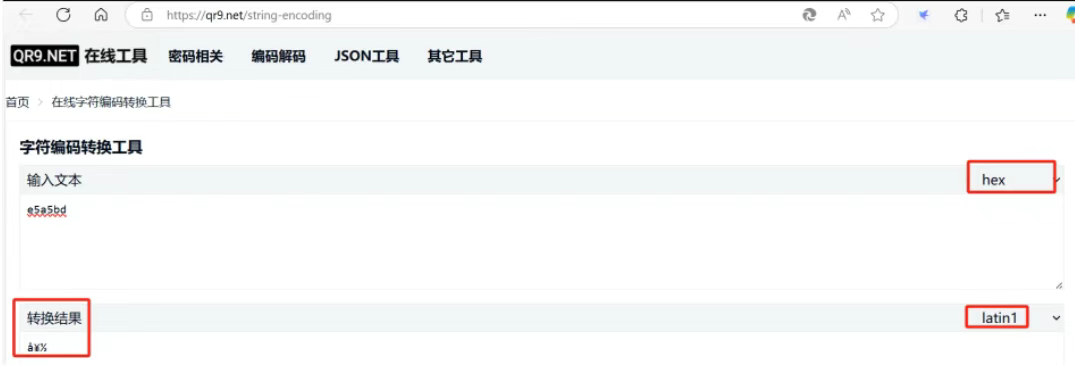
如果是用默认的 latin1 做为字符集进行解码,那么把 e5 a5 bd 按照 latin1 进行解码,发现返回结果集和查询乱码一致。
通过在线工具 https://qr9.net/string-encoding 将十六进制内容按latin1解码发现和乱码内容一致:
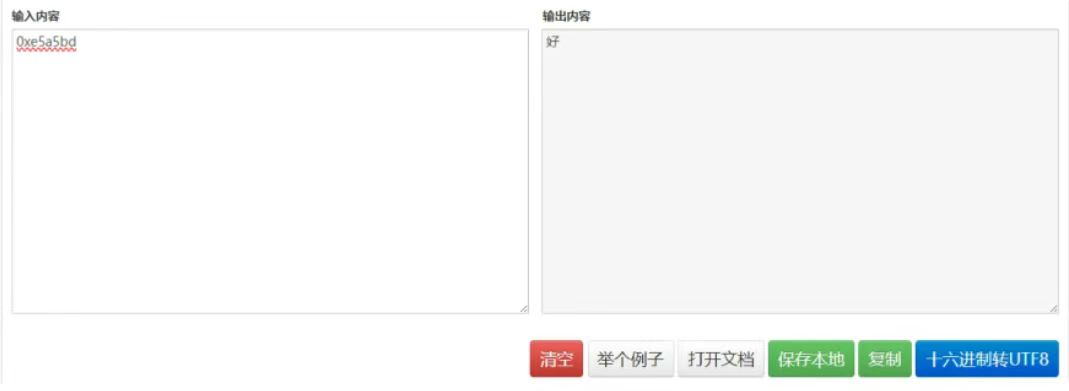
通过在线工具 https://lzltool.cn/Tools/HexToUtf8 将十六进制内容按 utf8 解码,确认能够解析正确的返回结果“好”:
五、根因分析
乱码本质:低版本驱动(5.1.46)未适配 GreatSQL 8.0.32 的 utf8mb4_0900_bin 排序规则,触发默认的 latin1 解码机制,导致 UTF-8 字节流被错误转换。
六、解决方法
方案1:强制指定JDBC字符集参数(推荐)
在连接字符串中显式声明编解码规则:
String url = "jdbc:mysql://10.191.81.31:3307/test?useUnicode=true&characterSetResults=utf8&characterEncoding=utf8&useSSL=false";
参数作用:
characterSetResults=utf8:强制服务端返回UTF-8编码。characterEncoding=utf8:客户端使用UTF-8编码发送请求。
优点:无需升级,调整简单,兼容性强。
方案2:使用兼容的排序规则
将排序规则改为utf8mb4_bin(非utf8mb4_0900_bin),该规则在驱动5.1.46中已支持,且同样区分大小写。
ALTER TABLE test.t1 CONVERT TO CHARSET utf8mb4 COLLATE utf8mb4_bin;
方案3:升级驱动至8.0.x版本
使用mysql-connector-java-8.0.32,完全支持utf8mb4_0900_bin。
<!-- Maven依赖示例 -->
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.32</version>
</dependency>
注意事项:需验证 JDK 1.7 与新版驱动的兼容性,部分API可能需调整。
七、总结
本文通过复现、排查、分析三步定位乱码问题,根本原因在于驱动版本与数据库排序规则的兼容性。三种解决方案各有适用场景:
-
快速修复场景:调整JDBC连接参数,强制UTF-8编解码。
-
保守场景:使用兼容的utf8mb4_bin排序规则。
-
技术升级场景:升级驱动至8.0.x版本。
建议根据实际环境选择最优方案,并在变更后进行全面测试,确保数据一致性与业务功能正常。