怎么自己的电脑做网站服务器八零云自助建站免费建站平台
摘要
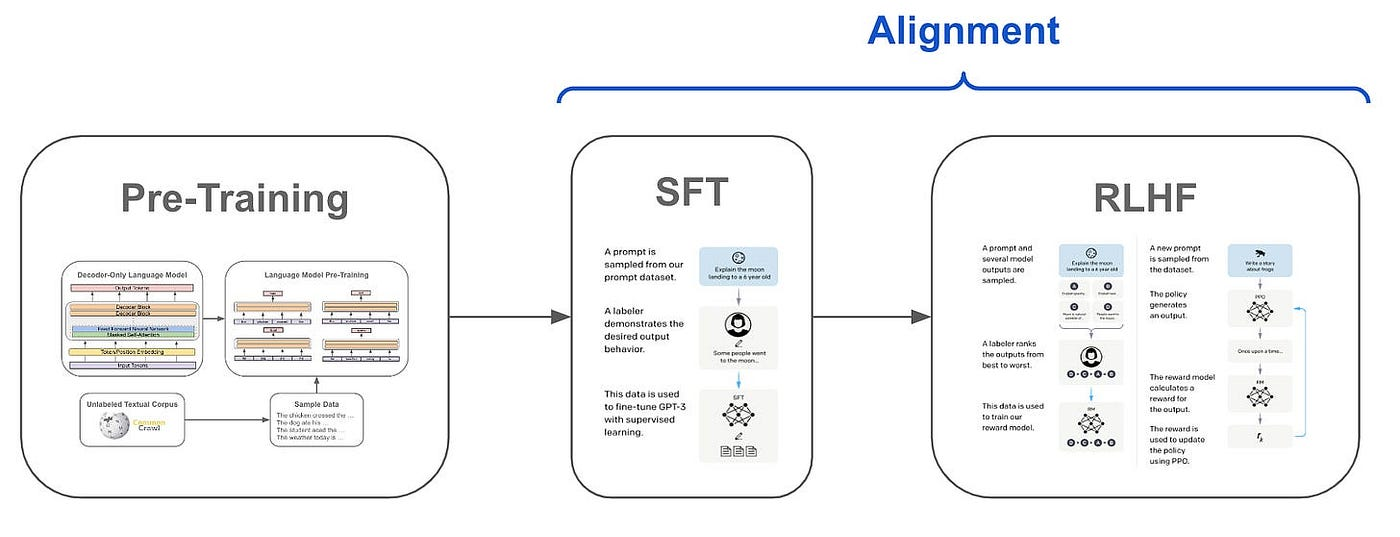
大模型一般分三个阶段(现在有很多个阶段的,比如DeepSeek),首先要完成的是Pre-Training阶段。预训练是指在大量无标签数据上进行训练,使模型学习到一些基础的语言表示和知识。常见的预训练方法包括自回归语言模型(如GPT系列)、自编码器等。这些方法通过在大规模语料库上训练,使模型能够理解语言的语法、语义和上下文信息。这篇文章试图告诉大家如何去实现增量Pre-Training。
为什么要增量Pre-Training
增量预训练的本质是在已有预训练模型基础上,通过新数据或新任务进一步优化模型参数或者针对特定需求对已有基座模型进行定向增强。我总结了一下几个方面需要用到增量Pre-Training:
1. 领域知识注入(Domain Adaptation)
- 问题:通用大模型(如LLaMA、GPT)在垂直领域(医疗、法律、金融)表现不足,缺乏专业术语和逻辑。
- 解法:
- 注入领域语料(如医学文献、法律条文),重建领域知识表征。
- 技术优势:相比从头训练,节省90%算力,且避免破坏原有语言能力。
2. 数据时效性更新(Data Freshness)
- 问题:预训练数据存在时间滞后(如GPT-4数据截止2023年10月),无法理解新事件或技术。
- 解法:
- 增量训练加入最新语料(新闻、论文、社交媒体),更新知识库。
- 动态采样:按时间衰减加权(新数据权重更高)。
3. 多语言/文化适配(Multilingual Enhancement)
- 问题:通用模型对小语种或文化特性(方言、古文)支持不足,LLama对中文的支持不太友好等。
- 解法:
- 添加低资源语言数据,调整分词器(扩展词表)。
- 引入文化标识符(如
[lang=zh-yue]标注粤语)。
4. 任务能力强化(Task-Specific Augmentation)
- 问题:模型在特定任务(代码生成、数学推理)上表现弱于专用模型。
- 解法:
- 混合任务相关数据(如GitHub代码、arXiv数学论文)。
- 课程学习:逐步增加任务难度(先Python语法,再复杂算法)。
5. 灾难性遗忘缓解(Catastrophic Forgetting Mitigation)
- 问题:微调(Fine-tuning)过度适配下游任务,导致通用能力退化。
- 解法:
- 混合训练:在微调时混入5%-10%原始预训练数据。
- 弹性权重固化:保护重要神经元不被覆盖(EWC算法)。
6. 资源优化与迭代效率
- 问题:从头训练千亿级模型需数月时间和千万美元算力。
- 解法:
- 基于现有模型增量扩展,节省90%以上资源。
- 参数冻结:仅训练部分层(如顶层+注意力头)。
| 维度 | 增量预训练 | 从头训练 | 微调(Fine-tuning) |
|---|---|---|---|
| 数据需求 | 中规模领域数据(1B-100B tokens) | 超大规模通用数据(1T+ tokens) | 小规模标注数据(1k-1M样本) |
| 计算成本 | 10%-30%从头训练成本 | 100%基准成本 | 1%-5%从头训练成本 |
| 能力保留 | 保持通用能力 + 新增专项能力 | 从零构建 | 可能牺牲通用能力 |
| 适用阶段 | 基座模型迭代/领域适配 | 初始模型构建 | 下游任务适配 |
预训练数据集
LLama-Factory支持的数据集格式
大语言模型通过学习未被标记的文本进行预训练,从而学习语言的表征。通常,预训练数据集从互联网上获得,因为互联网上提供了大量的不同领域的文本信息,有助于提升模型的泛化能力。 预训练数据集文本描述格式如下:
[{"text": "document"},{"text": "document"}
]
在预训练时,只有 text 列中的 内容 (即document)会用于模型学习。
对于上述格式的数据, dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.json","columns": {"prompt": "text"}
}
同时也支持jsonl格式
{"text": "document"}{"text": "document"}
在 dataset_info.json 中的 数据集描述 应为:
"数据集名称": {"file_name": "data.jsonl","columns": {"prompt": "text"}
}
一般开源数据集用jsonl
开源数据集
-
Firefly-LLaMA2-Chinese 数据集
- 内容:包含约 22GB 中文文本,涵盖 CLUE、ThucNews、CNews、COIG、维基百科等开源数据,以及古诗词、散文、文言文等特色语料。
- 特点:专为中文增量预训练设计,适用于增强模型的中文理解和生成能力。
- 获取地址:HyperAI 社区或者魔搭社区。建议用魔搭社区,速度快一些。
-
WuDao 200G
- 内容:中文开源预训练数据集,覆盖百科、新闻、论坛等多领域文本。
- 特点:经典中文语料库,常与 The Pile 数据集搭配使用,总规模达 1T,适合基础预训练。
- 获取地址:https://openi.pcl.ac.cn/BAAI/WuDao-Data
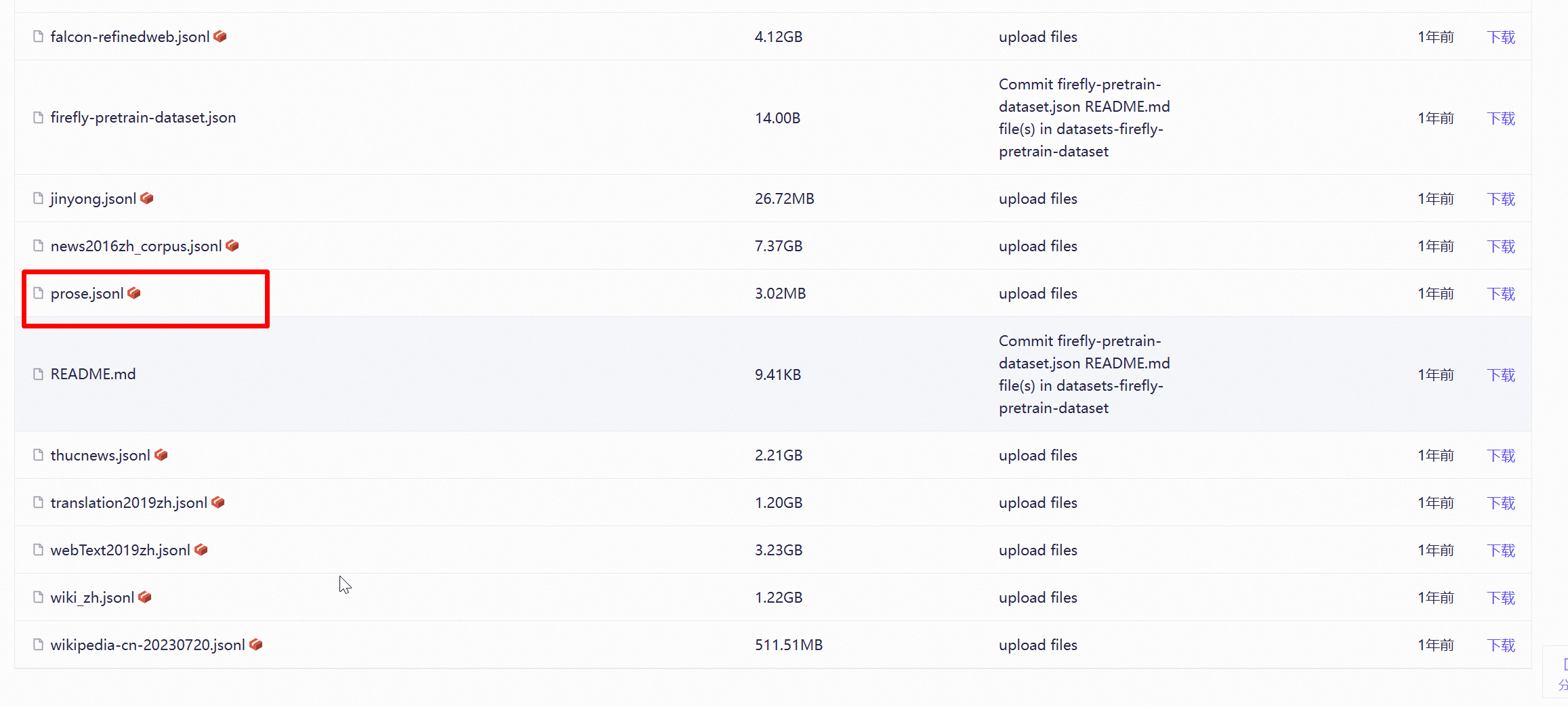
作为练习使用,找一个小点的数据集就可以了,除非你有钱有资源。比如prose.jsonl
安装LLama-Factory
Linux
CUDA 安装
CUDA 是由 NVIDIA 创建的一个并行计算平台和编程模型,它让开发者可以使用 NVIDIA 的 GPU 进行高性能的并行计算。
首先,在 https://developer.nvidia.com/cuda-gpus 查看您的 GPU 是否支持CUDA
保证当前 Linux 版本支持CUDA. 在命令行中输入 uname -m && cat /etc/*release,应当看到类似的输出
x86_64
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=22.04
检查是否安装了 gcc . 在命令行中输入 gcc --version ,应当看到类似的输出
gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
在以下网址下载所需的 CUDA,这里推荐12.2版本。 https://developer.nvidia.com/cuda-gpus 注意需要根据上述输出选择正确版本
如果您之前安装过 CUDA(例如为12.1版本),需要先使用 sudo /usr/local/cuda-12.1/bin/cuda-uninstaller 卸载。如果该命令无法运行,可以直接:
sudo rm -r /usr/local/cuda-12.1/
sudo apt clean && sudo apt autoclean
卸载完成后运行以下命令并根据提示继续安装:
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run
sudo sh cuda_12.2.0_535.54.03_linux.run
注意:在确定 CUDA 自带驱动版本与 GPU 是否兼容之前,建议取消 Driver 的安装。
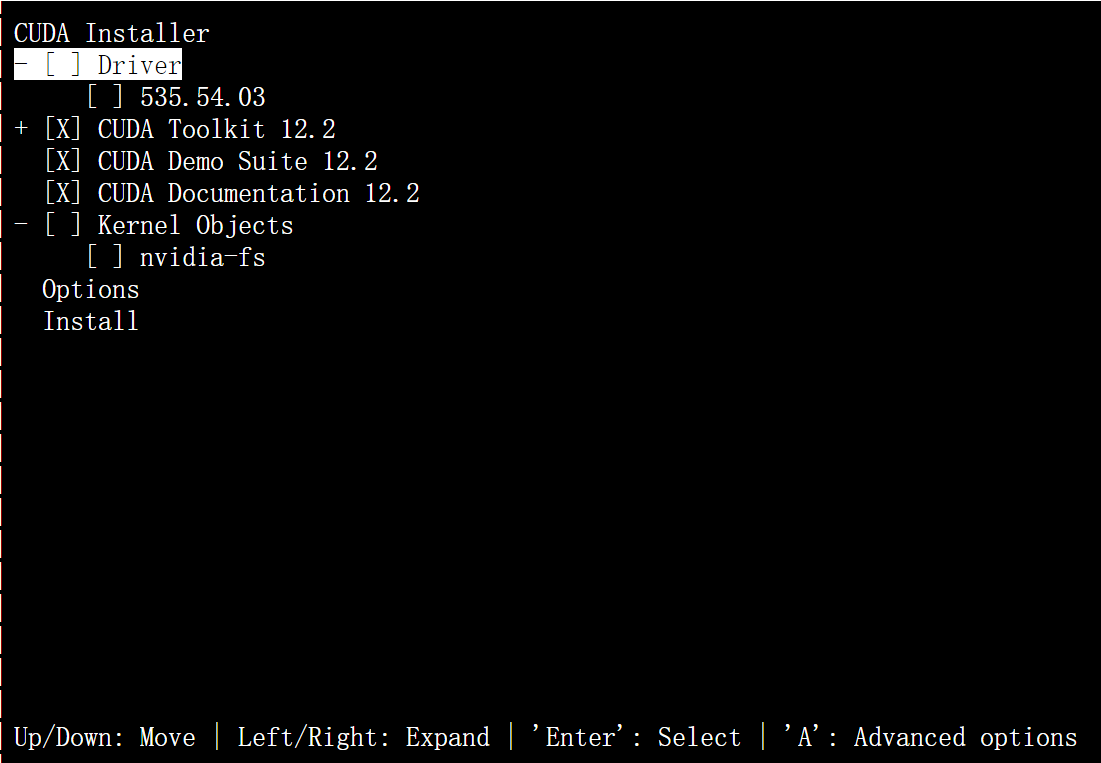
完成后输入 nvcc -V 检查是否出现对应的版本号,若出现则安装完成。
Windows
CUDA 安装
打开 设置 ,在 关于 中找到 Windows 规格 保证系统版本在以下列表中:
支持版本号
Microsoft Windows 11 21H2
Microsoft Windows 11 22H2-SV2
Microsoft Windows 11 23H2
Microsoft Windows 10 21H2
Microsoft Windows 10 22H2
Microsoft Windows Server 2022
选择对应的版本下载并根据提示安装。
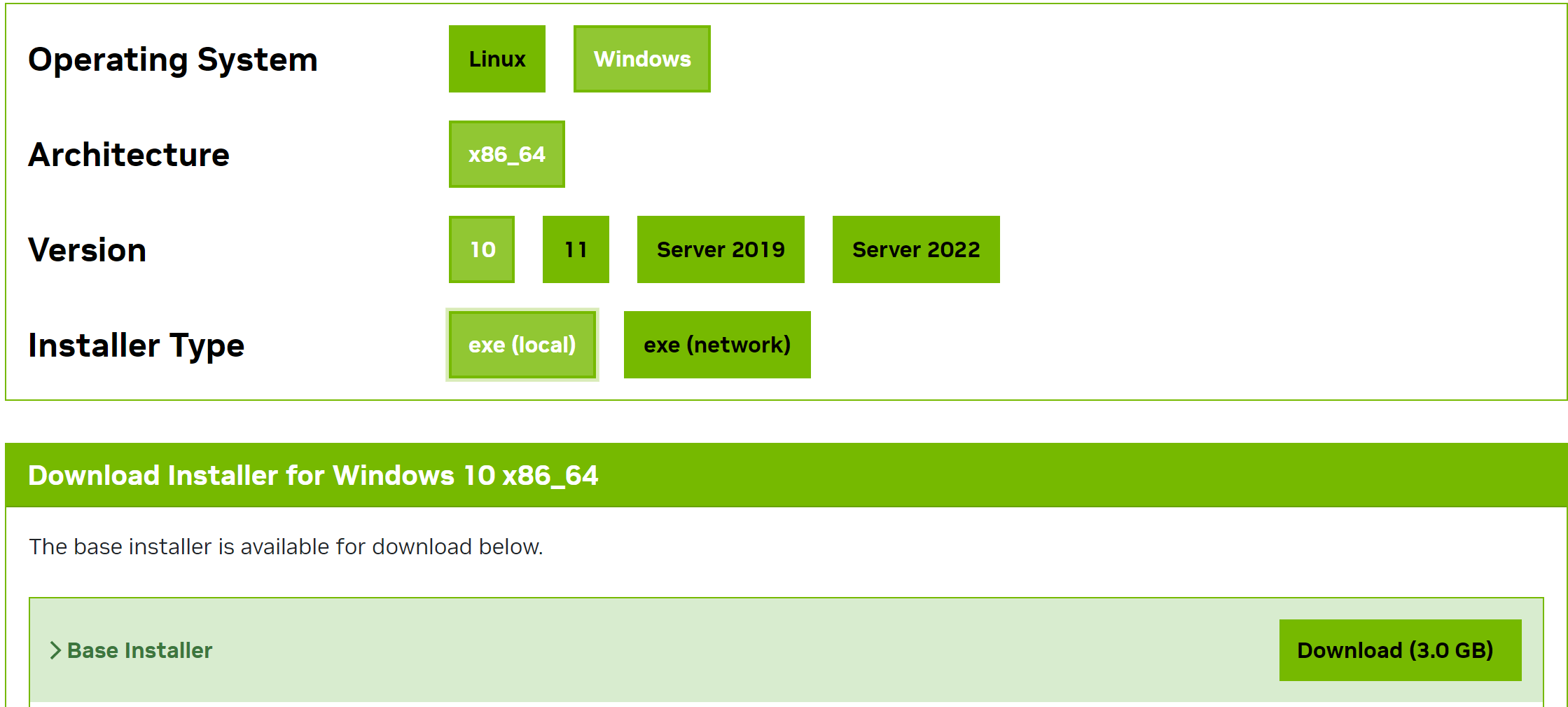
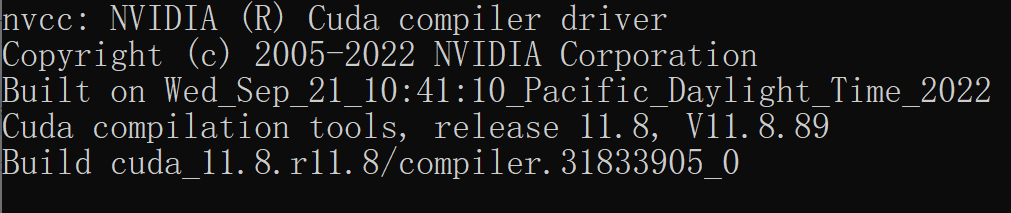
打开 cmd 输入 nvcc -V ,若出现类似内容则安装成功。
否则,检查系统环境变量,保证 CUDA 被正确导入。

LLaMA-Factory 安装
在安装 LLaMA-Factory 之前,请确保您安装了下列依赖:
运行以下指令以安装 LLaMA-Factory 及其依赖:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
如果出现环境冲突,请尝试使用 pip install --no-deps -e . 解决
LLaMA-Factory 校验
完成安装后,可以通过使用 llamafactory-cli version 来快速校验安装是否成功
如果您能成功看到类似下面的界面,就说明安装成功了。

LLaMA-Factory 高级选项
Windows
QLoRA
如果您想在 Windows 上启用量化 LoRA(QLoRA),请根据您的 CUDA 版本选择适当的 bitsandbytes 发行版本。
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
FlashAttention-2
如果您要在 Windows 平台上启用 FlashAttention-2,请根据您的 CUDA 版本选择适当的 flash-attention 发行版本。
如果觉得安装麻烦还有一种简单的办法,就是,新建虚拟环境,直接按照pytorch,pytorch会自动安装CUDA,这样不用担心版本的问题。如果版本不满足就换一个cuda版本的pytorch。比如我想安装CUDA12.4版本的pytorch,即使我本机是CUDA12.2的,我也可以用,执行命令:
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.4 -c pytorch -c nvidia
pytorch环境安装好后,就可以安装LLama-Factory了。
增量预训练
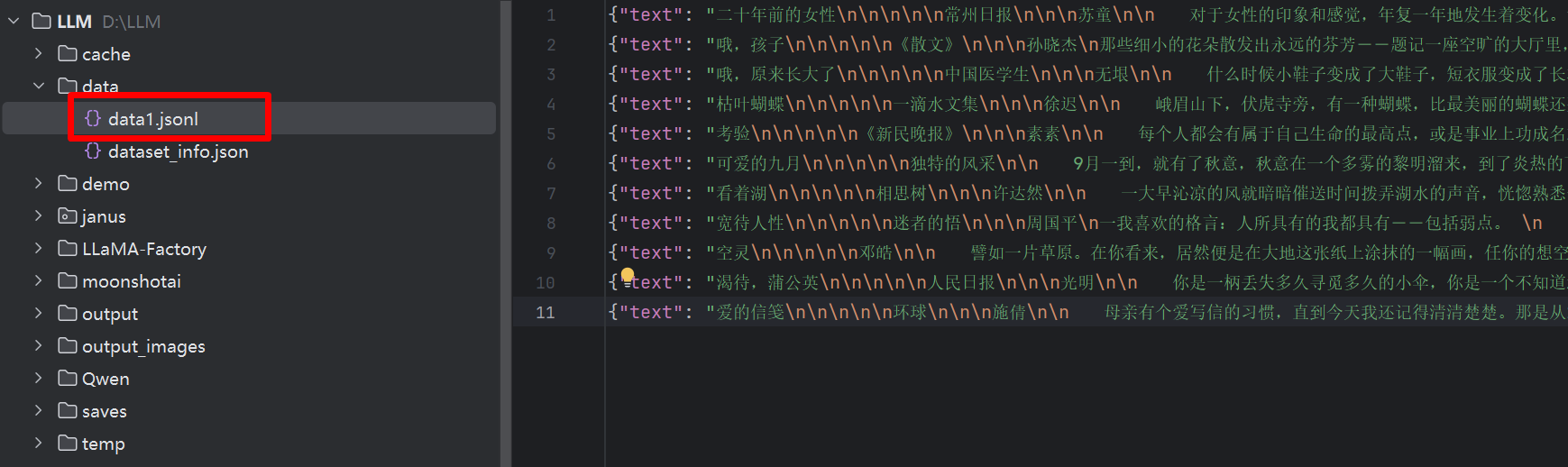
新建data1.jsonl,从prose.jsonl复制一些数据放到data1.josnl中,如下图:
然后,新建dataset_info.json,增加data1的配置,如下图:

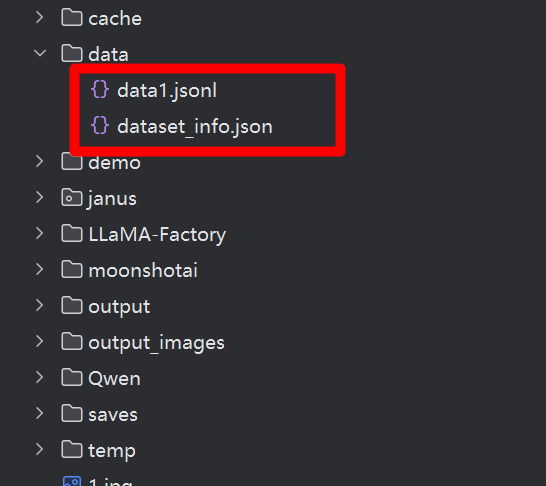
将data1.jsonl和dataset_info.json,放到data文件夹下面,如下图:
编写llama3_lora_pretrain.yaml,详细配置如下:
### model
model_name_or_path: Qwen/Qwen3-0.6B
trust_remote_code: true### method
stage: pt
do_train: true
finetuning_type: lora
lora_rank: 8
lora_target: all### dataset
dataset: data1
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
dataloader_num_workers: 4### output
output_dir: saves/Qwen/lora/pretrain
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
save_only_model: false
report_to: none # choices: [none, wandb, tensorboard, swanlab, mlflow]### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
resume_from_checkpoint: nullstage设置为pt,model_name_or_path为模型的路径,我用Qwen3的0.6B模型为例: Qwen/Qwen3-0.6B
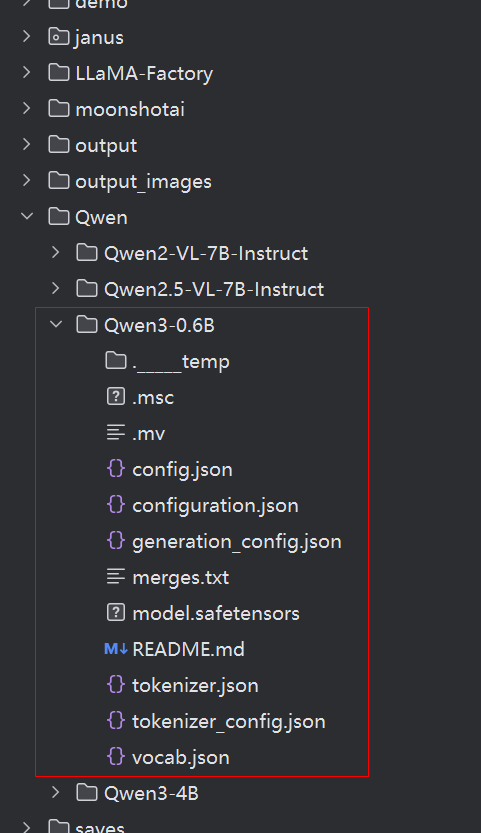
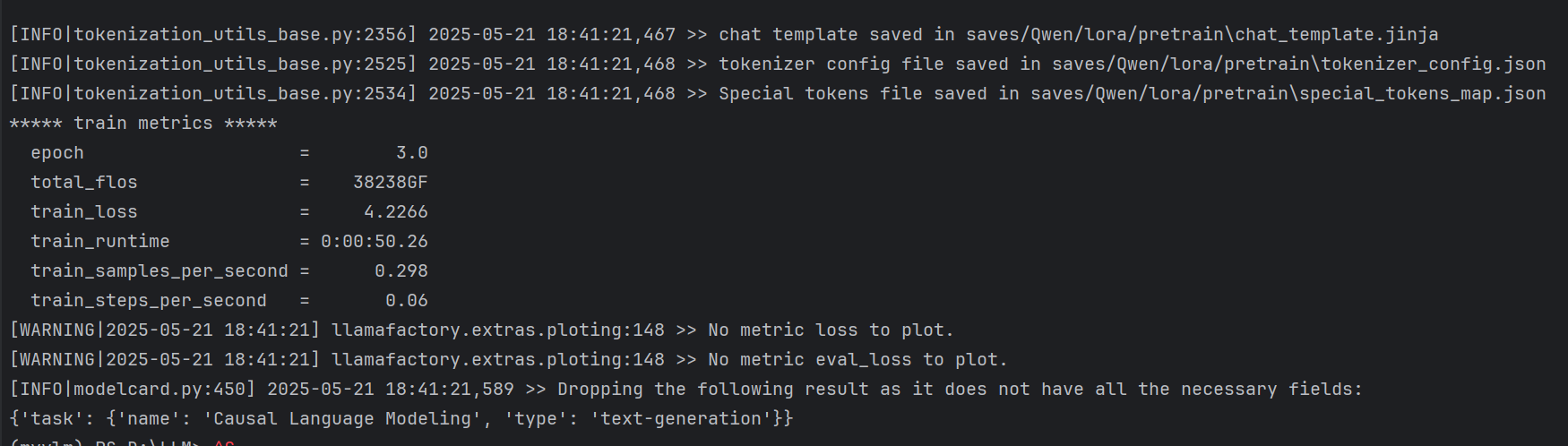
llama3_lora_pretrain.yaml和Qwen在同一个目录,然后,在命令行里执行:
llamafactory-cli train .\llama3_lora_pretrain.yaml