怎样做网站域名2345网址导航
使用KNN算法判断是否为传入的图片是否为苹果
"""
使用KNN算法判断是否为传入的图片是否为苹果
"""
# 导入需要的库
from sklearn.model_selection import train_test_split # 导入数据集划分函数
from sklearn.preprocessing import StandardScaler # 导入标准化函数
from sklearn.neighbors import KNeighborsClassifier # 导入KNN的分类器
import matplotlib.pyplot as plt # 导入绘图库
import seaborn as sns # 导入seaborn库
import pandas as pd # 导入pandas库
import os # 导入os
import cv2 # 导入cv2库
import numpy as np # 导入numpy库# 设置主题
sns.set_theme(style="darkgrid")# 设置中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 获取数据 读取data文件夹下的所有图片,并分为2类apple,not_appledef load_data(data_path, img_size=(64,64)):# 获取data文件夹下的所有图片images = []labels = []# 检查数据路径是否存在if not os.path.exists(data_path):print(f"错误:数据路径 {data_path} 不存在")return None, None# 遍历data_path下的所有子文件夹for class_name in os.listdir(data_path):class_path = os.path.join(data_path, class_name)if os.path.isdir(class_path):# 遍历子文件夹中的所有文件for file in os.listdir(class_path):# 检查文件是否为图片文件if file.endswith('.jpg') or file.endswith('.png'):try:# 读取图片img = cv2.imread(os.path.join(class_path, file))if img is None:continue# 调整图片大小img = cv2.resize(img, img_size)# 将图片转换为RGB格式img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)# 将图片展平为一维数组img = img.flatten()# 添加到图片列表images.append(img)# 根据文件夹名称判断是否为苹果if class_name == 'apple':labels.append(1) # 1表示苹果else:labels.append(0) # 0表示非苹果except Exception as e:continueif not images:print("错误:没有找到任何有效的图片")return None, None# 将列表转换为numpy数组images = np.array(images)labels = np.array(labels)return images, labels# 数据集划分
def split_data(images, labels, test_size=0.2, random_state=11):# 将数据集划分为训练集和测试集x_train, x_test, y_train, y_test = train_test_split(images, labels, test_size=test_size, random_state=random_state)return x_train, x_test, y_train, y_test# 标准化
def standardize(x_train, x_test):scaler = StandardScaler()x_train = scaler.fit_transform(x_train)x_test = scaler.fit_fit_transform(x_test)return x_train, x_test# KNN算法
def knn_classifier(x_train, y_train, x_test, k=5):# 创建KNN分类器knn = KNeighborsClassifier(n_neighbors=k)# 训练分类器knn.fit(x_train, y_train)return knn# 计算准确率
def accuracy_score(y_test, y_pred):return np.sum(y_test == y_pred) / len(y_test)if __name__ == '__main__':# 获取数据images, labels = load_data('data')# 数据集划分x_train, x_test, y_train, y_test = split_data(images, labels)# 标准化scaler = StandardScaler()x_train = scaler.fit_transform(x_train)# KNN算法knn = knn_classifier(x_train, y_train, x_test)# 预测y_pred = knn.predict(x_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print(f"准确率: {accuracy}")# 读取图片,判断是否为苹果img = cv2.imread('fruits/apple/12.jpg')cv2.imshow('img', img)img = cv2.resize(img, (64,64))img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)img = img.flatten()img = scaler.transform([img])pred = knn.predict(img)if pred == 1:print('该图片是苹果')else:print('该图片不是苹果')cv2.waitKey(0)cv2.destroyAllWindows()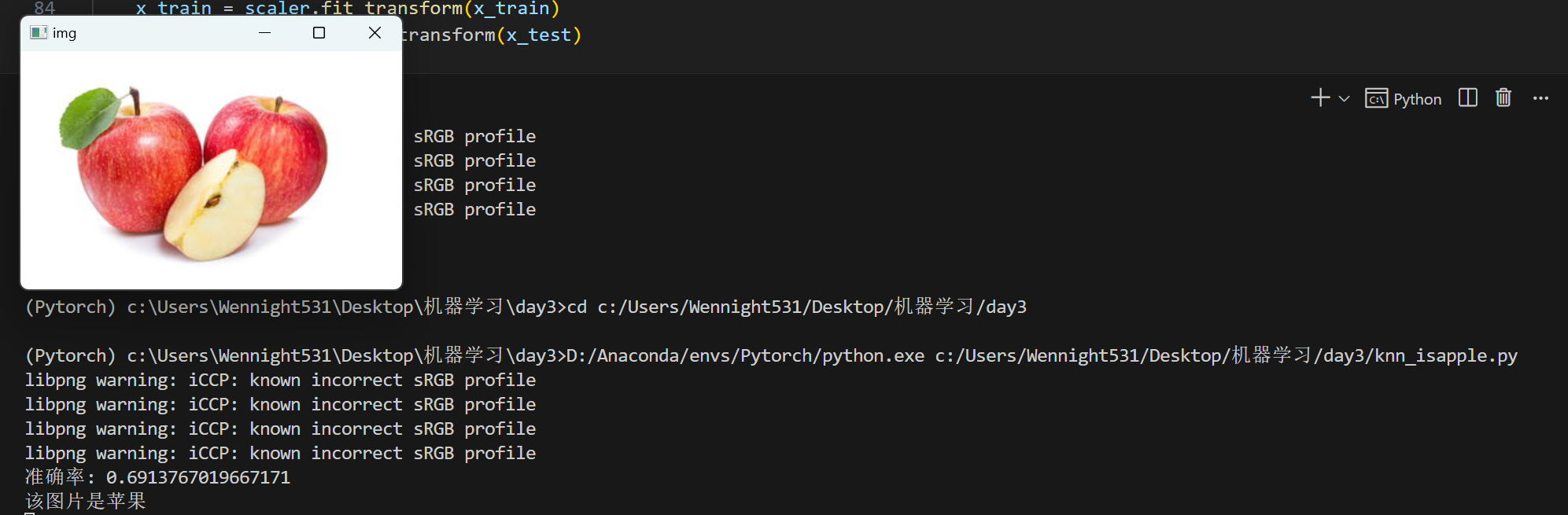
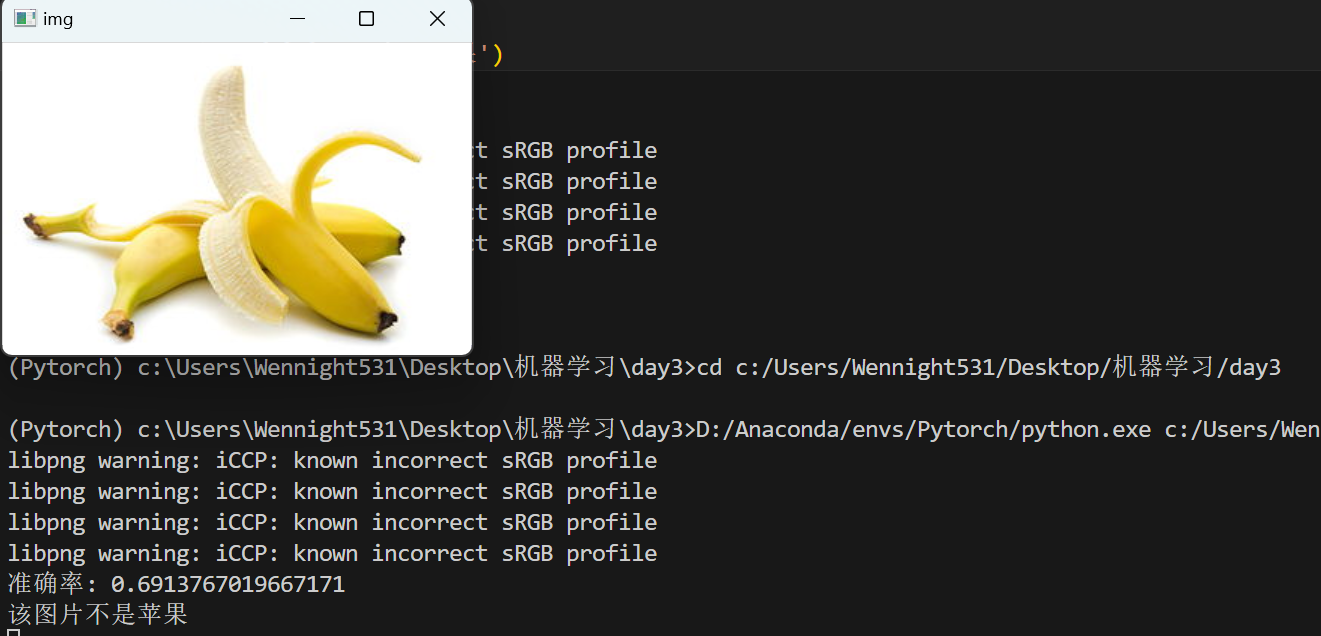
代码的目录结构如下图:数据集来自于飞桨网,想要复现代码的可以自行去网上找公开数据集